一种基于隐音素检索的数字人口型多样性增强方法
本发明属于数字人口型动画合成,具体涉及一种基于隐音素检索的数字人口型多样性增强方法。
背景技术:
1、在数字人口型动画合成领域,现有的主流技术方案通常基于音素(phoneme)与视素(viseme)的匹配方法。这一方法首先从语音中提取连续的音素序列,例如:/ni3hɑo3/(你好)、(hello),随后根据音素与预定义视素之间的对应关系,挑选出相应的视素图像,最终将这些图像拼接成流畅的口型动画。
2、音素是人类语言中能够区别意义的最小声音单位,通常通过语音专家手动标注或使用语音识别工具对音频数据进行分段和分类。而视素则指与特定音素相对应的发音器官的可视状态。mpeg-4标准提出了视素的概念,并将其应用于语音动画合成中。
3、市场上已商业化的应用为了降低成本并确保实时性,通常会采用这种方案。首先将输入的语音信号进行音素级分割,识别出连续语音中的各个音素。然后,根据音素到视素的映射关系,确定相应的口型动画。这种方法的优势在于实现相对简单,能够快速地将语音与口型动画进行同步,在算力受限的手机端应用广泛。
4、然而,现有技术存在一些局限性。由于音素和视素的映射关系是基于静态的、离散的状态,这种方法难以捕捉到发音过程中的动态变化和细微差别。此外,不同语言的发音特点和音位组成差异较大,导致现有的音素视素匹配方案在处理某些语言时可能不够准确或自然。
5、此外,对于不同语种,音视素的个数和定义也不尽相同。例如,英语可能需要区分更多的辅音视素,以反映其丰富的辅音结尾和辅音群;汉语中的声母和韵母构成复杂,其视素分类方法多样,从基于声母和韵母的分类到使用聚类方法对音素进行分组,不同的分类方法反映了汉语发音的复杂性。例如,有研究将汉语分为28个基本的静态视位,而微软则将视素分为22个,以适应不同语言的需求。这些分类方法为音素到视素的映射提供了基础,而生成这些音素需要基于语言学的规则,通常通过具备相关专业知识的语音专家手动标注或使用先进的语音识别工具对音频数据进行分段和分类,是一个非常耗时的过程。同时,受人工定义的局限性,离散有限的音素个数在实际应用中仍面临着发音连贯性和动画真实性的挑战。
6、综上所述,尽管现有的音素视素匹配方案在数字人口型动画合成中得到了广泛应用,但其在捕捉自然发音的动态变化和适应不同语言特点方面仍有改进空间。
技术实现思路
1、本发明的目的在于提供一种基于隐音素检索的数字人口型多样性增强方法,通过引入基于深度学习的隐音素技术,克服现有技术的局限,实现更自然、更连贯的数字人口型动画合成。
2、为实现上述目的,本发明采用了如下技术方案:一种基于隐音素检索的数字人口型多样性增强方法,包括以下步骤:
3、a)数据预处理步骤,对已有数字人说话视频中的音频与视频数据进行预处理,为步骤b)提供预处理后的音频和视频数据;
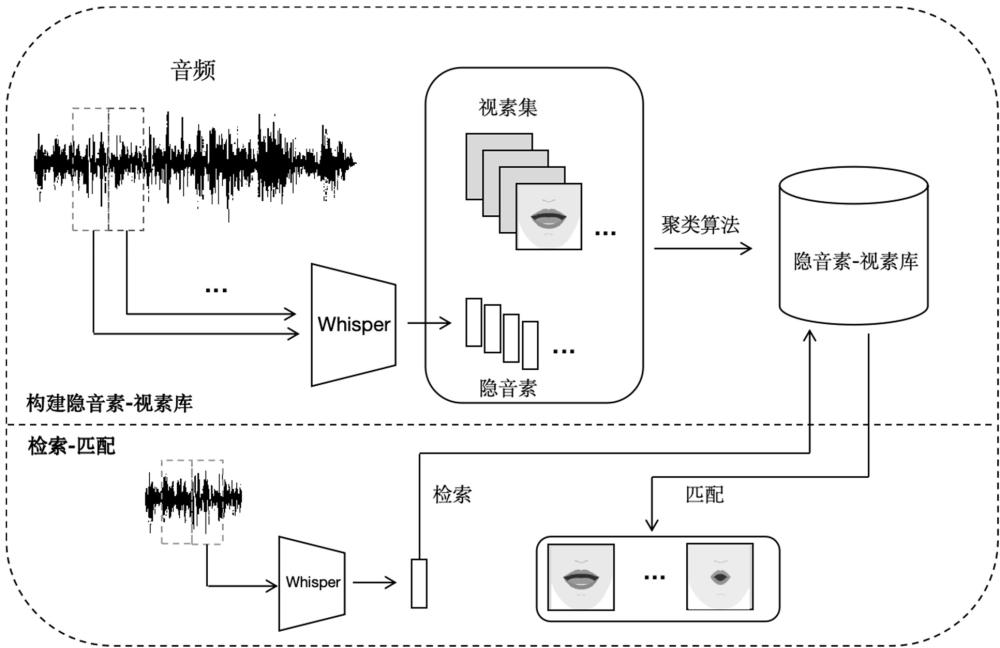
4、b)特征提取步骤,利用深度音频特征编码器对步骤a)中预处理后的音频数据进行特征提取,生成特征向量,步骤b)生成的特征向量作为步骤c)的输入;
5、c)隐音素生成步骤,使用聚类算法对步骤b)中提取的音频特征向量进行聚类,生成代表不同隐音素的中心特征向量,步骤c)生成的隐音素用于步骤d)中的隐音素-视素库构建;
6、d)隐音素-视素库构建步骤,将步骤c)生成的隐音素与对应的视频图片帧关联,形成一个包含多种发音口型的视素图库,步骤d)构建的库为步骤e)提供隐音素和视素图;
7、e)音频的隐音素检索步骤,在数字人与用户实时交互过程中,将音频片段通过深度音频特征编码器转换为特征向量,并与步骤d)构建的隐音素集合计算距离或相似度,检索出最匹配的视素口型图片序列,步骤e)检索的结果用于步骤f);
8、f)视素图匹配步骤,根据步骤e)检索到的隐音素口型图片序列,从步骤d)构建的库中匹配相应的视素图,步骤f)匹配的视素图为步骤g)提供口型序列;
9、g)口型序列合成步骤,按照时序顺序组合步骤f)中匹配的视素图,生成连贯的数字人口型动画,步骤g)合成的动画为步骤h)提供基础;
10、h)动态匹配机制步骤,在实时音频处理过程中,动态调整隐音素和视素数量和匹配关系以优化口型动画表现力,步骤h)的调整依据步骤i)中反馈的交互体验;
11、i)持续优化与迭代步骤,根据数字人的发音风格和真实交互体验,不断调整隐音素和视素的数量,提升系统的适应性和性能,步骤i)的反馈循环作用于步骤c)至步骤h)。
12、优选的,所述数据预处理步骤a)包括以下子步骤:
13、a1)音频重采样步骤,将所有音频数据重采样至16,000hz,步骤a1)处理后的音频为步骤a2)提供输入;
14、a2)mel频谱图计算步骤,使用25毫秒的窗口和10毫秒的步长对步骤a1)中重采样的音频数据进行滑动分割,并计算80通道的对数mel频谱图,步骤a2)生成的mel频谱图作为步骤a3)的输入;
15、a3)视频帧率转换步骤,将视频转换为每秒25帧,并将视频拆分为单张图片,以确保每帧图片能够对应40ms的音频数据,步骤a3)产生的图片与步骤a2)的mel频谱图共同作为步骤b)的输入。
16、优选的,所述特征提取步骤b)包括以下子步骤:
17、b1)利用whisper模型的编码器部分对步骤a2)生成的mel频谱图数据进行特征提取,此编码器包含两个卷积层、正弦位置编码及4层标准的transformer编码器块;
18、b2)经过步骤b1)的处理后,30秒音频的mel数据被转化为特征向量,每20ms的音频被转为5*384纬的特征向量,步骤b2)生成的特征向量作为步骤c)隐音素生成的输入。
19、优选的,所述隐音素生成步骤c)包括以下子步骤:
20、c1)对步骤b2)中生成的特征向量进行数据预处理,包括对每个特征进行归一化或标准化;
21、c2)在完成步骤c1)的数据预处理之后,选择一个预设的簇数量k,使用k-means聚类算法初始化k个质心,并将步骤b2)中处理后的特征向量分配给最近的质心,形成k个簇,这些簇的中心即为隐音素的中心特征向量;
22、c3)通过重复执行步骤c2)中的分配数据点到最近中心和更新质心的操作,直到质心的变化非常小或达到预定的迭代次数,步骤c3)最终生成的隐音素用于步骤d)中的隐音素-视素库构建。
23、优选的,所述隐音素-视素库构建步骤d)包括以下子步骤:
24、d1)将步骤c3)生成的k个隐音素中心特征向量与对应的视频帧进行关联,这些视频帧是从预处理过的数字人说话视频中提取的,每个视频帧对应于一个特定的口型状态;
25、d2)依据步骤d1)中隐音素中心特征向量与视频帧的关联关系,构建一个由k个隐音素对应的发音口型图片组成的视素图库,该库中的每一个视素图都代表了一个隐音素的发音状态;
26、d3)利用步骤d2)构建的视素图库,在步骤e)中进行隐音素检索机制的实现,即将实时音频处理过程中得到的特征向量与库中的隐音素进行比对,找到最匹配的视素图并合成连贯的口型动画。
27、优选的,所述音频的隐音素检索步骤e)包括以下子步骤:
28、e1)在数字人与用户的实时交互过程中,通过深度音频特征编码器(whisper)将输入的音频片段转换为一系列5*384维的特征向量;
29、e2)对于步骤e1)中获取的每个特征向量,与步骤d2)构建的隐音素集合中的隐音素计算欧几里得距离或余弦相似度;
30、e3)依据步骤e2)计算得到的距离或相似度,从隐音素集合中检索出与当前音频片段最匹配的隐音素,进而确定对应的视素口型图片序列。
31、优选的,所述视素图匹配步骤f)包括以下子步骤:
32、f1)根据步骤e3)检索出的隐音素口型图片序列,确定与之对应的视素图,这些视素图来自于步骤d2)构建的隐音素-视素图库;
33、f2)从步骤d2)的库中提取步骤f1)确定的视素图,作为下一步骤g)中合成连贯数字人口型动画的基础视素图集合;
34、f3)步骤f2)提取的视素图经过排序和组织,形成一个连贯的口型序列。
35、优选的,所述口型序列合成步骤g)包括以下子步骤:
36、g1)将步骤f3)中组织好的视素图按时间顺序排列,确保每一个视素图对应正确的音频时间点;
37、g2)使用图形合成技术将步骤g1)排列好的视素图序列合并成一个连续的动画流,生成逼真的数字人口型动画,为步骤h)中的最终呈现提供基础素材;
38、g3)对步骤g2)生成的动画流进行平滑处理,提升步骤h)中数字人交互的真实感。
39、优选的,所述动态匹配机制步骤h)包括以下子步骤:
40、h1)在实时音频处理过程中,利用步骤f)中提取的隐音素特征,动态检索与之匹配的视素图,并根据实际效果调整隐音素的数量;
41、h2)结合步骤g)中合成的口型动画序列,观察其连贯性和真实性,根据实际应用情况动态调整隐音素和视素的数量,持续优化口型动画;
42、h3)收集步骤i)中用户交互体验的反馈,基于反馈信息,微调步骤h2)中的隐音素和视素的数量及匹配策略。
43、优选的,所述持续优化与迭代步骤i)包括以下子步骤:
44、i1)收集来自数字人与用户的交互数据,包括但不限于用户反馈、系统响应时间和口型动画的一致性评价;
45、i2)基于步骤i1)收集的数据,分析数字人的发音风格和用户的交互体验,动态调整步骤c)中生成的隐音素数量及步骤4)中构建的隐音素-视素库;
46、i3)将步骤i2)中调整后的隐音素和视素图应用于步骤h)中的动态匹配机制,以优化口型动画的表现力,并继续监测用户反馈和系统性能,循环执行步骤i1)至i3),持续提升系统的适应性和性能。
47、本发明的技术效果和优点:本发明提出的一种基于隐音素检索的数字人口型多样性增强方法,与现有技术相比,具有以下优点:
48、本发明通过对已有数字人的音频和视频素材数据进行预处理、特征提取、构建隐音素-视素库、音频的隐音素检索-匹配,最终实现了数字人逼真且连贯的口型动画合成,能够通过优化和迭代,不断提升口型动画的连贯性和真实性,实现了实时生成与音频一致的口型动画,能够不受传统音素数量和专业性的限制,根据不同数字人的发音风格和真实交互体验,动态调整隐音素和视素的数量,从而提升系统的适应性和性能。
- 还没有人留言评论。精彩留言会获得点赞!