基于人工智能的数字人视频生成方法、装置、设备及介质与流程
本技术涉及人工智能开发与金融科技领域,尤其涉及基于人工智能的数字人视频生成方法、装置、计算机设备及存储介质。
背景技术:
1、随着人工智能技术的飞速发展,人脸重建技术作为图像处理领域的核心技术之一,在智能设备及数字人生成领域展现出了巨大的应用潜力。然而,尽管当前已有许多金融企业致力于数字人生成技术的研究与应用,该领域仍面临诸多挑战,导致生成的数字人在真实感、自然度及多样性方面存在不足。
2、目前,三维人脸模型(3dmm)是目前广泛使用的数字人建模方法之一。该模型通过学习大量人脸图像数据,构建基础的三维人脸表示,并通过线性或非线性组合来生成新的人脸模型。然而,3dmm的低维表征能力限制了其准确表达高频信息的能力,如皱纹、酒窝等细微面部特征。这导致生成的数字人脸部过于平滑,缺乏真实感,难以满足对细节丰富度要求较高的应用场景。
技术实现思路
1、本技术实施例的目的在于提出一种基于人工智能的数字人视频生成方法、装置、计算机设备及存储介质,以解决现有的基于三维人脸模型的数字人建模方法生成的数字人脸部过于平滑,缺乏真实感的技术问题。
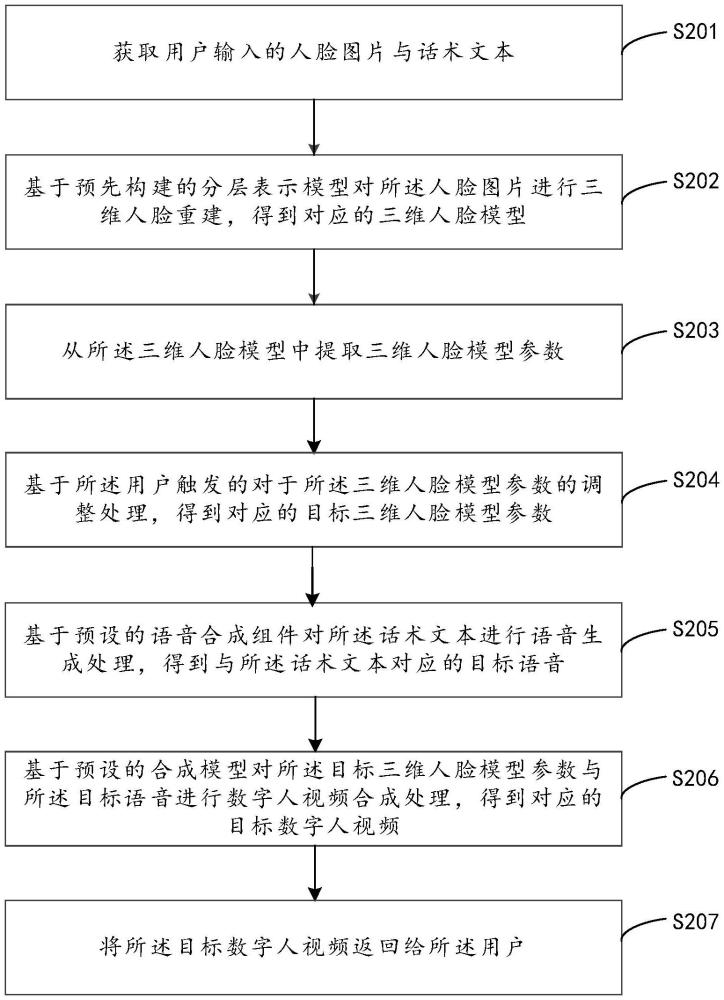
2、为了解决上述技术问题,本技术实施例提供一种基于人工智能的数字人视频生成方法,采用了如下所述的技术方案:
3、获取用户输入的人脸图像与话术文本;
4、基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型;其中,所述三维人脸模型基于与所述人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到;
5、从所述三维人脸模型中提取三维人脸模型参数;
6、基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数;
7、基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音;
8、基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频;
9、将所述目标数字人视频返回给所述用户。
10、进一步的,所述分层表示模型至少包括输入层、特征提取层、解耦模块、重建层、融合层以及输出层;所述基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型的步骤,具体包括:
11、将所述人脸图像输入至所述分层表示模型的输入层内;
12、通过所述特征提取层对所述人脸图像进行特征提取,得到对应的面部特征;
13、通过所述解耦模块将所述面部特征解耦为初始低频几何形状特征、初始中频细节特征以及初始高频细节特征;
14、通过所述重建层对所述初始低频几何形状特征、所述初始中频细节特征以及所述初始高频细节特征进行重建处理,得到对应的低频几何形状特征、中频细节特征以及高频细节特征;
15、通过所述融合层对所述低频几何形状特征、所述中频细节特征以及所述高频细节特征进行融合处理,得到对应的三维人脸模型;
16、通过所述输出层输出所述三维人脸模型。
17、进一步的,在所述基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型的步骤之前,还包括:
18、获取预先构建的人脸图像样本数据;
19、调用预设的初始分层表示模型;
20、确定与所述初始分层表示模型对应的目标优化算法;
21、基于所述目标优化算法以及预设的轮廓感知损失函数,使用所述人脸图像样本数据对所述初始分层表示模型进行训练处理,得到训练好的指定模型;
22、将所述指定模型作为所述分层表示模型。
23、进一步的,所述基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数的步骤,具体包括:
24、调用预设的参数调整界面;其中,所述参数调整界面包括所述三维人脸模型参数;
25、展示所述参数调整界面,并接收所述用户在所述参数调整界面中输入的参数调整操作;
26、基于所述参数调整操作对所述三维人脸模型参数进行调整处理,得到调整后的三维人脸模型参数;
27、将所述调整后的三维人脸模型参数作为所述目标三维人脸模型参数。
28、进一步的,所述基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音的步骤,具体包括:
29、调用所述语音合成组件;
30、基于所述语音合成组件对所述话术文本进行文本分析,得到对应的文本分析结果;
31、基于所述文本分析结果,调用预设的语音生成算法对所述话术文本进行语音生成处理,得到对应的第一语音;
32、基于所述第一语音生成所述目标语音。
33、进一步的,所述基于所述第一语音生成所述目标语音的步骤,具体包括:
34、获取预设的参数调整策略与优化策略;
35、基于所述参数调整策略对所述第一语音进行参数调整处理,得到对应的第二语音;
36、基于所述优化策略对所述第二语音进行优化处理,得到对应的第三语音;
37、将所述第三语音作为所述目标语音。
38、进一步的,在所述基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频的步骤之后,还包括:
39、确定与所述目标数字人视频对应的指定存储方式;
40、调用与所述指定存储方式对应的指定存储介质;
41、基于所述指定存储介质对所述目标数字人视频进行存储处理。
42、为了解决上述技术问题,本技术实施例还提供一种基于人工智能的数字人视频生成装置,采用了如下所述的技术方案:
43、第一获取模块,用于获取用户输入的人脸图像与话术文本;
44、重建模块,用于基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型;其中,所述三维人脸模型基于与所述人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到;
45、提取模块,用于从所述三维人脸模型中提取三维人脸模型参数;
46、调整模块,用于基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数;
47、生成模块,用于基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音;
48、合成模块,用于基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频;
49、返回模块,用于将所述目标数字人视频返回给所述用户。
50、为了解决上述技术问题,本技术实施例还提供一种计算机设备,采用了如下所述的技术方案:
51、获取用户输入的人脸图像与话术文本;
52、基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型;其中,所述三维人脸模型基于与所述人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到;
53、从所述三维人脸模型中提取三维人脸模型参数;
54、基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数;
55、基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音;
56、基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频;
57、将所述目标数字人视频返回给所述用户。
58、为了解决上述技术问题,本技术实施例还提供一种计算机可读存储介质,采用了如下所述的技术方案:
59、获取用户输入的人脸图像与话术文本;
60、基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型;其中,所述三维人脸模型基于与所述人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到;
61、从所述三维人脸模型中提取三维人脸模型参数;
62、基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数;
63、基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音;
64、基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频;
65、将所述目标数字人视频返回给所述用户。
66、与现有技术相比,本技术实施例主要有以下有益效果:
67、本技术首先获取用户输入的人脸图像与话术文本;然后基于预先构建的分层表示模型对所述人脸图像进行三维人脸重建,得到对应的三维人脸模型;其中,所述三维人脸模型基于与所述人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到;之后从所述三维人脸模型中提取三维人脸模型参数;并基于所述用户触发的对于所述三维人脸模型参数的调整处理,得到对应的目标三维人脸模型参数;后续基于预设的语音合成组件对所述话术文本进行语音生成处理,得到与所述话术文本对应的目标语音;进一步基于预设的合成模型对所述目标三维人脸模型参数与所述目标语音进行数字人视频合成处理,得到对应的目标数字人视频;最后将所述目标数字人视频返回给所述用户。本技术基于分层表示模型的使用,并引入了三种层次化的表征,即低频几何形状、中频细节和高频细节,能够更全面地捕捉人脸的各个层面特征。通过基于与用户输入的人脸图像对应的低频几何形状特征、中频细节特征以及高频细节特征构建得到相应的三维人脸模型,有效地提高了三维人脸重建的精准性和细节还原度,提高了生成的三维人脸模型的真实感。使得后续通过使用合成模型对由三维人脸模型相对应的目标三维人脸模型参数,以及与用户输入的话术文本目标语音进行数字人视频合成处理,可以生成高度真实的目标数字人视频,有效地提高了生成的目标数字人视频的真实感。
- 还没有人留言评论。精彩留言会获得点赞!