音频处理方法、装置、设备、介质及产品与流程
本技术属于空间音频渲染,尤其涉及一种音频处理方法、装置、设备、介质及产品。
背景技术:
1、空间音频的本质是“计算音频”,也即空间音频能够将声源模拟为空间中固定位置的音响设备,当用户头部转动或设备移动时,声音能够随着用户的运动变化而变换,仍能使得用户能够感受到身临其境的环绕声体验。
2、随着虚拟现实(virtual reality,vr)行业的兴起,空间音频作为vr视频中的重要组成部分,其在vr领域内的发展与应用显得尤为重要。因此,如何快速生成适用于vr视频的音频是至关重要的。
技术实现思路
1、本技术实施例提供一种音频处理方法、装置、设备、介质及产品,能够根据用户输入的视频数据,自动化地生成与之匹配的空间音频。
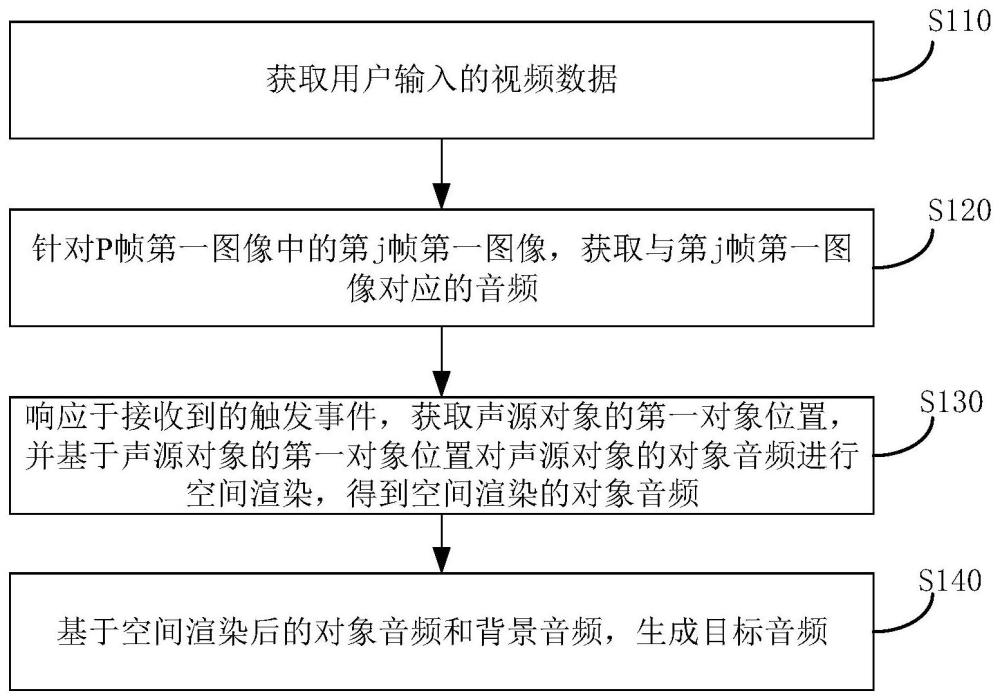
2、第一方面,本技术实施例提供一种音频处理方法,方法包括:
3、获取用户输入的视频数据,视频数据包括p帧第一图像;
4、针对p帧第一图像中的第j帧第一图像,获取与第j帧第一图像对应的音频,音频包括声源对象的对象音频和背景音频,j大于等于1;
5、响应于接收到的触发事件,获取声源对象的第一对象位置,并基于声源对象的第一对象位置对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频;
6、基于空间渲染后的对象音频和背景音频,生成目标音频。
7、在第一方面的一种可选的实施方式中,音频包括声源对象的对象音频;
8、针对p帧第一图像中的第j帧第一图像,获取与第j帧第一图像对应的音频,包括:
9、针对p帧第一图像中的第j帧第一图像,确定第j帧第一图像中的声源对象,以及声源对象的对象标签;
10、确定从第一预设音频库中筛选的与声源对象的对象标签匹配的对象音频,为声源对象的对象音频。
11、在第一方面的一种可选的实施方式中,针对p帧第一图像中的第j帧第一图像,确定第j帧第一图像中的声源对象,以及声源对象的对象标签,包括:
12、针对p帧第一图像中的第j帧第一图像,利用第一深度学习网络对第j帧第一图像进行处理,提取第j帧第一图像的图像特征;
13、根据第j帧第一图像的图像特征,确定第一图像中的声源对象,以及声源对象的对象标签。
14、在第一方面的一种可选的实施方式中,音频还包括背景音频;
15、针对p帧第一图像中的第j帧第一图像,获取与第j帧第一图像对应的音频,包括:
16、针对p帧第一图像中的第j帧第一图像,确定第j帧第一图像的场景标签;
17、基于第j帧第一图像的场景标签,确定第j帧第一图像的背景音频。
18、在第一方面的一种可选的实施方式中,针对p帧第一图像中的第j帧第一图像,确定第j帧第一图像的场景标签,包括:
19、针对p帧第一图像中的第j帧第一图像,按照预设角度对第j帧第一图像进行划分,得到与第j帧第一图像对应的预设数量的第二图像,利用第二深度学习网络对预设数量的第二图像进行解析,得到预设数量的第二图像中每张第二图像的场景类别;
20、基于预设数量的第二图像中每张第二图像的场景类别,确定图像的场景标签。
21、在第一方面的一种可选的实施方式中,当j=1时,基于第j帧第一图像的场景标签,确定第j帧第一图像的背景音频,包括:
22、从第二预设音频库中筛选得到与第j帧第一图像的场景标签匹配的背景音频;
23、确定与第j帧第一图像的场景标签匹配的背景音频,为第j帧第一图像的背景音频。
24、在第一方面的一种可选的实施方式中,当j大于等于2,基于第j帧第一图像的场景标签,确定第j帧第一图像的背景音频,包括:
25、判断第j帧第一图像的场景标签与第j-1帧第一图像的场景标签是否一致;
26、在第j帧第一图像的场景标签与第j-1帧第一图像的场景标签不一致的情况下,确定从第二预设音频库中筛选的与第j帧第一图像的场景标签匹配的背景音频,为第j帧第一图像的背景音频;
27、在第j帧第一图像的场景标签与第j-1帧第一图像的场景标签一致的情况下,确定第j-1帧第一图像的背景音频为第j帧第一图像的背景音频。
28、在第一方面的一种可选的实施方式中,响应于接收到的触发事件,获取声源对象的第一对象位置,包括:
29、响应于接收到的触发事件,获取姿态变化信息、声源对象的第二对象位置;
30、根据姿态变化信息和声源对象的第二对象位置,确定声源对象的第一对象位置。
31、在第一方面的一种可选的实施方式中,获取声源对象的第二对象位置,包括:
32、获取参数信息,参数信息包括视频数据对应的空间位置信息,以及用于采集视频数据的图像采集设备的设备参数;
33、获取声源对象在第j帧第一图像所在的二维坐标系中的坐标位置;
34、映射坐标位置至球坐标系中,得到声源对象的第二对象位置,球坐标系基于空间位置信息和设备参数构建。
35、在第一方面的一种可选的实施方式中,基于声源对象的第一对象位置对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频,包括:
36、基于预设的对象位置与声强之间的对应关系,对声源对象的第一对象位置进行匹配,得到声源对象的目标声强;
37、基于声源对象的目标声强对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频。
38、在第一方面的一种可选的实施方式中,在基于声源对象的第一对象位置对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频之后,方法还包括:
39、利用目标函数对空间渲染后的对象音频进行卷积处理,得到卷积处理后的对象音频,目标函数用于模拟音频传入人耳的过程;
40、基于空间渲染后的对象音频和背景音频,生成目标音频,包括:
41、基于卷积处理后的对象音频和背景音频,生成目标音频。
42、第二方面,本技术实施例提供一种音频处理装置,装置包括:
43、获取模块,用于获取用户输入的视频数据,视频数据包括p帧第一图像;
44、获取模块,还用于针对p帧第一图像中的第j帧第一图像,获取与第j帧第一图像对应的音频,音频包括声源对象的对象音频和背景音频,j大于等于1;
45、获取模块,还用于响应于接收到的触发事件,获取声源对象的第一对象位置,并基于声源对象的第一对象位置对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频;
46、生成模块,用于基于空间渲染后的对象音频和背景音频,生成目标音频。
47、第三方面,提供一种电子设备,包括:存储器,用于存储计算机程序指令;处理器,用于读取并运行存储器中存储的计算机程序指令,以执行第一方面中任一可选的实施方式提供的音频处理方法。
48、第四方面,提供一种计算机存储介质,计算机存储介质上存储有计算机程序指令,计算机程序指令被处理器执行时实现第一方面中的任一可选的实施方式提供的音频处理方法。
49、第五方面,提供一种计算机程序产品,计算机程序产品包括计算机程序,该计算机程序被处理器执行时实现第一方面中的任一可选的实施方式提供的音频处理方法。
50、在本技术实施例中,能够获取用户输入的视频数据,该视频数据包括p帧第一图像,针对该p帧第一图像中的第j帧第一图像,获取与该第j帧第一图像对应的声源对象的对象音频以及背景音频,进而能够响应于接收到的触发事件,获取声源对象的第一对象位置,并基于声源对象的第一对象位置对声源对象的对象音频进行空间渲染,得到空间渲染后的对象音频,并基于空间渲染后的对象音频和背景音频,生成目标音频。如此,能够对用户输入的视频数据进行逐帧处理,不仅能够快速自动化地生成与之匹配的空间音频,也无需额外设置音频采集设备或对音频和视频进行同步操作,降低了操作复杂度。
- 还没有人留言评论。精彩留言会获得点赞!