本发明涉及互联网大数据及快速视频编码,具体涉及一种基于深度学习的vvc帧内快速编码优化方法。
背景技术:
1、随着视频采集、通信和显示技术的快速发展,用户对超高清和360度视频应用的依赖日益增加。这些应用涵盖教育、娱乐、医疗服务和文化遗产保护等多个领域,生成的大量数据的传输和存储成为一个关键问题。
2、上一代视频编码标准高效视频编码(high efficiency video coding,hevc)的压缩性能逐渐无法满足视频应用发展的要求。为应对这一问题,联合视频专家组(jointvideo experts team,jvet)制定了一种名为多功能视频编码(versatile video coding,vvc)的视频压缩标准。在vvc编码框架中,引入了嵌套多类树的四叉树(quad tree withnested multi-type tree,qtmt)划分结构、更大的编码树单元(coding tree unit,ctu)、自适应滤波、仿射运动补偿预测等新技术。这些技术使得vvc编码的效率明显优于hevc,在相同峰值信噪比(psnr)条件下能节约50%的码率。然而,这些新技术也导致了编码复杂度的显著上升,特别是在ai全帧内模式下,vvc编码的平均复杂度达到hevc的18倍,使得vvc编码标准在实际应用中难以推广。因此,在保持较高编码效率的前提下,有效降低vvc编码复杂度显得非常必要。
3、vvc编码采用了更为复杂和多样化的划分结构,引入了水平和垂直二叉树划分(binary-tree,bt)以及水平和垂直三叉树划分(ternary-tree,tt)的qtmt划分结构,如图7所示qtmt包括四叉树(qt)、垂直二叉树(btv)、水平二叉树(bth)、垂直三叉树(ttv)和水平三叉树(tth)五种划分模式,使得vvc具备了更为灵活的划分方式,能够更好地适应不同图像区域的局部特性,从而提升了编码性能。然而,这种划分结构的应用也导致vvc帧内编码复杂度的急剧增加,主要归因于以下两个方面:1)qtmt技术需要考虑更多的划分组合,以找到最佳划分模式来提升编码性能;2)vvc允许对图像进行更细粒度的划分,以更好地捕捉复杂纹理信息,但更深层次的划分增加了编码过程中的计算量和内存开销,从而进一步提高了编码复杂度。
4、目前,学者们已经提出了基于统计分析、传统机器学习和卷积神经网络(cnn)等多种vvc帧内快速编码方法。基于统计分析的方法主要利用方差、梯度和纹理等中间编码特征建立预测模型,这类方法依赖于手动特征选择和阈值设置,这限制了帧内预测精度,导致编码效率显著下降。基于传统机器学习的方法通过引入贝叶斯决策规则、决策树、随机森林和支持向量机等技术来预测编码单元(coding unit,cu)的划分模式,提高模型预测精度。随着深度学习的发展,基于cnn的视频编码方法引起了人们的极大关注,如应用经典的cnn结构(resnet、densenet和u-net)来预测vvc的编码单元划分模式等。
5、然而,基于深度学习的vvc快速编码方法通常将划分模式预测转化为多分类问题,这类方法主要存在两个问题:1)未能考虑到编码深度对vvc帧内编码复杂度的影响,在简单纹理下仍需要对深层次编码单元进行划分模式搜索,导致vvc编码的复杂度高且效率低。2)需要对每个编码单元的五种划分模式均进行预测,消耗了大量的计算资源,同样导致vvc编码的效率很低。因此,如何在较高的编码效率下有效降低vvc的编码复杂度成为本领域技术人员亟需解决的问题。
技术实现思路
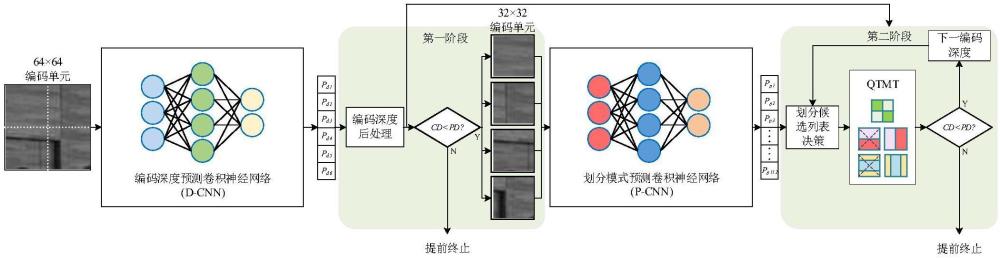
1、针对上述现有技术的不足,本发明所要解决的技术问题是:如何提供一种基于深度学习的vvc帧内快速编码优化方法,通过编码深度预测(d-cnn)模型预测编码单元的最大编码深度,有效考虑编码深度对vvc帧内编码复杂度的影响,提前终止率失真优化过程从而降低vvc帧内编码的复杂度;通过划分模式预测(p-cnn)模型预测编码单元的最优划分模式,跳过不必要的划分模式,进一步降低vvc的编码复杂度。
2、为了解决上述技术问题,本发明采用了如下的技术方案:
3、一种基于深度学习的vvc帧内快速编码优化方法,包括:
4、s1:获取待编码的视频帧;
5、s2:将待编码视频帧划分为若干个n1×n1编码单元;将n1×n1编码单元输入训练好的d-cnn模型中,得到对应的预测编码深度;
6、s3:将n1×n1编码单元划分为若干个n2×n2编码单元;将若干个n2×n2编码单元一起输入训练好的p-cnn模型中,得到每个n2×n2编码单元的划分预测概率向量;
7、s4:通过n2×n2编码单元的划分预测概率向量结合对应n1×n1编码单元的预测编码深度,确定每个n2×n2编码单元及其子编码单元的划分模式候选列表;
8、s5:对于待编码视频帧中的每个n1×n1编码单元均执行步骤s3至s4,获取每个n1×n1编码单元中的每个n2×n2编码单元及其子编码单元的划分模式候选列表;对于每个编码单元,从其划分模式候选列表中选择率失真成本最小的划分模式作为其编码结果。
9、优选的,步骤s2中,d-cnn模型包括依次首尾连接的输入层、卷积层、批归一化层、relu函数层、第一个融合模块、第二个融合模块、第一个最大池化层、第三个融合模块、第四个融合模块、第二个最大池化层、flatten层、全连接层和softmax激活函数层;
10、第一个至第四个融合模块均包括依次首尾连接的卷积层、批归一化层、relu函数层、卷积层、批归一化层、sum层和relu函数层;其中每个融合模块的输入均通过卷积层和批归一化层处理后与sum层的输入进行残差连接。
11、优选的,步骤s2中,训练d-cnn模型时的损失函数如下:
12、
13、式中:nd为每个训练批次中n1×n1编码单元的训练样本数量;为真实编码深度;为d-cnn输出的预测编码深度。
14、优选的,步骤s2中,d-cnn模型的输出包括六个编码深度概率及其索引值,通过如下步骤选取最优的编码深度概率对应的索引值作为预测编码深度:
15、s201:从所有编码深度概率中选取最大的编码深度概率pd[u1];
16、s202:判断最大的编码深度概率pd[i1]是否超过预设值:若是,则将最大的编码深度概率pd[i1]对应的索引值i1作为预测编码深度;否则,执行步骤s203;
17、s203:将最大的编码深度概率pd[i1]设置为0并删除,从剩余的所有编码深度概率中选取最大的编码深度概率pd[i2];
18、s204:选择索引值i1和u2中较大的索引值max[u1,i2]作为预测编码深度。
19、优选的,步骤s3中,p-cnn模型包括依次首尾连接的输入层、卷积层、批归一化层、relu函数层、第一个融合模块、第二个融合模块、第一个最大池化层、第三个融合模块、第四个融合模块、第二个最大池化层、第五个融合模块、第六个融合模块、第三个最大池化层、flatten层、全连接层和sigmoid激活函数层;
20、第一个至第六个融合模块均包括依次首尾连接的卷积层、批归一化层、relu函数层、卷积层、批归一化层、sum层和relu函数层;其中每个融合模块的输入均通过卷积层和批归一化层处理后与sum层的输入进行残差连接。
21、优选的,步骤s3中,将一个n2×n2编码单元划分为若干个4×4编码单元;
22、p-cnn模型针对每个n2×n2编码单元的输出包括:该n2×n2编码单元中的所有4×4编码单元除去该n2×n2编码单元自身边界之外的所有边界的划分预测概率向量;其中某个边界的划分预测概率接近1,则表示该边界存在,即会被进一步划分;某个边界的划分预测概率接近0,则表示该边界不存在,即不会被进一步划分;
23、通过如下公式计算划分预测概率向量的维度np:
24、
25、式中:nw为n2×n2编码单元的宽度;nh为n2×n2编码单元的高度。
26、优选的,步骤s3中,训练p-cnn模型时的损失函数如下:
27、
28、式中:n为每个训练批次中n2×n2编码单元的训练样本数量;ypi为样本真实的边界概率向量;表示p-cnn输出的边界划分预测概率向量。
29、优选的,步骤s4中,通过如下步骤确定n2×n2编码单元及其子编码单元的划分模式候选列表:
30、s401:为当前编码单元生成划分模式候选列表;
31、s402:遍历当前编码单元的划分模式候选列表中的每种划分模式,选择率失真成本最小的划分模式作为当前编码单元的最优划分模式;
32、s403:通过最优划分模式对当前编码单元进行划分,得到若干个下一个尺寸的子编码单元;
33、s404:返回步骤s401,将子编码单元作为当前编码单元;
34、s405:重复执行步骤s401至s404,直至当前编码单元的编码深度大于或等于预测编码深度或当前编码单元已为最小编码单元;
35、s406:获取n2×n2编码单元及其子编码单元的划分模式候选列表。
36、优选的,步骤s401中,通过如下步骤确定编码单元的划分模式候选列表:
37、s4011:为当前编码单元创建划分模式候选列表;
38、s4012:判断当前编码单元的编码深度是否大于或等于预测编码深度:若是,则提前终止并执行步骤s4020;否则,执行步骤s4013;
39、s4013:基于n2×n2编码单元的划分预测概率向量计算当前编码单元的五种划分模式的概率;其中五种划分模式包括qt模式、btv模式、bth模式、ttv模式和tth模式;
40、s4014:将最大概率的划分模式加入到划分模式候选列表中;
41、s4015:判断最大概率的划分模式是否为qt模式:若是,则执行步骤s4016;否则,执行s4017;
42、s4016:判断是否满足abs(pbtv-pbth)>β:若是,则将btv模式和bth模式中概率较大的加入到划分模式候选列表中,并执行步骤s4020;否则直接执行步骤s4020;
43、s4017:判断是否满足最大概率类型是bth模式或是tth模式:若是则执行s4018步骤;否则,执行s4019步骤;
44、s4018:判断是否满足abs(pbth-ptth)<β:若是,则把tth模式或bth模型加入到划分模式候选列表中,并执行步骤s4020;否则直接执行步骤s4020;
45、s4019:判断是否满足abs(pbtv-pttv)<β:若是:则把ttv模式或btv模式加入到划分模式候选列表中,并执行步骤s4020;否则直接执行步骤s4020;
46、s4020:输出当前编码单元的划分模式候选列表,并执行下一个编码深度。
47、优选的,步骤s4013中,通过如下公式计算五种划分模式的概率:
48、1)qt模式
49、
50、2)btv模式
51、
52、3)bth模式
53、
54、4)ttv模式
55、
56、5)tth模式
57、
58、式中:pqt、pbtv、pbth、pttv、ptth分别表示qt模式、btv模式、bth模式、ttv模式和tth模式的概率;w和h分别表示当前编码单元的宽和高;xc和yc表示当前编码单元在待编码视频帧中的坐标;xp和yp表示32×32编码单元在待编码视频帧中的坐标;p表示划分预测概率向量。
59、本发明中基于深度学习的vvc帧内快速编码优化方法与现有技术相比,具有如下有益效果:
60、本发明充分利用了编码过程中的编码单元的编码深度信息以及划分模式信息,设计了两阶段的vvc帧内快速编码预测框架。首先,在第一阶段使用d-cnn以及深度决策后处理方法预测n1×n1(如64×64)编码单元的最大编码深度,考虑了编码深度对vvc帧内编码复杂度的影响,有助于提前终止率失真优化过程,能够避免在简单纹理下对深层次编码单元的划分模式搜索,从而降低vvc帧内编码的复杂度。其次,在第二阶段使用p-cnn生成每个n2×n2(如32×32)编码单元的划分预测概率向量,进而结合划分候选列表决策方式确定每个n2×n2编码单元及其子编码单元的划分模式候选列表,这有利于确定编码单元的最优划分模式,并跳过不必要的划分模式,从而进一步降低vvc的编码复杂度。最后,为了避免因神经网络推理造成编码以外大量时间开销,本发明使用p-cnn一次性推理预测多个n2×n2编码单元及其子编码单元的划分模式,极大地缩减了模型推理的时间开销;同为了应对p-cnn存在的错误预测导致编码性能下降,本发明还设计了一种p-cnn后处理方法来避免错误预测导致编码性能的下降。