视频合成方法、装置、设备及存储介质与流程
本技术涉及人工智能,更具体的说,是涉及一种视频合成方法、装置、设备及存储介质。
背景技术:
1、随着图像处理技术进步,图像被广泛应用于各种各样的场景中。在图像显示场景中,如何提升图像的显示效果成为备受关注的问题之一。
2、在一些场景中,会通过将图像生成视频进行展示。多数情况下,需要用户提供多张图像,对多张图像进行拼接、合成为视频进行展示。而在面对单张图像的展示时,部分现有技术采用动图技术,其仅能够根据固定的模板进行动图的合成,无法适用于不同用户的不同合成需求,导致图像展示效果不佳的问题。
技术实现思路
1、鉴于上述问题,提出了本技术以便提供一种视频合成方法、装置、设备及存储介质,以实现根据用户的合成需求,对图像进行视频合成的目的。具体方案如下:
2、第一方面,提供了一种视频合成方法,包括:
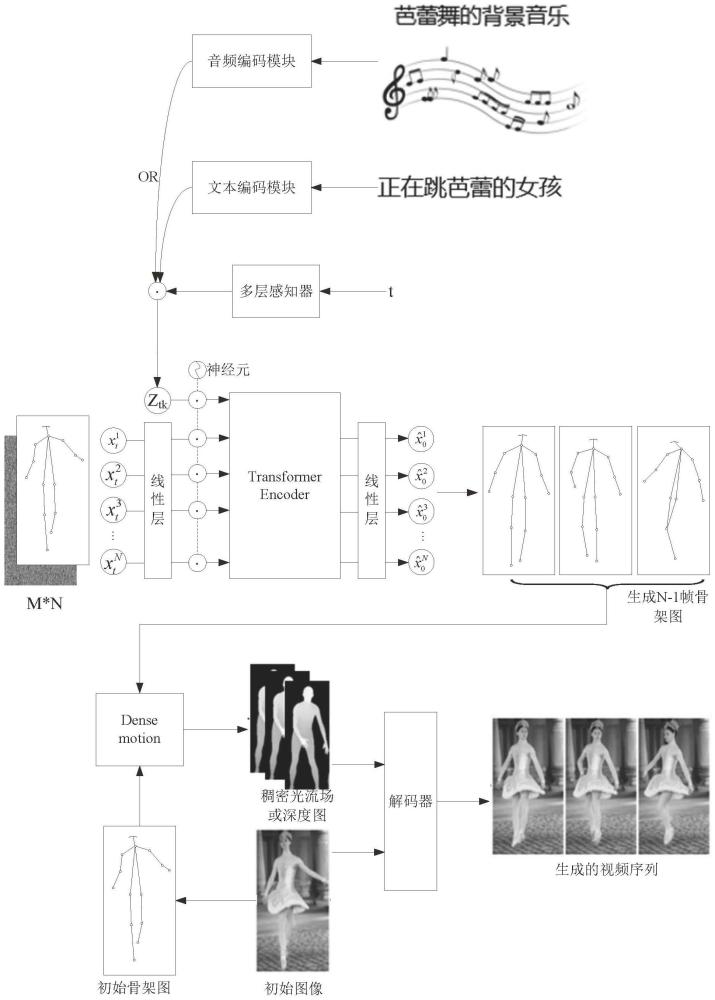
3、获取指定的初始图像,及与待合成视频匹配的多模态条件信息,所述多模态条件信息包括与所述待合成视频匹配的音频信息和/或文本描述信息;
4、提取所述初始图像对应的初始骨架图;
5、以所述多模态条件信息作为控制条件,利用配置的扩散模型在所述控制条件的指导下,生成与所述多模态条件信息语义匹配的连续骨架图,由所述初始骨架图及生成的所述连续骨架图依序组成目标骨架图序列;
6、基于所述目标骨架图序列对所述初始图像的图像特征进行变形,以生成视频序列。
7、优选地,以所述多模态条件信息作为控制条件,利用配置的扩散模型在所述控制条件的指导下,生成与所述多模态条件信息语义匹配的连续骨架图的过程,包括:
8、获取所述多模态条件信息的条件编码特征;
9、由所述初始骨架图及若干帧随机噪声骨架图组成输入数组,将所述输入数组送入配置的扩散模型,同时将所述条件编码特征作为控制条件也送入所述扩散模型,由所述扩散模型对所述输入数组进行编码,将编码特征与所述条件编码特征进行融合,并基于融合后的编码特征生成与所述多模态条件信息语义匹配的若干帧连续的骨架图。
10、优选地,获取所述多模态条件信息的条件编码特征的过程,包括:
11、通过配置的编码网络对所述多模态条件信息进行编码,得到条件编码特征,其中所述编码网络包括音频编码模块及文本编码模块,所述音频编码模块用于对音频信息进行编码,所述文本编码模块用于对文本描述信息进行编码。
12、优选地,所述编码网络和所述扩散模型采用端到端的方式进行训练,训练过程包括:
13、获取视频样本,并标记所述视频样本匹配的多模态条件信息,所述多模态条件信息包括视频样本匹配的音乐信息和/或文本描述;
14、提取所述视频样本中各帧图像的骨架图,作为样本标签;
15、通过所述编码网络对所述视频样本匹配的多模态条件信息进行编码,得到的条件编码特征作为控制条件送入所述扩散模型,以及,将所述视频样本中首帧图像的骨架图及若干帧噪声骨架图组成输入数组送入所述扩散模型,得到所述扩散模型生成的若干帧连续的骨架图;
16、基于所述扩散模型生成的连续的骨架图及所述样本标签,计算损失函数的值,并根据所述损失函数的值更新所述编码网络和所述扩散模型的网络参数。
17、优选地,所述损失函数包括:
18、第一损失函数,用于约束所述扩散模型生成的每时刻的骨架图中各骨架节点的位置,与对应时刻的样本标签中各骨架节点的位置一致。
19、优选地,所述损失函数还包括以下任意一项或多项:
20、第二损失函数,用于约束所述扩散模型生成的每时刻的骨架图中各骨架节点的位置均值,与对应时刻的样本标签中各骨架节点的位置均值一致;
21、第三损失函数,用于约束所述扩散模型生成的连续骨架图中,若前后两帧骨架图中脚部节点触地,则所述前后两帧骨架图中所述脚步节点的位置一致;
22、第四损失函数,用于约束所述扩散模型生成的连续骨架图中,各帧骨架图的速度保持一致。
23、优选地,基于所述目标骨架图序列对所述初始图像的图像特征进行变形,以生成视频序列的过程,包括:
24、将所述目标骨架图序列输入预训练的稠密变形场生成网络,得到网络输出的与所述目标骨架图序列匹配的稠密变形场,所述稠密变形场为稠密光流场或深度图;
25、将所述稠密变形场及所述初始图像输入预训练的解码器网络,得到网络输出的视频序列。
26、优选地,所述稠密变形场生成网络及所述解码器网络组成视频合成模型,所述视频合成模型的训练过程包括:
27、获取视频样本,并提取所述视频样本中各帧图像的骨架图;
28、将所述视频样本中各帧图像的骨架图输入所述稠密变形场生成网络,得到生成的稠密变形场;
29、将生成的稠密变形场及所述视频样本中首帧图像输入所述解码器网络,得到解码器网络输出的视频序列;
30、基于所述解码器网络输出的视频序列及所述视频样本,计算视频图像的生成损失值,并根据所述生成损失值更新所述视频合成模型的网络参数。
31、第二方面,提供了一种视频合成装置,包括:
32、数据获取单元,用于获取指定的初始图像,及与待合成视频匹配的多模态条件信息,所述多模态条件信息包括与所述待合成视频匹配的音频信息和/或文本描述信息;
33、初始骨架图提取单元,用于提取所述初始图像对应的初始骨架图;
34、第一计算单元,用于以所述多模态条件信息作为控制条件,利用配置的扩散模型在所述控制条件的指导下,生成与所述多模态条件信息语义匹配的连续骨架图,由所述初始骨架图及生成的所述连续骨架图依序组成目标骨架图序列;
35、第二计算单元,用于基于所述目标骨架图序列对所述初始图像的图像特征进行变形,以生成视频序列。
36、第三方面,提供了一种视频合成设备,包括:存储器和处理器;
37、所述存储器,用于存储程序;
38、所述处理器,用于执行所述程序,实现本技术前述第一方面中任一项所描述的视频合成方法。
39、第四方面,提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现本技术前述第一方面中任一项所描述的视频合成方法。
40、第五方面,提供了一种计算机程序产品,该计算机程序产品被有形地存储在非瞬态计算机存储介质中并且包括机器可执行指令,该机器可执行指令在由设备执行时实现本技术前述第一方面中任一项所描述的视频合成方法。
41、本技术提供了一种多模态控制的视频合成方案,针对指定的初始图像,用户可以从音频、文本描述等模态的角度提出合成限制条件,示例如针对给定的初始图像,用户可以提供该图像的描述文本如“正在跳芭蕾的女孩”,或者提供背景音乐如“芭蕾舞的背景音乐”,在此基础上,本技术可以提取初始图像的初始骨架图,以多模态条件信息作为控制条件,利用扩散模型在该控制条件的控制下,生成与多模态条件信息语义匹配的连续骨架图,由初始骨架图和生成的连续骨架图组成目标骨架图序列,进而可以利用该目标骨架图序列对初始图像的图像特征进行变形,以生成视频序列。显然,本技术提供的方案支持用户通过多种模态信息对所要合成的视频进行条件限定,进而可以基于用户提供的多模态条件信息,以及初始图像,采用扩散模型生成与多模态条件信息语义相匹配的连续骨架图,进而合成视频序列,实现了根据用户的合成要求,对初始图像进行视频合成的目的,满足用户个性化的合成需求。
42、并且,本技术创造性的提出了一种全新的视频合成流程,即先生成与多模态条件信息语义相匹配的连续骨架图,再基于连续骨架图合成视频序列,保证了视频合成效果。
- 还没有人留言评论。精彩留言会获得点赞!