一种基于Quic协议的丢包检测系统及丢包检测方法
本发明涉及一种丢包检测系统及丢包检测方法,尤其涉及一种基于quic协议实时丢包检测系统和方法。
背景技术:
1、quick udp internet connections (quic)是一种实验传输协议,主要用于减少连接建立和传输延迟,以及在基于http的应用程序中使用默认的端到端加密来改进安全标准。更具体地说,quic的出现是由于传输层迫切需要创新,主要是由于tcp扩展和部署新协议的困难。因此,quic的开发必须采用不同的方法来避免即将发生的身份验证,即无法部署更新和修复。这些考虑已经导致quic的迅速普及。自 2016对quic早期大规模实验以来,quic 的流量份额已经达到欧洲一级 isp的 7% 以上,它构成了google出口流量的 30% 以上。
2、quic在用户空间中实现,封装在udp中运行,它的灵感来自几个协议和扩展的最佳实践,如tcp、tls 1.3和http/2。quic旨在通过在连接设置时直接发送数据的可能性来减少连接延迟。在内部,quic数据包有一个未加密的公共报头和一个加密的有效负载,它可以包括一个或多个帧。同一数据包中的帧可能携带控制或数据信息,可能属于相同或不同的流,即流复用。在丢包的情况下,只有丢失包中有帧的流被阻塞,其他流不受影响。这是quic的主要优点之一,因为它避免了多个流的hol阻塞。然而,如果丢失的数据包包含来自多个流的帧,那么需要减少与重传相关的延迟。
3、tcp将传输包中的数据的偏移量和包号合并在一起,这样就导致无法区分第一次发送包和重传包。而quic将两者区分开,包号用于确定传输顺序,应用数据由stream帧中的偏移量字段决定。quic包号是严格递增的,直接说明传输顺序。当一个包确认丢失后,包中的帧会在一个新的包中用新的包号进行传输,解决了重传二义性的问题。因此,使用包号,rtt估计将更加准确,虚假重传容易探测,快重传能够广泛的部署。与tcp的sack只有三个sack块不同,quic的ack帧包含很多ack块。在高丢包率的场景,这能加速恢复,减少伪重传,确保数据包转发进度。
4、目前大规模使用的tcp丢包恢复机制主要有 ack 触发和定时器触发两种。
5、ack触发。服务端发送数据到达用户后,客户端会回复 ack 包来表明已经顺序收到的数据包序列号以及期待下一个收到的数据包序列号,因此衍生出由 ack 触发的丢包恢复。
6、(1)快速恢复 (fast recovery):快速恢复通过监控是否有重复 ack(dupack)作为探测触发条件。当接收到的 dupack 达到设置的确定阈值时,便开始重传最老的数据包;
7、(2)fack(forward acknowledgment):当ack携带了sack选项,在fack模式下,重传时机定义为被sack的数据报数量 + 空洞数 > reordering(乱序容忍度)。当满足上述条件时,便开始重传数据包;
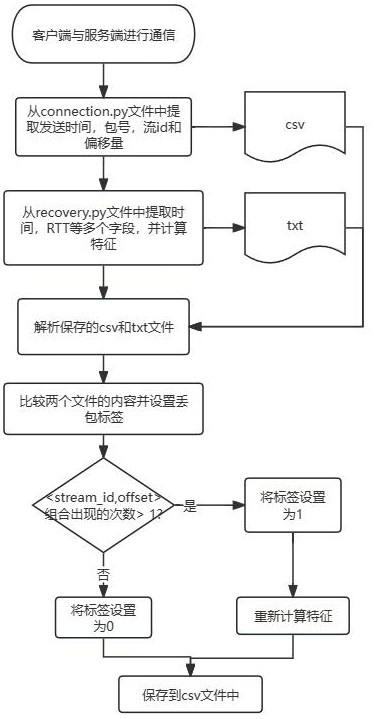
8、(3)rack(recent acknowledgment):rack中利用 ack 触发丢包恢复的部分——使用最近投递成功的数据包的发送时刻来推测在此数据包之前传输的未被确认的数据包是否在传输过程中丢失。当预测为丢失时,便开始重传数据包。
9、定时器触发。当没有足够的 ack 回复或者快速恢复方法没有成功预测到数据包的丢失,将只能依靠定时器进行丢包恢复,在加密重传计时器、尾部探测计时器和重传超时机制之间切换。ack 触发的丢包恢复有:定时器触发的丢包恢复有:
10、(1)rto:设置定时器,当某数据包超过定时器时间仍未被确认收到,则触发rto重传同时会重传所有un-acked数据包;
11、(2)rack 中利用定时器重传的部分:利用最近投递成功的数据包的发送时刻以及根据有 ack 回复时计算出的整体乱序程度为 un-acked 数据包设置超时定时器,定时器超时则重传该数据包即可。
12、但是这些丢包探测的算法有很多不足之处:
13、(1)快速恢复:发送方未必可以收到三个及以上的 dupack 来触发快速恢复同时无法检测到同一个拥塞窗口内发生的多个数据包丢失的情况;
14、(2)fack:fack 虽然在一定程度上解决了快速恢复需要依赖多个 dupack 才能触发恢复以及无法预测整个拥塞窗口内多个数据包同时丢失的问题,但是同样带来了新的问题:
15、a)基于人工经验进行设计,使用一个变量来维护空间上的差异。但是又缺乏从时间维度上对数据包的分析,对丢包探测的准确率较低;
16、b)reordering(乱序容忍度)在一条网络连接中只增不减,无法应对网络的突然变化;
17、c)并不能对重传包进行丢包的再一次探测,需要使用额外的方法进行重传包的丢包探测。
18、(3)rack:rack 在一定程度上解决了 fack 无法对重传包进行丢包再次探测的问题但是仍有一些问题没有解决:
19、a)同样基于人工经验进行设计,利用经验来进行丢包的快速恢复;
20、b)rack 是完全基于时间的一种丢包探测方法,由于内核的计时采用 jiffies 模式,所以在传输过程中 rtt 是无法被精确计算的同时又放弃了空间维度方面对于网络情况的反映,因此也不能很好地适应网络的快速变化。
21、(4)rto:丢包恢复时间太长,会严重影响整体的传输时间。
22、上面分析了现有大规模使用的丢包恢复方法所存在的不足,这些不足都是造成丢包探测出现 rto 占比过高以及出现部分 dsack 的原因同时也是导致实际 fct和理论fct 之间较大差距的原因。
23、quic发送端也是通过ack信息和超时来检测包丢失:
24、(1)在基于ack丢包探测中,quic发送方使用ack来检测丢失的数据包,并使用pto来确保收到确认。它实现了tcp的快速重传、早期重传、前向确认(fack)、sack丢失恢复和rack-tlp的原理。如果数据包丢失,quic传输需要从丢失中恢复,例如通过重传数据、发送更新的帧或丢弃帧。与rtt测量和拥塞控制不同,丢失检测在每个包号空间是独立的,因为rtt和拥塞控制是路径的属性,而丢失检测也依赖于密钥可用性。为了尽可能的实现快重传而不是超时重传,quic采用了tail loss probes (tlps)实现某些情况下的快重传机制触发。数据包丢失不仅导致重传耗时,还会使拥塞窗口变小,从而降低吞吐量,影响了数据传输速度。谷歌在quic早期采用了前向纠错码(forward-error correction)来减少包丢失现象。在一个group中带上一个额外的fec包(n+1个包),分组中任意一个包丢失,都可以用其余n个包来恢复。这种做法同时也带来了冗余,可能每10个包中就要额外传输1个冗余包,在网络状况好的时候是一种浪费,目前谷歌已经废弃了quic的fec功能。
25、在基于时间探测中,加密超时重传机制对于quic来说是至关重要的。quic使用pto,带有一个基于tcp重传超时(rto)计算的计时器看到的。quic的pto包括对端的最大预期确认延迟,而不是使用固定的最小超时。与tcp的rack-tlp丢失检测算法类似,quic在pto到期时不会崩溃拥塞窗口,因为在尾部的单个数据包丢失并不表示持续拥塞。相反,当声明持续拥塞时,quic会关闭拥塞窗口。这样做,quic避免了不必要的拥塞窗口减少,避免了对纠错机制(如forward rto-recovery (frto))的需要。由于quic不会在pto过期时崩溃拥塞窗口,因此如果pto过期后仍然有可用的拥塞窗口,quic发送方不受限制,可以发送更多的in-flight数据包。当发送方受到应用程序限制并且pto计时器过期时,就会发生这种情况。在应用程序受限的情况下,这比tcp的rto机制更具侵略性,但在不受应用程序限制的情况下是相同的。quic允许探测报文在定时器到期时暂时超过拥塞窗口。
26、综上所述,quic官方文档判断quic数据包的条件如下,当quic数据包满足以下所有条件,则声明丢失:
27、1、数据包在传输后未确认,并在已确认的数据包之前发送。
28、2、数据包在公认的数据包之前发送 kpacketthreshold 包,或者它在过去足够长发送。
29、截止为此,有很多对quic进行了性能研究,但是随着人工智能的引入,目前并无利用机器学习的方法对quic协议进行丢包判断。
技术实现思路
1、本发明要解决的技术问题是克服现有技术的不足,提供一种基于quic协议的丢包检测系统及丢包检测方法。
2、为解决上述技术问题,本发明提出的技术方案为: 一种基于quic协议的丢包检测系统,包括数据收集器、特征选择器、丢包学习器和丢包检测器;所述数据收集器收集预设时间内和预设大小的quic传输数据作为初始数据;
3、数据收集器在线下收集服务器和客户端双边的quic传输数据,在线上仅收集服务器侧的quic输数据;数据收集器得到模型训练所需的特征和标签;标签设置步骤为:在收集的数据中根据stream_id和offset,判断数据包是否丢失;stream_id和offset出现的次数大于1,则判定这个数据包丢失,并设置标签为“1”;stream_id和offset出现的次数为1,则判定这个数据包未丢失,并设置标签为“0”;
4、特征选择器通过借鉴fack和rack丢包探测方法,通过数据收集器得到的模型训练所需的特征,利用决策树模型来寻找最优特征子集;
5、所述丢包学习器:学习和训练从特征选择器和数据收集器传递而来的特征,形成可以进行quic丢包探测的inceptiontime模型或者inceptiontimeplus模型,并对实现在aioquic协议栈中的丢包探测的inceptiontime模型或者inceptiontimeplus模型进行动态的替换;
6、所述丢包检测器:在inceptiontime模型或者inceptiontimeplus模型中输入数据包探测所需的特征集合,得到inceptiontime模型或者inceptiontimeplus模型计算得到的丢包探测结果;结果为0则表示数据包未丢失,结果为1则表示数据包丢失;数据包探测所需的特征集合包括rtt_variance、ratio_time、 sacked_out和order_out;
7、上述的基于quic协议的丢包检测系统,优选的,所述数据收集器、特征选择器和丢包学习器离线训练,所述丢包检测器在线部署。
8、上述的基于quic协议的丢包检测系统,优选的,所述模型训练所需的特征包括ack_rtt、smooth_rtt、rtt_variance、elapsed_time、ratio_time、sack_holes、sacked_out、order_out中的至少两个;
9、一种基于quic协议的丢包检测方法,包括以下步骤;
10、1)数据收集器收集预设时间内和预设大小的quic传输数据作为初始数据;初始数据由空间维度数据和时间维度数据组成;数据收集器获取的packet number、stream_id和offset这些字段以csv文件保存下来,命名为csv文件1;从另一个底层代码文件中获取packet number、rtt字段,同时计算特征rtt_variance、ratio_time、 sacked_out和order_out,并将计算结果和提取的字段以txt文件1保存下来;
11、2)数据收集器解析步骤1)中的csv文件1和txt文件1,获得stream_id和offset出现的次数;若是stream_id和offset这个组合出现的次数为1次,则判定这个数据包未丢失,并设置标签为“0”;若是出现的次数大于1次,则判定这个数据包丢失,并设置标签为“1”,;将结果保存到csv文件中;命名为csv文件2;
12、3)特征选择器则根据fack和rack丢包探测方法,从数据收集器得到模型训练所需的特征,模型训练所需的特征包括ack_rtt、smooth_rtt、rtt_variance、elapsed_time、ratio_time、sack_holes、sacked_out、order_out中的至少两个;使用决策树模型进行分类操作从而确定每一个特征所占有的权重,以 gini 指数或者 entropy作为节点判别条件,得到丢包预测所需要的特征;丢包预测所需要的特征包括 rtt_variance、ratio_time、sacked_out和order_out,确定四个变量 rtt_variance、ratio_time、 sacked_out和order_out作为模型进行丢包预测所需要的特征;
13、4)丢包学习器学习和训练从特征选择器和数据收集器处传递而来的特征,将特征与标签组合成四元组,形成inceptiontime模型或者inceptiontimeplus模型进行训练和转换的数据集,四元组为rtt_variance、ratio_time、 sacked_out、order_out和loss,然后利用这些特征数据训练inceptiontime模型或者inceptiontimeplus模型,形成可以进行quic丢包探测的模型,并定时对实现在aioquic协议栈中的丢包探测模型进行动态的替换;
14、5)丢包检测器在inceptiontime模型或者inceptiontimeplus模型中输入数据包探测所需的特征集合,得到inceptiontime模型或者inceptiontimeplus模型计算得到的丢包探测结果;结果为0则表示数据包未丢失,结果为1则表示数据包丢失;数据包探测所需的特征集合包括rtt_variance、ratio_time、 sacked_out和order_out;
15、6)执行器则根据丢包检测器所给出的丢包探测结果为基础,若是判断为丢包则做出快速重传,否则什么也不做。
16、上述的基于quic协议的丢包检测方法,优选的,对所述步骤2)中保存到csv文件2中的结果进行核验;
17、①在数据传输的服务端和客户端分别采用tcpdump命令来捕获数据,生成pcap文件;
18、②在服务端利用wireshark工具对捕获的数据包进行解析,导入秘钥进行解密,然后将解析后的文件以json的文件保存下来;
19、③解析json文件,提取字段packet number,stream_id和offset;根据stream_id和offset出现的次数来判断数据包有没有丢失,最后保存到csv文件中,命名csv文件3;若是stream_id和offset这个组合出现的次数为1次,则判定这个数据包没有丢失,并设置标签;若是出现的次数大于1次,则判定这个数据包丢失,并设置标签;
20、④比对csv文件2和csv文件3中的数据,核验csv文件2中数据的准确性。
21、与现有技术相比,本发明的优点在于: 本发明的基于quic协议的丢包检测系统和方法,相比于现有的基于经验的网络特征提取方法,本发明抓包数据和数据挖掘的方法直接提取与网络丢包最相关的数据包空间和时间特征。其次,相比现有基于经验阈值的丢包识别算法设计,本发明利用深度学习模型更大程度地利用了与丢包相关的网络特征用于丢包识别,从而提升对于丢包预测的准确度。通过线下实验以及交叉验证,相比与传统算法,这个方案可以实现更高的查全率和查准率。
22、本发明还提出了丢包识别算法的动态优化方案。针对不同的服务器在不同时间段采集的网络数据实现了自适应的丢包识别算法的更新,使得模型可以不断保持符合当前网络环境的丢包恢复策略。
- 还没有人留言评论。精彩留言会获得点赞!