视频生成方法及装置和电子设备与流程
本说明书实施例涉及计算机,尤其涉及一种视频生成方法及装置和电子设备。
背景技术:
1、在电商内容化的背景下,各大平台都在加大短视频内容的供给量,为了提升用户停留时长,需要扩大泛娱乐的视频供给。
2、然而,视频制作不仅需要具备一定的专业技能,还需要消耗大量的时间才能制作完成。
3、因此需要提供一种能够快速生成视频的方案,以满足对视频生产效率的需求。
技术实现思路
1、本说明书实施例提供的一种视频生成方法及装置和电子设备。
2、根据本说明书实施例的第一方面,提供一种视频生成方法,所述方法包括:
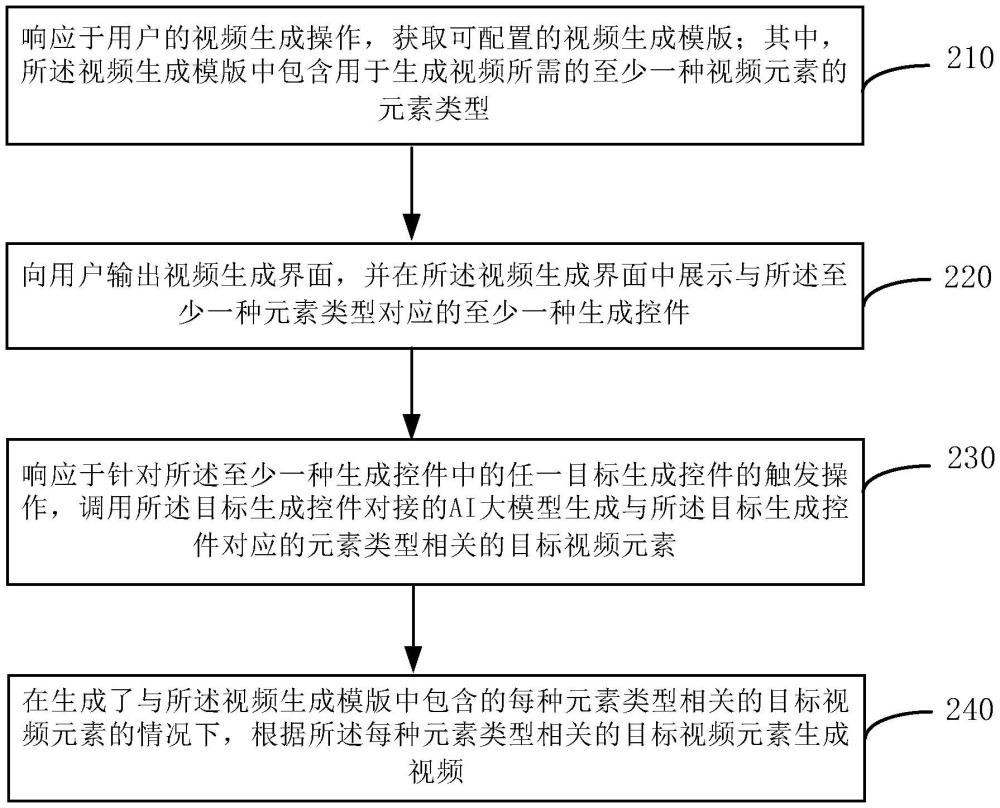
3、响应于用户的视频生成操作,获取可配置的视频生成模版;其中,所述视频生成模版中包含用于生成视频所需的至少一种视频元素的元素类型;
4、向用户输出视频生成界面,并在所述视频生成界面中展示与所述至少一种元素类型对应的至少一种生成控件;
5、响应于针对所述至少一种生成控件中的任一目标生成控件的触发操作,调用所述目标生成控件对接的ai大模型生成与所述目标生成控件对应的元素类型相关的目标视频元素;
6、在生成了与所述视频生成模版中包含的每种元素类型相关的目标视频元素的情况下,根据所述每种元素类型相关的目标视频元素生成视频。
7、可选的,所述元素类型包括生成视频所需的背景图像的类型;所述至少一种生成控件包括用于生成背景图像的第一生成控件;所述ai大模型包括图像大模型;
8、所述响应于针对所述至少一种生成控件中的任一目标生成控件的触发操作,调用所述目标生成控件对接的ai大模型生成与所述目标生成控件对应的元素类型相关的目标视频元素,包括:
9、响应于针对所述第一生成控件的触发操作,获取用于表征所需背景图像的描述信息,并将所述描述信息作为提示词发送给与所述第一生成控件对接的图像大模型,以由所述图像大模型基于所述提示词生成对应的目标背景图像。
10、可选的,所述获取用于表征所需背景图像的描述信息,包括:
11、展示第一管理页面;
12、获取用户在所述第一管理页面中输入的表征所需背景图像的描述信息。
13、可选的,所述元素类型包括视生成视频所需的背景音频的类型,所述至少一种生成控件包括用于生成背景音频的第二生成控件;所述ai大模型包括音频大模型;
14、所述响应于针对所述至少一种生成控件中的任一目标生成控件的触发操作,调用所述目标生成控件对接的ai大模型生成与所述目标生成控件对应的元素类型相关的目标视频元素,包括:
15、响应于针对所述第二生成控件的触发操作,获取用于表征所需音频的分类标签,并将所述分类标签作为提示词发送给与所述第二生成控件对接的音频大模型,以由所述音频大模型基于所述提示词从音频库中查询标记有相同的所述分类标签的目标背景音频。
16、可选的,所述获取用于表征所需音频的分类标签,包括:
17、从所述用户历史发布视频的视频标签中获取与音频相关的分类标签;或者,
18、展示第二管理页面;
19、获取用户在所述第二管理页面中配置的表征所需音频的分类标签。
20、可选的,所述元素类型包括视频中展示的文本标题;所述文本标题用于在生成的视频中预设的展示位置进行显示;所述至少一种生成控件包括用于生成文本标题的第三生成控件;所述ai大模型包括文本大模型;
21、所述响应于针对所述至少一种生成控件中的任一目标生成控件的触发操作,调用所述目标生成控件对接的ai大模型生成与所述目标生成控件对应的元素类型相关的目标视频元素,包括:
22、响应于针对所述第三生成控件的触发操作,获取用于表征视频所要表达的视频主题,将所述视频主题作为提示词发送与所述第三生成控件对接的文本大模型,以由所述文本大模型基于所述提示词生成与所述视频主题相关的目标文本标题。
23、可选的,所述获取用于表征视频所要表达的视频主题,包括:
24、展示第三管理页面;
25、获取用户在所述第三管理页面中输入的视频主题。
26、可选的,所述视频生成模版可配置多个文本标题,以及所述多个文本标题对应在视频中不同的展示位置;
27、针对生成的多个目标文本标题,所述根据所述每种元素类型相关的目标视频元素生成视频,包括:
28、根据所述视频生成模版配置的多个文本标题与展示位置的对应关系,将生成的所述多个目标文本标题添加到视频中对应的展示位置。
29、可选的,所述背景图像包括动态播放的图像序列。
30、根据本说明书实施例的第二方面,提供一种视频生成装置,所述装置包括:
31、模版获取单元,响应于用户的视频生成操作,获取可配置的视频生成模版;其中,所述视频生成模版中包含用于生成视频所需的至少一种视频元素的元素类型;
32、控件展示单元,向用户输出视频生成界面,并在所述视频生成界面中展示与所述至少一种元素类型对应的至少一种生成控件;
33、元素生成单元,响应于针对所述至少一种生成控件中的任一目标生成控件的触发操作,调用所述目标生成控件对接的ai大模型生成与所述目标生成控件对应的元素类型相关的目标视频元素ai大模型;
34、视频生成单元,在生成了与所述视频生成模版中包含的每种元素类型相关的目标视频元素的情况下,根据所述每种元素类型相关的目标视频元素生成视频。
35、可选的,所述元素类型包括生成视频所需的背景图像的类型;所述至少一种生成控件包括用于生成背景图像的第一生成控件;所述ai大模型包括图像大模型;
36、所述元素生成单元,包括:
37、图像生成子单元,响应于针对所述第一生成控件的触发操作,获取用于表征所需背景图像的描述信息,并将所述描述信息作为提示词发送给与所述第一生成控件对接的图像大模型,以由所述图像大模型基于所述提示词生成对应的目标背景图像。
38、可选的,所述图像生成子单元在获取用于表征所需背景图像的描述信息时,进一步包括:
39、响应于针对所述第一生成控件的触发操作,展示第一管理页面;获取用户在所述第一管理页面中输入的表征所需背景图像的描述信息。
40、可选的,所述元素类型包括视生成视频所需的背景音频的类型,所述至少一种生成控件包括用于生成背景音频的第二生成控件;所述ai大模型包括音频大模型;
41、所述元素生成单元,包括:
42、音频生成子单元,响应于针对所述第二生成控件的触发操作,获取用于表征所需音频的分类标签,并将所述分类标签作为提示词发送给与所述第二生成控件对接的音频大模型,以由所述音频大模型基于所述提示词从音频库中查询标记有相同的所述分类标签的目标背景音频。
43、可选的,所述音频生成子单元在获取用于表征所需音频的分类标签时,进一步包括:
44、从所述用户历史发布视频的视频标签中获取与音频相关的分类标签;或者,展示第二管理页面,获取用户在所述第二管理页面中配置的表征所需音频的分类标签。
45、可选的,所述元素类型包括视频中展示的文本标题;所述文本标题用于在生成的视频中预设的展示位置进行显示;所述至少一种生成控件包括用于生成文本标题的第三生成控件;所述ai大模型包括文本大模型;
46、所述元素生成单元,包括:
47、标题生成子单元,响应于针对所述第三生成控件的触发操作,获取用于表征视频所要表达的视频主题,将所述视频主题作为提示词发送与所述第三生成控件对接的文本大模型,以由所述文本大模型基于所述提示词生成与所述视频主题相关的目标文本标题。
48、可选的,所述标题生成子单元在获取用于表征视频所要表达的视频主题时,进一步包括:
49、展示第三管理页面,获取用户在所述第三管理页面中输入的视频主题。
50、可选的,所述视频生成模版可配置多个文本标题,以及所述多个文本标题对应在视频中不同的展示位置;
51、针对生成的多个目标文本标题,所述视频生成单元,进一步包括根据所述视频生成模版配置的多个文本标题与展示位置的对应关系,将生成的所述多个目标文本标题添加到视频中对应的展示位置。
52、可选的,所述背景图像包括动态播放的图像序列。
53、根据本说明书实施例的第三方面,提供一种电子设备,包括:
54、处理器;
55、用于存储处理器可执行指令的存储器;
56、其中,所述处理器被配置为上述任一项视频生成方法。
57、根据本说明书实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行上述任一项视频生成方法。
58、根据本说明书实施例的第五方面,提供一种计算机程序产品,包括计算机程序或指令,所述计算机程序或指令被处理器执行时实现上述任一项视频生成方法。
59、本说明书实施例,提供了一种视频生成方案,通过视频生成模版可以个性化地定制用于生成视频所需的至少一种视频元素的元素类型,进而向用户输出与每种元素类型对应的生成控件;通过生成控件调用对接的ai大模型所具备的视频元素生成能力,生成用户希望得到的目标视频元素,最后根据生成的各种目标视频元素自动生成对应的视频。如此无需用户具备视频制作技能,不仅操作方便且能够快速生成视频,提高了视频生成效率。
- 还没有人留言评论。精彩留言会获得点赞!