一种基于夏普利值的异构VLC/RFV2V智能资源分配方法
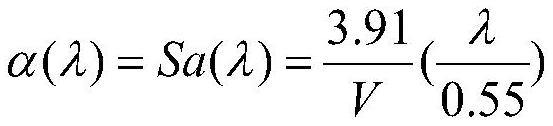
本发明涉及可见光车载通信领域,尤其是一种引入了博弈论和强化学习的概念的一种基于夏普利值的异构vlc/rf v2v智能资源分配方法。
背景技术:
1、可见光通信是使用发光二极管发射的可见光作为无线通信的载体的通信方式,其具有无授权频谱、无电磁干扰、高带宽、保密性强等优点,因此被认为是车与车之间近距离射频无线通信技术的一种很有前途的补充技术。因此,近年来有关异构vlc/rf车载通信网络受到研究者们的广泛关注。研究者们提出了不同的vlc/rf混合通信系统模型并从不同角度对系统性能进行了分析,现有的异构vlc/rf车载通信网络有着通信方面的局限性,其中较明显的是车载自组织网络中车辆节点之间通信质量较低,传输速率受限,且使用传统的智能算法收敛性低,制约着使用可见光通信时车载网络中车辆之间的通信效率。
技术实现思路
1、本发明需要解决的技术问题是提供一种基于夏普利值的异构vlc/rf v2v智能资源分配方法,以解决车载自组织网络中车辆节点之间通信质量较低,传输速率受限,传统智能算法收敛性低的问题,可以提升车辆网络性能,保证算法模型的收敛性,使其能够找到最优策略。
2、为解决上述技术问题,本发明所采用的技术方案是:一种基于夏普利值的异构vlc/rf v2v智能资源分配方法,利用博弈论中夏普利值边际贡献的特点,促进智能体之间的合作行为,由每辆车对车载网络的贡献来决定在训练过程中的q值,将异构车组网通信中每辆车设为一个智能体,由车辆自主选择信道,并优化rf和vlc的发射功率,选择合适的功率等级,进一步降低信道之间的干扰,在不牺牲一个或多个智能体性能的同时确保整个车辆网络性能收敛到最优解,以提高v2v网络通信质量以及稳定性,具体步骤如下:
3、步骤1:vlc信道噪声分析;
4、步骤2:rf信道噪声分析;
5、步骤3:建立信道功率控制模型;
6、步骤4:建立信道功率控制算法。
7、本发明技术方案的进一步改进在于:步骤1异构车组网通信中,任意车辆之间接受光功率可表示为:
8、pr=pt*h(0)*exp[-α(λ)d]
9、其中α(λ)为可见光随波长变化的光强衰减系数,h(0)为发射端到接收端的直射链路信道增益,d为链路发射端到接收端之间的距离;其中α(λ)=sa(λ),可由下式给出:
10、6km≤v≤10km其中λ为可见光波长;v为大气能见度取6-10km;
11、
12、其中a为pd有效面积;为辐照度角即出射角;φ为入射角,且为光滤波器增益;r为路径损耗指数;m和分别为郎伯发射阶数和光学集中器增益,可由下式给出:
13、
14、
15、其中φ1/2为半功率角;η为光学集中器反射指数;为接收机视场角;σ2为总的噪声和干扰能量;
16、
17、其中为接收机产生的热噪声功率,
18、
19、其中k为玻尔兹曼常数;tk为绝对温度;g开环电压增益;η为单位面积上的固定电容;i2和i3为噪声带宽因子;b为噪声带宽;γ为晶体管fet信道噪声因子;gm为fet跨导;为车辆网络内邻近车辆vlc信道所产生的背景光噪声功率,可由下式给出:
20、
21、其中q为电子电荷量;pbg为背景光噪声功率;pbg=pnδλtsan2;pn为滤波器单位光带宽幅度;δλ为光带通滤波器带宽;ts为滤波器透射系数;n为介质折射率;最后得到发射端车辆与接收端车辆节点之间的vlc信道信噪比为:
22、
23、其中μ为光电转换常数。
24、本发明技术方案的进一步改进在于:步骤2任意两车辆间传播路径损耗为:
25、
26、其中a为路损指数;b为路损频率依赖性系数;c为截距系数;fc为rf中心载波频率,单位为ghz;
27、通过引入相邻车辆干扰能量更准确计算信噪比,发射端车辆i与接收端车辆节点j之间的信噪比为:
28、
29、其中pt(i)及pt(n)为rf发射端车辆i和邻居车辆n的发射功率;为发射端车辆i与接收端车辆节点j之间的信道增益;in为背景干扰噪声功率;n为车辆节点i的邻居车辆数量;为来自相邻车辆rf信道的干扰;hin为发射端车辆i与邻居车辆节点n之间的信道增益。
30、本发明技术方案的进一步改进在于:步骤3具体步骤如下:
31、步骤3.1:在q学习中使用表格来存储每个状态s下采取动作a获得的奖励,即状态动作值函数.即:
32、
33、其中p(s'|s,a)为状态s在执行动作a的情况下转移到状态s′的概率;r为状态s在执行动作a的奖励;v(s',π*)为状态价值函数,即
34、
35、其中π*(s')为智能体收敛后的最优策略;
36、深度q网络采用价值函数近似的表示方法,在学习过程中智能体根据策略π采取行动,π是从状态空间s到动作空间a的映射,表示为π:st∈s→at∈a,行动空间跨越了信道和功率两个维度,在at∈a的一个行动对应于对v2v链路的信道和功率的选择;
37、使用学习算法获取最优策略π,即使长期累积折扣奖励最大化,使其逐渐向目标网络靠近在学习过程中输入状态-动作对,定义为从状态s开始,采取行动a,然后遵循策略π的预期收益,其中动作价值函数如下所示:
38、π′优于π;
39、训练过程中最优q迭代过程为一个马尔可夫过程,可由下式给出:
40、
41、其中χ为折扣因子;α为学习率;st,at和rt分别表示t时刻智能体的状态,动作和奖励;st+1表示t+1时刻的状态;在马尔可夫过程中,如果动作空间中的每个动作在无限次运行中在每种状态下执行无限次,并且学习率α适当衰减,则q值将以概率1收敛到最优q*,确定了最优q值q*即可确定最优策略π*,即:
42、
43、在v2v资源分配场景中,确定最优策略π*后,将其用于为车v2v链路选择信道和传输功率等级,使整体容量最大化,并保证车v2v链路的时延约束;
44、步骤3.2:引入夏普利值,夏普利值是解决大联盟收益分配问题的方法,给定一个合作博弈γ=(n,v),对于任意智能体i的夏普利值可写成
45、
46、其中v(k∪{i})-v(k)为边际贡献;k为车辆网络车辆总数;n为邻居数;
47、夏普利值作为策略更新,对应强化学习中的状态-动作值函数,即q(s,a),可得到
48、
49、基于夏普利值的q函数:
50、
51、在多智能体框架下,每个智能体进行参数共享,以最小化回归损失函数共同更新:
52、
53、
54、其中θi为目标q网络的参数集;目标q网络的参数集从训练q网络参数集θ中周期性地复制出来,并进行更新;经验回放通过对存储的经验进行重复采样,提高了采样效率,打破了连续更新中的相关性,从而稳定了学习。
55、本发明技术方案的进一步改进在于:步骤4具体步骤如下:
56、步骤4.1:设置观察空间,在环境值s内含所有的信道状态和智能体的动作,智能体通过观测函数了解环境,观测空间包含:当前agent的信道信息,rf相邻信道之间的干扰,vlc背景光和信号光的干扰,此外,局部观测空间还包括v2v速率,信噪比,局部观测空间表示为:
57、
58、其中ik(n)是智能体k邻居n的rf射频干扰,是智能体k邻居n的vlc干扰,v2v_ratek智能体k当前时刻下的v2v速率,v2v_sinrk智能体k当前时刻下的v2v信噪比,v2v_channelk智能体k当前时刻下的v2v信道状态即当前信道选择结果;将每个智能体的策略变化都包括在对一个agent k的观察空间,表示为
59、
60、步骤4.2:设置动作空间,车载链路的资源共享设计归结为车v2v链路的信道选择和传输功率控制,其中信道分为[rf,vlc],将功率控制选项限制在四个级别,即[10,15,20,25]dbm动作空间的维度为4×2,每个动作对应于信道和功率选择的一个特定组合;
61、步骤4.3:设置奖励,在v2v信道分配和功率控制的问题中,目标是在一定时间内在不牺牲局部性能的情况下最大化v2v传输速率的同时增加v2v通信质量;将所有v2v链路的瞬时容量总和定义为ck[n,t],包含在每个时间步t的奖励中,对于每个智能体k,将奖励lk设置为有效的v2v传输速率每个时间步t的v2v相关奖励设置为
62、
63、其中n为当前时间步下智能体k的邻居数量,ck[n,t]表示智能体k在时间步t时邻居n的传输速率,γk[n,t]表示智能体k在时间步t时邻居n的信噪比;在训练中,β是一个需要经验调整的超参数;学习的目标为找到最优策略π*,即从s中的状态到选择a中的每个行动的概率的映射使任何初始状态s的期望收益最大化将每个时间步t的奖励设为
64、
65、其中λ1和λ2为平衡传输速率和信噪比目标的正权重;
66、步骤4.4:设置控制方法。
67、本发明技术方案的进一步改进在于:步骤4.4具体流程为:
68、步骤4.41:初始化状态,环境,车辆信息,初始化参数;
69、步骤4.42:根据agent当前状态st,选择动作ai;
70、步骤4.43:根据奖励函数获得全局奖励r,得到智能体下一状态st+1,将(st,ai,r,st+1)存放在经验池;
71、步骤4.44:当样本数量达到k时:从经验池随机采样b组(st,ai,r,st+1);根据采样计算基于合作博弈的q值;计算dqn损失函数;
72、步骤4.45:更新目标网络以及网络参数。
73、由于采用了上述技术方案,本发明取得的技术进步是:通过引入博弈论和强化学习有效提高了车与车之间异构vlc/rf通信的质量,同时提高了传输速率,并且提高了智能算法的收敛性,避免出现局部最优的情况。
- 还没有人留言评论。精彩留言会获得点赞!