音视频数据的处理方法及其装置、程序产品、电子设备与流程
本发明涉及人工智能领域,具体而言,涉及一种音视频数据的处理方法及其装置、程序产品、电子设备。
背景技术:
1、随着金融科技的飞速发展,金融机构网点作为金融服务的关键提供者,正面临着提升客户满意度的问题。随着客户期望的不断提升,当前的满意度监控方式逐渐显露出其不足之处。当前,大部分金融机构网点的柜面依赖人工点选的方式来收集客户满意度反馈,通常通过设置在柜台的纸质问卷或电子设备,让客户在办理业务后进行选择。这种方法虽然简单,但在执行过程中存在如下问题:
2、(1)主观性强,缺乏客观性:人工点选满意度的方式主要依赖于客户的主观感受,客户在点选时可能受到多种因素的影响,如个人情绪、对金融机构品牌的忠诚度等,导致满意度结果存在一定的主观性和不确定性。
3、(2)数据收集效率低,反馈周期长:人工点选满意度的方式通常需要客户在办理完业务后,通过纸质问卷或电子问卷进行反馈,这种方式不仅数据收集效率低,而且反馈周期较长,难以及时反映金融机构网点的柜面服务的真实情况。
4、(3)无法实时监测,缺乏时效性:人工点选满意度的方式无法实时监测客户在办理业务过程中的满意度变化,只能在业务办理完成后进行反馈,这导致金融机构网点无法及时发现和解决服务过程中存在的问题,影响了服务质量的持续改进。
5、(4)信息维度单一,难以全面评估:人工点选满意度的方式通常只关注客户对整体服务的满意度评价,缺乏对客户行为特征、情绪变化、交易结果等多个维度的深入分析,难以全面、准确地评估金融机构网点的柜面服务的质量。
6、对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种音视频数据的处理方法及其装置、程序产品、电子设备,以至少解决相关技术中对客户情绪状态进行确定的准确性较低的技术问题。
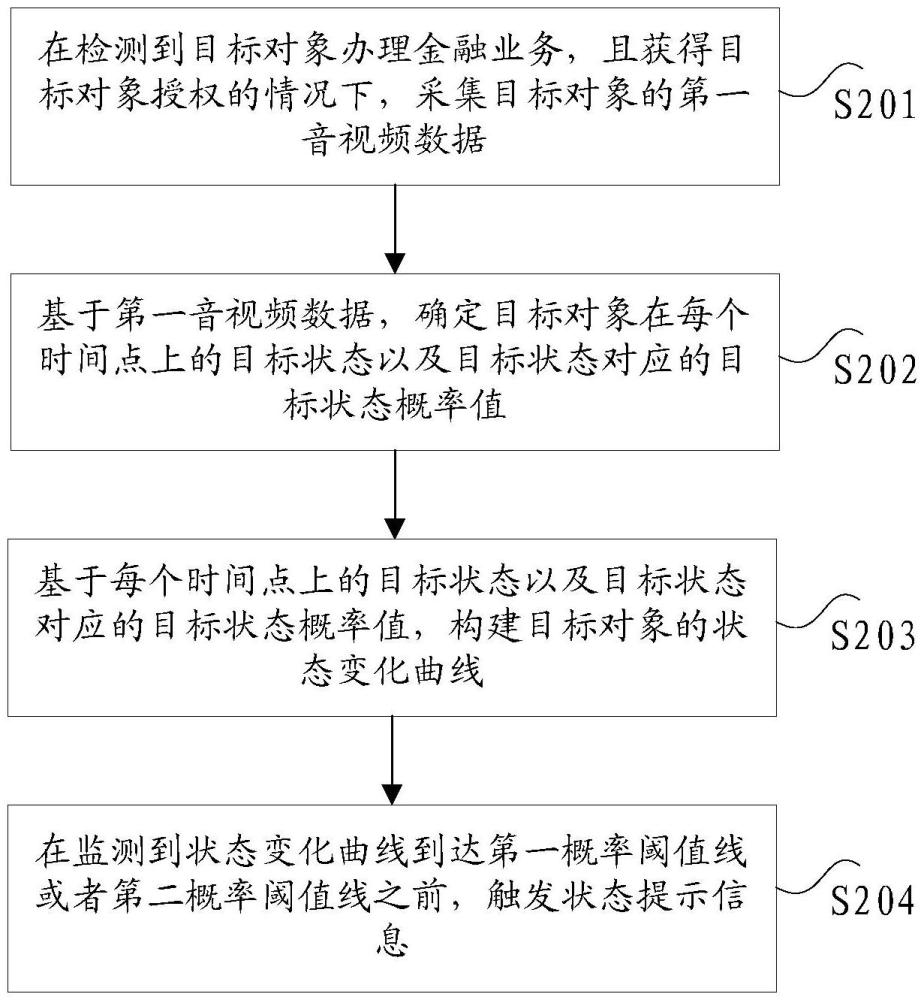
2、根据本发明实施例的一个方面,提供了一种音视频数据的处理方法,包括:在检测到目标对象办理金融业务,且获得所述目标对象授权的情况下,采集所述目标对象的第一音视频数据,其中,所述第一音视频数据携带有时间戳;基于所述第一音视频数据,确定所述目标对象在每个时间点上的目标状态以及所述目标状态对应的目标状态概率值;基于每个所述时间点上的所述目标状态以及所述目标状态对应的所述目标状态概率值,构建所述目标对象的状态变化曲线;在监测到所述状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,触发状态提示信息。
3、进一步地,基于所述第一音视频数据,确定所述目标对象在每个时间点上的目标状态以及所述目标状态对应的目标状态概率值的步骤,包括:对所述第一音视频数据进行分离,得到视频数据和音频数据;对所述视频数据进行处理,得到目标视频数据;基于所述目标视频数据,提取所述目标对象的面部特征数据以及动作特征数据;分别对所述面部特征数据、所述动作特征数据以及所述音频数据进行处理,得到第一状态结果、第二状态结果以及第三状态结果;基于所述第一状态结果、所述第二状态结果以及所述第三状态结果,确定所述目标对象在每个时间点上的所述目标状态以及所述目标状态对应的所述目标状态概率值。
4、进一步地,对所述视频数据进行处理,得到目标视频数据的步骤,包括:对所述视频数据中的每帧图像进行标注,得到每帧图像上的矩形框;基于每帧图像上的所述矩形框,对每帧图像进行裁剪,得到所述目标视频数据。
5、进一步地,分别对所述面部特征数据、所述动作特征数据以及所述音频数据进行处理,得到第一状态结果、第二状态结果以及第三状态结果的步骤,包括:采用第一模型处理所述面部特征数据,得到所述第一状态结果,其中,所述第一模型是采用第一历史数据训练得到的模型,所述第一历史数据包括:历史面部特征数据集合以及对所述历史面部特征数据集合中的每个历史面部特征数据进行标注的状态标注结果;采用第二模型处理所述动作特征数据,得到所述第二状态结果,其中,所述第二模型是采用第二历史数据训练得到的模型,所述第二历史数据包括:历史动作特征数据集合以及对所述历史动作特征数据集合中的每个历史动作部特征数据进行标注的状态标注结果;采用第三模型处理所述音频数据,得到所述第三状态结果,其中,所述第三模型是采用第三历史数据训练得到的模型,所述第二历史数据包括:历史音频数据集合以及对所述历史音频数据集合中的每个历史音频数据进行标注的状态标注结果。
6、进一步地,在采用第三模型处理所述音频数据,得到所述第三状态结果之前,还包括:对所述音频数据进行过滤,得到目标音频数据;对所述目标音频数据进行特征提取,得到频谱特征、音调特征和音量特征。
7、进一步地,所述第一状态结果、所述第二状态结果以及所述第三状态结果都至少包括:积极状态以及所述积极状态对应的积极概率值、消极状态以及所述消极状态对应的消极概率值,基于所述第一状态结果、所述第二状态结果以及所述第三状态结果,确定所述目标对象在每个时间点上的所述目标状态以及所述目标状态对应的所述目标状态概率值的步骤,包括:比较状态结果中的所述积极概率值与所述消极概率值,在所述积极概率值大于等于所述消极概率值的情况下,确定所述状态结果对应的状态为所述积极状态,或者,在所述积极概率值小于所述消极概率值的情况下,确定所述状态结果对应的状态为所述消极状态,其中,所述状态结果是所述第一状态结果、所述第二状态结果或者所述第三状态结果;基于所有所述状态结果分别对应的所述状态,确定所述目标对象在当前时间点上的所述目标状态;基于与所述目标状态一致的所有所述状态结果中的所述状态对应的概率值,确定所述目标状态对应的所述目标状态概率值。
8、进一步地,所述处理方法还包括:采集目标柜员的第二音视频数据,其中,所述目标柜员是为所述目标对象办理所述金融业务的柜员,所述第二音视频数据携带有时间戳;对所述第二音视频数据进行处理,得到所述目标柜员在每个时间点上的柜员状态以及所述柜员状态对应的柜员状态概率值;基于每个所述时间点上的所述柜员状态以及所述柜员状态对应的所述柜员状态概率值,构建所述目标柜员的柜员状态变化曲线;将所述柜员状态为消极状态的时间点以预设形式在所述柜员状态变化曲线上展示。
9、进一步地,在采集目标柜员的第二音视频数据之后,还包括:依据时间戳,对所述第一音视频数据中的音频数据以及所述第二音视频数据的音频数据进行整合,得到对话文本;基于所述柜员状态变化曲线,在所述对话文本中确定所述目标柜员带有所述消极状态的所有时间点对应的对话内容;将所述对话文本输入至预设语言模型,输出总结内容,其中,所述预设语言模型是采用历史对话文本集合以及为所述历史对话文本集合中每个历史对话文本标注的标注总结内容训练得到的模型。
10、进一步地,在监测到所述状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,触发状态提示信息的步骤,包括:在监测到所述状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,基于当前时间点之前的所述对话内容以及所述总结内容,触发所述状态提示信息。
11、根据本发明实施例的另一方面,还提供了一种音视频数据的处理装置,包括:采集单元,用于在检测到目标对象办理金融业务,且获得所述目标对象授权的情况下,采集所述目标对象的第一音视频数据,其中,所述第一音视频数据携带有时间戳;确定单元,用于基于所述第一音视频数据,确定所述目标对象在每个时间点上的目标状态以及所述目标状态对应的目标状态概率值;构建单元,用于基于每个所述时间点上的所述目标状态以及所述目标状态对应的所述目标状态概率值,构建所述目标对象的状态变化曲线;触发单元,用于在监测到所述状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,触发状态提示信息。
12、进一步地,所述确定单元包括:第一分离模块,用于对所述第一音视频数据进行分离,得到视频数据和音频数据;第一处理模块,用于对所述视频数据进行处理,得到目标视频数据;第一提取模块,用于基于所述目标视频数据,提取所述目标对象的面部特征数据以及动作特征数据;第二处理模块,用于分别对所述面部特征数据、所述动作特征数据以及所述音频数据进行处理,得到第一状态结果、第二状态结果以及第三状态结果;第一确定模块,用于基于所述第一状态结果、所述第二状态结果以及所述第三状态结果,确定所述目标对象在每个时间点上的所述目标状态以及所述目标状态对应的所述目标状态概率值。
13、进一步地,所述第一处理模块包括:第一标注子模块,用于对所述视频数据中的每帧图像进行标注,得到每帧图像上的矩形框;第一裁剪子模块,用于基于每帧图像上的所述矩形框,对每帧图像进行裁剪,得到所述目标视频数据。
14、进一步地,所述第二处理模块包括:第一处理子模块,用于采用第一模型处理所述面部特征数据,得到所述第一状态结果,其中,所述第一模型是采用第一历史数据训练得到的模型,所述第一历史数据包括:历史面部特征数据集合以及对所述历史面部特征数据集合中的每个历史面部特征数据进行标注的状态标注结果;第二处理子模块,用于采用第二模型处理所述动作特征数据,得到所述第二状态结果,其中,所述第二模型是采用第二历史数据训练得到的模型,所述第二历史数据包括:历史动作特征数据集合以及对所述历史动作特征数据集合中的每个历史动作部特征数据进行标注的状态标注结果;第三处理子模块,用于采用第三模型处理所述音频数据,得到所述第三状态结果,其中,所述第三模型是采用第三历史数据训练得到的模型,所述第二历史数据包括:历史音频数据集合以及对所述历史音频数据集合中的每个历史音频数据进行标注的状态标注结果。
15、进一步地,所述处理装置还包括:第一过滤模块,用于在采用第三模型处理所述音频数据,得到所述第三状态结果之前,对所述音频数据进行过滤,得到目标音频数据;第二提取模块,用于对所述目标音频数据进行特征提取,得到频谱特征、音调特征和音量特征。
16、进一步地,所述第一状态结果、所述第二状态结果以及所述第三状态结果都至少包括:积极状态以及所述积极状态对应的积极概率值、消极状态以及所述消极状态对应的消极概率值,所述第一确定模块包括:第一比较子模块,用于比较状态结果中的所述积极概率值与所述消极概率值,在所述积极概率值大于等于所述消极概率值的情况下,确定所述状态结果对应的状态为所述积极状态,或者,在所述积极概率值小于所述消极概率值的情况下,确定所述状态结果对应的状态为所述消极状态,其中,所述状态结果是所述第一状态结果、所述第二状态结果或者所述第三状态结果;第一确定子模块,用于基于所有所述状态结果分别对应的所述状态,确定所述目标对象在当前时间点上的所述目标状态;第二确定子模块,用于基于与所述目标状态一致的所有所述状态结果中的所述状态对应的概率值,确定所述目标状态对应的所述目标状态概率值。
17、进一步地,所述处理装置还包括:第一采集模块,用于采集目标柜员的第二音视频数据,其中,所述目标柜员是为所述目标对象办理所述金融业务的柜员,所述第二音视频数据携带有时间戳;第三处理模块,用于对所述第二音视频数据进行处理,得到所述目标柜员在每个时间点上的柜员状态以及所述柜员状态对应的柜员状态概率值;第一构建模块,用于基于每个所述时间点上的所述柜员状态以及所述柜员状态对应的所述柜员状态概率值,构建所述目标柜员的柜员状态变化曲线;第一展示模块,用于将所述柜员状态为消极状态的时间点以预设形式在所述柜员状态变化曲线上展示。
18、进一步地,所述处理装置还包括:第一整合模块,用于在采集目标柜员的第二音视频数据之后,依据时间戳,对所述第一音视频数据中的音频数据以及所述第二音视频数据的音频数据进行整合,得到对话文本;第二确定模块,用于基于所述柜员状态变化曲线,在所述对话文本中确定所述目标柜员带有所述消极状态的所有时间点对应的对话内容;第一输入模块,用于将所述对话文本输入至预设语言模型,输出总结内容,其中,所述预设语言模型是采用历史对话文本集合以及为所述历史对话文本集合中每个历史对话文本标注的标注总结内容训练得到的模型。
19、进一步地,所述触发单元包括:第一触发模块,用于在监测到所述状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,基于当前时间点之前的所述对话内容以及所述总结内容,触发所述状态提示信息。
20、根据本发明实施例的另一方面,还提供了一种计算机程序产品,包括非易失性计算机可读存储介质,所述非易失性计算机可读存储介质存储计算机程序,所述计算机程序被处理器执行时实现上述任意一项音视频数据的处理方法。
21、根据本发明实施例的另一方面,还提供了一种电子设备,包括一个或多个处理器和存储器,所述存储器用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述任意一项音视频数据的处理方法。
22、在本发明中,在检测到目标对象办理金融业务,且获得目标对象授权的情况下,采集目标对象的第一音视频数据,其中,第一音视频数据携带有时间戳;基于第一音视频数据,确定目标对象在每个时间点上的目标状态以及目标状态对应的目标状态概率值;基于每个时间点上的目标状态以及目标状态对应的目标状态概率值,构建目标对象的状态变化曲线;在监测到状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,触发状态提示信息,进而解决了相关技术中对客户情绪状态进行确定的准确性较低的技术问题。
23、在本发明中,通过对采集到的目标对象的音视频数据进行实时分析,能够得到目标对象在每个时间点上的目标状态以及目标状态对应的目标状态概率值,然后构建随时间变化的状态变化曲线,以在监测到状态变化曲线到达第一概率阈值线或者第二概率阈值线之前,及时触发状态提示信息,如此,不仅可以实时、准确地确定客户的情绪状态,还可以在客户情绪状态进一步恶化之前能够及时进行干预,有利于提升客户满意度,达到了实时监测客户情绪状态,提高客户满意度的技术效果。
- 还没有人留言评论。精彩留言会获得点赞!