本发明属于功率分配,具体涉及一种基于mamfsac算法的认知无蜂窝系统功率分配方法。
背景技术:
1、认知无蜂窝(cell-free)大规模网络系统由网内次级无蜂窝网络和网外主级用户(primary user,pu)网络组成,随着网内用户的逐渐增多,次级网络陷入频谱资源短缺。为了解决该问题,次级用户(secondary user,su)需要感知主级用户的频谱空洞来机会式地接入主级用户网络。传统基于认知无蜂窝系统的功率分配文献中,通常假设次级用户能够准确感知主级用户的频谱空洞,而在实际场景中,次级用户无法准确地感知到主级用户的频谱空洞。
2、当频谱感知结果存在误差时,可能会出现虚警或漏检。虚警将导致su失去接入频谱的机会,降低网络吞吐量。漏检将导致su访问不可用的频谱,并可能对pu造成干扰。这可能会惩罚su,甚至可能禁止su再次使用主级用户的授权频谱。此外,在次级无蜂窝网络内部,将小区从固有的蜂窝外形约束和小区边界的束缚中解放出来,与蜂窝相比,无蜂窝网络允许多个基站同时服务一个用户,大幅提高了对边缘用户的服务性能。然而,这同时带来了用户间的干扰,为了综合考虑次级无蜂窝网络内部用户间的干扰和协调主次级网络间的干扰,针对认知无蜂窝系统的功率分配方法至关重要。
3、现有基于传统无蜂窝网络的最大最小公平性问题是非多项式级难度(non-deterministic polynomial hard,np-hard)和非凸的。文献中利用数学推导得到了这些优化问题的等价凸问题,常规的做法是采用迭代优化的思路,但是这种方法时间复杂度非常高,无法满足实际场景中在极短时间内做出功率分配结果的需求。近年来,随着深度学习(deep learning,dl)技术的兴起,无模型的强化学习作为一种用数据驱动并通过与环境的交互动态地更新网络受到研究者的青睐。
4、一方面,在认知无蜂窝系统有关的文献中,大多考虑次级用户能够准确感知主级用户的频谱,然而在实际运用过程中,虚警和漏检难免存在,因此针对实际场景,需要将虚警和漏检概率引入至系统的优化模型中。另一方面,在传统认知有关的文献中,对于功控类的优化问题,一般采用迭代式方法对问题进行求解,而此种方法的高复杂度无法在实际中应对快速变化的信道状态。尽管也有文献使用了强化学习算法,但是一般停留在深度q学习网络(deep q-learning network,dqn)和深度确定性策略梯度(deep deterministicpolicy gradient,ddpg)这两种算法,在算法性能方面具有较弱的探索能力并且对超参数十分敏感,且探索能离较弱导致曲线波动很大。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于mamfsac算法的认知无蜂窝系统功率分配方法。本发明要解决的技术问题通过以下技术方案实现:
2、本发明提供了一种基于mamfsac算法的认知无蜂窝系统功率分配方法,包括:
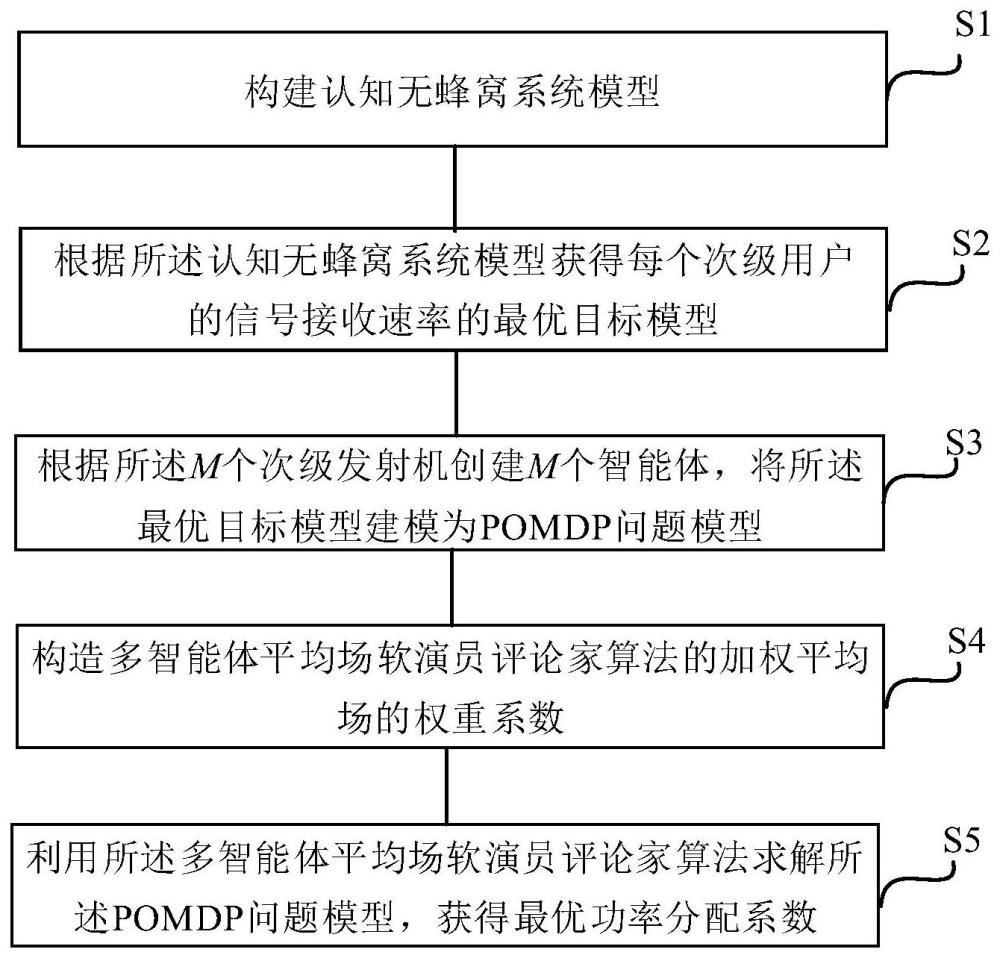
3、s1:构建认知无蜂窝系统模型,所述认知无蜂窝系统模型包括主级发射机、主级用户、m个次级发射机和n个次级用户;
4、s2:根据所述认知无蜂窝系统模型获得每个次级用户的信号接收速率的最优目标模型;
5、s3:根据所述m个次级发射机创建m个智能体形成多智能体系统,将所述最优目标模型建模为pomdp问题模型;
6、s4:构造多智能体平均场软演员评论家算法的加权平均场的权重系数;
7、s5:利用所述多智能体平均场软演员评论家算法求解所述pomdp问题模型,获得最优功率分配系数。
8、在本发明的一个实施例中,所述s2包括:
9、s2.1:获得第n∈[1,n]个次级用户sun在主级用户不占用频段时接收到的信号yn0:
10、
11、其中,表示期望信号,ηmn表示为第m∈[1,m]个次级发射机stm分配至第n∈[1,n]个次级用户sun的功率系数,hmn表示为stm与sun之间的下行信道系数,hmn={hmn1,...,hmnk,...,hmnk},hmnk表示stm与sun之间第k根天线的下行信道系数,wmn为stm与sun之间的共轭波束成形方式的预编码矩阵,qn表示发送至第n个次级用户的数据,表示次级用户之间的干扰,qi表示发送至第i个次级用户的数据,wn为均值为0,方差为σ2的高斯白噪声;
12、s2.2:获得第n个次级用户sun在主级用户不占用频段时的信干噪比:
13、
14、其中,pmax表示每个次级发射极的最大发射功率;
15、s2.3:获得第n个次级用户sun在主级用户占用频段时接收到的信号yn1:
16、
17、其中,pt表示主级发射机的发射功率,hpn表示主级发射机与第n个次级用户sun之间的信道系数;
18、s2.4:获得第n个次级用户sun在主级用户占用频段时对应的信干噪比:
19、
20、s2.4:根据主级用户占用频段时的信干噪比与主级用户非占用频段时的信干噪比,获得次级用户sun的信号接收速率rn为:
21、rn=(1-pf)pr(h0)log2(1+sinrn0)+(1-pd)pr(h1)log2(1+sinrn1)
22、其中,pr(h0)为主级用户不占用频段的概率,pr(h1)为主级用户占用频段的概率,pf=pr{判决为h1|h0}表示虚警概率,pd=pr{判决为h1|h1}表示检测概率;
23、s2.5:构建次级用户的信号接收速率的最优目标模型:
24、
25、
26、
27、其中,hmp表示主级用户与第m个次级发射机之间的信道系数,表示主级用户的最大干扰门限。
28、在本发明的一个实施例中,所述s3包括:
29、s3.1:将所述m个次级发射机创建成m个智能体,将所述认知无蜂窝系统模型构建成(s,o,a,r,p)形成,其中,s={s1,...,sm,...,sm}表示所有智能体的状态集合,o={o1,...,om,...,om}表示所有智能体的局部观测集合,a={a1,...,am,...,am}表示所有智能体的动作集合,r={r1,...,rm,...,rm}表示所有智能体的回报值集合,p表示状态转移概率;
30、s3.2:根据次级发射机与次级用户之间的功率系数、下行信道系数以及次级用户的信号接收速率构建每个智能体的状态、动作和回报值。
31、在本发明的一个实施例中,所述s3.2包括:
32、s3.21:获得第m个智能体的局部观测om:
33、om={ηm1,...,ηmn,...,ηmn,hm1,...,hmn,...,hmn}
34、其中,ηmn表示为第m个次级发射机stm分配至第n个次级用户sun的功率系数,hmn表示为stm和sun之间的下行信道系数;
35、s3.22:根据所述局部观测om获得所有智能体的状态集合:
36、
37、s3.23:获得第m个智能体的动作:
38、am={ηm1,...,ηmn,...,ηmn};
39、s3.24:将t时刻的回报值设计为:
40、r(t)=min{r1,...,rn,...,rn}+c(t),
41、其中,表示状态st时采取动作at的最小次级用户信号接收速率,c(t)表示带惩罚项的代价函数。
42、在本发明的一个实施例中,所述s4包括:
43、s4.1:假设所有次级发射机均包括一个n维的预连接向量prej:
44、
45、其中,prej(n)表示第j个次级发射机与第n个次级用户的连接情况,lf表示路损,threshold表示路损门限值,prej={prej(1),...,prej(n),...,prej(n)};
46、s4.2:获得智能体j在第n个次级用户上对智能体i的权重系数:
47、
48、其中,k表示次级发射机的天线数量,hjnk表示第j个次级发射机对第n个次级用户在第k根天线上的信道系数;
49、s4.3:获得智能体i在第n个次级用户上的权重系数wi(n):
50、
51、在本发明的一个实施例中,所述s5包括:
52、s5.1:创建m个智能体,每个智能体包括一个策略网络和一个评估网络,初始化策略网络参数θ和智能体功率分配系数{η1,...,ηn},初始化评估网络的网络参数ω1、ω2、
53、s5.2:获得所有智能体不同时刻的经验信息并存储至经验池中,其中,所述不同时刻的经验信息包括不同时刻的状态集合、部分观测集合、动作集合和回报值集合;
54、s5.3:根据智能体不同时刻的经验信息对所述智能体进行训练,更新所述策略网络和所述评估网络的网络参数,获得训练后的多智能体系统;
55、s5.4:将次级用户的局部观测数据输入至训练后的多智能体系统中,获得所述次级用户的最优功率分配系数。
56、在本发明的一个实施例中,所述s5.2包括:
57、s5.21:每个智能体获得当前时刻t的局部观测ot,将所述局部观测ot输入至所述策略网络中获得当前时刻t对应的动作at;
58、s5.22:利用每个智能体当前时刻t对应的动作at获得每个智能体当前回报值rt以及下一时刻的观测ot+1;
59、s5.23:获得所有智能体的经验信息(st,ot,at,rt,st+1,ot+1),并存储至经验池中。
60、在本发明的一个实施例中,所述s5.3包括:
61、s5.31:在所述经验池中选择智能体不同时刻的经验信息作为训练数据;
62、s5.32:将所述训练数据输入所述策略网络和所述评估网络中,计算当前动作的加权权重系数,根据所述加权权重系数计算加权平均动作;
63、s5.33:根据计算熵的损失函数,根据获得所述评估网络的损失函数,根据获得所述策略网络的损失函数,其中,e表示取平均,表示(st,at,rt,st+1)取自回放经验池α为温度系数,h(π(·|st))为熵的正则化项,π(at|st)表示在状态st时,执行动作at的概率,表示在全局状态为st,智能体自身动作为at,其余智能体加权平均动作为参数为ω的评估网络计算得到的q值,表示在全局状态为st+1时,参数为ω-的评估网络计算得到的状态价值,γ表示折扣因子,πθ(at|st)表示在状态为st时,参数为θ的策略网络输出动作at的概率;
64、s5.34:对所述熵的损失函数、所述评估网络的损失函数和所述策略网络的损失函数执行反向传播操作得到相对应的梯度和更新评估网络的参数ωi和策略网络的参数θ和熵的正则化项的参数α。
65、本发明的另一方面提供了一种存储介质,所述存储介质中存储有计算机程序,所述计算机程序用于执行上述实施例中任一项所述基于mamfsac算法的认知无蜂窝系统功率分配方法的步骤。
66、本发明的又一方面提供了一种电子设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器调用所述存储器中的计算机程序时实现如上述实施例中任一项所述基于mamfsac算法的认知无蜂窝系统功率分配方法的步骤。
67、与现有技术相比,本发明的有益效果有:
68、1、本发明提供了一种基于mamfsac算法的认知无蜂窝系统功率分配方法通过使用多智能体强化学习这种以数据为驱动的算法,在智能体训练完成后,能够在极短时间内对原非凸问题进行求解。
69、2、在大规模场景中,本发明利用平均场理论,将评估网络中其他智能体的动作信息用一个等效的平均动作作为代替,从而将原先的o(mn)的动作维度降低成了o(n)的动作维度,大幅提升了算法的性能和可扩展性。
70、3、根据无蜂窝网络场景特点,本发明设计以信道系数作为加权平均场的权重,这种权重设计方式充分考虑了次级发射机和次级用户的耦合关系及小尺度影响。相比于传统方法以距离作为权重,用本发明所提的权重计算出的等效平均动作更为精确。
71、以下将结合附图及实施例对本发明做进一步详细说明。