一种云上系统全链路故障定位分析方法及系统与流程
本发明涉及云上系统监控,更具体地说,它涉及一种云上系统全链路故障定位分析方法及系统。
背景技术:
1、云上系统是指部署在云计算平台上的应用程序。对于大型的应用程序通常是拆分为成多个微服务部署在云计算平台,随着应用程序的迭代更新,由大量微服务组成的应用程序也逐渐难以管控。
2、现有的微服务链路追踪技术(例如skywalking、zipkin等)用于追踪多个微服务之间的调用情况并形成网络拓扑图,当微服务之间的链路出现异常时,则根据预设的告警规则生成告警消息,并发送给应用程序的后台管理人员,并将异常链路直接显示在网络拓扑图中,从而实现微服务的故障定位。
3、然而现有的微服务链路追踪技术只能根据已经发生异常的链路信息结合预设的告警规则来定位故障,例如skywalking预设的告警规则包括:最近3分钟内服务的平均响应时间超过1秒、最近2分钟服务成功率低于80%等,并无法直接根据链路信息进行提前预警,在故障出现后,需要运维人员进行故障定位以及开发人员进行故障修复,期间可能产生“雪崩效应”,即一个微服务的故障堆积了大量的用户请求,影响到与该微服务存在调用关系的其他微服务的正常运行,从而降低用户对应用程序的使用体验。
技术实现思路
1、本发明提供一种云上系统全链路故障定位分析方法及系统,解决相关技术中现有的微服务链路追踪技术无法直接根据链路信息进行提前预警,存在解决故障的时间延滞性,降低用户对应用程序的使用体验的技术问题。
2、本发明提供了一种云上系统全链路故障定位分析方法,包括以下步骤:
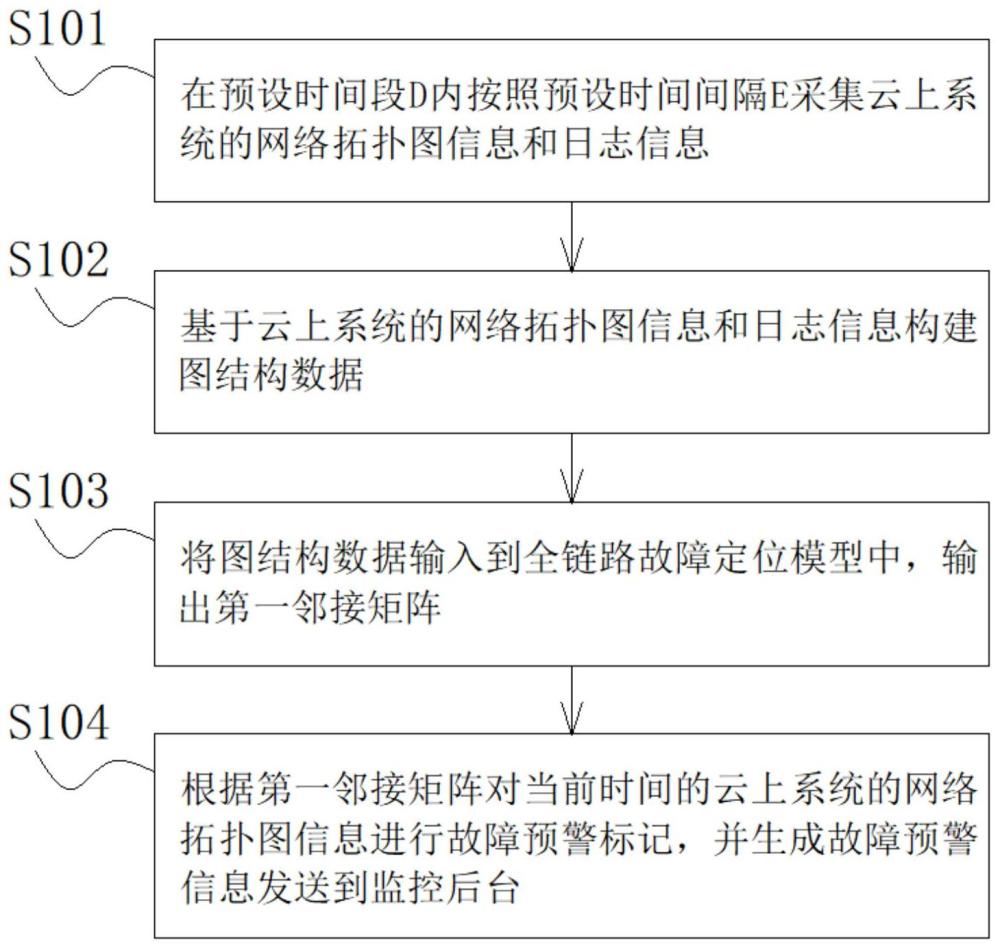
3、步骤s101,在预设时间段d内按照预设时间间隔e采集云上系统的网络拓扑图信息和日志信息;云上系统的每个微服务都分配有一个唯一标识码;
4、网络拓扑图信息包括:微服务之间的调用关系、每分钟请求量、请求成功率、平均响应时间、平均吞吐量、百分比响应和最大延时;
5、日志信息包括:微服务对应虚拟机的cpu占比、内存占用大小、垃圾回收时间、垃圾回收次数和线程数;
6、步骤s102,基于云上系统的网络拓扑图信息和日志信息构建图结构数据;
7、图结构数据包括:节点、节点的初始向量和节点之间的边;
8、节点与云上系统的微服务建立数据联系;
9、节点的初始向量根据节点所数据联系的信息生成;
10、节点之间的边根据云上系统的网络拓扑图信息中的微服务之间的调用关系构建;不同时间间隔的同一节点之间构建边;
11、步骤s103,将图结构数据输入到全链路故障定位模型中,输出第一邻接矩阵;第一邻接矩阵的大小为n*n,其中n表示云上系统的微服务的总数,第一邻接矩阵的第i行的第j列的元素值通过0或者1表示,当第一邻接矩阵的第i行的第j列的元素值为0时,表示云上系统的第i个微服务与第j个微服务之间不存在调用关系,否则表示云上系统的第i个微服务与第j个微服务之间存在调用关系,其中1≤i≤n,1≤j≤n;
12、步骤s104,根据第一邻接矩阵对当前时间的云上系统的网络拓扑图信息进行故障预警标记,并生成故障预警信息发送到监控后台。
13、进一步地,预设时间段d和预设时间间隔e均为自定义参数。
14、进一步地,微服务之间的请求成功率等于请求成功的数量除以请求的总数;微服务之间的平均响应时间等于所有请求的响应时间的总和除以请求的总数,其中请求的响应时间表示一个微服务发送请求的时间与该微服务接收到请求返回数据的时间之间的时间差,单位为毫秒;平均吞吐量通过每秒请求量或者每秒事务量表示;百分比响应等于请求成功响应的数量除以请求的总数;最大延时表示单次请求到响应的时间的最大值;微服务对应虚拟机的垃圾回收时间和垃圾回收次数分别表示虚拟机中的垃圾回收器释放不再被微服务占用的内存空间的时间和次数。
15、进一步地,节点的初始向量通过将网络拓扑图信息中每分钟请求量、请求成功率、平均响应时间、平均吞吐量、百分比响应、最大延时与日志信息中微服务对应虚拟机的cpu占比、内存占用大小、垃圾回收时间、垃圾回收次数、线程数进行拼接得到组合向量表示。
16、进一步地,当云上系统的网络拓扑图信息中的微服务之间存在直接的调用关系,则微服务对应的节点之间构建边,当云上系统的网络拓扑图信息中的微服务之间存在间接的调用关系,则微服务对应的节点之间不构建边。
17、进一步地,全链路故障定位模型的计算公式包括:
18、第一邻接矩阵q的计算公式如下:
19、q=σ(p*pt);
20、其中p表示更新矩阵,更新矩阵的一个行向量对应一个节点的更新向量,t表示转置操作,σ表示sigmoid激活函数,第一邻接矩阵的元素值大于等于0.5则赋值为1,否则赋值为0;
21、第u个节点的更新向量的计算公式如下:
22、
23、其中nu表示第u个节点的邻居节点的集合,第u个节点的邻居节点表示与第u个节点存在边的节点,hv表示第v个邻居节点的初始向量,αuv表示第u个节点与第v个邻居节点之间的归一化注意力系数,w1表示第一权重参数,σ表示sigmoid激活函数;
24、第u个节点与第v个邻居节点之间的归一化注意力分数αuv的计算公式如下:
25、
26、其中nu表示第u个节点的邻居节点的集合,第u个节点的邻居节点表示与第u个节点存在边的节点,hu、hv和hk分别表示第u个节点的初始向量、第v个邻居节点的初始向量和第k个邻居节点的初始向量,β表示注意力权重参数,w2表示第二权重参数,concat表示拼接操作,t表示转置操作,exp表示取自然指数函数的幂运算,leakyrelu表示leakyrelu激活函数。
27、进一步地,用于训练全链路故障定位模型的训练样本通过模拟仿真平台获得,其中一个训练样本包括训练数据和训练标签,训练数据与基于云上系统的网络拓扑图信息和日志信息构建的图结构数据相同,训练标签为第二邻接矩阵,与第一邻接矩阵的表示相同,包括以下步骤:
28、步骤s201,通过模拟仿真平台模拟云上系统,在预设时间段d内按照预设时间间隔e采集云上系统的网络拓扑图信息和日志信息,并构建图结构数据作为一个训练样本的训练数据;
29、步骤s202,基于步骤s201构建的图结构数据构建第二邻接矩阵;当微服务之间的调用关系满足预警条件,则直接将第二邻接矩阵中对应的节点之间的元素值标记为0,其余元素值则通过运维人员进行标注;
30、预警条件包括:微服务之间无法进行网络通讯;微服务对应虚拟机的cpu占比的大于等于第一阈值;微服务对应虚拟机的内存占用大小大于等于第二阈值;其中第一阈值和第二阈值均为自定义参数;
31、步骤s203,重复步骤s201和步骤s202,直至获得m个训练样本,其中m为自定义参数。
32、进一步地,将第一邻接矩阵的元素值与第二邻接矩阵的元素值之间的差作为全链路故障定位模型的损失函数。
33、进一步地,当第一邻接矩阵的第x行的第y列的元素值为0时,则表示云上系统的第x个微服务与第y个微服务之间不存在调用关系,并将云上系统的网络拓扑图中对应的两个微服务之间的连接关系通过颜色标记作为故障预警标记,并根据两个微服务的ip地址或者唯一标识码生成预警信息发送给后台管理人员,其中1≤x≤n,1≤y≤n。
34、本发明提供一种云上系统全链路故障定位分析系统,包括:
35、信息采集模块,其用于在预设时间段d内按照预设时间间隔e采集云上系统的网络拓扑图信息和日志信息;
36、图结构数据构建模块,其用于基于云上系统的网络拓扑图信息和日志信息构建图结构数据;
37、全链路故障定位模型构建模块,其用于将图结构数据输入到全链路故障定位模型中,输出第一邻接矩阵;
38、故障预警生成模块,其用于根据第一邻接矩阵对当前时间的云上系统的网络拓扑图信息进行故障预警标记,并生成故障预警信息发送到监控后台。
39、本发明的有益效果在于:本发明基于云上系统的微服务的链路信息构建图结构数据,并通过神经网络模型将链路信息进行聚合分析生成预警信息,从而实现对云上系统的提前预警,提高用户对应用程序的使用体验。
- 还没有人留言评论。精彩留言会获得点赞!