一种多路径路由方法、装置、介质和设备
本发明涉及网络通信,特别涉及一种多路径路由方法、装置、介质和设备。
背景技术:
1、近年来,随着互联网技术的不断发展,云计算和大数据等新兴产业迅速崛起,导致数据流量大量集中在数据中心进行存储和管理。数据中心网络(data centernetwork,dcn)作为数据中心基础设施的重要组成部分,负责实现数据中心内部大量计算资源之间的通信。因此,数据中心网络需要高效、灵活的路由算法以应对大规模的流量传输。然而,传统的静态路由算法,如最短路径路由(shortest path routing,spr)或等价多路径路由(equal-cost multi-path routing,ecmp),通常未能充分考虑实际流量特性。这些算法的路由规则建立与网络中的流量分布无关,无法实现最佳性能水平。
2、软件定义网络(software-definednetworking,sdn)扩展了解决相关问题的视野,通过解耦网络中的控制平面和数据平面,使得有效监控网络状态和动态部署网络策略成为可能。因此,sdn非常适合用于实现流路由的优化。然而,流路由算法相对复杂,尽管近几十年来取得了重大进展,但流路由仍然是一种复杂的路由方法,需要详细的通信网络和流量模型。近年来,基于强化学习的无模型人工智能技术已成功应用于各种复杂的控制和优化问题。因此,最近大量研究将强化学习方法应用于路由优化问题。这些研究展示了强化学习在动态环境中自适应和优化决策的潜力,为流路由算法提供了新的解决方案。
3、但是,当网络规模扩大,即网络拓扑结构复杂或节点数量较多时,传统的路由方法难以处理大规模的状态和动作空间,计算资源消耗巨大且难以收敛,同时,在流量路由中往往会为相同源-目标网络节点对选择相同流路径,缺乏多路由路径的灵活性,限制了网络的负载均衡能力,也容易导致局部路径过载。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种多路径路由方法、装置、介质和设备。
2、本发明采用下述技术方案:
3、本发明提供了一种多路径路由方法,包括:
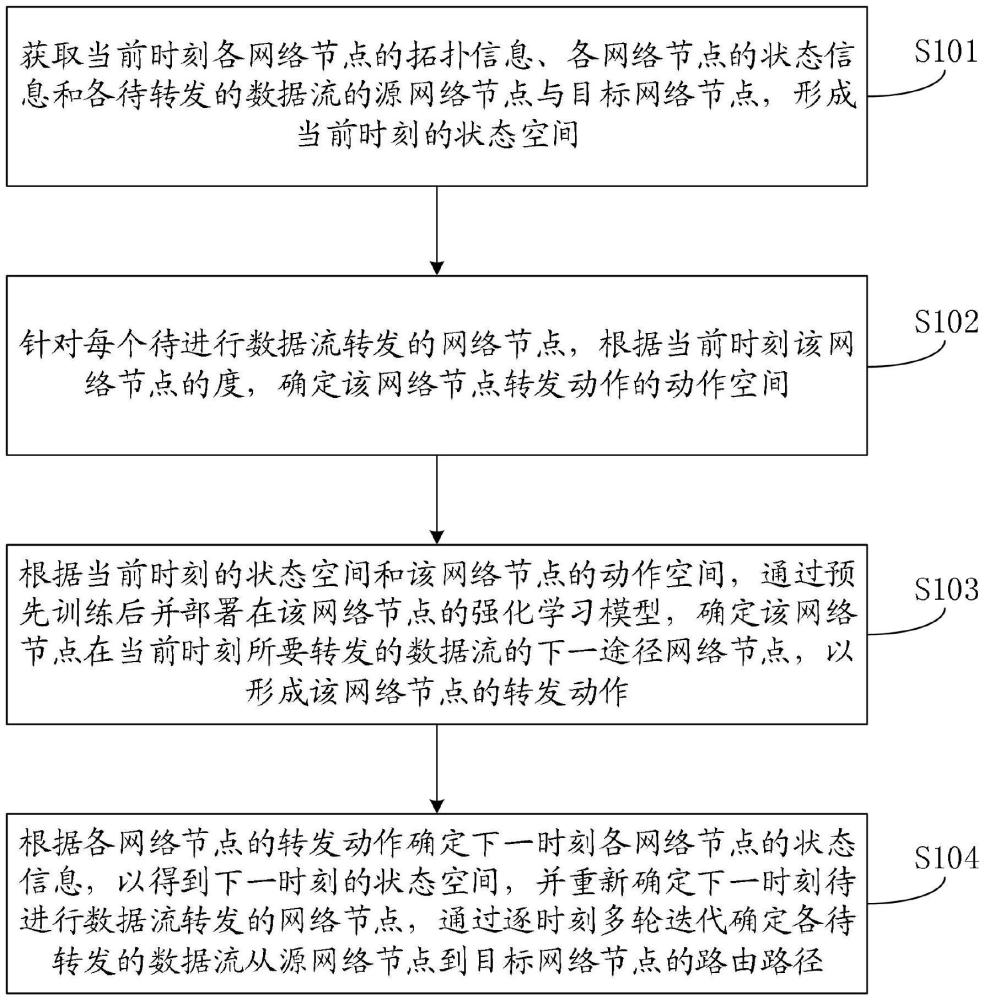
4、获取当前时刻各网络节点的拓扑信息、各网络节点的状态信息和各待转发的数据流的源网络节点与目标网络节点,形成当前时刻的状态空间;
5、针对每个待进行数据流转发的网络节点,根据当前时刻该网络节点的度,确定该网络节点转发动作的动作空间;
6、根据当前时刻的状态空间和该网络节点的动作空间,通过预先训练后并部署在该网络节点的强化学习模型,确定该网络节点在当前时刻所要转发的数据流的下一途径网络节点,以形成该网络节点的转发动作;
7、根据各网络节点的转发动作确定下一时刻各网络节点的状态信息,以得到下一时刻的状态空间,并重新确定下一时刻待进行数据流转发的网络节点,通过逐时刻多轮迭代确定各待转发的数据流从源网络节点到目标网络节点的路由路径。
8、可选地,训练所述强化学习模型,具体包括:
9、针对每个网络节点,通过下式根据历史时刻的状态空间和该网络节点的动作空间,确定该网络节点执行动作空间中每个转发动作后转换到下一时刻的状态空间的奖励:
10、
11、根据历史时刻的状态空间、该网络节点的动作空间以及该网络节点执行动作空间中每个转发动作后转换到下一时刻的状态空间的奖励,通过下式确定该网络节点执行动作空间中每个转发动作的价值:
12、
13、通过多轮迭代得到不同状态空间经各网络节点的动作空间中每个转发动作实现状态转换对应的价值表;
14、其中,为t时刻第n个网络节点执行转发动作的奖励,α1、α2、β1、β2和β3为不同的调节参数,为t时刻全局感知奖励,为t时刻局部感知奖励,thruputflow为各数据流的平均传输速率,latencyflow为各数据流的平均延迟,lossflow为各数据流的平均丢包率,dist[dpid][dst]为第n个网络节点到其所转发的数据流的目标网络节点的最短距离,dist[nextdpid][dst]为第n个网络节点执行转发动作后下一途径节点到其所转发的数据流的目标网络节点的最短距离,为t时刻第n个网络节点在状态空间st时执行动作的价值,α为学习率,γ为折扣因子,为t+1时刻第n个网络节点在状态空间st+1时执行最优动作的最大估计价值。
15、可选地,训练所述强化学习模型,具体包括:
16、针对每个网络节点,生成随机值,当随机值大于或等于预设的探索或利用策略的边界值时,确定预设的价值表中最大价值对应的转发动作,作为该网络节点所要执行的转发动作;所述价值表包括不同状态空间经各网络节点的动作空间中每个转发动作实现状态转换对应的价值;
17、当随机值小于预设的探索或利用策略的边界值时,根据价值表确定该网络节点执行其动作空间中各转发动作的概率,并通过随机算法基于各转发动作的概率选取一个转发动作作为该网络节点所要执行的转发动作;
18、确定该网络节点执行确定得到的转发动作后转换到下一时刻的状态空间的奖励;根据历史时刻的状态空间、该网络节点的动作空间以及该网络节点执行确定得到的转发动作后转换到下一时刻的状态空间的奖励,确定该网络节点执行确定得到的转发动作的价值;通过多轮迭代更新价值表。
19、可选地,所述根据当前时刻的状态空间和该网络节点的动作空间,通过预先训练后并部署在该网络节点的强化学习模型,确定该网络节点在当前时刻所要转发的数据流的下一途径网络节点,具体包括:
20、根据当前时刻的状态空间和该网络节点的动作空间,通过查询不同状态空间经各网络节点的动作空间中每个转发动作实现状态转换对应的价值表,确定当前时刻的状态空间下最大价值对应的转发动作;
21、根据转发动作,确定该网络节点在当前时刻所要转发的数据流的下一途径网络节点。
22、可选地,所述通过逐时刻多轮迭代确定各待转发的数据流从源网络节点到目标网络节点的路由路径,具体包括:
23、通过逐时刻多轮迭代确定各待转发的数据流的待选路由路径,判断每条待选路由路径是否为有效路径;其中,路由路径无环路、无黑洞时为有效路径;
24、若是,则将各待选路径作为对应各待转发的数据流的路由路径;
25、若否,则根据对应无效路径的待转发数据流的源网络节点和目标网络节点,确定从源网络节点到目标网络节点的最大可用带宽路径,并将其作为对应无效路径的待转发数据流的路由路径。
26、可选地,所述方法还包括:
27、针对每个网络节点,保存逐时刻每轮迭代过程中当前时刻的状态空间、该网络节点的转发动作、该网络节点的转发动作对应的奖励以及各网络节点执行对应转发动作后转换到下一时刻的状态空间形成对应该网络节点的训练数据;
28、通过云端服务器基于网络节点的数量和拓扑信息,实例化多个待训练强化学习模型,并根据各待训练强化学习模型与各网络节点的对应关系,通过对应网络节点的训练数据对各待训练强化学习模型分别进行训练,得到分别对应各网络节点不同状态空间经各网络节点的动作空间中每个转发动作实现状态转换对应的价值表,并将其分别部署在对应的网络节点中。
29、可选地,各网络节点间链路的剩余带宽、传输时延和丢包率。
30、本发明提供了一种多路径路由方法装置,包括:
31、获取模块,用于获取当前时刻各网络节点的拓扑信息、各网络节点的状态信息和各待转发的数据流的源网络节点与目标网络节点,形成当前时刻的状态空间;
32、确定模块,用于针对每个待进行数据流转发的网络节点,根据当前时刻该网络节点的度,确定该网络节点转发动作的动作空间;
33、路由模块,用于根据当前时刻的状态空间和该网络节点的动作空间,通过预先训练后并部署在该网络节点的强化学习模型,确定该网络节点在当前时刻所要转发的数据流的下一途径网络节点,以形成该网络节点的转发动作;
34、迭代模块,用于根据各网络节点的转发动作确定下一时刻各网络节点的状态信息,以得到下一时刻的状态空间,并重新确定下一时刻待进行数据流转发的网络节点,通过逐时刻多轮迭代确定各待转发的数据流从源网络节点到目标网络节点的路由路径。
35、本发明提供了一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述多路径路由方法。
36、本发明提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述多路径路由方法。
37、本发明采用的上述至少一个技术方案能够达到以下有益效果:
38、先获取当前时刻各网络节点的拓扑信息、各网络节点的状态信息和各待转发的数据流的信息,形成当前时刻的状态空间,再针对每个待进行数据流转发的网络节点,确定该网络节点在当前时刻所要转发的数据流,并根据当前时刻该网络节点的度确定该网络节点转发动作的动作空间,从而根据状态空间和动作空间确定该网络节点的转发动作,即所要转发的数据流的下一途径网络节点,最后通过逐时刻多轮迭代确定各待转发的数据流的路由路径。
39、本发明通过将待转发数据流的路由确定过程拆分为单个网络节点逐时刻的下一跳确定过程,从而将大规模的状态空间拆分为逐时刻的状态空间,整体的动作空间拆分为多个网络节点的动作空间,并通过每个网络节点上部署的强化学习模型逐时刻分别进行处理,降低了资源消耗提高了收敛效率。同时,拆分后逐时刻的路由确定过程中上一时刻各网络节点的转发动作会影响下一时刻的状态空间,因此,即使对于相同源-目标网络节点对,也会由于状态空间的变化而得到不同的路由路径,提高了灵活性和负载均衡能力,避免了局部路径过载。
- 还没有人留言评论。精彩留言会获得点赞!