一种通信网络下数字人驱动视频播放方法与流程
本发明涉及数字人播放领域,尤其涉及一种通信网络下数字人驱动视频播放方法。
背景技术:
1、数字人驱动视频播放是指使用计算机技术和人工智能算法来创建和操控虚拟人物在视频中进行各种动作和表情;这项技术可以根据特定的指令和数据生成高度逼真的虚拟角色,并使它们在视频中表现出生动的动作和表情;首先,通过捕捉真实人类的动作和面部表情数据,数字人技术可以将这些数据与算法相结合,创建一个虚拟人物;该虚拟人物可以模仿真实人类的动作,并根据算法来实现逼真的面部表情;这意味着我们可以通过数字人技术,使用计算机生成一个看起来与真实人类非常相似的虚拟角色;数字人技术的一个重要应用是在视频制作中;通过将数字人与视频场景结合,我们可以实现从未有过的创作自由度和效果;虚拟角色可以代替真实演员来进行危险或特殊效果的场景,这可以降低拍摄成本并保护演员的安全;此外,数字人技术还可以对角色进行各种修改和定制,使得视频制作更加灵活和创新;随着计算机技术和人工智能的不断进步,数字人技术的应用前景非常广泛;它不仅可以用于电影和电视剧的制作,还可以应用于广告、游戏和虚拟现实等领域;数字人技术的发展和应用将会极大地改变影视娱乐产业,并引领未来的视频创作潮流;现有技术通过在用户输入指令之后,将指令在预先录入的数据库中进行搜索,并将匹配的结果输出,相当于根据语音选择不同的视频进行播放,当面对复杂环境和复杂的指令时,无法及时有效的作出应对,且为了对更多的指令作出回应,需要预先制作大量的视频和响应的数据,对设备的储存性能要求高。
技术实现思路
1、为了克服通过在用户输入指令之后,将指令在预先录入的数据库中进行搜索,并将匹配的结果输出,相当于根据语音选择不同的视频进行播放,当面对复杂环境和复杂的指令时,无法及时有效的作出应对,且为了对更多的指令作出回应,需要预先制作大量的视频和响应的数据,对设备的储存性能要求高的问题。
2、本发明的技术方案为:一种通信网络下数字人驱动视频播放方法,包括有以下步骤:
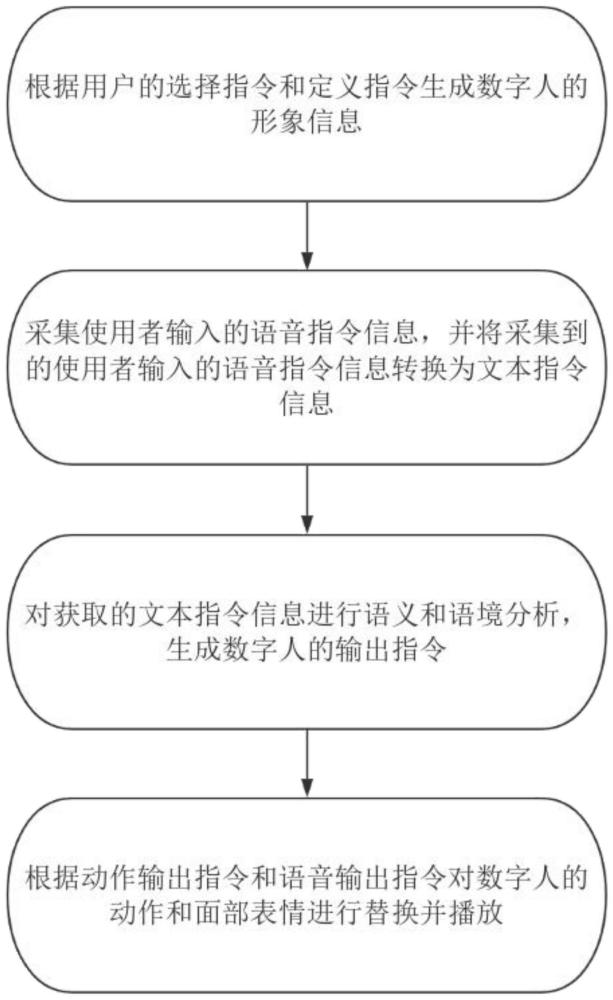
3、s11:根据用户的选择指令和定义指令生成数字人的形象信息,其中数字人的形象信息包括有数字人的性别、数字人的身高、数字人的胖瘦、数字人的外貌、数字人的衣服和数字人视频的背景;
4、s12:采集使用者输入的语音指令信息,并将采集到的使用者输入的语音指令信息转换为文本指令信息;
5、s13:对获取的文本指令信息进行语义和语境分析,生成数字人的输出指令,其中数字人的输出指令包括有动作输出指令和语音输出指令;
6、s14:根据动作输出指令和语音输出指令对数字人的动作和面部表情进行替换并播放。
7、优选的,相对于现有技术通过在用户输入指令之后,将指令在预先录入的数据库中进行搜索,并将匹配的结果输出,相当于根据语音选择不同的视频进行播放,当面对复杂环境和复杂的指令时,无法及时有效的作出应对,且为了对更多的指令作出回应,需要预先制作大量的视频和响应的数据,对设备的储存性能要求高,该方法通过对文本指令信息进行语义和语境分析,使得计算机理解用户的输入指令,再根据输入指令判断不同的表情和动作信息,并将表情和动作信息与监理的数字人模型进行合成,不需要预先制作,且使用范围更广,更加智能化,并具有一定的学习能力,适应性更强。
8、作为优选,在采集使用者输入的语音指令信息,并将采集到的使用者输入的语音指令信息转换为文本指令信息时,包括以下步骤:
9、s21:预先录入用户设定的语音唤醒指令;
10、s22:对用户的音频信息进行收集,并将音频信息与语音唤醒指令进行比对;
11、s23:当用户的音频信息中的某一段与语音唤醒指令的相似度达到85%时,开始对语音指令信息的处理;其中,从识别到的语音唤醒指令之后直至收集到的音频信息小于30分贝持续1s,将此时间段之内的音频信息判断为语音指令信息;
12、s24:将语音指令信息转换为文本指令信息。
13、作为优选,在将语音指令信息转换为文本指令信息时,包括以下步骤:
14、s31:将采集到的语音指令信息利用声卡转换为数字化语音模拟信号,其中,采样频率大于信号中最高频率的两倍,表达公式为:fsmax≥2*fmax;其中,fmax为用户语音频率的最大值,fmax设置为4000赫兹,采样频率设置为8000赫兹;
15、s32:对数字化语音模拟信号进行预处理,剔除数字化语音模拟信号中的高频部分,并采用半帧交叠的方式将数字化语音模拟信号进行分帧;
16、s33:对预处理后的数字化语音模拟信号进行特征提取;
17、s34:利用隐马尔可夫模型模板匹配法对提取出来的数字化语音模拟信号的特征进行匹配,从而实现将语音指令信息转换为文本指令信息。
18、作为优选,在对预处理后的数字化语音模拟信号进行特征提取时,包括以下步骤:
19、s41:利用加窗处理除去每一帧语音信号中的gibbs效应公式;其中,加窗处理的数学表达式为:sω(n)=y(n)*ω(n);其中sω(n)为加窗处理之后的语音信号,y(n)为预加重处理之后的语音信号,0≤n≤n-1;
20、s42:对经过加窗处理后的语音信号sω(n)进行离散傅里叶变换,得到频谱系数;
21、s43:将得到的频谱系数进行利用三角滤波器进行滤波处理,得到每个滤波器输出的对数能量;
22、s44:对滤波器输出的对数能量进行离散余弦变换,得到mfcc参数;
23、s45:以该帧的归一化能量和得到的mfcc参数中舍弃第一组组成13维特征向量c;
24、s46:将得到的13维特征向量c进行差分得到δc和δδc,将c、δc和δδc组成39维特征向量,最终得到mfcc特征参数。
25、优选的,取每个临界带内所有信号幅度加权和作为某个临界带滤波器的输出,然后对所有滤波器输出作对数运算,形成一个矢量,然后作离散余弦变换即得到mfcc参数,mfcc从人耳对频率高低的非线性心理感觉角度反映了语音短时幅度谱的特征,因而识别性能和抗噪性能均明显优于传统的线性预测参数。
26、作为优选,在将用户的语音指令信息转换为文本指令信息后,还包括以下步骤:
27、s51:把识别到的文本分割成完整的句子;
28、s52:对分割出来的完整的句子,进行分词、词性标注及过滤停用词,将名词、动词和形容词保留下来,形成候选关键词;
29、s53:利用n-gram模型对每个关键词在语句中出现的概率p进行计算;
30、s54:当概率p小于30%时,将该语句的前两句语句加入n-gram模型,进行计算,若该关键词出现的概率大于35%,则判断该关键词无问题;若该关键词出现的概率小于35%,则返回值步骤s33,重新进行特征匹配。
31、优选的,语言模型描述的时语言学中词与词在数学上的关系,包括词与词之间的语法规则和使用规律,在语句中,一个词在语句中出现的概率依赖于语句的整体语境,而语句的整体语境是由语句中的词语构成的,因此一个词在语句中出现的概率可以由同句话中其他的词进行分析判断,利用n-gram语言模型可以简单有效的分辨出语句中词语与词语之间的关系,从而可以对词语进行简单有效的分析和判断。
32、作为优选,在对获取的文本指令信息进行语义和语境分析时,包括以下步骤:
33、s61:对得到的文本指令信息进行文本分割,根据从网络或者相关自定义数据中的词语信息和语句信息,将文本指令信息的文本分割成多个单独存在的词语,形成文本词语集;
34、s62:去除文本词语集中的非必要词语;其中,非必要词语包括有停用词和结巴分词;
35、s63:将文本词语集中的词语标准化;其中,包括扩写缩写词、将具有近似示的词语转换为统一的词语以及对将未知词语利用网络进行搜索,并将其转换为已经记载的词语或者短语;
36、s64:对文本进行句法分析;其中,采用基于深度学习的句法分析自然语言理解模型nlu对文本进行句法分析;
37、s65:根据句法和标准化后的文本词语集在网络或其他相关平台上进行检索。
38、作为优选,在生成数字人的输出指令时,包括以下步骤:
39、s71:根据步骤s51-s55中所检索后的结果,判定数字人需要进行的反应,其中数字人需要进行的反应包括有回复语音、回复动作以及回复动作和语音;
40、s72:根据回复语音指令中所需要回复的文本信息,在数据库中对该语音文本信息中每个字节的唇形进行搜索,并将唇形图像合成;
41、s73:将回复语音指令中所需要回复的文本信息在预先设定的表情库中进行搜索,当匹配成功后,确定表情图像,输出表情图像指令。
42、作为优选,在判定数字人需要进行的反应时,当数字人需要进行的反应为回复动作或回复动作和语音时,包括以下步骤:
43、s81:采集对应的网络或者预先录入的视频图像,并对视频图像进行人像轮廓识别和划分;
44、s82:根据识别和划分的人像轮廓图像,利用识别模型对人像轮廓图像的关键点进行检测和识别;
45、s83:建立二维坐标系,根据关键点的位置确定关键点的坐标,根据关键点的位置和图像信息对关键点进行分类;
46、s84:将同一个关键点在每一帧图像中的位置坐标进行连接,形成该关键点的运动轨迹;
47、s85:根据不同关键点的运动轨迹生成不同的回复动作指令。
48、作为优选,在根据动作输出指令和语音输出指令对数字人的面部表情进行替换并播放时,包括以下步骤:
49、s91:将步骤s62中合成的唇形图像黏贴在根据步骤s11中用户指令建立的无表情的数字人的人脸部分中的唇部区域,且根据数字人的唇形特征对唇形图像进行扭曲和变形;
50、s92:进行唇部区域超分提升唇部区域的贴合度、真实度和清晰度;
51、s93:对数字人的人脸部分进行变形,在无表情的数字人的人脸部分中加入表情信息;其中加入表情信息的数学表达式为:
52、
53、其中,表示平均人脸,aid表示人脸的身份基,αid表示为身份基的系数,aex表示人脸的表情基,αex表示表情基的系数;其中,aid和αid根据步骤s11中用户输入的数字人的性别、数字人的身高、数字人的胖瘦、数字人的外貌进进行确定。
54、作为优选,在根据用户的选择指令和定义指令生成数字人的形象信息时,包括以下步骤:
55、s101:建立人体模型,其中人体模型为无指令情况下的人体轮廓模型;
56、s102:根据用户所输入的数字人的性别、数字人的身高和数字人的胖瘦对人体模型进行拉伸变形,使得人体模型的轮廓与用户输入的指令一致;
57、s103:根据用户所输入的数字人的外貌对人体模型的面部进行建模,其中,对人体模型的面部进行建模的数学表达式为:
58、s104:根据用户输入的数字人的衣服及步骤s102中建立的人体模型,对数字人的衣服进行变形,并将变形后的数字人的衣服套设在人体模型的外部;
59、s105:将建立好的人体模型导入用户选择的数字人视频的背景的图层之上,完成数字人的建模。
60、优选的,通过将数字人的面部分布平均人脸、身份基和表情基,使得用户可以自定义更多的人脸,且对于用户自定义的不同的人脸均可根据不同的情况加入不同的表情,且表情更加自然且和谐,不会出现人脸与表情分离的情况发生,且脱离了数据库的限制,不需要占用大量的储存空间,同时表情和外貌特征的选择更加多样化。
61、本发明的有益效果:
62、1、相对于现有技术通过在用户输入指令之后,将指令在预先录入的数据库中进行搜索,并将匹配的结果输出,相当于根据语音选择不同的视频进行播放,当面对复杂环境和复杂的指令时,无法及时有效的作出应对,且为了对更多的指令作出回应,需要预先制作大量的视频和响应的数据,对设备的储存性能要求高,该方法通过对文本指令信息进行语义和语境分析,使得计算机理解用户的输入指令,再根据输入指令判断不同的表情和动作信息,并将表情和动作信息与监理的数字人模型进行合成,不需要预先制作,且使用范围更广,更加智能化,并具有一定的学习能力,适应性更强;
63、2、语言模型描述的时语言学中词与词在数学上的关系,包括词与词之间的语法规则和使用规律,在语句中,一个词在语句中出现的概率依赖于语句的整体语境,而语句的整体语境是由语句中的词语构成的,因此一个词在语句中出现的概率可以由同句话中其他的词进行分析判断,利用n-gram语言模型可以简单有效的分辨出语句中词语与词语之间的关系,从而可以对词语进行简单有效的分析和判断;
64、3、通过将数字人的面部分布平均人脸、身份基和表情基,使得用户可以自定义更多的人脸,且对于用户自定义的不同的人脸均可根据不同的情况加入不同的表情,且表情更加自然且和谐,不会出现人脸与表情分离的情况发生,且脱离了数据库的限制,不需要占用大量的储存空间,同时表情和外貌特征的选择更加多样化。
- 还没有人留言评论。精彩留言会获得点赞!