一种人工智能辅助音乐剪辑的方法、装置、设备及存储介质
本技术涉及人工智能领域,特别涉及一种人工智能辅助音乐剪辑的方法、装置、设备及存储介质。
背景技术:
1、短视频程序是以用户原创拍摄的短视频,作为网络传播内容的分享平台。在短视频程序中,用户存在对音乐片段进行选取的需求。
2、在短视频程序上提供有音乐剪辑界面,该音乐剪辑界面上有音乐显示控件,通常包含音乐进度条、音乐声谱图、音乐歌词图中的一种或多种,该音乐剪辑界面上有片段选取控件(比如竖线或圆头针状指示器),通过在选取控件在音乐播放进度条、音乐声谱图、音乐歌词图所指向的位置,短视频程序根据片段选取控件所指向的位置,结合短视频程序的音乐片段选取规则,例如预置推荐音乐片段,来确定被选音乐片段。由于(a)用户通常是根据歌词段落来选择期望的音乐片段,通过播放进度条、音乐声谱图等方式进行选择不符合用户习惯,增加了用户的使用成本,(b)播放进度条、音乐声谱图的长度有限,用户的手指滑动操作的精度较低,很难准确地定位到一段音乐中的某一秒或一毫秒,用户很难准确地选择到期望选择的音乐片段,(c)预置音乐段落剪辑方案作为候选推荐方案,无法覆盖所有用户期望选择的音乐片段,因此目前的剪辑音乐片段的技术方案的易用性、高效性、灵活性有待提高。
技术实现思路
1、针对现有技术中的问题,本发明提供一种人工智能辅助音乐剪辑的方法、装置、设备及存储介质。
2、为了实现上述目的本发明采用以下技术方案:
3、第一方面,本发明提供一种人工智能辅助音乐剪辑的方法,包括以下步骤:
4、基于乐曲的基本结构信息,构建乐曲数据库,所述乐曲数据库包括:乐曲层次结构,即乐句、乐段、前间奏片段之间的排列组合层次,含歌词的乐句、乐段及相应的歌词逐字文本-时间戳数据对、一个或多个前间奏片段起止时间戳;
5、确定被选音乐片段的选择范围,终端根据被选音乐片段识别出其对应的数据库内的存储乐句和/或乐段的歌词逐字文本-时间戳数据和/或前间奏音乐数据;并以对应的存储乐句和/或乐段作为被选片段,储存的前间奏片段作为被选前间奏片段;
6、输出目标音乐,目标音乐包含被选的一个或多个乐句,
7、或,一个乐段和/或一个或多个前间奏片段,
8、或,多个乐段和/或一个或多个前间奏片段。
9、在所述人工智能辅助音乐剪辑的方法中,进一步地,一个乐段包含多个乐句。
10、在所述人工智能辅助音乐剪辑的方法中,进一步地,所述歌词逐字文本-时间戳数据包括数据库内存取的音乐片段的歌词文本的起终点和对应的时间戳数据对。
11、在所述人工智能辅助音乐剪辑的方法中,进一步地,所述前间奏片数据包括前间奏音乐片段的起止时间戳。
12、在所述人工智能辅助音乐剪辑的方法中,进一步地,确定被选音乐片段的方法为:通过定位点击或双击操作的位置,将其覆盖的一个或多个乐句或前间奏片段识别为选定的音乐片段;或者,通过检测滑动操作的范围,将其覆盖的一个或多个乐句或或前间奏片段识别为选定的音乐片段;或者,通过解析语音指令,将其中指定的音乐片段识别为选定的音乐片段之一。
13、在所述人工智能辅助音乐剪辑的方法中,进一步地,当用户首次选择的被选片段为多个乐句,且被选片段的起点与乐段的起点相同或被选片段终点与乐段终点相同时,则提示是否选择对应乐段作为被选片段,若用户选择否,则将对应多个乐句作为被选片段;若用户选择是,则将覆盖上述多个乐句的乐段重设作为被选片段;当重设后的被选片段为乐段,且该被选片段起点与一个或多个前间奏片段终点相同或该被选片段终点与一个或多个前间奏片段起点相同时,提示是否选择前间奏选取控件,若用户选择否,则将对应乐段作为输出的目标音乐;若用户选择是,则将乐段和前间奏片段重设作为输出的目标音乐。
14、以用户期望选取某首歌的某一片段为例。例如用户期望选取某个片段,该首歌曲由(a)前奏、(b)主歌段落1、(c)主歌段落2、(d)副歌段落1、(e)副歌段落2、(f)间奏、(g)副歌段落1、(h)主歌段落2,(i)副歌段落1、(j)副歌段落2、(k)尾声顺序连接而成。
15、a当用户期望选取的片段为(h)中的两个乐句,
16、即“
17、o p ......q
18、r...... s t”,
19、即2分53秒568毫秒的“o”至3分01秒122毫秒的“t”。用户滑动音乐歌词图至该片段中的“o p ......q”中的任一个文本和“r...... s t”中的任一个文本,触发终端在播放进度条或音乐声谱图上自动选中2分53秒568毫秒至的至3分01秒122毫秒的“o p...... q.,r...... s t”的音乐片段。
20、b当用户期望选取的片段为(g)(h)的多个乐句,
21、即“a b c d.....e f g,......,r ......s t”,
22、即1分22秒362毫秒的“a”至3分01秒122毫秒的“t”。用户滑动音乐歌词图至该片段中的“a b c d.....e f g”中的任一个文本和“x......y z”中的任一个文本,触发终端在播放进度条或音乐声谱图上自动选中1分22秒362毫秒至的至3分01秒122毫秒的“a b c d...... e f g,......,x......y z”的音乐片段。
23、此时,本例中被选音乐片段的“r...... s t”与乐段(h)的起点相同,在音乐剪辑页面上提示是否选择对应乐段(g)(h)作为被选片段,若用户选择否,则将对应多个乐句作为被选片段;若用户选择是,则将覆盖上述多个乐句的乐段重设作为被选片段。
24、此时,如果用户选择是,将(g)(h)乐段作为被选片段,本例中(g)左侧存在间奏片段(f),在音乐剪辑界面上显示前间奏选取控件,用户点击前间奏选取控件,触发终端在播放进度条或音乐声谱图上自动选中1分03秒129毫秒至3分01秒122毫秒的包含该乐段和间奏的音乐片段作为输出的目标音乐,即(f)(g)(h)。
25、第二方面,本发明提供上述人工智能辅助音乐剪辑的方法在视频编辑中的应用。
26、进一步地,所述人工智能辅助音乐剪辑的方法在视频编辑中的应用,包括以下步骤:
27、步骤1,获取短视频的视频长度;
28、步骤2,根据短视频的视频长度、目标音乐时长、存储乐段时间戳和前间奏时间戳确定剪辑音乐片段时间戳以及剪辑音乐片段与短视频的对齐时间戳。
29、进一步地,确定剪辑音乐片段时间戳的方法包括:
30、短视频的视频长度减去目标音乐片段的时长,得到相减后的时长。
31、当相减后的时长小于等于0,将剪辑音乐片段的起点设为目标音乐片段的起点,将剪辑音乐片段的终点重设为目标音乐片段的起点与短视频的视频长度相加后的时间戳。
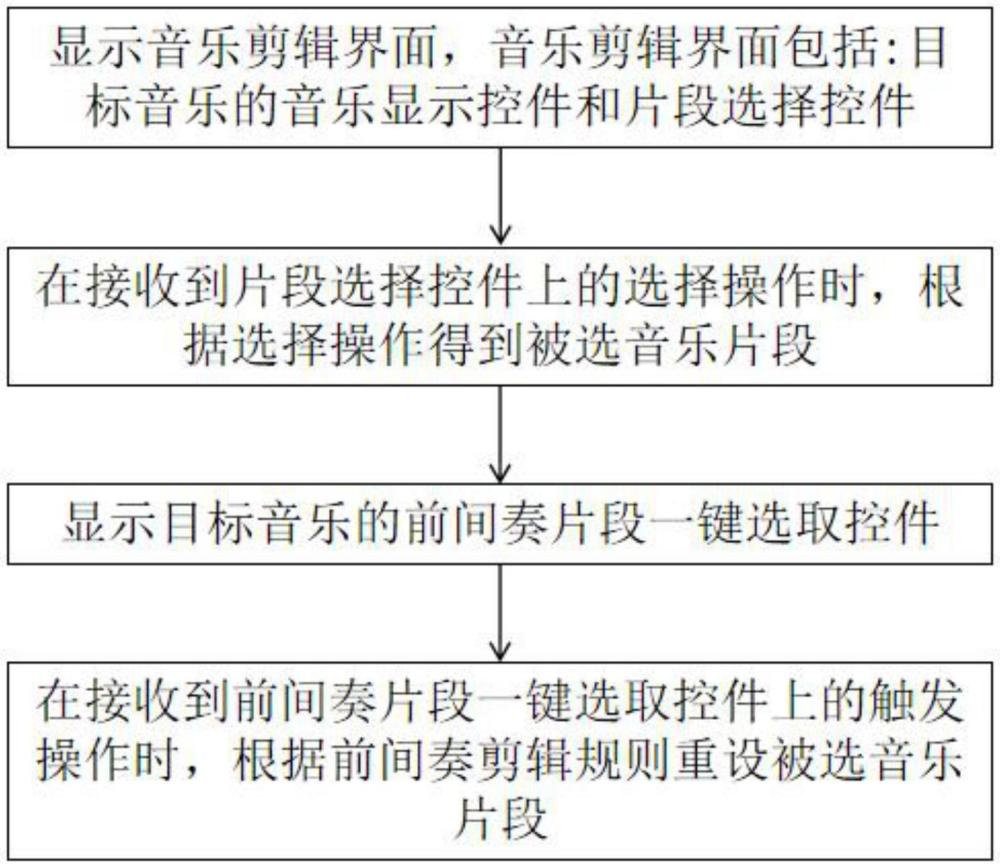
32、当相减后的时长大于0且小于阈值,将剪辑音乐片段的起点设置为目标音乐片段的起点,将剪辑音乐片段的终点重设为目标音乐片段的终点。
33、当相减后的时长大于某个大于0的阈值,确定剪辑音乐片段起止时间戳的方法为:
34、遍历目标音乐片段左侧前间奏、右侧前间奏的时长、左侧前间奏与右侧前间奏的相加时长,得到与相减后时长最后接近的片段作为前间奏片段,将剪辑音乐片段的起点设置为存储乐句片段的起点与前间奏片段起点中较小者,将剪辑音乐片段的起点设置为被选音乐片段的终点与前间奏片段终点中较小者的起点,将剪辑音乐片段的终点设置为前间奏片段起点、被选音乐片段的起点较大者的终点。
35、终端根据短视频的视频长度、剪辑音乐片段时间长度确定剪辑音乐片段与短视频的视频长度确定对齐时间戳。
36、第三方面,本发明还提供了人工智能辅助音乐剪辑的装置,所述装置包括:
37、显示模块,用于显示音乐剪辑界面,所述音乐剪辑界面包括:被选音乐的音乐显示控件和片段选择控件;显示所述被选音乐的前间奏音乐片段的前间奏选取控件;
38、交互模块,用于接收到所述片段选择控件上的选择操作;接收所述前间奏选取控件上的触发操作;
39、获取模块,用于在接收到所述片段选择控件上的选择操作时,根据所述选择操作得到与被选音乐对应的存储乐句片段;
40、重设模块,在接收到所述前间奏选取控件上的触发操作时,根据所述选择操作和前间奏片段重设所述被选音乐片段得到目标音乐。
41、第四方面,本发明还提供了一种计算机设备,所述计算机设备包括:处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上方面所述的人工智能辅助音乐剪辑方法。
42、第五方面,本发明还提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上方面所述的人工智能辅助音乐剪辑方法。
43、本发明有益效果:
44、本技术通过获取音乐歌词文本-时间戳数据对和前间奏时间戳数据,并通过音乐显示控件、片段选择控件、前间奏选取控件的的组合操控流程,使得用户在目标音乐上手动选取音乐片段时,降低手动定位音乐片段时的难易程度,更灵活高效快速地选取出被选音乐片段,使音乐剪辑快速高效。
45、本技术的特色在于人工智能辅助音乐剪辑的过程中应用了乐曲的基本结构信息,从而使剪辑出的音乐片段更符合用户(尤其是非音乐专业的用户)所希望表达的潜在音乐形象情绪。具体的,从音乐专业角度而言,乐句是构成乐段的基本元素,乐句之间的组合和排列,形成了乐段的独特风格,表达了乐段的独特形象,乐段之间通过前间奏的衔接和过渡,表达了乐曲的独特风格和形象。本技术自动识别乐曲结构及其对应的时间戳来实现,通过分割乐段、乐句和前间奏,并获取其各层次元素的起止时间戳及乐曲歌词文本的逐字时间戳来辅助完成音乐剪辑。
- 还没有人留言评论。精彩留言会获得点赞!