一种基于人工智能的视频加密方法与流程
本发明涉及视频加密相关领域,具体为一种基于人工智能的视频加密方法。
背景技术:
1、随着互联网的发展和多媒体技术的进步,视频作为信息传播的重要媒介,已经广泛应用于各个领域。然而,视频内容的保密性和安全性成为了一个重要问题。传统的视频加密方法主要依赖于对视频数据进行加密,但这些方法在面对日益复杂的攻击手段时显得力不从心。因此,亟需一种更加智能、高效的加密方法来保证视频数据的安全性。
技术实现思路
1、本发明的目的在于提供一种基于人工智能的视频加密方法,以解决上述背景技术中提出的问题。
2、1.为实现上述目的,本发明提供如下技术方案:一种基于人工智能的视频加密方法,包括以下步骤:
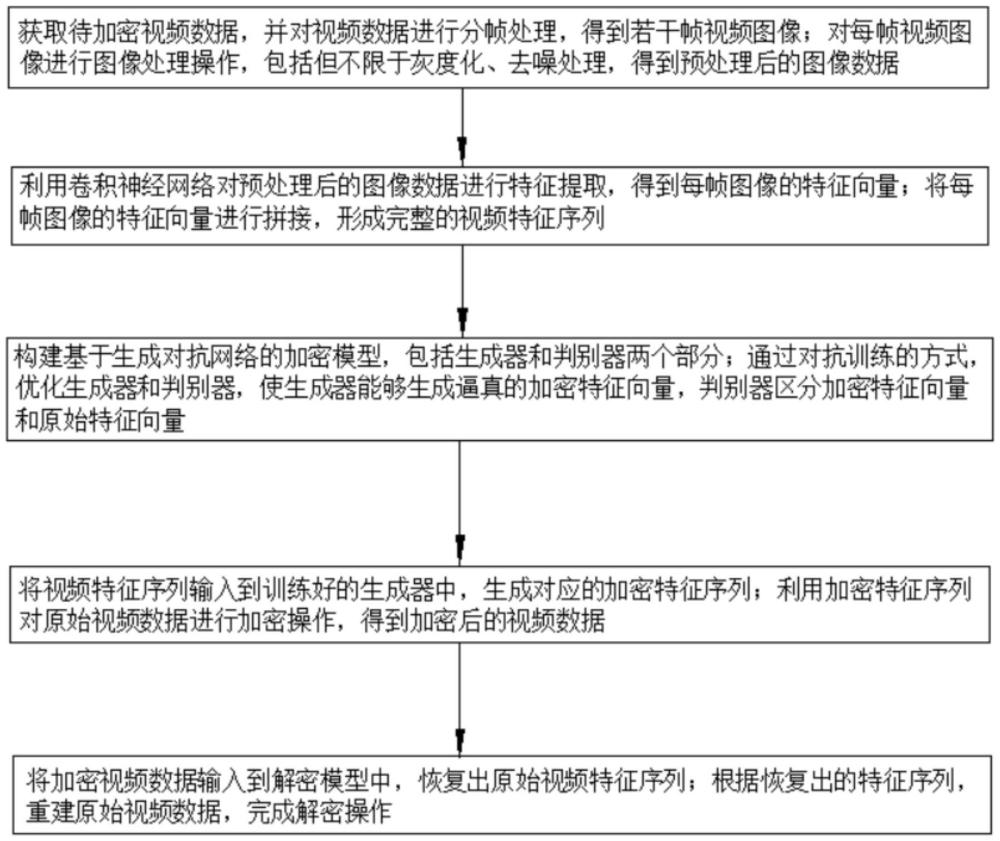
3、步骤1、视频数据预处理:获取待加密视频数据,并对视频数据进行分帧处理,得到若干帧视频图像;对每帧视频图像进行图像处理操作,包括但不限于灰度化、去噪处理,得到预处理后的图像数据;
4、步骤2、特征提取:利用卷积神经网络对预处理后的图像数据进行特征提取,得到每帧图像的特征向量;将每帧图像的特征向量进行拼接,形成完整的视频特征序列;
5、步骤3、加密模型训练:构建基于生成对抗网络的加密模型,包括生成器和判别器两个部分;通过对抗训练的方式,优化生成器和判别器,使生成器能够生成逼真的加密特征向量,判别器区分加密特征向量和原始特征向量;
6、步骤4、视频加密:将视频特征序列输入到训练好的生成器中,生成对应的加密特征序列;利用加密特征序列对原始视频数据进行加密操作,得到加密后的视频数据;
7、步骤5、视频解密:将加密视频数据输入到解密模型中,恢复出原始视频特征序列;根据恢复出的特征序列,重建原始视频数据,完成解密操作。
8、优选的,所述步骤1中获取待加密视频数据,并对视频数据进行分帧处理,得到若干帧视频图像的具体步骤如下:
9、步骤11、视频数据获取:通过摄像设备、网络下载、或从本地存储中读取方式获取待加密的视频文件,同时确保视频文件的格式和编码方式适合后续处理;
10、步骤12、视频数据加载:使用视频处理库,具体使用opencv加载视频文件,确保视频能够被成功读取并进行后续处理;
11、步骤13、分帧处理:初始化帧计数器,用于记录和控制每一帧的读取和处理,循环读取步骤12中加载的视频的每一帧图像,直到视频结束,将每一帧图像存储在内存中,或者保存为图像文件以备后续处理;
12、步骤14、帧图像存储:将提取的帧图像存储到指定的目录或数据结构中,确保每一帧都有唯一的标识;
13、步骤15、帧数据验证:验证提取的帧图像的完整性和质量,确保没有丢帧或损坏的情况发生;随机选择若干帧进行显示或保存,手动检查图像质量。
14、优选的,所述步骤2中特征提取具体步骤如下:
15、步骤21、准备图像数据:将预处理后的帧图像调整为cnn模型所需的输入尺寸,对图像数据进行归一化处理,使其适应模型的输入要求;
16、步骤22、特征提取:使用预训练的cnn模型对每一帧图像进行前向传播,提取特征向量,特征向量看作是高维空间中的点,表示图像的高级特征,具体为:给定输入图像ii,其特征向量fi通过cnn模型m提取,公式如下:[fi=m(ii)],其中ii表示第i帧图像,m表示cnn模型,fi表示提取的特征向量;
17、步骤23、特征向量展平:提取的特征向量是高维张量,具体为:对于特征向量fi的展平操作记为flattlen(fi),公式如下:[fi=flattlen(fi)],其中fi表示展平后的特征向量;
18、步骤24、特征向量拼接:将所有帧的特征向量按时间顺序拼接成一个完整的视频特征序列,具体的,给定一系列帧的特征向量f1,f2,…,fn,拼接操作记为:[\text{videofeaturesequence}=[flatten(f1),flatten(f2),…,flatten(fn))]],其中n表示视频的帧数,\text{videofeaturesequence}表示完整的视频特征序列;
19、步骤25、特征序列归一化:对拼接后的特征序列进行归一化处理,确保数据的尺度统一,便于后续的加密操作,归一化使用标准化方法,将数据转换到零均值和单位方差的分布中。
20、优选的,所述步骤3中加密模型训练的具体步骤如下:
21、步骤31、生成器模型:生成器的目标是接受输入特征向量并生成与原始特征向量相似的加密特征向量,具体的,给定输入特征向量\mathbf{z},生成器g生成加密特征向量\mathbf{g(z)},公式如下:[\mathbf{g(z)}=g(\mathbf{z})],其中\mathbf{z}是随机噪声向量;
22、步骤32、判别器模型:判别器的目标是区分真实的原始特征向量和生成器生成的加密特征向量,具体的,给定输入特征向量mathbf{x},判别器d输出其为真实特征向量的概率d(\mathbf{x}),公式如下:[d(\mathbf{x})=\text{sigmoid}(f(\mathbf{x}))],其中f(\mathbf{x})是判别器的输出,\text{sigmoid}函数将其映射到[0,1]区间;
23、步骤33、判别器的损失函数:判别器最大化其正确分类真实特征向量和生成的加密特征向量的能力,具体的,判别器的损失函数\mathcal{l}d定义为以下交叉熵损失:[\mathcal{l}d=―\mathbb{e}{\mathbf{x}~p{\text{data}}(\mathbf{x})}[\logd(\mathbf{x})]―\matgbb{e}{\mathbf{z}~p{mathbf(z)}(\mathbf{z})}[\log(1―d(g(\mathbf{z})))]],其中p{\text{data}}(\mathbf{x})是真实特征向量的分布,p{mathbf(z)}(\mathbf{z})是噪声向量的分布;
24、步骤34、生成器的损失函数:生成器最大化判别器对其生成的加密特征向量判断为真实特征向量的概率,生成器的损失函数\mathcal{l}g定义为以下交叉熵损失:[\mathcal{l}g=―\mathbb{e}{\mathbf{z}~p{\mathbf{z}}(\mathbf(z))}[\logd(g(\mathbf{z}))]],其中生成器的目标是使d(g(\mathbf{z})接近1,即判别器生成的特征向量是来自真实分布的;
25、步骤35、通过交替优化生成器和判别器,使得生成器生成逼真的加密特征向量,判别器有效区分加密特征向量和原始特征向量,具体步骤如下:
26、a、从真实特征向量分布p{\text{data}}(\mathbf{x})中采样一批真实特征向量\mathbf{x};
27、b、从噪声分布p{mathbf(z)}(\mathbf{z})中采样一批噪声向量mathbf{z};
28、c、使用生成器生成一批加密特征向量\mathbf{g(z)};
29、d、计算判别器的损失\mathcal{l}d,并更新判别器的参数以最小化该损失;
30、e、计算生成器的损失\mathcal{l}g,并更新生成器的参数以最小化该损失。
31、优选的,所述步骤4中视频加密的具体步骤如下:
32、步骤41、准备视频特征序列:从步骤3中获取的视频特征序列\mathbf{x}=\mathbf{x}1,\mathbf{x}2,…,\mathbf{x}n,其中每个\mathbf{x}i是展平后的特征向量;
33、步骤42、输入到训练好的生成器中:将视频特征序列的每个特征向量\mathbf{x}i输入到已经训练好的生成器g中,生成对应的加密特征向量\mathbf{y}i,其中\mathbf{y}i=g(\mathbf(x)i);
34、步骤43、生成加密特征序列:将所有生成的加密特征向量拼接成加密特征序列\mathbf{y}=\mathbf{y}1,\mathbf{y}2,…,\mathbf{y}n,即\mathbf{y}=g(\matbhf{x}=[g(\mathbf{x}1),g(\matbhf{x}2),…g(\mathbf{x}n]),其中\mathbf{y}表示完整的加密特征序列;
35、步骤44、设计加密操作:定义加密操作,利用加密特征序列\mathbf{y}用于调整原始视频帧的像素值,达到加密效果;
36、步骤45、加密视频帧:对于每一帧视频\mathb{i}i,结合对应的加密特征向量\mathbf{y}i进行加密,具体的,假设每帧图像的像素值为\mathb{i}i,加密操作可以定义为:其中是加密后的图像,α是调节因子,控制加密强度,\mathbf{reshape}操作为将加密特征向量调整为与图像尺寸一致的形状;
37、步骤46、生成加密视频:将所有加密后的帧重新组合成一个完整的视频。
38、优选的,所述步骤5视频解密的具体步骤如下:
39、步骤51、准备加密视频特征序列:从加密视频数据中提取加密特征序列\mathbf{y}=\mathbf{y}1,\mathbf{y}2,…,\mathbf{y}n,其中每个\mathbf{y}i是加密特征向量;
40、步骤52、输入到解密模型中:将加密特征序列的每个加密特征向量\mathbf{y}i输入到预设训练好的解密器d中,恢复对应的原始特征向量具体公式为:
41、步骤53、生成恢复特征序列:将所有恢复的特征向量拼接成恢复特征序列具体公式为:其中表示恢复的原始视频特征序列;
42、步骤54、设计解密操作:利用恢复出的特征序列来重建原始视频帧,通过逆向操作或使用解码网络将特征向量转回图像;
43、步骤55、对于每一恢复特征向量通过解码网络e生成对应的原始视频帧具体公式如下:
44、步骤56、将所有重建的帧重新组合成一个完整的视频,具体为:
45、与现有技术相比,本发明的有益效果是:本发明通过生成器对视频特征序列进行加密处理,使得未经授权的用户即使获得了加密视频数据,也无法观看或解析其中内容,从而有效防止数据泄露;通过利用训练好的生成器逆过程构建解密模型,保证了从加密特征序列恢复出原始视频特征序列的高准确性和可靠性,确保解密后的视频质量;通过对解密模型的优化训练,能够有效减少误差,进一步提高解密后的视频数据与原始视频数据的相似性;本发明方案能够对用户视频数据进行全面加密处理,只有通过特定解密模型才能还原视频内容,从而保护用户隐私,防止敏感信息泄露,通过解密模型的授权管理,确保只有经过授权的用户才能访问和解密视频数据,实现了精细化的权限控制;本发明利用生成对抗网络的特性,实现了高效的视频加密与解密处理,能够在保证安全性的前提下,不显著增加系统的计算和存储负担,且本发明能够与现有的视频处理系统无缝集成,通过适当的接口和模块设计,便于在各种应用场景中推广和使用。
- 还没有人留言评论。精彩留言会获得点赞!