数字人视频生成方法、装置、存储介质及电子设备与流程
本技术属于数字人,尤其涉及一种数字人视频生成方法、装置、存储介质、电子设备及计算机程序产品。
背景技术:
1、随着虚拟现实(virtual reality,vr)、增强现实(augmented reality,ar)和人工智能的快速发展,数字人技术逐渐成为了人机交互领域的重要研究方向。数字人是指通过计算机生成的虚拟人物,可以表现出类似于真实人类的外貌、动作和交互能力。
2、虚拟数字人技术一般分为2d虚拟数字人和3d虚拟数字人两条路线,相对于2d虚拟数字人而言,3d虚拟数字人的展示效果、操作性以及交互性都更优,广泛应用于新闻播报、智能客服、电影制作、游戏开发、虚拟现实、增强现实和在线社交等领域,为用户提供了更加沉浸式和个性化的交互体验。但是,现有技术在制作3d数字人视频时,大部分都需要专业的动画师手动调整数字人动作或者提前设定好各个动作的数字人视频后调用,这种数字人视频生成方法比较繁琐,灵活性较低,且适用范围比较局限。
技术实现思路
1、本技术旨在至少解决现有技术中存在的技术问题之一。为此,本技术提出一种数字人视频生成方法、装置、存储介质、电子设备和计算机程序产品,无需用户手动调整或设计数字人动作即可生成数字人视频,灵活性高,适用范围广。
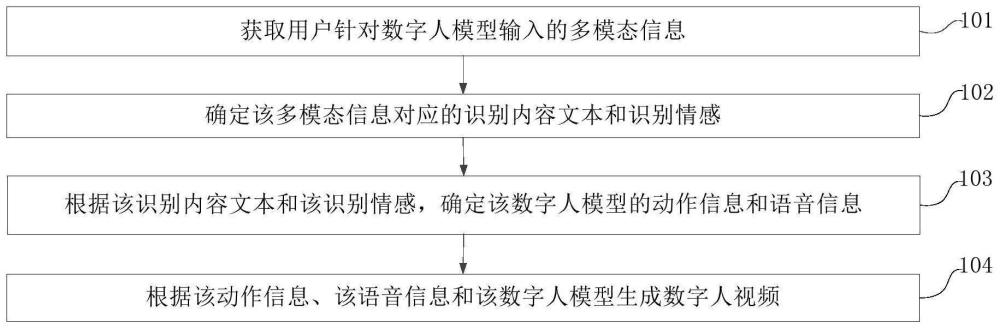
2、第一方面,本技术提供了一种数字人视频生成方法,包括:
3、获取用户针对数字人模型输入的多模态信息;
4、确定所述多模态信息对应的识别内容文本和识别情感;
5、根据所述识别内容文本和所述识别情感,确定所述数字人模型的动作信息和语音信息;
6、根据所述动作信息、所述语音信息和所述数字人模型生成数字人视频。
7、在一些实施例中,所述数字人视频生成方法还包括:
8、通过预设的图像采集阵列和光源阵列,获取针对目标人物拍摄的多张人物图像,不同的所述人物图像是针对所述目标人物以不同的拍摄角度和/或打光颜色拍摄得到;
9、根据所述人物图像生成所述目标人物对应的所述数字人模型。
10、在一些实施例中,所述确定所述多模态信息对应的识别内容文本和识别情感,包括:
11、利用已训练的多模态识别模型对所述多模态信息进行识别,得到所述多模态信息对应的识别内容文本和识别情感。
12、在一些实施例中,所述多模态信息包括视频信息、文本信息、音频信息和/或图像信息,所述利用已训练的多模态识别模型对所述多模态信息进行识别,得到所述多模态信息对应的识别内容文本和识别情感,包括:
13、确定所述多模态信息对应的至少一种信息类型;
14、从已训练的多模态识别模型中确定每种所述信息类型对应的特征提取模块,得到目标提取模块;
15、利用所述目标提取模块对相应信息类型的所述多模态信息进行特征提取,以得到相应的特征向量;
16、利用所述多模态识别模型中的融合识别模块,对所有所述信息类型的所述特征向量进行融合识别处理,得到所述多模态信息对应的识别内容文本和识别情感。
17、在一些实施例中,所述根据所述识别内容文本和所述识别情感,确定所述数字人模型的动作信息和语音信息,包括:
18、根据所述识别内容文本和所述识别情感,确定所述数字人模型中至少一个关键部位的动作信息,所述关键部位包括肢体、脸部和/或头部;
19、根据所述识别内容文本确定所述数字人模型的语音信息。
20、在一些实施例中,所述根据所述动作信息、所述语音信息和所述数字人模型生成数字人视频,包括:
21、根据所述动作信息和所述数字人模型确定待渲染的图像帧序列;
22、根据所述语音信息确定待渲染的音频帧序列;
23、将所述图像帧序列和所述音频帧序列进行融合,得到数字人视频。
24、第二方面,本技术提供了一种数字人视频生成装置,包括:
25、获取单元,用于获取用户针对数字人模型输入的多模态信息;
26、第一确定单元,用于确定所述多模态信息对应的识别内容文本和识别情感;
27、第二确定单元,用于根据所述识别内容文本和所述识别情感,确定所述数字人模型的动作信息和语音信息;
28、视频生成单元,用于根据所述动作信息、所述语音信息和所述数字人模型生成数字人视频。
29、在一些实施例中,所述数字人视频生成装置还包括模型生成单元,用于:
30、通过预设的图像采集阵列和光源阵列,获取针对目标人物拍摄的多张人物图像,不同的所述人物图像是针对所述目标人物以不同的拍摄角度和/或打光颜色拍摄得到;
31、根据所述人物图像生成所述目标人物对应的所述数字人模型。
32、在一些实施例中,所述第一确定单元具体用于:
33、利用已训练的多模态识别模型对所述多模态信息进行识别,得到所述多模态信息对应的识别内容文本和识别情感。
34、在一些实施例中,所述多模态信息包括视频信息、文本信息、音频信息和/或图像信息,所述第一确定单元具体用于:
35、确定所述多模态信息对应的至少一种信息类型;
36、从已训练的多模态识别模型中确定每种所述信息类型对应的特征提取模块,得到目标提取模块;
37、利用所述目标提取模块对相应信息类型的所述多模态信息进行特征提取,以得到相应的特征向量;
38、利用所述多模态识别模型中的融合识别模块,对所有所述信息类型的所述特征向量进行融合识别处理,得到所述多模态信息对应的识别内容文本和识别情感。
39、在一些实施例中,所述第二确定单元具体用于:
40、根据所述识别内容文本和所述识别情感,确定所述数字人模型中至少一个关键部位的动作信息,所述关键部位包括肢体、脸部和/或头部;
41、根据所述识别内容文本确定所述数字人模型的语音信息。
42、在一些实施例中,所述生成单元具体用于:
43、根据所述动作信息和所述数字人模型确定待渲染的图像帧序列;
44、根据所述语音信息确定待渲染的音频帧序列;
45、将所述图像帧序列和所述音频帧序列进行融合,得到数字人视频。
46、第三方面,本技术提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述任一项所述的数字人视频生成方法。
47、第四方面,本技术提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的数字人视频生成方法。
48、第五方面,本技术提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的数字人视频生成方法。
49、本技术实施例提供的数字人视频生成方法、装置、存储介质、电子设备及计算机程序产品,通过获取用户针对数字人模型输入的多模态信息;确定该多模态信息对应的识别内容文本和识别情感;根据该识别内容文本和该识别情感,确定该数字人模型的动作信息和语音信息;根据该动作信息、该语音信息和该数字人模型生成数字人视频,也即用户可以通过输入一段文本、视频、语音等方式直接驱动数字人模型执行所需的动作和发出所需的声音,无需用户手动调整或设计数字人模型动作,方法简单,灵活性高,适用范围广。
- 还没有人留言评论。精彩留言会获得点赞!