基于改进蜣螂优化和Q学习算法的WSN路由协议方法
本发明属于路由算法,具体涉及基于改进蜣螂优化和q学习算法的wsn路由协议方法。
背景技术:
1、无线传感器网络(wireless sensor network,wsn)是由大量空间分布的微电子设备组成的网络系统。用于从环境中收集数据并构建有关监控对象的推论。近年来,wsn已广泛应用于灾害预警系统、医疗保健、环境监测、智慧交通、入侵检测、精准农业等关键领域。虽然wsn因其成本低、体积小、易于部署等优点在各个领域得到了广泛的应用,但由于wsn的传感器节点电源一般是由电量有限的电池提供并且不易频繁更换,如何高效率利用传感器能量、提高网络生命周期成为了路由算法研究的重点工作之一。因此,研究无线传感器网络的能量消耗以及如何提升其使用生命周期具有很好的现实意义和实用价值。
2、传感器节点是由微小的电池进行供电,在一些特殊环境中进行充电或者换电池成本相对较高。在实际应用中,传感器节点需要尽可能少地消耗能量来完成数据的收集和传输。在wsn的节能通信协议中,集群路由协议是一个重要的分支,已被证明在能量有限的wsn中是较好的节能方案。在集群路由协议中,wsn被分多个集群。每个集群中都有一个簇头,簇头负责收集不同节点采集到的数据并将其发送至基站。主要过程是集群的建立、簇头的选择以及簇头和基站之间的路由。集群路由协议相较于其他路由协议消耗更少的能量。
3、在集群路由协议中,网络集群建立的好坏对网络能耗有着本质的影响。在集群中节点与簇头的通信距离越小,其能耗就越低。每个集群中的节点数量越均衡,每个簇头的负载就越均衡。由于簇头需要接收、融合和转发数据,故而消耗的能量更多,因此选择合适的簇头对于提高网络负载均衡至关重要。此外,簇头需要承担将数据转发至基站的任务,相较于簇内通信其通信距离更长,消耗的能量也越大。因此选择合适的通信路径能有效均衡簇头通信能耗。
4、蜣螂优化算法(dung beetle optimizer,dbo)是一种新型的群智能优化算法,在2022年底由提出,受蜣螂在自然界中习性的启发,主要模拟了蜣螂的滚球、跳舞、繁殖、觅食和偷窃五种行为。作为一种强大性能的群智能算法,dbo已被应用于不同的研究领域。
5、对于一些远离基站的簇头来说,它与基站进行通信时需要消耗大量能量。故此需要优化路由将数据包送达的同时减少能量的消耗。q-learning算法是一种优化路由路径的有效方法。然而,传统的基于q-learning算法的路由方法通常分布式运行在传感器节点上。因此,传感器节点需要通过交互来维护q表。而对于资源有限的传感器节点来说,维护q表也是一个挑战。一方面,节点之间的数据传输消耗大量能量。另一方面,维护q表需要传感器节点拥有特定计算能力。
技术实现思路
1、本发明要解决的技术问题是:提供基于改进蜣螂优化和q学习算法的wsn路由协议方法,用于高效率利用传感器能量。
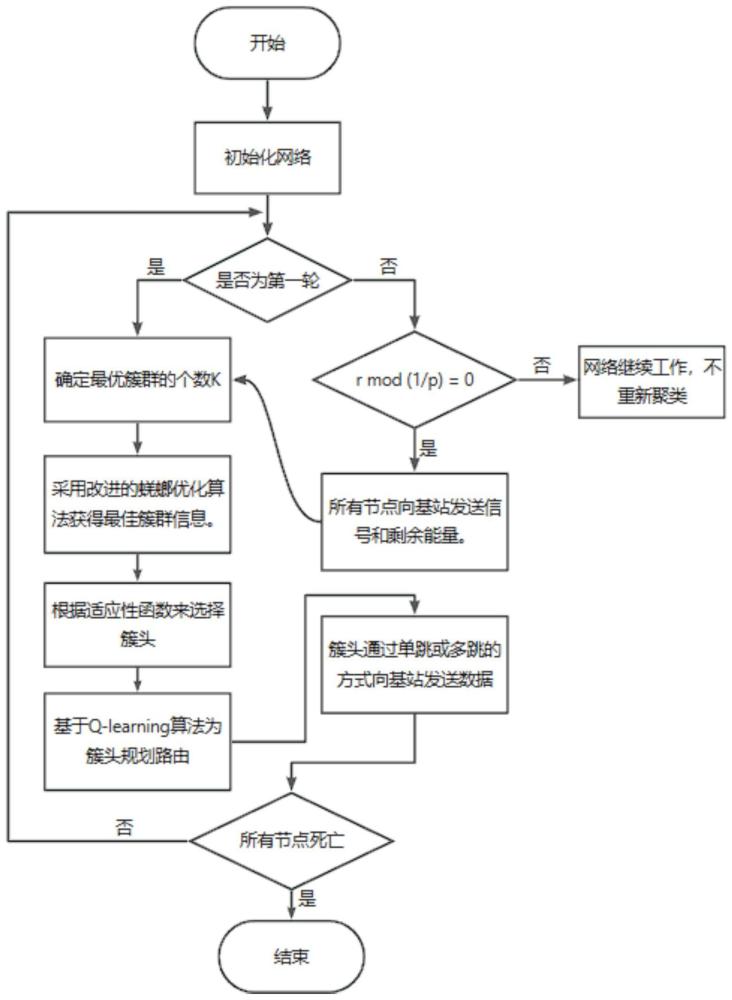
2、本发明为解决上述技术问题所采取的技术方案为:基于改进蜣螂优化和q学习算法的wsn路由协议方法,以轮为单位运行,每轮包括以下步骤:
3、s1:根据网络模型和能耗模型推算最优簇头数,采用改进蜣螂优化算法对网络内的节点进行分簇,得到最优簇头数个簇及每个簇内的节点;
4、s2:根据选举函数得到每个簇内的各节点成为簇头的概率值,以每一轮选取概率值最大的节点成为簇头;通过自适应的方式向基站发送信息;
5、s3:每个簇内的簇头接收、融合簇内节点数据;采用q-learning算法集中为簇头规划路由,根据簇头到基站的距离采用单跳或多跳的方式向基站发送数据。
6、按上述方案,所述的步骤s1中,设n表示网络中的存活节点数目,m表示监测区域的边长,dtobs表示簇头到基站的平均距离,则最优簇头数k的计算公式如下:
7、
8、最优簇头数随网络中的存活节点数目动态改变。
9、进一步的,所述的步骤s1中,分簇的具体步骤为:
10、s11:随机初始化各种蜣螂位置,采用蜣螂优化算法得到基于全局最优簇头数k的最优蜣螂位置;
11、s12:将最优蜣螂位置解码为聚类中心,寻找距离聚类中心最近的成员节点直至各簇群划分完毕;
12、s13:输出聚类中心及簇群成员节点的信息,得到k个簇及每个簇内的节点。
13、进一步的,所述的步骤s11中,具体步骤为:
14、s111:初始化种群,按照a:f:g:h的比例将蜣螂划分为不同的角色,包括a个进行滚球行为的滚球蜣螂、f个进行繁殖行为的繁殖蜣螂、g个进行觅食行为的觅食蜣螂和h个进行偷窃行为的偷窃蜣螂;
15、s112:设λ1、λ2、λ3为各评价因子的权重系数,λ1+λ2+λ3=1;设f1为分簇紧凑性评价因子,f2为簇群能量评价因子,f3为集群位置评价因子;则根据成簇的影响因子构造蜣螂的适应度函数为:
16、cost(pj)=λ1f1(pj)+λ2f2(pj)+λ3f3(pj);
17、s113:根据角色的不同,按照不同的方式对蜣螂的位置和状态进行更新;
18、设bi(t)为第i个繁殖蜣螂在第t次迭代的位置信息,x*为局部最优位置,b1和b2是两个独立的大小为1×d的随机向量,d是优化问题的维度,lb和ub分别表示最佳觅食区域的下界和上界;则繁殖蜣螂的位置更新公式为:
19、bi(t+1)=x*+b1×(bi(t)-lb*)+b2×(bi(t)-ub*);
20、设xi(t)为第i个觅食蜣螂第t次迭代的位置信息,xb为全局最优位置,c1表示服从正态分布的随机数,c1/c2是(0,1)范围内的随机向量,tmax表示最大迭代次数,r=1-t/tmax;则觅食蜣螂的位置更新公式为:
21、xi(t+1)=xi(t)+c1×(xi(t)-max(xb×(1-r),lb))+c2×(xi(t)-min(xb×(1+r),ub));
22、设si(t)表示第i个盗窃蜣螂第t次迭代的位置信息,g表示大小为1×d的随机向量,遵循正态分布,s表示常数值;则盗窃蜣螂的位置更新公式为:
23、si(t+1)=xb+s×g×(|si(t)-x*|+|si(t)-xb|);
24、设ri(t)表示第i个滚球蜣螂第t次迭代的位置信息,a为-1或1,b为属于(0,1)的一个随机数,偏转系数μ为属于(0,0.2)之间的常数,rω为全局最差位置;则滚球蜣螂的位置更新公式为:
25、ri(t+1)=ri(t)+a×μ×ri(t-1)+b×|ri(t)-rω|;
26、s114:判断是否达到最大迭代次数tmax,是则跳出循环步骤执行步骤s115,否则返回步骤s113;
27、s115:输出最优的簇头路由路径。
28、进一步的,所述的步骤s111中,引入chebyshev混沌映射对蜣螂种群进行初始化,设xi表示第i只蜣螂的位置信息,为常数,则:
29、
30、进一步的,所述的步骤s112中,
31、设d(ni,chpj,k)为节点ni到对应的簇头ch的距离,|cpj,k|为种群p中簇群ck的节点数目;则分簇紧凑性评价因子f1为节点到候选簇头的最大平均欧式距离:
32、
33、簇群能量评价因子f2为所有节点剩余能量e(ni)之和除以当前所有簇头能量之和:
34、
35、设nc表示网络中心坐标;则集群位置评价因子f3为簇头ch到基站bs的平均距离[σki=1d(bs,chpj,k)]/k除以基站bs到网络中心的距离d(bs,nc):
36、
37、进一步的,所述的步骤s113中,设xbest(t)为第t次迭代时的局部最优位置x*或全局最优位置xb,tmax为最大迭代次数,t为当前迭代次数,r为(0,1)之间的一个随机数;cauchy(0,1)为遵循标准柯西分布的随机数;引入柯西变异扰动策略更新繁殖蜣螂、觅食蜣螂和盗窃蜣螂的位置为:
38、
39、按上述方案,所述的步骤s2中,选举函数基于包括节点能量和距离的因素选举簇头;设n为集群中节点的数量;eres(i)为节点i的剩余能量;dtocentre(i)为节点i到聚类中心的距离;ω1和ω2为权重系数,范围为[0,1],且ω1+ω2=1;则选举函数的计算公式如下:
40、
41、按上述方案,所述的步骤s2中,设r为当前轮次,p为控制重新聚类操作频率的参数;则通过自适应的方式向基站发送信息的公式为:
42、
43、当cluster等于1时,表示在该轮将节点信息发送至基站;
44、当cluster等于0时,在网络中不执行发送节点信息至基站操作。
45、按上述方案,所述的步骤s3中,具体步骤为:
46、s31:采用q-learning算法将每个簇头视为一个智能体,初始化q表;
47、设d(si,snext)为节点si至snext的欧式距离;假设从状态st采取行动at时,数据包从si发送到snext;设立负能耗为奖励值;当传输数据消耗的能量越大时,负值越小,奖励越小;当传输数据消耗的能量越小时,负值越大,奖励越多;则奖励函数为:
48、
49、设qt(st,at)表示在状态st下采取动作at的预期回报值;α是学习率,表示每次更新时保留的以前记忆;r(st,at)是当前的奖励;γ是折扣因子,表示未来奖励的重要程度;是在下一个状态下采取所有可能的动作中,预期回报值最大的那个值;则在状态at下采取行动时获得奖励r(st,at),并更新q表:
50、
51、s32:进行迭代更新时使用ε-贪心策略维护q表的更新;设为在当前状态s下,计算q表后以ε的概率选择一个随机动作a、以1-ε的概率选择预期回报值最大的动作a*:
52、
53、s33:输出各簇头最优的路由路径,簇头通过规划好的路径通过单跳或多跳的方式向基站发送数据。
54、本发明的有益效果为:
55、1.本发明的基于改进蜣螂优化和q学习算法的wsn路由协议方法,针对集群中节点与簇头的通信距离越小能耗越低,每个集群中的节点数量越均衡每个簇头的负载越均衡的原理,采取了优化建立集群、选择簇头、簇头和基站之间的路由这三个阶段的措施;在簇头选举阶段采用改进蜣螂优化算法进行分簇,综合考虑节点能量、位置因素,使选举的簇头具有合理性,使网络分簇更加均匀;利用q-learning算法为簇头规划路由,降低了簇首因长距离传输数据消耗的能量;设计合理的簇头更换机制避免频繁更换簇头造成能量浪费,有效均衡了网络负载;从而实现了高效率利用传感器能量的功能。
56、2.本发明在原有dbo的基础上针对初始化种群不均和可能陷入局部最优等问题进行改进,利用改进蜣螂优化算法进行分簇,引入chebyshev混沌映射的种群初始化方法和柯西变异扰动策略,使得种群资源在搜索空间中更加均衡分配,平衡算法全局寻优和局部开发的能力;并将改进蜣螂优化算法应用在优化网络聚类中,避免了陷入局部最优地可能,使网络分簇更加均匀,以均衡网络能耗。
57、3.本发明基于节点剩余能量、位置因素选举簇头,并根据节点剩余能量动态调整权重系数,使选举的簇头更具合理性,均衡节点负载。
58、4.由于并不是每轮都需要执行聚类和簇头替换操作,在每轮中,当基站执行聚类和簇头选择操作时,所有节点必须向基站发送自己的信息(即位置和剩余能量),这将消耗大量能量;而本发明提出簇头替换方法以控制重新聚类操作的频率,从而避免了能源浪费。
59、5.本发明提出一种基于q-learning算法的优化路由机制,通过搜索簇头与基站之间的最佳路由路径,平衡网络能耗,提高了在不同网络环境中的可扩展性;由基站进行q表的维护,相较于传统的基于分布式的q-learning算法路由方法,将维护q表的任务交由具有强大计算资源的bs来完成,避免了在大多场景下资源有限的传感器节点难以维护q表的问题;在数据传输阶段根据簇头到基站距离采用单跳或多跳的方式向基站发送数据,使用q-learning算法为簇头规划路由,通过规划的簇头路由来降低簇头因长距离传输数据消耗的能量,均衡了簇头负载。
- 还没有人留言评论。精彩留言会获得点赞!