一种基于云边协同策略的移动边缘计算卸载方法
本发明属于物联网领域,具体涉及一种基于云边协同策略的移动边缘计算卸载方法。
背景技术:
1、计算卸载是一种将计算任务从主设备转移到边缘设备或云端设备的策略,以提高资源利用率、降低能耗和改善用户体验。随着互联网技术的快速发展和用户设备数量的增加,计算卸载成为解决大规模高性能计算和数据实时处理需求的有效方式。
2、常见的计算卸载模型根据是否引入云计算资源分为两种:两层计算卸载模型和三层计算卸载模型。两层计算卸载模型主要指将计算任务迁移到边缘设备中计算或云服务器中计算,如智能手机、物联网设备等,以减少数据传输延迟和网络拥塞,提高实时性和响应性。三层卸载模型则是将计算任务交由云边协同计算,利用边缘服务器的高带宽低时延特性以及云服务器强大的计算资源特性来提高用户的服务质量。
3、在计算卸载模型中,根据终端设备与边缘服务器的数量,又可以分为:单用户单(mobile edge computing,mec)卸载模型、多用户多mec卸载模型。单用户单mec卸载一般用于满足用户个性化需求,模型中主要研究的是可拆分的卸载问题。多用户多mec模型主要研究不可拆分的任务卸载问题。
4、在选择计算卸载策略时,需要考虑不同场景下的因素,包括用户设备的计算能力、带宽限制、延迟要求、能源消耗等。根据任务特性和系统需求,可以采用静态卸载和动态卸载两种方式。
5、(1)静态卸载:在任务开始执行之前确定卸载策略,根据任务的类型和要求将其分配给边缘设备或云服务器。这种方式适用于任务特性相对固定,且可以预先布置的场景,例如批处理任务或数据密集型任务。
6、(2)动态卸载:根据实时情况和系统状态来动态地决定任务的卸载策略。通过监测网络负载、计算资源利用率和设备能源状况等指标,可以实时调整任务的卸载位置。动态卸载适用于实时性要求高、任务特性不确定或网络环境变化频繁的场景。但在进行动态卸载的同时也会产生额外的性能需求。
7、为了确定最佳的计算卸载策略,需要考虑以下几个方面:
8、(1)任务划分与调度:将任务划分成可并行执行或者串行的子任务,并决定将哪些子任务卸载到边缘设备或云端设备上执行。任务调度算法可以通过优化目标函数来确定最佳的任务分配和调度策略。在目标函数的选择方面,通常考虑时延、能耗以及其他开销问题,不同的卸载场景要考虑的情况不同,所建立的优化目标函数也不同。
9、(2)数据传输与同步:由于计算卸载涉及到数据的传输和同步,需要考虑数据的大小、传输延迟以及数据一致性等因素。合理的数据划分和传输策略可以降低通信开销和延迟,并保证数据的一致性和完整性。
10、(3)资源管理与能耗优化:在边缘设备和云端设备的资源管理方面,需要考虑计算资源的分配和调度、能源消耗以及设备的负载均衡。通过合理地管理资源和优化能耗,可以提高系统性能和资源利用率。
11、(4)安全性和隐私保护:计算卸载涉及到数据的传输和处理,因此安全性和隐私保护是重要的考虑因素。加密通信、数据隔离和访问控制等技术可以用于确保数据的安全性和用户的隐私。
技术实现思路
1、本发明的目的是解决sdn网络中固定场景下用户设备的卸载问题,首先使用基于密度的聚类方法将有限的边缘计算资源整合起来,以提高利用效率。然后引入云服务器与边缘服务器进行协同计算。由于引入了云服务器进行计算,本发明综合考量计算时延、能量消耗、安全因素以及其他花销,将计算卸载问题转换为非凸函数的优化问题。最后,提出了一种基于人工蜂鸟算法的求解策略。实验结果表明,本发明提出的算法能够满足固定场景下用户设备的卸载问题,且卸载性能具有鲁棒性。
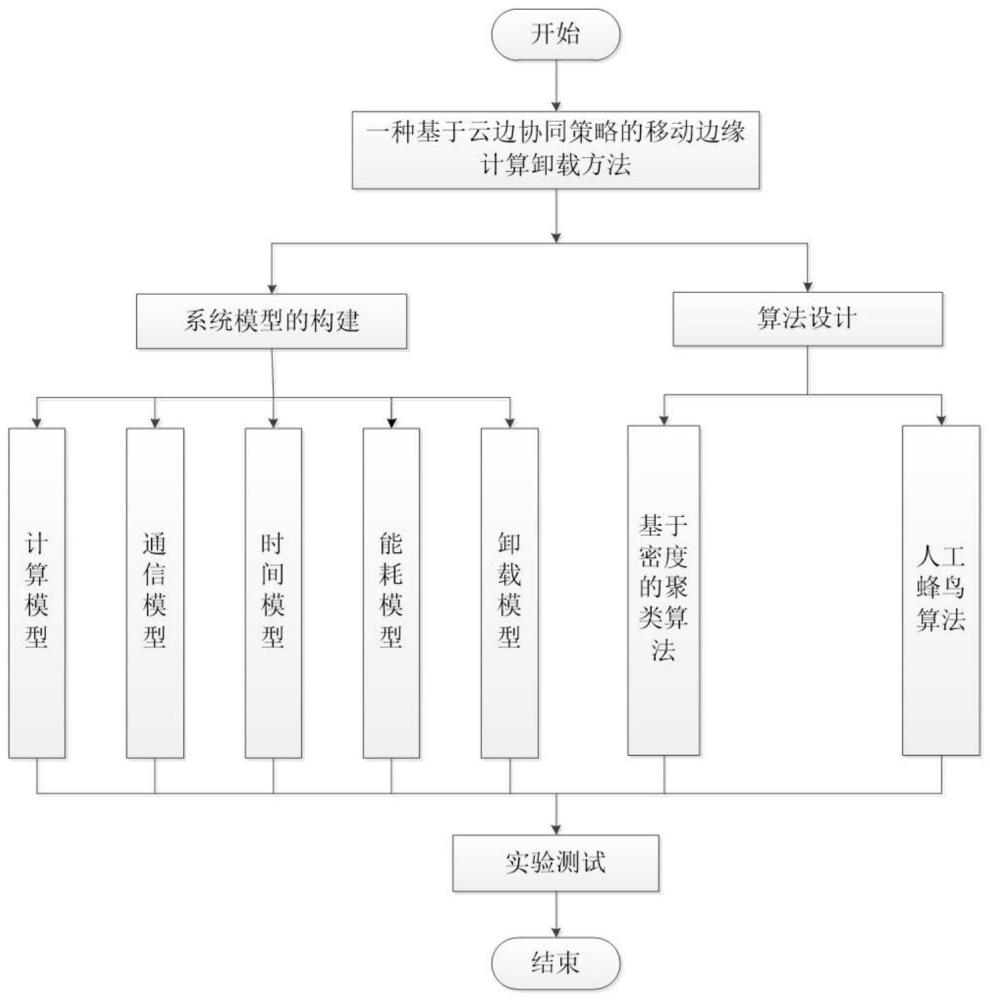
2、本发明的基于云边协同策略的移动边缘计算卸载方法,主要包括如下关键步骤:
3、第1、系统模型的构建:
4、第1.1、建立计算模型;
5、第1.2、建立通信模型;
6、第1.3、建立时间模型;
7、第1.4、建立能耗模型;
8、第1.5、建立卸载模型;
9、第2、算法设计:
10、第2.1、基于密度的聚类算法;
11、第2.2、人工蜂鸟算法。
12、步骤第1.1中建立了计算模型的方法如下,计算模型主要研究软件定义网络(software-defined networking,sdn)模型下云边协同的计算卸载问题。sdn网络采用集中式软件管理,并将网络控制和数据转发分离,所以需要先将边缘设备的计算与传输能力整合起来。首先,用户设备方面,假设存在n台用户设备,则将这n台设备描述为tasks={task1,task2,...,taskn},即每台设备对应一系列的计算任务,对于每个taski(0<i≤n),都有:
13、
14、上式中,mi表示第i个设备的数据量(mb);di表示第i个设备的计算量(bit);ki表示第i个设备的计算能力(转/bit);fi表示第i个设备的cpu周期频率(hz);bi表示第i个设备所处的信道带宽(hz);coli和rowi表示用户设备所在的二维空间的坐标;
15、每台设备都拥有数据卸载比例λi(0<λi≤1),λi表示用户设备i有λi比例的数据量要卸载到边缘服务器中。由于卸载数据量的比例和计算量的比例不存在确定的关系,因此提出一个随机映射函数rand(x):
16、rand(x)=(rand(0,x)+rand(x,1))/2 (2)
17、其中,rand(a,b)表示生成(a,b)区间内的随机值,公式(2);保证生成一个在(0,1]范围内的随机数,当用户设备的数据卸载比例为λi时,其计算量的卸载比例为rand(λi)。
18、步骤第1.2中建立通信模型的方法如下,假设某个空间范围内存在m台边缘服务器s={s1,s2,...,sm},每台边缘服务器si(0<i≤m)的二维坐标表示为:
19、si={colsi,rowsi} (3)
20、实际场景中,假设一个通信距离d,边缘服务器对于处于通信距离内的用户设备提供计算服务,d的计算公式为:
21、
22、用户设备与边缘服务器之间信道传输特性符合瑞利分布,使用表示,则用户设备i与边缘设备j之间的信道传输速率为:
23、
24、
25、其中,hij表示用户设备i与边缘服务器j之间的信道功率增益;g0表示路径损耗常数;dij为二者之间的欧式距离;由香农公式可知,bi表示第i个设备所处的信道带宽(hz);pihij/(ii+σ2)表示信噪比;其中,pi为用户设备i的传输功率;σ2为背景噪声方差;ii为用户设备i的区间干扰。
26、步骤第1.3中建立时间模型的方法如下,时间模型主要考虑有计算时间模型、传输时间模型和卸载时间模型;
27、(1)计算时间模型:
28、用户设备的本地计算时间与用户设备的计算能力以及卸载之后的计算量有关:
29、
30、边缘服务器的计算时间消耗为:
31、
32、其中,fserv,i为边缘服务器的cpu周期频率(hz);dserv,i表示边缘服务器接收到的全部计算量,只要在服务范围d内,边缘服务器就能够为用户设备提供计算服务,用户设备和边缘服务器之间属于多对多的关系,每个用户设备能够将自身的计算量平均传输分配给每个能够提供服务的边缘服务器中,每台边缘服务器能够收到多台用户设备的计算量,这些计算量的总量为dserv,i,则有:
33、
34、其中,nj表示能够为用户设备j提供计算服务的边缘服务器数量,设备j需满足以下公式:
35、
36、表示边缘服务器si能够提供服务的所有用户设备,云服务器的计算时间消耗主要分为排队时延和计算时间两部分,则有:
37、
38、其中,dcloud,i(0<i≤m)表示云服务器接收到的边缘服务器i传输而来的计算量。fcloud表示云服务器的计算能力,所有边缘设备共用一台云服务器,云服务器只能同时执行一台边缘服务器的计算任务,所以其他设备的计算需求要进行排队,为了准确的描述每台设备的排队时延,使用排队论中m/m/1的队列方式描述;
39、(2)传输时间模型:
40、传输时间主要考虑两个方面,用户设备向边缘服务器传输数据以及边缘服务器向云服务器传输数据,用户设备与边缘服务器通信时采用正交频分多址协议,用户设备与不同边缘服务器之间的通信同时进行,互不干扰;
41、用户设备i向边缘服务器传输数据所需时间ti2为传输到所有边缘服务器所需的最大时间:
42、
43、上式中,j表示用户设备i欧式距离在d内的所有边缘服务器的编号;λimi/ni表示传输给每个边缘服务器的数据量;cij的计算公式可以参考公式(6);
44、边缘服务器与云服务之间距离保持不变,则二者之间的信道传输速率始终保持相同,为了模拟真实场景中的通信,增加一个随机干扰因子ωi(0<i≤m,0<ωi≤1),表示边缘服务器与云服务器之间通信的受干扰程度;
45、
46、边缘服务器返回给用户设备和云服务器返回给用户设备的数据量较小,所以忽略这两部分数据在信道中传输所占用的时间;
47、(3)卸载时间模型:
48、假设卸载出去的任务不可再分,即卸载任务要么在边缘服务器中执行,要么传输到云服务器上执行,故卸载任务的计算时间取边缘服务器计算时间和传输到云服务器的计算时间的最小值,则计算用户设备i的任务所需的时间可以表示为:
49、ti=ti1+ti2+min(tserv,i,tcloud,i+tserv,i2) (14)
50、
51、步骤第1.4中建立能耗模型的方法如下,卸载场景中用户设备、边缘服务器以及云服务器均存在能量消耗,但边缘服务器的能量消耗一般计算在用户或边缘服务器的附加费用上面,不予关注,所以该方法主要研究用户设备以及边缘服务器的能量消耗,
52、(1)用户设备能耗:
53、用户设备的能耗主要包括本地计算能耗和传输能耗,根据所提出的理论,用户设备的计算功率与频率的三次方成正比,即:
54、
55、κ为芯片结构系数,fi为用户设备i的计算频率,进而,得到用户设备本地计算的能耗为:
56、
57、用户设备与边缘服务器之间通信虽然互不干扰,但能量消耗依旧是叠加的,表示如下:
58、
59、表示传输到所有边缘服务器所消耗的时间;pi表示用户设备i的传输功率;
60、(2)边缘服务器能耗
61、边缘服务器能耗主要包括服务器计算能耗和传输能耗,边缘服务器j(0<j≤m)的计算能耗为,由公式(8)(16)有:
62、
63、其传输能耗为,由公式(8)(13)有:
64、
65、卸载场景中,能耗主要考虑用户设备能耗以及边缘设备能耗,由于用户设备与边缘服务器属于多对多的关系,无法确定每台边缘服务器为每台用户设备消耗了多少能量,所以此处只能给出总能耗:
66、
67、步骤第1.5中建立卸载模型的方法如下,卸载模型综合考量计算时间、能量消耗和其他消耗,由于这三类变量单位不同,采用直接相加的方法没有实际意义,因此提出映射公式h(x)用于将具有不同物理意义的数据映射到相同的区间:
68、
69、公式(22)将变量x映射到(0,1)区间内,这样不同的变量就表示相同的权重,引入变量g1、g2、g3,分别表示对时间、能量和其他消耗的重视程度,将这种重视程度表示为适应度函数fitness,则有:
70、fitness=g1*h(t)+g2*h(e)+g3*scloud (23)
71、适应度越小,表示时间和能量消耗越少,所以本卸载模型表示如下
72、
73、其中,需要满足:
74、g1+g2+g3=1 (25)
75、
76、步骤第2.1中基于密度的聚类算法的设计描述如下,传统的基于密度的聚类算法一般使用dbscan算法,但dbscan算法对于其两个参数ε和minpts的依赖性太强,选用不同的参数得到的聚类结果相差太多,本发明采用optics(ordering points to identify theclustering structrue)算法,该算法提出的目的就是为了帮助dbscan算法选择合适的参数,optics算法的时间复杂度主要取决于以下几个步骤:
77、(1)核心距离计算:对于每个数据点,需要计算它到其ε范围内所有点的距离,并进行排序,计算距离时间复杂度为o(n),排序时间复杂度为o(nlogn),故核心距离计算的时间复杂度为o(n2logn);
78、(2)可达距离计算:对于每个数据点的每个邻居,计算可达距离,最坏情况下,对于每个数据点,都需要计算n-1个邻居的可达距离,因此计算的时间复杂度为o(n2)。
79、步骤第2.2中人工蜂鸟算法的设计描述如下,人工蜂鸟算法是2021年提出的一种新型元启发算法,该算法模拟了自然界中蜂鸟轴向飞行、对角飞行和全方位飞行三种特殊的飞行技能以及引导觅食、区域觅食和迁移觅食三种觅食策略,最后通过引入访问表来实现蜂鸟寻找和选择食物来源的记忆功能,最终达到求解最优化问题的目的;
80、蜂鸟在选取食物来源时,通常会评估来源的特性,如花蜜质量和含量、补蜜率以及最后一次访问花朵的时间。使用访问表的形式记录不同蜂鸟对每个食物源的访问级别,蜂鸟更倾向于访问级别最高的食物源,故访问表随着每次迭代而更新。
81、本发明的优点和积极效果:
82、本发明主要设计了一种基于云边协同策略的移动边缘计算卸载方法,在该方法中,主要研究了在边缘服务器计算能力有限的情况下,基于云边协同的计算卸载问题,提出了一种基于人工蜂群算法的卸载策略。首先,使用基于密度的聚类算法将有限的边缘设备聚集一起,再增加一个用于通信的服务器组成一个边缘服务器。然后,提出一种关注计算时延、能耗以及云服务器消耗的适应度函数,将计算卸载问题描述为求解非凸函数的优化问题。最后,使用人工蜂群算法对问题进行求解,以寻找最佳的适应度。
83、实验结果表明,本发明使用的人工蜂鸟算法能够有效解决云边协同的计算卸载问题。仿真实验中,人工蜂鸟算法能够在较少的迭代次数下找到最佳的卸载策略,且算法稳定性优异,在任何场景下都有稳定表现。真实场景实验中,人工蜂群算法的性能表现依旧良好。
- 还没有人留言评论。精彩留言会获得点赞!