一种分镜脚本生成方法、装置、介质及设备与流程
本说明书涉及计算机,尤其涉及一种分镜脚本生成方法、装置、介质及设备。
背景技术:
1、近年来,随着计算机技术的发展,越来越多的用户成为了视频创作者。而对于每个用户来说,如何能创作出高质量的视频,使得创作的视频从海量的视频中脱颖而出,也就成为了重点研究方向。
2、而现有技术中,用户需要先收集灵感进行构思,再制定大纲,并进行创作以得到分镜脚本,从而参考分镜脚本进行视频创作,得到高质量的视频。
3、不难看出,分镜脚本决定了创作出的视频质量。然而,对于没有学习过专业拍摄技术的普通用户,构思过程以及制定大纲过程难度大,这导致用户得到分镜脚本的效率低下,严重影响了用户的视频创作体验。
4、为此,本说明书提供了一种分镜脚本生成方法。
技术实现思路
1、本技术提供一种方法,以部分的解决现有技术存在的上述问题。
2、本技术提供了一种分镜脚本生成方法,包括:
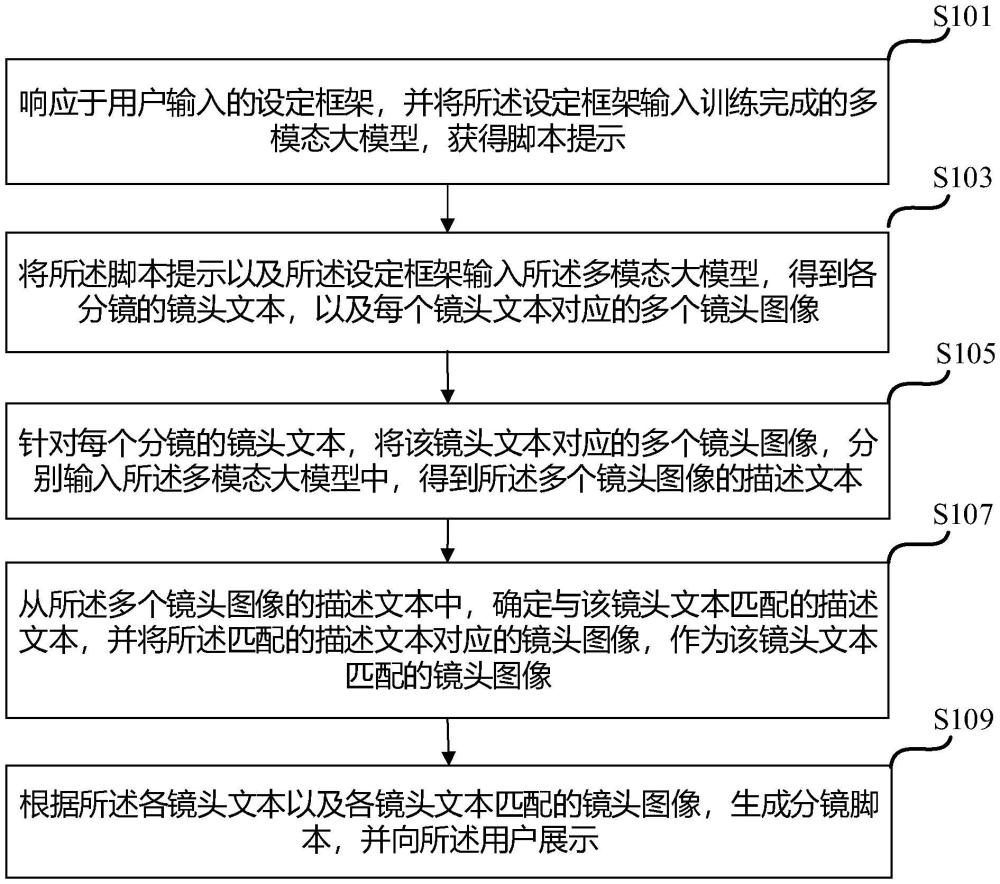
3、响应于用户输入的设定框架,并将所述设定框架输入训练完成的多模态大模型,得到脚本提示;
4、将所述脚本提示以及所述设定框架输入所述多模态大模型,得到各分镜的镜头文本,以及每个镜头文本对应的多个镜头图像;
5、针对每个分镜的镜头文本,将该镜头文本对应的多个镜头图像,分别输入所述多模态大模型中,得到所述多个镜头图像的描述文本;
6、从所述多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,并将所述匹配的描述文本对应的镜头图像,作为该镜头文本匹配的镜头图像;
7、根据各镜头文本以及各镜头文本匹配的镜头图像,生成分镜脚本,并向所述用户展示。
8、可选地,所述方法还包括:
9、响应于用户输入的评价文本,将所述评价文本输入所述多模态大模型,得到评价提示;
10、将所述评价提示以及所述设定框架输入所述多模态大模型,得到各分镜的镜头文本,以及每个镜头文本对应的多个镜头图像;
11、针对每个分镜的镜头文本,将该镜头文本对应的多个镜头图像,分别输入所述多模态大模型中,得到所述多个镜头图像的描述文本;
12、从所述多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,并将所述匹配的描述文本对应的镜头图像,作为该镜头文本匹配的镜头图像;
13、根据所述各镜头文本以及各镜头文本匹配的镜头图像,生成分镜脚本,并向所述用户展示。
14、可选地,所述方法还包括:
15、响应于用户根据所述分镜脚本输入的重写指令,确定生成所述分镜脚本的所述多模态大模型的温度参数,并调整所述多模态大模型的温度参数;
16、将所述设定框架以及所述重写指令输入调整后的所述多模态大模型,得到与所述脚本提示不同的脚本提示;
17、将所述不同的脚本提示以及所述设定框架输入所述多模态大模型,重新得到各分镜的镜头文本,以及重新得到的每个镜头文本对应的多个镜头图像;
18、针对每个重新得到的镜头文本,从该镜头文本对应的多个镜头图像中,确定该重新得到的镜头文本匹配的镜头图像;
19、根据所述重新得到的各镜头文本以及重新得到的各镜头文本匹配的镜头图像,重新生成分镜脚本,并向所述用户展示所述重新生成的分镜脚本。
20、可选地,将所述设定框架输入训练完成的多模态大模型,得到脚本提示,具体包括:
21、从所述设定框架中,确定各关键词,并根据预设的脚本要素对照表,确定所述各关键词分别对应的脚本要素;
22、针对每个关键词,根据该关键词在所述设定框架中的位置,确定该关键词在脚本大纲中的位置;
23、根据所述各关键词的位置、所述各关键词对应的脚本要素以及预设的镜头数量,确定具有所述镜头数量的镜头的脚本大纲,将所述脚本大纲输入训练完成的多模态大模型,得到脚本提示。
24、可选地,从所述多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,具体包括:
25、针对每个描述文本,确定该描述文本中的所述关键词,并确定在该描述文本中所述关键词的位置;
26、确定该镜头文本中的所述关键词,以及该镜头文本中所述关键词的位置;
27、根据各描述文本中所述关键词的位置以及该镜头文本中所述关键词的位置,确定与该镜头文本匹配的描述文本。
28、可选地,所述方法还包括:
29、响应于用户从所述分镜脚本中选择的镜头文本,确定所述选择的镜头文本的各关键词;
30、根据预设的脚本要素对照表,确定所述各关键词分别对应的脚本要素;
31、针对每个关键词,根据该关键词在所述镜头文本中的位置,确定该关键词在脚本大纲中的位置;
32、根据所述各关键词的位置、所述各关键词对应的脚本要素以及预设的镜头数量,确定具有所述镜头数量的镜头的脚本大纲,将所述脚本大纲输入训练完成的多模态大模型,得到脚本提示;
33、将所述脚本提示以及所述设定框架输入所述多模态大模型,得到各分镜的镜头文本,以及每个镜头文本对应的多个镜头图像;
34、针对每个分镜的镜头文本,将该镜头文本对应的多个镜头图像,分别输入所述多模态大模型中,得到所述多个镜头图像的描述文本;
35、从所述多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,并将所述匹配的描述文本对应的镜头图像,作为该镜头文本匹配的镜头图像;
36、根据所述各镜头文本以及各镜头文本匹配的镜头图像,生成分镜脚本,并向所述用户展示。
37、可选地,所述设定框架至少包括:背景剧情以及世界观。
38、本说明书提供了一种计算机存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现一种分镜脚本生成方法。
39、本技术提供了一种分镜脚本生成装置,包括:
40、提示模块,响应于用户输入的设定框架,并将所述设定框架输入训练完成的多模态大模型,得到脚本提示;
41、确定模块,将所述脚本提示以及所述设定框架输入所述多模态大模型,得到各分镜的镜头文本,以及每个镜头文本对应的多个镜头图像;
42、描述模块,针对每个分镜的镜头文本,将该镜头文本对应的多个镜头图像,分别输入所述多模态大模型中,得到所述多个镜头图像的描述文本;
43、匹配模块,从所述多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,并将所述匹配的描述文本对应的镜头图像,作为该镜头文本匹配的镜头图像;
44、展示模块,根据各镜头文本以及各镜头文本匹配的镜头图像,生成分镜脚本,并向所述用户展示。
45、本说明书提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现一种分镜脚本生成方法。
46、在本说明书提供的一种分镜脚本生成方法中,首先将用户输入的设定框架输入训练完成的多模态大模型,得到脚本提示,其次将脚本提示以及设定框架再次输入,得到各分镜的镜头文本,以及各分镜的多个镜头图像,再次将每个镜头文本对应的多个镜头图像,分别输入多模态大模型中,得到多个镜头图像的描述文本,并从多个镜头图像的描述文本中,确定与该镜头文本匹配的描述文本,并将匹配的描述文本对应的镜头图像,作为该镜头文本匹配的镜头图像,最后根据各镜头文本以及各镜头文本匹配的镜头图像,生成分镜脚本并展示。
47、从上述方法可以看出,通过根据设定框架快速生成的分镜脚本,大幅提高了用户的视频创作体验。
- 还没有人留言评论。精彩留言会获得点赞!