一种基于多种声音特征的相似度计算方法与流程
本发明涉及一种基于多种声音特征的相似度计算方法,属于音频信号处理技术领域。
背景技术:
在语音识别、语音内容相似性判别系统中,特征提取过程就是抽取保持语音最重要特征,并消除与语音无关信号的干扰。特征参数的选择直接影响着相似性判别的准确率。本发明分别提取时域特征参数、频域特征参数、倒谱域特征参数,因不同特征参数表征的音频信息不同,对相似性判别的贡献不同,对此,为了能够有效准确的比较待测音频的相似性,使以特征参数判别相似性的方法具有更好的鲁棒性,提出了对不同特征参数计算的相似度值线性加权的方法。
技术实现要素:
本发明要解决的技术问题是提供一种基于多种声音特征的相似度计算方法,分别通过时域特征参数、频域特征参数、倒谱域特征参数进行音频信号相似度的计算,并对不同特征参数计算的结果进行线性加权。
本发明的技术方案是:一种基于多种声音特征的相似度计算方法,包括以下步骤:
(1)预处理:预处理过程分为三个步骤:预加重处理、分帧处理、加窗函数;
(2)提取特征参数:分别提取表征音频信号信息的时域特征,频域特征,倒谱域特征;
(3)相似度值计算:分别计算每种特征参数的相似度值;
(4)相似度值线性加权:把每一种特征参数计算的相似度值进行线性加权,通过试验方法,确定权重系数,从而确定待测音频的相似度。
上述的一种基于多种声音特征的相似度计算方法,步骤(1)中预处理,其中把待测音频信号进行分帧处理:音频序列是时间轴上的一维信号,为了能够对其进行信号分析,需要假设音频信号在毫秒级别的短时间处于稳定状态,因此在此基础上对音频信号进行分帧操作。对音频信号分帧处理可采用连续分段的方法,但为了使帧与帧之间平滑过渡保持其连续性,一般会采用交叠分段的方法。分帧是用可移动的有限长度窗口进行加权的方法来实现的,也就是用一定的窗函数w(n)来乘音频信号s(n),从而形成加窗的音频信号sw(n)=s(n)×w(n)。
设待测的音频信号分别为s(n)和s*(n),经过预处理后的信号为si(n)和
上述的一种基于多种声音特征的相似度计算方法,步骤(2)中提取特征参数,提取的特征参数有时域、频域、倒谱域特征参数。时域特征参数有短时平均过零率和短时自相关函数,频域特征参数有短时功率谱密度函数,倒谱域特征参数有梅尔频率倒谱系数(mfcc)和线性预测倒谱系数(lpcc)。
对每一帧信号si(n)和
(1)短时平均过零率:待测音频信号每一帧的短时平均过零率分别为xi和
(2)短时自相关函数:对待测音频分别取出帧序列si(n)和
(3)短时功率谱密度函数:反映信号的功率经常是用信号的功率谱密度函数。语音信号是一个非稳态的时变信号,但是在短时间范围内可以认为语音信号是稳态的,时不变的,因此对信号分帧后计算每一帧的短时功率谱密度函数。待测音频帧序列si(n)和
(4)梅尔频率倒谱系数(mfcc):mel频率倒谱系数(mfcc)的分析是在基于人的听觉机理,即依据人的听觉实验结果来分析语音的频谱,期望能获得好的语音特性。mfcc分析依据的听觉机理有两个,第一,人的主观感知频域的划定并不是线性的,而是fmel=2595*log(1+f/700),式中,fmel是以梅尔(mel)为单位的感知频率,f是以hz为单位的实际频率。第二,临界带宽,频率群相应于人耳基底膜分成许多很小的部分,每一部分对应一个频率群,对应于同一频率群的那些频率的声音,在大脑中是叠加在一起进行评价的。按临界带的划分,将语音在频域上划分成一系列的频率群组成了滤波器组,即mel滤波器组。待测音频帧序列si(n)和
式中,s(i,h)和s*(i,h)是mel滤波器能量,h是指第h个mel滤波器(共有h个),下标i表示第i帧,n是离散余弦变换后的谱线;
(5)线性预测倒谱系数(lpcc):在不考虑鼻音和摩擦音的情况下,语音的声道传递函数就是一个全极点模型:
上述的一种基于多种声音特征的相似度计算方法,步骤(3)中相似度值计算:(1)若提取的音频特征参数为短时平均过零率序列,互相关函数定义:
取互相关函数r1(n)的最大值r1(n)max为短时平均过零率序列计算的相似度值。
(2)若提取的音频特征参数为短时自相关函数序列,互相关函数定义:
取每一帧互相关函数ri(n)的最大值ri(n)max为相应帧短时自相关函数序列的相似度值。则两个待测音频信号的相似度值为:
(3)若提取的音频特征参数为短时功率谱密度函数序列,互相关函数定义:
取每一帧互相关函数ri(n)的最大值ri(n)max为相应短时功率谱密度函数序列的相似度值:
(4)若提取的音频特征参数为梅尔频率倒谱系数序列,互相关函数定义:
(5)若提取的音频特征参数为线性预测倒谱系数序列,互相关函数定义:
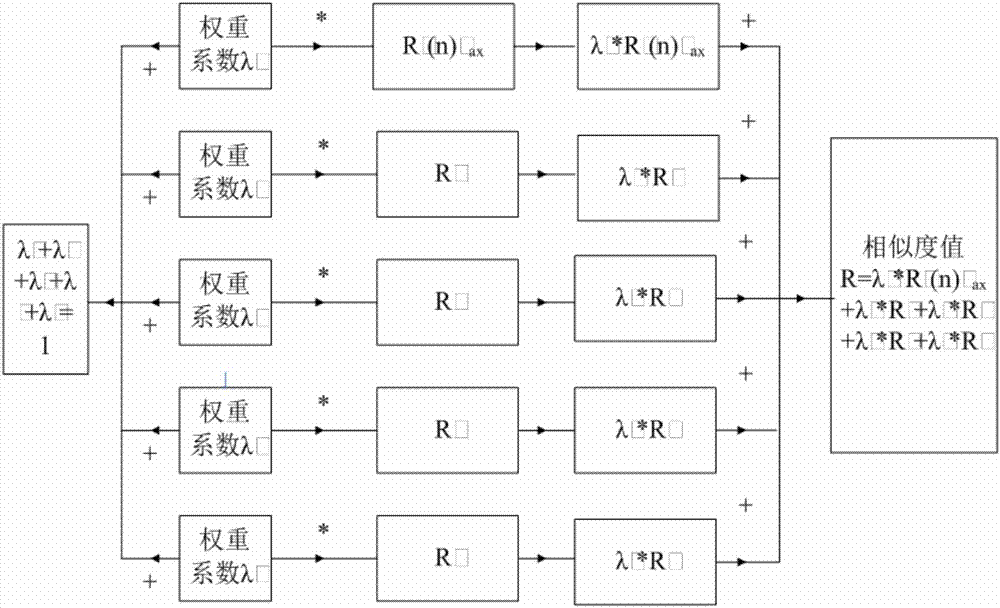
上述的一种基于多种声音特征的相似度计算方法,步骤(4)中相似度值线性加权:待测音频信号的特征参数计算的相似度值分别为:r1(n)max、r2、r3、r4、r5,不同的特征参数计算的相似度值也不同,不同的特征参数均表征音频信号的部分信息,但是每一种特征参数,无论是时域,频域,倒谱域,都不能完全详尽的表征音频信号的所有信息。时域分析方法具有简单、计算量小、物理意义明确等优点,但由于语音信号最重要的感知特性反映在功率谱中,而相位变化只起着很小的作用,所以相对于时域分析来说频域分析更为重要。每一种特征参数对相似性的判定所起的作用是不相同的,但是最终的相似性的判定、相似度值需要根据各个特征参数计算的相似度值来定,所以本发明提出了线性加权的相似度值计算方法。待测音频的相似度值为:r=λ1*r1(n)max+λ2*r2+λ3*r3+λ4*r4+λ5*r5,其中λ1、λ,2、λ,3、λ4和λ,5分别为权重系数,且λ1+λ2+λ3+λ4+λ5=1,权重系数值由多次例举试验来确定。
本发明的有益效果是:本发明可用于音频信号的相似度比对,可以应用在广播电视信号的监测方面。把不同特征参数计算的相似度值线性加权,不仅提高相似性判别的准确率,并且逻辑严谨,使相似性判别方法具有更好的鲁棒性。本发明算法简单,理论清晰,技术容易实现。
附图说明
图1是本发明相似度计算流程图;
图2是本发明相似度值线性加权流程图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-2所示,一种基于多种声音特征的相似度计算方法,具体步骤为:
(1)预处理:预处理过程分为三个步骤:预加重处理、分帧处理、加窗函数;
(2)提取特征参数:分别提取表征音频信号信息的时域特征参数、频域特征参数、倒谱域特征参数;
(3)相似度值计算:分别计算每种特征参数的相似度值;
(4)相似度值线性加权:把每一种特征参数计算的相似度值进行线性加权,通过试验方法,确定权重系数,从而计算待测音频的相似度。
所述预处理中的预加重处理、分帧处理、加窗函数具体为:
(1)预加重处理:声门脉冲的频率响应曲线接近于一个二阶低通滤波器,而口腔的辐射响应也接近于一个一阶高通滤波器,预加重的目的是为了补偿高频分量的损失,提升高频分量;
(2)分帧处理:由于语音信号是一个准稳态的信号,把它分成较短的帧,在每帧中可将其看成稳态信号,可用处理稳态信号的方法处理,同时,为了使一帧与另一帧之间的参数能较平稳地过渡,在两帧之间互相有部分重叠;
(3)加窗函数:加窗函数的目的是减少频域中的泄漏,将对每一帧语音乘以汉明窗或海宁窗。
所述时域特征参数、频域特征参数、倒谱域特征参数具体为:
(1)提取时域特征参数:时域特征参数包括短时平均过零率和短时自相关函数;
(2)提取频域特征参数:频域特征参数是短时功率谱密度函数;
(3)提取倒谱域特征参数:倒谱域特征参数包括梅尔频率倒谱系数和线性预测倒谱系数;
把音频信号进行预处理后,分别提取音频信号每一帧的特征参数,提取的每一帧信号分别组成数据集合。
所述相似度值计算包括以下步骤:
(1)若提取的音频特征参数为短时平均过零率序列,提取音频信号每一帧的短时平均过零率,所有帧的短时平均过零率组成一个序列,音频比对是通过互相关函数计算短时平均过零率序列的相似度值;
(2)若提取的音频特征参数为短时自相关函数序列,音频比对是通过互相关函数计算短时自相关函数序列每一帧的相似程度,然后对所有帧计算的相似度值求平均;
(3)若提取的音频特征参数为短时功率谱密度函数序列,音频比对是通过互相关函数计算短时功率谱密度函数序列每一帧的相似程度,然后对所有帧计算的相似度值求平均;
(4)若提取的音频特征参数为梅尔频率倒谱系数序列,音频比对是通过互相关函数计算梅尔频率倒谱系数序列每一帧的相似程度,然后对所有帧计算的相似度值求平均;
(5)若提取的音频特征参数为线性预测倒谱系数序列,音频比对是通过互相关函数计算线性预测倒谱系数序列每一帧的相似程度,然后对所有帧计算的相似度值求平均。
所述相似度值线性加权,时域特征、频域特征、倒谱域特征所表征的声音信号的信息不完全相同,每一种特征只能部分的表征信号信息,并且不同的特征对识别相似性的影响也不同,有的特征对识别相似性的贡献大,有的特征对识别相似性的贡献小,因此最后判定待测的音频信号是否相似,就需要把不同特征计算的相似度值进行线性加权。
所述相似度值线性加权权重系数的设定为:
制定试验方案,通过对不同的权重系数分配进行试验,前提是待测音频信号是已知的实信号,已知相似或不相似,相似的设定特征参数的互相关函数最大值为1,不相似的设定为0,不同权重系数下的相似度值与已知的相似度值进行均方误差比较,在所有设定的不同权重系数组合下,均方误差最小的那一组权重系数即为最优的线性加权系数。
实施例2:如图1-2所示,一种基于多种声音特征的相似度计算方法,包括以下步骤:
(1)预处理:预处理过程分为三个步骤:预加重处理、分帧处理、加窗函数;
(2)预加重处理:预加重处理的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。预加重一般是在语音信号数字化之后,在参数分析之前在计算机里用具有6db/倍频程的提升高频特性的预加重数字滤波器来实现。一般是一阶的数字滤波器,即,其中,值接近于1,典型值为0.94;
(3)分帧处理:音频序列是时间轴上的一维信号,是一个非稳态时变的信号,但语音是由声门的激励脉冲通过声道形成的,而声道,即人的口腔(或耦合了鼻腔)肌肉运动是缓慢的,“短时间”范围内可以认为语音信号是稳态的,时不变的。所以为了能够对其进行信号分析,需要假设音频信号在毫秒级别的短时间处于稳定状态,因此在此基础上对音频信号进行分帧操作。对音频信号分帧处理可采用连续分段的方法,但为了使帧与帧之间平滑过渡保持其连续性,一般会采用交叠分段的方法。分帧是用可移动的有限长度窗口进行加权的方法来实现的,也就是用一定的窗函数w(n)来乘音频信号s(n),从而形成加窗的音频信号sw(n)=s(n)×w(n)。
(4)加窗函数:加窗函数的目的是减少频域中的泄漏,将对每一帧语音乘以汉明窗或海宁窗。
(5)提取特征参数:分别提取表征音频信号信息的时域特征,频域特征,倒谱域特征。设待测的音频信号分别为s(n)和s*(n),经过预处理后的信号为si(n)和
(6)时域特征参数提取:提取的时域特征参数包括短时平均过零率和短时自相关函数。
1:短时平均过零率:待测音频信号每一帧的短时平均过零率分别为xi和
2:短时自相关函数:对待测音频分别取出帧序列si(n)和
(7)频域特征参数提取:提取的频域特征参数是短时功率谱密度函数。反映信号的功率经常是用信号的功率谱密度函数。语音信号是一个非稳态的时变信号,但是在短时间范围内可以认为语音信号是稳态的,时不变的,因此对信号分帧后计算每一帧的短时功率谱密度函数。待测音频帧序列si(n)和
(8)倒谱域特征参数提取:提取的倒谱域特征参数包括梅尔频率倒谱系数和线性预测倒谱系数。
1:梅尔频率倒谱系数(mfcc):mel频率倒谱系数(mfcc)的分析是在基于人的听觉机理,即依据人的听觉实验结果来分析语音的频谱,期望能获得好的语音特性。mfcc分析依据的听觉机理有两个,第一,人的主观感知频域的划定并不是线性的,而是fmel=2595*log(1+f/700),式中,fmel是以梅尔(mel)为单位的感知频率,f是以hz为单位的实际频率。第二,临界带宽,频率群相应于人耳基底膜分成许多很小的部分,每一部分对应一个频率群,对应于同一频率群的那些频率的声音,在大脑中是叠加在一起进行评价的。按临界带的划分,将语音在频域上划分成一系列的频率群组成了滤波器组,即mel滤波器组。待测音频帧序列si(n)和
式中,s(i,h)和s*(i,h)是mel滤波器能量,h是指第h个mel滤波器(共有h个),下标i表示第i帧,n是离散余弦变换后的谱线;
2:线性预测倒谱系数(lpcc):在不考虑鼻音和摩擦音的情况下,语音的声道传递函数就是一个全极点模型:
(9)相似度值计算:分别计算每种特征参数的相似度值;
1:若提取的音频特征参数为短时平均过零率序列,互相关函数定义:
取互相关函数r1(n)的最大值r1(n)max为短时平均过零率序列计算的相似度值。
2:若提取的音频特征参数为短时自相关函数序列,互相关函数定义:
取每一帧互相关函数ri(n)的最大值ri(n)max为相应帧短时自相关函数序列的相似度值。则两个待测音频信号的相似度值为:
3:若提取的音频特征参数为短时功率谱密度函数序列,互相关函数定义:
取每一帧互相关函数ri(n)的最大值ri(n)max为相应短时功率谱密度函数序列的相似度值:
4:若提取的音频特征参数为梅尔频率倒谱系数序列,互相关函数定义:
l为整数,取每一帧互相关函数ri(l)的最大值ri(l)max为相应梅尔频率倒谱系数序列的相似度值:
5:若提取的音频特征参数为线性预测倒谱系数序列,互相关函数定义:
(10)相似度值线性加权:把每一种特征参数计算的相似度值进行线性加权,通过试验方法,确定权重系数,从而确定待测音频的相似度。待测音频信号的特征参数计算的相似度值分别为:r1(n)max、r2、r3、r4、r5,不同的特征参数计算的相似度值也不同,不同的特征参数均表征音频信号的部分信息,但是每一种特征参数,无论是时域,频域,倒谱域,都不能完全详尽的表征音频信号的所有信息。时域分析方法具有简单、计算量小、物理意义明确等优点,但由于语音信号最重要的感知特性反映在功率谱中,而相位变化只起着很小的作用,所以相对于时域分析来说频域分析更为重要。每一种特征参数对相似性的判定所起的作用是不相同的,但是最终的相似性的判定、相似度值需要根据各个特征参数计算的相似度值来定,所以本发明提出了线性加权的相似度值计算方法。待测音频的相似度值为:r=λ1*r1(n)max+λ2*r2+λ3*r3+λ4*r4+λ5*r5,其中λ1、λ,2、λ,3、λ4和λ,5分别为权重系数,且λ1+λ2+λ3+λ4+λ5=1,权重系数值由多次例举试验来确定。
实施例3:在上述实施例的基础上,本发明的权重系数确定步骤为:
(1)待测音频信号为已知的实信号,前提知道两个待测的音频信号是否相似,本发明是通过实验的方法来计算相似度。设定已知的两个相似的音频信号相似度值为1,不相似的音频信号相似度值为0。
(2)λ1+λ2+λ3+λ4+λ5=1,不同的λ组合,就可以得到不同的待测音频相似度值。λ组合之间的变化步长越小,试验的组合就越多,得到的试验结果就越精确。
(3)不同组合的λ值就得到不同的相似度值,计算不同组合得到的相似度值和1之间的均方误差,选取其中均方误最小的一组λ值,则这一组合就是最优的特征参数的权重系数。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
-
 0访客 来自[日本] 2019年08月16日 05:07Sound-Similar Free就干这个
0访客 来自[日本] 2019年08月16日 05:07Sound-Similar Free就干这个