一种基于隔离森林算法的网络流量异常检测方法
本发明涉及网络安全异常流量检测的,是一种基于隔离森林算法的网络流量异常检测方法。
背景技术:
1、在当前网络安全领域,时间序列数据的有效处理和分析,尤其在网络流(netflow)数据异常检测研究中显得至关重要。网络流数据,作为时间序列数据的一种,承载着网络流量的记录,为深入了解网络流量的特征和行为模式提供了关键信息。然而,由于网络流量数据的庞大容量和复杂结构,对其进行有效处理和分析面临一系列挑战。在实际网络环境中,网络流量数据的应用不仅在异常检测和网络性能监控等方面显得尤为重要,而且在应对日益复杂的网络安全威胁时扮演着关键角色。因此,确保网络流量数据的准确分析和异常检测对于维护网络安全至关紧要。
2、随着机器学习技术的迅猛发展,处理大规模网络流量的技术不断创新。然而,目前的研究在深入挖掘隔离森林(isolation forest)算法在网络流量异常检测中的潜在优势方面存在一些不足,特别是在处理类别不平衡或数据标签不完整的情况下,很少有研究全面考虑隔离森林算法的适用性。此外,对隔离森林算法在网络流量中的具体应用场景,尤其是在异常检测任务中的性能表现的深入研究尚未展开。这一研究空白意味着当前对于隔离森林算法在网络流量异常检测中的真正潜力了解不足。因此,研究仍需进一步深入,更好地发挥隔离森林算法在解决网络流量挑战、提高异常检测准确性和效率方面的潜力。
技术实现思路
1、本发明的目的是补充现有技术和研究的空白,旨在解决网络流量中的恶意行为检测问题,通过引入隔离森林算法,创新性地提供了一种高效、快速而准确的网络安全检测方法。相较于传统方法,本发明采用隔离森林,一种基于集成学习的无监督学习算法,以实现对网络流量中潜在恶意行为的精准检测。
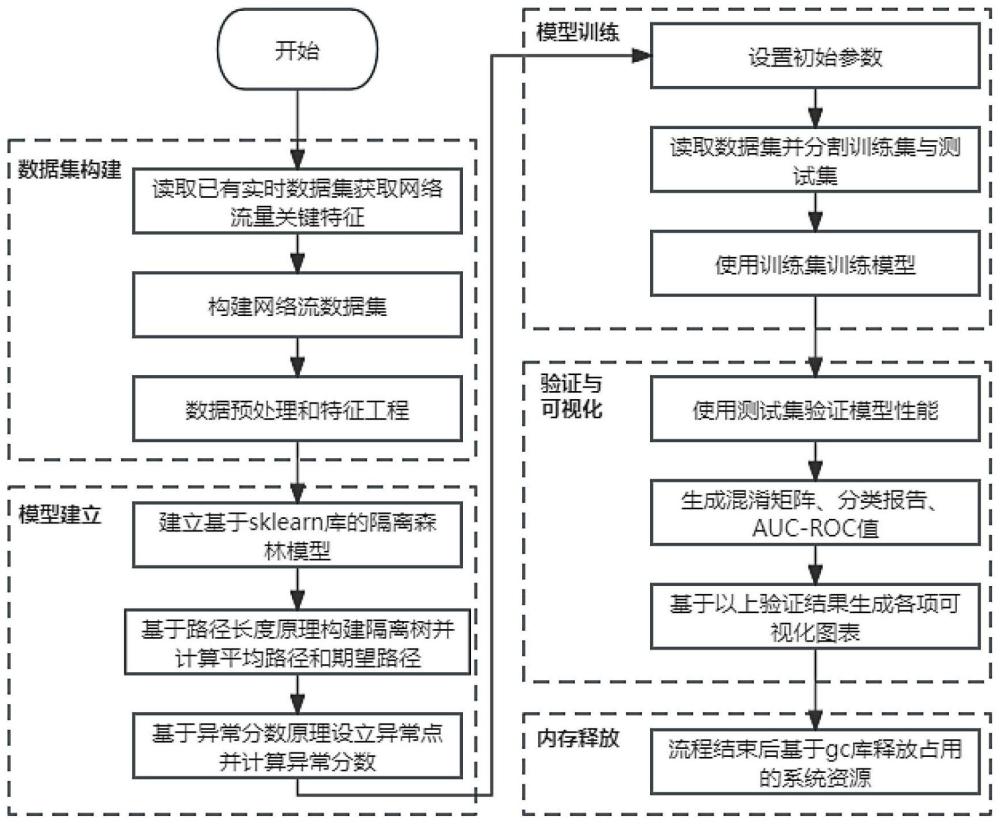
2、本发明的目的是由以下技术方案来实现的:一种基于隔离森林算法的网络流量异常检测方法,其特征是,首先,通过读取已有的实时数据集和特征映射策略构建网络流(netflow)数据集。对数据集进行数据预处理、特征工程,标准化特征和标签编码,为模型训练提供准备好的输入数据。随后,采用隔离森林(isolation forest)算法进行模型训练,以捕捉和识别恶意流量模式。最后,模型性能通过混淆矩阵(confusion matrix)、分类报告(classification report)和auc-roc(receiver operating characteristic curve andarea under the curve)曲线等指标在验证集上进行全面评估,关注准确性、召回率等关键性能指标。在评估结果后输出检测到的异常数据集,并释放资源占用。其具体步骤包括:
3、1)构建网络流数据集;
4、2)数据预处理和特征工程;
5、3)训练隔离森林模型;
6、4)模型性能评估;
7、5)可视化输出;
8、6)输出检测到的异常数据集;
9、7)垃圾回收。
10、所述步骤1)中通过读取已有的实时数据集获取网络流量的关键信息,构建网络流数据集。该数据集包含实时网络流量的多维信息,网络流数据集需要包含以下关键信息:源ip地址(source_ip):标识网络通信的发起者的ip地址。目标ip地址(destination_ip),标识网络通信的接收者的ip地址;源端口号(source_port),指示网络通信的发起者端口的数字标识;目标端口号(destination_port),指示网络通信的接收者端口的数字标识;协议类型(protocol),描述网络通信所使用的协议,如tcp、udp等;tcp标志(tcp_flags),包含有关tcp通信状态的信息,如syn、ack、fin等;应用层协议(layer7_protocol),标识网络通信所使用的应用层协议;传入字节数(incoming_bytes),指示网络通信中传入数据的总字节数;传出字节数(outgoing_bytes),指示网络通信中传出数据的总字节数;传入数据包数(incoming_packets),表示网络通信中传入数据包的总数;传出数据包数(outgoing_packets),表示网络通信中传出数据包的总数;流持续时间(毫秒)(flow_duration_ms),描述网络流量的持续时间,以毫秒为单位。这些特征反映了网络通信活动的基本特性。通过提取实时网络数据集的关键信息获取了有关网络流量的详尽描述。
11、通过这一步骤,可以成功构建一个具备多维特征的网络流数据集,为进一步的分析和异常检测提供全面而详细的网络流量描述,并为后续的数据预处理和模型训练奠定基础。
12、所述步骤2)中进行数据预处理以确保模型训练时的稳定性。这包括处理缺失值、标准化特征等操作,以保障数据的完整性和一致性。对于缺失值,采用适当的方法进行填充或删除,以防止对模型产生负面影响。标准化特征的过程旨在消除不同特征之间的量纲差异,以确保它们在模型中的权重被平等对待。之后进行特征工程的阶段,旨在通过选择、转换和组合特征,提高模型对网络流量模式的敏感性和泛化能力。这涉及到以下几个方面:特征选择(feature selection),通过选择与目标相关性较高的特征,剔除对模型贡献较小的特征,从而简化模型并提高计算效率;特征转换(feature transformation),应用一些数学变换或函数,将原始特征转换为更适合模型的形式。例如,可以使用对数变换来处理偏斜分布的特征。特征组合(feature combination),将不同特征进行组合,创造新的特征,以更好地捕捉网络流量的复杂模式。这可以通过数学运算,如加法、乘法等来实现。
13、数据预处理和特征工程的目标是提高模型的性能和泛化能力,确保模型对网络流量的各种模式和变化具有较强的适应性。这一步骤的完善有助于为隔离森林模型提供更为优质和有效的输入数据。
14、所述步骤3)中采用隔离森林算法进行模型训练。隔离森林是一种基于树结构的集成学习方法,用于检测异常值或离群点。隔离森林的主要思想是通过随机选择特征和切分点,构建多棵树,然后利用这些树来对正常和异常样本进行划分。隔离森林的实现包括路径长度和异常分数。
15、①路径长度原理
16、隔离森林中树的构建过程依赖于路径长度。每个数据点在树中的路径长度定义为从根节点到达该点所经过的边的数量。路径长度用于衡量一个样本点在树中的孤立程度。对于一棵树而言,平均路径长度(average path length)可以通过式(1)计算:
17、
18、式中n表示样本点的数量,即数据集中的样本数量。h(n-1)表示调和数,用欧拉常数(euler’s constant)估计为ln(n)+0.5772。这里ln(n)表示数据集中样本数量n的自然对数。第二项,2(n-1)/n,作为一个归一化因子,根据数据集大小调整平均路径长度;
19、②异常分数原理
20、隔离森林通过计算每个样本的路径长度来得到异常分数,对于样本点x,其异常分数s(x)可以表示用式(2)描述:
21、
22、式中随着样本点在树中的路径长度增加,异常分数s(x,n)会减小。这是因为路径长度越短,样本点越容易被隔离,被认为是异常的可能性越高。反之,路径长度越长,样本点越接近树的叶子节点,被认为是正常的可能性越高。异常分数的设计是基于这样的思想,使得异常分数较高的样本点更有可能是异常点。e(h(x))是样本点x的平均路径长度的期望值,可以通过式(3)计算得到:
23、
24、在具体实现过程中,可以通过设定隔离森林的超参数,如树的数量(n_estimators)、采样比例等。增加树的数量有助于提高模型的鲁棒性,而适当的采样比例可以控制每棵树的规模,防止模型过拟合。
25、此步骤的关键是通过有监督学习的方式,构建多个隔离森林,使其能够有效地捕捉到正常网络流量和恶意流量的模式,为后续的模型评估和应用提供基础。
26、所述步骤4)中通过使用验证集,对训练好的隔离森林模型进行全面的性能评估。计算关键性能指标包括准确性、召回率、精确率、f1分数等,以深入了解模型的效果。这些指标提供了对模型在不同方面表现的详细了解,有助于评估其在正常和异常类别上的分类效果。
27、在具体实现中,使用混淆矩阵(confusion matrix)来计算这些性能指标。混淆矩阵是一个二维矩阵,展示了模型的预测结果与实际情况的对应关系。基于混淆矩阵,可以计算准确性(accuracy)、召回率(recall)、精确率(precision)和f1分数,这些指标表示为式(4)、式(5)、式(6)、式(7):
28、
29、
30、
31、
32、式中,tp表示真正例(true positive),tn表示真负例(true negative),fp表示假正例(false positive),fn表示假负例(false negative)。
33、另外,计算auc-roc分数以更全面地评估模型性能。auc-roc是一种用于度量二元分类器性能的指标。其计算方法如式(8)所示:
34、
35、auc-roc分数表示roc曲线下的面积,用于总体评估分类器的性能。roc曲线是以真正例率(true positive rate)为纵轴,假正例率(false positive rate)为横轴的曲线。它展示了模型在不同阈值下的真正例率和假正例率之间的权衡。auc-roc分数越接近1,说明模型的性能越好。其中真正例率又称为敏感性(sensitivity)或召回率(recall),是指在实际正例中,模型成功识别为正例的比例。假正例率是指在实际为负例中,模型错误地识别为正例的比例。真正例率和假正例率的计算方法如式(9)和式(10)所示:
36、
37、
38、真正例率和假正例率是在不同阈值下的模型性能度量,通常在绘制roc曲线时使用。通过改变分类器的阈值可以得到不同点上的真正例率和假正例率。
39、这一步骤的评估结果对于确定隔离森林模型在检测网络流量异常行为方面的有效性至关重要。
40、所述步骤5)中利用多个图表和可视化工具,对隔离森林模型的输出进行可视化详细展示。这包括数据类型分布图,通过水平条形图展示了攻击类型的分布情况,使用百分比表示。这个图表直观地展示了模型在不同攻击类型上的检测效果,并帮助用户理解模型对于各种攻击的处理能力;数据类型计数表格,利用表格显示了攻击类型的计数、百分比等信息,为用户提供了更详细的攻击类型分布数据。这样的表格展示有助于更精细地了解模型在各类攻击中的表现;混淆矩阵热力图,利用热力图直观展示了模型在验证集上的混淆矩阵。混淆矩阵热力图清晰地显示了模型在不同类别的真正例、真负例、假正例和假负例数量,提供了对模型性能的更细致了解;异常分数分布图,展示了模型输出的异常分数的分布情况。通过分布图展示了异常分数的分布从而更好地理解模型对于验证集中样本的异常程度评估。
41、这些图表和可视化工具综合呈现了隔离森林模型的性能和输出结果,为研究者和实践者提供了全面的视觉信息。
42、所述步骤6)中根据模型对验证集的评估结果,输出检测到的异常数据集。首先,通过模型的预测结果,筛选出被标记为异常的网络流量实例。这些实例代表了模型认为具有异常行为的网络通信。之后进行反向转换编码,将数值化的攻击类型还原为实际的攻击类型。这一步骤是为了更好地理解检测到的异常流量的特征,并使结果更具可解释性。
43、随后过滤掉经过分类后被标记为正常(benign)的流量,只保留被模型判定为恶意的流量。这样,输出的异常数据集中将只包含潜在的攻击流量。最后,为了方便进一步研究和分享,将结果保存为csv文件并输出,其中包含了有关恶意流量的详细信息,如源ip地址、目标ip地址、端口号、协议类型等。
44、这些数据集包含被模型标记为异常的网络流量实例,为进一步的研究、分析和响应提供了有用的信息。
45、所述步骤7)中在前述流程完成后,进行垃圾回收以释放占用的系统资源。垃圾回收的主要目的是确保模型训练和评估过程的高效性,提高系统的整体性能和稳定性,同时为系统后续的操作或进一步的优化提供准备。
46、通过使用gc库调用了python的垃圾回收模块,主动回收不再使用的对象和释放内存。这是为了确保模型的高效性和可维护性,防止潜在的资源泄漏问题,并确保系统在后续任务中能够以最佳状态运行。
47、本发明是一种基于隔离森林算法的网络流量异常检测方法,其特征是,首先,通过读取已有的实时数据集和特征映射策略构建网络流(netflow)数据集。对数据集进行数据预处理、特征工程,标准化特征和标签编码,为模型训练提供准备好的输入数据。随后,采用隔离森林(isolation forest)算法进行模型训练,以捕捉和识别恶意流量模式。最后,模型性能通过混淆矩阵(confusion matrix)、分类报告(classification report)和auc-roc(receiver operating characteristic curve and area under the curve)曲线等指标在验证集上进行全面评估,关注准确性、召回率等关键性能指标。在评估结果后输出检测到的异常数据集,并释放资源占用。本发明综合运用了隔离森林算法和多维特征的网络流量,结合了专用于异常检测的机器学习算法和特征工程技术,填补了现有研究中的空白,并通过全面的评估和可视化输出,提供了对异常检测模型性能和异常数据集的深入理解,具有方法科学合理、适用性强、效果佳等优点。
- 还没有人留言评论。精彩留言会获得点赞!