用于检测地中海贫血基因突变的高通量文库构建试剂盒及文库构建方法与流程
本发明涉及基因测序
技术领域:
,具体涉及一种用于检测地中海贫血基因突变的高通量文库构建试剂盒及文库构建方法。
背景技术:
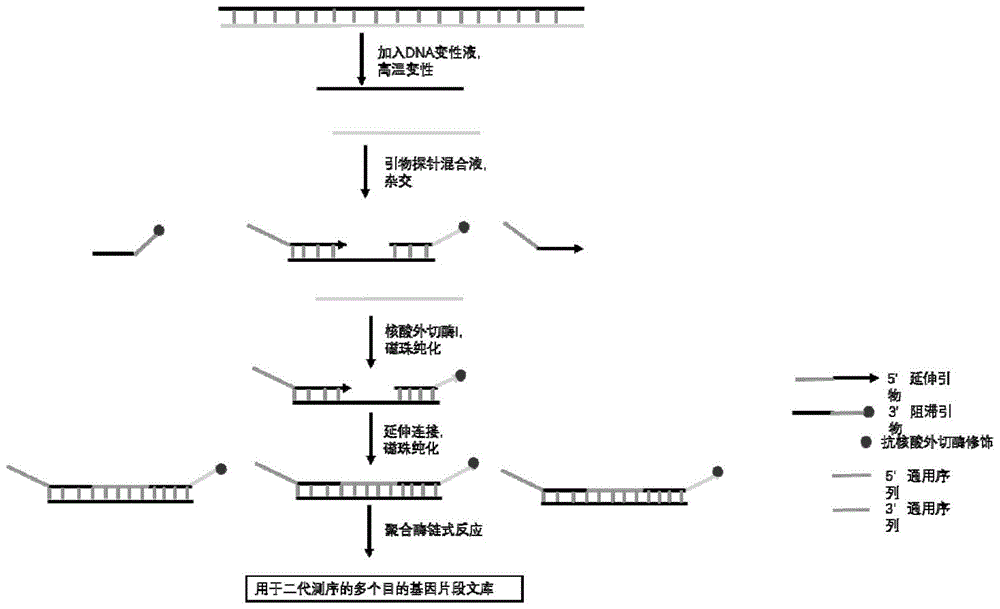
:地中海贫血(thalassemia)(简称地贫)是由于珠蛋白基因发生缺陷,导致珠蛋白链的合成减少或缺如,使形成血红蛋白的α-链/非α-链比例失衡,而导致的一组单基因遗传性、溶血性疾病。轻者可无临床表现,重者以进行性贫血为主要特征。根据珠蛋白肽链合成受到抑制的类型,地贫可以分为α-地贫、β-地贫、δ-地贫、γ-地贫、δβ-地贫和εγδβ-地贫。临床上,地中海贫血又分为轻型(地中海贫血基因携带者)、中间型和重型3个类型。α-地中海贫血是由于α-珠蛋白基因(hba2和hba1)缺失或非缺失突变,导致α珠蛋白链功能异常,或合成减少而引起的一种遗传性溶血性疾病。引发α-地中海贫血的突变主要是类α-珠蛋白基因簇的大片段缺失,此外,还有少量α-地中海贫血是由于α2或α1基因的点突变导致。β-地中海贫血的分子基础是珠蛋白基因(hbb)的点突变或核苷酸序列缺失,造成β珠蛋白合成的减少或缺如。β-珠蛋白基因突变主要分为两大类:一类是非缺失型突变,包括转录突变、rn加工突变、翻译突变、显性遗传性β地中海贫血和高度不稳定性血红蛋白、转录起始点突变、起始密码子突变、非翻译区突变、polya加合信号的突变。另一类是缺失型突变。另外,类β-珠蛋白基因簇的大片段缺失会导致β-地中海贫血或遗传性持续性胎儿血红蛋白增高症(hereditarypersistenceoffetalhemoglobin,hpfh)。目前世界上已发现至少300种α-珠蛋白基因变异和200余种β-珠蛋白基因变异,而在中国人群中目前报道的至少有57种(包括19种缺失型和38种非缺失型)α-地中海贫血和95种β-地中海贫血突变类型。而携带有其中6种α-地中海贫血突变(--sea/、-α3.7/、-α4.2/、αwsα/、αcsα/、αqsα/)和8种β-地中海贫血突变[cd41-42(-cttt)、ivs-ii-654(c>t)、cd71-72(+a)、cd17(aag>tag)、-28(a>g)、cd26(gag>aag)、-29(a>g)和cd43(gag>tag)]的人群数量分别占了α-地中海贫血突变和β-地中海贫血突变人群总数的98%和95%以上。个别重要的遗传修饰基因(klf1、bcl11a、hmip等)突变也能导致β-地贫样表型。地贫集中在热带和亚热带地区,多发生于地中海沿岸国家,其次为中东、印度、巴基斯坦、东南亚、中国南方和北非,美国是移民国家,其发生率也较高。我国长江以南各省是地贫高发区,广东、广西、海南、台湾和香港等地受累人口超过2亿。目前地贫尚无根治的方法,只能依靠传统方法治疗,即以输血治疗为主,价格昂贵,因此产前筛查和诊断对预防该种出生缺陷疾病具有重大意义。目前,诊断地贫基因变异的技术有跨越断裂位点pcr(gap-pcr)、实时荧光pcr、多重连接探针扩增法(multiplexligation-dependentprobeamplification,mlpa)和反向点杂交(reversedotblot,rdb)技术。多种高灵敏度的技术方法也被尝试用于地贫检测,如质谱、数字pcr、cold-pcr等。但这些基于单一位点的pcr技术的检测方法存在一定的局限性。dna测序是最直接最准确的判断突变的位置和性质的方法,尽管费用相对较高,仍然是检测未知的地贫突变基因的关键方法。基于高通量测序技术的dna全基因组测序或者目标区域捕获测序可以更加准确的实现对地贫基因的检测,但全基因组测序的成本以及分析方法的复杂性限制了在临床上的应用,而针对目标基因区域进行富集后的二代测序是比较经济适用的方法,适合临床应用推广。目前市场常用的目标区域富集方法主要是基于pcr扩增、环化和杂交捕获的目标区域富集。pcr扩增包含常规的标准多重pcr以及商业化高通量多重pcr(如,ionampliseqtmfromlifetechnologies,genereaddnaseqsystemfromqiagen,targetrichtmfromkailos),微液滴pcr(如,raindance),或者基于芯片的pcr(如,accessarraytmfromfluidigm)。“环化”也叫分子倒置探针(molecularinversionprobes,mips),间隙填充挂锁探针(gap-fillpadlockprobes)或选择器探针(selectorprobes)。在100-500kb的范围区间,通过一种高特异性的方式(间隙填充和连接反应)形成包含目标区域序列的单链dna环,进而产生包含共同dna原件的结构,用于对感兴趣的靶区域进行选择性扩增,比较代表性的方法有haloplex(agilent)和mips。杂交捕获指样品中的核酸和锚定在固相支持物或者直接存于液体中的与目标区域互补的dna/rna探针杂交,然后通过物理捕获的方式分离出感兴趣的序列。捕获范围从500kb到整个全外显子组,发展出了一些经典的商业化杂交方法,比如sureselect(agilent),nextera(illumina),truseq(illumina),seqcap(nimble-gen),iontargetseq(lifetechnologies),这些方法对大范围和预设计的区域有更好的捕获效率和成本效率。国内天昊基因科技有限公司于2012年发明了一种基于杂交延伸连接的多重目标基因片段富集技术(参考“一种高通量核酸分析方法及其应用”,专利号:zl201210581830.9),该技术针对目标区域片段设计1个上游延伸引物以及1个下游阻滞探针,变性复性后与同一条dna链结合,在同一个反应体系中,在热稳定dna聚合酶以及热稳定dna连接酶作用下产生1条延伸连接产物;通常延伸引物5端以及阻滞探针3端加上与高通量测序平台兼容的通用序列,这样延伸连接产物可以在纯化之后利用通用pcr引物进行扩增完成高通量测序文库的构建;该技术方法具备操作简单、体系易于优化,而且通过该方法富集之后的文库测序数据可以用于目标基因片段拷贝数的精确检测。该公司于2020年在此技术基础上进行了进一步优化,将杂交与延伸连接分开,样本经变性杂交后利用exoi外切酶对未杂交的延伸引物进行切除,然后再进行硅胶膜柱或磁珠纯化,纯化产物再进行同一体系延伸连接扩增富集(参考“一种靶基因区域快速富集方法”,专利号:202010647922.7)。该方案通过技术优化,显著降低非特异扩增背景,进一步降低体系优化难度,显著提高文库测序质量。本发明提供一种基于上述专利技术(专利号:202010647922.7)的“杂交纯化-延伸连接”富集技术方案(参见图1),应用于illumina二代测序平台的地中海贫血基因突变检测文库构建方法及试剂盒。技术实现要素:为了解决上述现有技术中存在的技术问题,本发明提供地中海贫血基因突变检测文库构建方法及试剂盒,其核心点在于基于多重循环延伸连接的靶基因区域富集构建文库;关键点在于针对地中海贫血基因目的区域设计引物探针组,通过杂交、酶切纯化、延伸连接反应富集包含常见地中海贫血基因点突变基因片段以及常见缺失突变断点序列,富集产物适用于illumina二代测序平台,测序数据可用于分析地中海贫血目的基因片段点突变和拷贝数,以及常见缺失突变。本发明提供一种用于检测地中海贫血基因突变的高通量文库构建试剂盒,所述试剂盒包括对应于待测样本中核苷酸序列的多对引物探针组、核酸外切酶、核酸连接酶和核酸聚合酶;还包括其他的建库试剂。优选地,每一对引物探针组分别包含5’延伸引物和3’阻滞探针;其中,所述5’延伸引物不能被5'端方向核酸外切酶降解,所述5’延伸引物包括与目标核酸片段3'端特异性杂交的第一部分和与后续pcr扩增引物序列相对应的第二部分;所述3’阻滞探针不能被3'端方向核酸外切酶降解,所述3’阻滞探针包括与目标核酸片段5’端特异性杂交的第一部分和与后续pcr扩增引物序列特异性杂交的第二部分;所述多对引物探针组的序列信息如seqidno:1-98所示。优选地,所述核酸外切酶的修饰为硫代修饰,即所述3’阻滞探针的5'端磷酸化修饰,3'端硫代修饰;所述核酸聚合酶为高温耐热核酸聚合酶:hemoklentaq(neb)、hotstartflexdnapolymerase(neb),所述核酸聚合酶为没有5'到3'核酸外切酶活性的聚合酶;所述核酸连接酶为高温耐热核酸连接酶:taqdnaligase(neb);所述核酸外切酶为exonucleasei。优选地,所述其他的建库试剂包括:(1)dna变性液:含有变性剂的缓冲液;(2)引物探针混合液:用于多对引物探针组溶解在杂交缓冲液;(3)核酸外切酶缓冲液;(4)延伸连接缓冲液:为核酸聚合酶和核酸连接酶的pcr反应及连接反应提供反应组分及缓冲环境;(5)延伸连接酶混合液:用于核酸聚合酶及核酸连接酶配比混合;(6)pcr缓冲液:为核酸聚合酶提供反应组分及缓冲环境;(7)taqdna聚合酶;(8)磁珠悬浮液;(9)磁珠洗脱液a及磁珠洗脱液b。优选地,所述dna变性液组分为:0.6875×te,ph8.0,1.25×gcsolution;所述引物探针混合液组分为:0.003μm/延伸引物,0.006μm/阻滞探针,30mmtris-cl,150mmnacl,0.3mmedta,ph8.0,5ng/μl鱼精;所述核酸外切酶缓冲液组分为:4.5×exoibuffer,20mmmgcl2;所述延伸连接缓冲液组分为:0.76×gcsolution,3.05×hemoklentaqbuffer,nad3.05mm,mgcl27.63mm,dntp0.61mm;所述延伸连接酶混合液组分为:0.4μlhemoklentaq+0.1μltaqdnaligase;所述pcr缓冲液组分为:1.65×gcbuffer1,0.49dntp,0.82mmmgcl2;所述磁珠纯化洗脱液a组分为:30mmkcl10mmtris-cl,ph8.0;所述磁珠纯化洗脱液b组分为:10mmtris-cl,ph8.0。本发明还提供一种用于检测地中海贫血基因突变的文库构建方法,其特征在于,包括以下步骤:步骤一、利用权利要求1-7中任一项所述的试剂盒,提供一反应体系;步骤二、杂交;所述5’延伸引物和所述3’阻滞探针在高温变性、退火过程中与待测样本的目标核酸片段特异性杂交,获得杂交产物,所述5’延伸引物的3'末端与所述3’阻滞探针的5'末端至少间隔1个核苷酸的距离;步骤三、酶切纯化;对步骤二的所述杂交产物,用核酸外切酶进行消化处理,再用磁珠进行纯化,从而获得经纯化的反应混合物,所述反应混合物中含有未被消化的所述杂交产物;步骤四、延伸连接纯化;在核酸聚合酶作用下,所述5’延伸引物沿目标核酸片段进行dna链延伸,延伸至所述3’阻滞探针的5'末端时被其阻滞,获得5’延伸引物延伸dna链;以及在核酸连接酶的作用下,将所述5’延伸引物延伸dna链3'端与所述3’阻滞探针5'端连接,从而形成含连接产物的反应混合物;和任选地重复上述“变性-退火-延伸-连接”,从而增加所述反应混合物中所述连接产物的数量;对所述反应液混合物中的所述连接产物用磁珠进行纯化;步骤五、富集以步骤四的所述纯化后的连接产物为模板,进行pcr扩增,从而获得pcr扩增产物,即为富集的核酸片段;将所述pcr扩增产物再用磁珠进行纯化,即可得到核酸片段测序文库。优选地,所述5'延伸引物不能被5'端方向核酸外切酶降解,能够被3'端方向核酸外切酶降解,所述5'延伸引物的5'端带有防止核酸外切酶降解的保护基团;所述3’阻滞探针不能被3'端方向核酸外切酶降解,能够被5'端方向核酸外切酶降解,所述3’阻滞探针的3'端带有防止核酸外切酶降解的保护基团。优选地,所述3’阻滞探针的tm值高出所述5’延伸引物的tm值4℃-6℃;每一对引物探针组中的各5’延伸引物的tm值为59℃-68℃;每一对引物探针组中的各3’阻滞探针的tm值为68℃-75℃。优选地,每一对引物探针组的5’延伸引物的第二部分是相同或基本相同的;每一对引物探针组的3’阻滞探针的第二部分是相同或基本相同的。优选地,在所述步骤四中,扩增循环数为4-20次。优选地,在步骤三、四中使用1.5×磁珠纯化回收连接产物是:使用beckman商用xp磁珠用于产物的纯化,最终使用1×te(ph8.0)洗脱溶解dna,其他根据商用产品说明进行纯化回收,以及根据文库需求进行片段筛选。优选地,所述步骤五中,所述pcr扩增过程中,采用的pcr引物包括正向引物和反向引物;所述正向引物包含能够与所述5’延伸引物的第二部分序列的反向互补序列特异性杂交的序列,所述反向引物包含与所述3’阻滞探针的第二部分特异性杂交的序列;所述正向引物和所述反向引物中含有与illumina高通量芯片测序平台兼容的通用序列;所述正向引物和所述反向引物中含有标签序列,针对不同的样本采用不同的标签序列。优选地,所述5’延伸引物的第二部分序列为:5’acactctttccctacacgacgctcttccgatct3’;所述3’阻滞探针的第二部分序列为:5’agatcggaagagcacacgtctgaactccagtctt3’;所述正向引物序列为:5’aatgatacggcgaccaccgagatctacactctttccctacac3’;所述反向引物序列为:5’caagcagaagacggcatacgagat[x]atggcaaaaatggtgctcaagg3’,其中[x]为标签序列。相较于现有技术,本发明提供的用于检测地中海贫血基因突变的高通量文库构建试剂盒及文库构建方法具有以下有益效果:一、本发明提供的用于检测地中海贫血基因突变的高通量文库构建试剂盒,操作步骤简单,地中海贫血基因目标区域富集后通过一次的pcr扩增,然后采用磁珠纯化产物,即得到地中海贫血基因测序文库,减少了纯化次数,可以有效减少建库过程中地中海贫血基因dna样本的损失;同时降低了建库的成本,减少了pcr扩增中引入突变的可能性,使得测序结果更加精确。二、本发明提供的用于检测地中海贫血基因突变的文库构建方法,关键在于针对地中海贫血基因目的区域设计引物及探针,通过延伸连接反应富集目的片段,对地中海贫血基因目的基因组区域进行捕获富集;一个延伸连接反应体系可以获得<200kb的区域内所有目的片段的连接产物;该方法快速、步骤简单,直接富集扩增效率极高,无需复杂的建库过程在文库构建中,能够高效、准确的计算dna含量;从而在高通量测序之后,能够依据测序对地贫相关的突变进行分型。三、常规探针杂交捕获富集技术需要样本基因组dna超声打碎、全基因组文库构建及杂交捕获富集等操作,操作复杂,实验流程长,而该试剂盒操作相对于全基因组文库构建,操作较简单,实验流程缩短;常规杂交捕获富集技术富集由于涉及更多步骤,使用更多试剂,成本高,而该试剂盒可显著降低成本。四、常规探针杂交捕获富集技术富集效果为40-60%,而该试剂盒富集效率可高达80%以上。五、常规杂交捕获富集技术富集的文库测序数据对单个目标基因片段的拷贝数检测波动大,准确性不高,而该试剂盒富集文库的测序数据对目标片段的拷贝数检测波动小,准确性高。附图说明图1为本发明采用的靶基因区段富集技术原理图。图2为本发明实施例中地中海贫血样本case01的基因片段拷贝数检测值。图3为本发明实施例中地中海贫血样本case02的基因片段拷贝数检测值。图4为本发明实施例中地中海贫血样本case03的基因片段拷贝数检测值。图5为本发明实施例中地中海贫血样本case04的基因片段拷贝数检测值。图6为本发明实施例中地中海贫血样本case05的基因片段拷贝数检测值。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。实施例1、试剂盒1)待测样本信息:利用本发明提供的试剂盒及方法对3个α-地中海贫血样本,2个β-地中海贫血以及1个正常个体样本进行目标基因片段富集二代测序,并对测序结果进行生物信息分析。表1五个地中海贫血样本的基因突变信息样本编号性别患病情况基因突变类型case01女α-地中海贫血––sea/αwscase02女α-地中海贫血––sea/-α4.2case03男α-地中海贫血-α3.7/αcscase04女β-地中海贫血cd41–42(–cttt)/–28(a>g)case05男β-地中海贫血chinese(aγδβ)0-/ivs–ii–654(c>t)control男正常无突变2)试剂盒组分:(1)dna变性液:含有变性剂的缓冲液;优选条件:0.6875×te,ph8.0;1.25×gcsolution。(2)引物探针混合液:溶解在杂交缓冲液中,延伸引物5端以及阻滞探针3端都含有与illumina二代测序平台扩增及测序引物对应的通用序列,3端阻滞探针进行了5端磷酸化修饰以及3端至少2个碱基的硫代修饰;探针浓度条件:0.0001-0.05μm/each延伸引物,0.0001-0.05μm/each阻滞探针;优选条件:0.003μm/延伸引物,0.006μm/阻滞探针,30mmtris-cl,150mmnacl,0.3mmedta,ph8.0,5ng/μl鱼精(鲱鱼精dna)。(3)缓冲液核酸外切酶i及缓冲液:核酸外切酶i优选浓度:20u/μl;核酸外切酶i缓冲液优选浓度:4.5×exoibuffer,20mmmgcl2。(4)延伸连接缓冲液:为耐热dna聚合酶以及dna连接酶的pcr反应及连接反应提供反应组分以及缓冲环境;优选条件:0.76×gcsolution,3.05×hemoklentaqbuffer,nad3.05mm,mgcl27.63mm,dntp0.61mm。(5)延伸连接酶混合液:含耐热dna聚合酶以及dna连接酶;优选条件:0.4μlhemoklentaq+0.1μltaqdnaligase(500u/μl)。(6)pcr缓冲液:为耐热dna聚合酶提供反应组分以及缓冲环境;优选条件:1.65×gcbuffer1,0.49dntp,0.82mmmgcl2。(7)taqdna聚合酶:优选条件:5u/μl。(8)磁珠悬浮液。(9)磁珠纯化洗脱液a:优选条件:30mmkcl10mmtris-cl,ph8.0;磁珠纯化洗脱液b:优选条件:10mmtris-cl,ph8.0。3)试剂盒使用流程:a)将样本基因组dna与dna变性液混合,高温变性;b)高温变性后样本基因组dna与引物探针混合液混合,完成引物探针与目标基因组dna的杂交;c)将样本基因dna与引物探针杂交之后,利用核酸外切酶切除没有杂交上的多余延伸引物;d)上述酶切产物利用磁珠纯化;e)磁珠纯化产物与延伸连接酶缓冲液以及延伸连接酶混合液混合,杂交上的引物进行延伸并与下游杂交上的阻滞探针进行连接;f)延伸连接产物利用磁珠纯化后,利用含特定标签序列的二代测序pcr通用引物以及试剂盒提供的taqdna聚合酶进行pcr扩增;g)pcr扩增产物单独或混合之后进行磁珠纯化后即获该样本“地中海贫血基因突变检测文库”;h)该二代测序文库经精确定量后与其它样本文库混合上illumina二代测序平台;i)测序数据经生物信息分析获得每个扩增片段內的单碱基变异以及每个扩增片段的拷贝数值。实施例2、实验过程本发明提供的用于检测地中海贫血基因突变的文库构建方法,包括以下步骤:s1、提供一反应体系所述反应体系包括:待测样本、上述试剂盒成分;其中:所述待测样本为人的核酸样本,所述待测样本数量为多个。本案中选取6个地中海贫血患者血液dna样本。所述样本中地中海贫血基因目标核酸片段的总量为300ng。本案中选取针对28个地中海贫血基因变异位点的54对引物探针组。所述5’延伸引物不能被5'端方向核酸外切酶降解,能够被3'端方向核酸外切酶降解;所述5’延伸引物的5'端带有防止核酸外切酶降解的保护基团。所述3’阻滞探针不能被3'端方向核酸外切酶降解,能够被5'端方向核酸外切酶降解;所述3’阻滞探针的3'端带有防止核酸外切酶降解的保护基团。通过在所述5’延伸引物的5'端和/或所述3’阻滞探针的3'端进行抗核酸外切酶的修饰,以实现所述5’延伸引物不能被5'端核酸外切酶降解和/或所述3’阻滞探针不能被3'端核酸外切酶降解。所述核酸外切酶的修饰为:硫代修饰(phosphorothioates)。所述3’阻滞探针的5'磷酸化修饰,3'硫代修饰。(3端阻滞探针进行了5端磷酸化修饰以及3端至少2个碱基的硫代修饰)所述核酸聚合酶为高温耐热核酸聚合酶:hemoklentaq(neb)、hotstartflexdnapolymerase(neb);所述核酸聚合酶为没有5'到3'核酸外切酶活性的聚合酶。所述核酸连接酶为高温耐热核酸连接酶:taqdnaligase(neb)。所述核酸外切酶为exonucleasei。扩增同一个目标核酸片段的所述3’阻滞探针的tm值高于所述5’延伸引物的tm值。所述3’阻滞探针的tm值高出所述5’延伸引物的tm值4℃-6℃,优选5℃。各所述探针组中的各5’延伸引物的tm值为59℃-68℃;各所述探针组中的各3’阻滞探针的tm值为68℃-75℃。所述的5’延伸引物的第二部分的长度为30-50bp和/或第一部分的长度为18-30bp。所述的3’阻滞探针的第二部分的长度为30-50bp和/或第一部分的长度为21-36bp。各个探针组的5’延伸引物的第二部分是相同或基本相同的。各个探针组的3’阻滞探针的第二部分是相同或基本相同的。具体地,本案以地中海贫血高频热点突变为例,对本案的文库构建方法进行性能验证。其中:地中海贫血高频突变位点如下表:表2地中海贫血基因常见突变位点表针对高频突变位点设计探针对,特异序列扩增长度为130bp-384bp。针对4个参照基因片段设计了4对探针,特异序列扩增长度为117bp-187bp。利用这些探针对采用本发明技术对目的基因片段以及参照基因片段在1个反应体系中进行同时扩增。6个样本在延伸连接之后的pcr扩增时采用含不同标签序列的通用引物对,不同样本的扩增产物先进行混合,纯化定量后采用美国illumina公司的miseq二代测序仪进行测序,测序数据先根据不同标签序列进行分拣,每个样本的测序数据利用burrows-wheeleraligner(bwa)软件进行与人参照基因组进行配对然后进行测序数据统计,同时利用该统计数据进行目的基因片段的拷贝数估计。探针设计方法如下:依据primer3引物设计软件(http://bioinfo.ut.ee/primer3-0.4.0/primer3/)基本原理,针对28个变异位点设计了54对引物探针组,特异序列扩增长度为130bp-384bp,同时也针对4个参照基因片段设计了4对探针,特异序列扩增长度为117bp-187bp。5’延伸引物由5’端通用序列(第二部分)加上3’端特异序列(第一部分)组成,其5’端通用序列开始4个碱基之间的磷酯键用硫酯键代替(phosphorothioates修饰),5’端通用序列为5’acactctttccctacacgacgctcttccgatct3’,3’阻滞探针由5’端特异序列(第一部分)加上3’端通用序列(第二部分)组成,其5’端进行磷酸化修饰,而3’端最后4个碱基之间的磷酯键用硫酯键代替,3’端通用序列为5’agatcggaagagcacacgtctgaactccagtctt3’。5’延伸引物特异序列的tm值为59℃-68℃,3’阻滞探针特异序列的tm值为68℃-75℃,同一个扩增片段的3’阻滞探针的tm值通常比5’延伸引物大5℃以上。精确定量引物探针浓度,配制引物探针mix:其中延伸引物终浓度为0.0025μm/each,阻滞探针终浓度为0.005μm/each。表3地中海贫血引物探针信息表备注:p表示5`端磷酸化修饰,*表示3`端硫代修饰。表4地中海贫血扩增基因片段信息表待测样本dna抽提方法如下:样本来自地中海贫血患者全血样本,样本采用长沙三济生物科技有限公司生产的“核酸提取或纯化试剂”提取dna后,用1×te(ph8.0)溶解,并用qubit测定浓度。s2、杂交所述5’延伸引物和所述3’阻滞探针在高温变性、退火过程中与所述待测样本的目标核酸片段特异性杂交,获得杂交产物,所述5’延伸引物的3'末端与所述3’阻滞探针的5'末端至少间隔1个核苷酸的距离;具体地,杂交实验流程如下:(1)配制反应体系1,其中单个反应体系10μl包含4×gc反应液、dna200ng(依据浓度计算加入体积),剩余用1×te(ph8.0)补至10μl。运行如下pcr程序:98℃10min;4℃保温。(2)配制反应体系2,其中单个反应体系5μl包含10×杂交液、引物探针mix、ddh2o。(3)每单个反应体系1中加入单个反应体系2,震荡混匀后,运行如下pcr程序:95℃for5min;52℃3h。室温放置10min后备用。s3、酶切纯化对步骤二的所述杂交产物,用核酸外切酶进行消化处理,再用磁珠进行纯化,从而获得经纯化的反应混合物,所述反应混合物中含有未被消化的所述杂交产物;其中,同时加入5'端方向核酸外切酶和3'端方向核酸外切酶。具体地,酶切纯化实验流程如下:(1)配制酶纯化混合液,其中单个反应体系5μl包含exoi(20u/μl)、10×exoibuffer(neb)、mgcl2(100mm)、ddh2o,震荡混匀。(2)步骤3(3)杂交反应加入酶纯化混合液5μl,轻微震荡混匀,3000rpm离心2min,37℃30min。(3)加入样品体积1.5倍磁珠,用移液器上下混匀10次。(4)50℃温浴10分钟(中间5分钟时拿出振荡混匀),置于磁力分离架上直至上清澄清,小心移去上清。(5)15μl30mmkcl/(10mmtris-cl,ph8.0)洗脱,轻微振荡后室温放置10min(中间5min、10min时各振荡1次),置于磁力分离架上直至上清澄清,小心取上清洗脱液13μl进行后续操作。s4、延伸连接纯化在所述核酸聚合酶作用下,所述5’延伸引物沿所述目标核酸片段进行dna链延伸,延伸至所述3’阻滞探针的5'末端时被其阻滞,获得5’延伸引物延伸dna链;以及在所述核酸连接酶的作用下,将所述5’延伸引物延伸dna链3'端与所述3’阻滞探针5'端连接,从而形成含连接产物的反应混合物;和任选地重复上述“变性-退火-延伸-连接”,从而增加所述反应混合物中所述连接产物的数量;对所述反应液混合物中的所述连接产物用磁珠进行纯化;其中,延伸连接产物的特异序列(即目标核酸序列)长度为226-492bp。扩增循环数为4-20次,优选16次。使用1.5×磁珠纯化回收连接产物是:使用beckman商用xp磁珠用于产物的纯化,最终使用1×te(ph8.0)洗脱溶解dna,其他根据商用产品说明进行纯化回收,以及根据文库需求进行片段筛选。具体地,延伸连接纯化实验流程如下:(1)配置20μl反应体系,其中含4×gcsolution、5×hemoklentaqbuffer、hemoklentaq、50mmnad、100mmmgcl2、taqdnaligase(500u/μl)、洗脱液13μl。(2)运行如下pcr程序:58℃30min;4℃保温。(3)加入样品体积1.5倍磁珠,用移液器上下混匀10次。置于磁力分离架上直至上清澄清,小心移去上清。(4)15μl10mmtris-cl,ph8.0洗脱,轻微振荡后室温放置10min(中间5min、10min时各振荡1次),置于磁力分离架上直至上清澄清,小心取上清洗脱液13μl进行后续操作。s5、富集以步骤四的所述纯化后的连接产物为模板,进行pcr扩增,从而获得pcr扩增产物,即为富集的核酸片段;将所述pcr扩增产物再用磁珠进行纯化,即可得到核酸片段测序文库。其中,在pcr扩增过程中,采用的pcr引物上带有标签序列,所述标签序列长度为5-10bp,优选8bp;所述的pcr引物的长度为42-58bp。不同样本的连接产物可以用带不同标签序列的pcr引物进行扩增,这样不同样本的扩增产物可以混合在一起,在后续测序数据中可以根据该标签序列对测序序列进行归类。所述pcr扩增过程中,采用的pcr引物包括正向引物和反向引物,所述正向引物包含能够与所述5’延伸引物的所述第二部分序列的反向互补序列特异性杂交的序列,所述反向引物包含与所述3’阻滞探针的所述第二部分特异性杂交的序列。所述正向引物和/或所述反向引物中含有与illumina高通量芯片测序平台兼容的通用序列。所述正向引物和/或所述反向引物中含有标签序列,针对不同的样本采用不同的标签序列。所述5’延伸引物的所述第二部分序列为:5’acactctttccctacacgacgctcttccgatct3’。所述3’阻滞探针的所述第二部分序列为:5’agatcggaagagcacacgtctgaactccagtctt3’。所述正向引物序列为:5’aatgatacggcgaccaccgagatctacactctttccctacac3’。所述反向引物序列为:5’caagcagaagacggcatacgagat[x]atggcaaaaatggtgctcaagg3’,其中[x]为标签序列,[x]长度为5-10bp。具体地,富集实验流程如下:1、连接产物pcr扩增(1)pcr扩增引物对为一条正向通用引物(5’aatgatacggcgaccaccgagatctacactctttccctacac3’和一条样本特异反向引物(5’caagcagaagacggcatacgagat[x]atggcaaaaatggtgctcaagg3’,这里[x]为标签序列,6个样本对应的标签序列为ctctgtga,aaggggtt,attaagct,gctattac,ccagacta和ctcaggag。(2)pcr反应体系为25μl,其中含10×takarabuffer、25mmmgcl2、10mmdntp混合液、10μm引物、1.5udna聚合酶以及13μl上述延伸连接纯化产物。(3)反应体系混合液瞬时离心后,按如下pcr程序运行:95℃10min;(95℃20s,63℃40s-0.5℃/cycle,72℃2min)×11;(95℃20s,65℃30s,72℃2min)×27;72℃10min;4℃保温。2、pcr产物质检(1)pcr产物1μl稀释10倍,取0.5μl进行荧光标记pcr。(2)荧光标记pcr反应引物对为一条正向引物ngpcrf(5’-[fam]aatgatacggcgaccaccgagatc3’,)和一条反向引物ngpcr-qcr(5’-gtttcttcaagcagaagacggcatacgagat3’)(3)配制10μl反应体系,其中含稀释后pcr产物、10×takarabuffer、25mmmgcl20.、10mmdntp混合液、5μm引物、0.4udna聚合酶、h2o。(4)反应混合液瞬时离心后,按如下pcr程序运行:95℃2min;(95℃20s,65℃30s,72℃2min)×12;60℃30min;4℃保温。(5)先取0.5μl进行ce检测,如果发现过高或过低,则通过稀释或增加循环数调整。3、pcr产物相对浓度估算(1)以同一长度分子内标为参照,针对4个在不同条件及不同样本都扩增良好的峰的峰高信息对扩增产物相对浓度进行估算校正。(2)将定量峰峰高除以分子内标得到r值,然后将r值除以中位数r值(rm),获得rr值;依次完成依据4个定量峰获得的rr值,取中位数作为该产物相对浓度(rrm)。4、将上述6个样本的pcr扩增产物按照1/rrm*5μl混合,取50μl进行1.2×磁珠纯化,纯化后产物采用rt-qpcr进行分子数定量,同时提供上样所需的文库信息(如index,长度范围等),测序数据按照每个片段2000×上样量估计。5、定量后的文库上美国illumina公司的miseq二代测序仪进行测序。实施例3、实验结果数据分析对测序数据根据不同标签序列进行分拣获得每个样本的测序数据,通过与参考扩增序列blast确定每个目的及参照片段的测序深度,统计每个样本总测序量,每个目的及参照片段的测序深度以及每个样本的富集效率。非缺失突变特异扩增片段测序reads先剔除引物探针序列以及扩增序列2侧近引物探针的3个碱基序列后进行后续snv/indel分析,非缺失突变特异扩增片段的测序深度数据用于各基因片段的拷贝数分析。1)snv/indel分析:测序数据采用bwa,gatk以及annovar等二代测序数据分析软件分析获得每个检测样本每个测序片段测序数据以及snv/indel数据信息2)基因片段拷贝数分析:对于测序深度>50的进行后续拷贝数计算,测序深度小于中位值5%但不超过10次的基因片段拷贝数判定为0,其它测序深度的不做拷贝数计算。基因片段拷贝数计算如下:a,将检测样本目标基因片段测序深度除以第1个参照基因片段测序深度获得r值;b,将检测样本r值除以正常样本的r值并乘以正常样本该目标基因片段拷贝数值即获得该目标基因片段相对这个参照基因片段的拷贝数检测值;d,按上述方法获得该基因片段相对其它参照基因片段的拷贝数检测值,取上述计算数值的中位数值作为该基因片段的拷贝数检测值;d,依次循环获得检测样本所有目标基因片段的拷贝数检测值。3)缺失突变判定3.1)-α3.7以及-α4.2判定主要根据hba1以及hba2上下游特异探针拷贝数变化来判定:a)hba2et01,hba2et02,hba2et15,hba2et16,hba2et17,hba2et18,hba2et19,hba2et20a,扩增片段拷贝数正常,位于其中间的hba2et03,hba2et04,hba2et13及hba2et14扩增片段的拷贝数减少,则判定存在-α4.2缺失突变;b)hba2et01,hba2et02,hba2et03,hba2et04,hba2et17,hba2et18,hba2et19及hba2et20a扩增片段拷贝数正常,位于其中间的hba2et03,hba2et04,hba2et13,hba2et14及hba2et15扩增片段的拷贝数减少,则判定存在-α3.7缺失突变。3.2)其它存在明确断点的缺失突变可根据1侧断点以及缺失特异扩增片段是否存在进行判定,但也可通过缺失区域扩增片段的拷贝数减少进行辅助判定:a)主要判定方法:1侧断点扩增片段存在但缺失特异扩增片段不存在,则判定不存在该缺失突变,为正常纯合;如果1侧断点及缺失特异扩增片段都存在,则判定杂合突变;如果缺失特异扩增片段都存在但1侧断点扩增片段不存在,则判定突变;b)辅助判定方法:但缺失突变存在时,缺失区域的扩增片段拷贝数应该减少。本发明6样本建库测序实验数据分析结果1)每个扩增基因片段的测序深度数据参见,表5、6样本扩增片段测序深度表。2)6个样本非缺失突变特异扩增片段的测序数据统计参见,表6、6样本测序数据统计表。数据统计时因为缺失导致的无测序数据值不纳入统计。3)点突变以及微小插入缺失突变分析参照上述分析方法,检测结果参见,表7、目标突变位点检测结果表。4)对于已知明确断点的缺失突变主要通过分析断点扩增片段以及缺失特异扩增片段的测序深度直接判定,同时也以基因片段拷贝数分析数据验证,而对于-α3.7以及-α4.2缺失突变则主要依据基因片段拷贝数分析数据(参见,表8、hbb,hba1及hba2基因片段检测拷贝数表及图2-6)来判定。其中,chinese(aγδβ)0-以及--sea的判定结果参见,表7、目标突变位点检测结果表。在case02中存在—sea缺失突变,而且hba2et03,hba2et04,hba2et13及hba2et14拷贝数减少,因此判定存在-α4.2缺失突变。在case03中,存在hba2et03,hba2et04,hba2et13,hba2et14及hba2et15扩增片段的拷贝数减少,因此判定存在-α3.7缺失突变。结论:从统计数据看,6个样本均实现54个基因片段的有效富集:其富集效率均达到80%以上,平均有效读数500×以上的片段分别为38个,测序深度到达200×以上的片段均为45个。表56样本扩增片段测序深度表表66样本测序数据统计表表7、目标突变位点检测结果表表8、hbb,hba1及hba2基因片段检测拷贝数表本发明提供的用于检测地中海贫血基因突变的高通量文库构建试剂盒及文库构建方法具有以下有益效果:一、本发明提供的用于检测地中海贫血基因突变的高通量文库构建试剂盒,操作步骤简单,地中海贫血基因目标区域富集后通过一次的pcr扩增,然后采用磁珠纯化产物,即得到地中海贫血基因测序文库,减少了纯化次数,可以有效减少建库过程中地中海贫血基因dna样本的损失;同时降低了建库的成本,减少了pcr扩增中引入突变的可能性,使得测序结果更加精确。二、本发明提供的用于检测地中海贫血基因突变的文库构建方法,关键在于针对地中海贫血基因目的区域设计引物及探针,通过延伸连接反应富集目的片段,对地中海贫血基因目的基因组区域进行捕获富集;一个延伸连接反应体系可以获得<200kb的区域内所有目的片段的连接产物;该方法快速、步骤简单,直接富集扩增效率极高,无需复杂的建库过程在文库构建中,能够高效、准确的计算dna含量;从而在高通量测序之后,能够依据测序对地贫相关的突变进行分型。三、常规探针杂交捕获富集技术需要样本基因组dna超声打碎、全基因组文库构建及杂交捕获富集等操作,操作复杂,实验流程长,而该试剂盒操作相对于全基因组文库构建,操作较简单,实验流程缩短;常规杂交捕获富集技术富集由于涉及更多步骤,使用更多试剂,成本高,而该试剂盒可显著降低成本。四、常规探针杂交捕获富集技术富集效果为40-60%,而该试剂盒富集效率可高达80%以上。五、常规杂交捕获富集技术富集的文库测序数据对单个目标基因片段的拷贝数检测波动大,准确性不高,而该试剂盒富集文库的测序数据对目标片段的拷贝数检测波动小,准确性高。以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书内容所作的等效流程变换,或直接或间接运用在其它相关的
技术领域:
,均同理包括在本发明的专利保护范围内。序列表<110>广州赛乐斯密医学科技有限公司南方医科大学<120>用于检测地中海贫血基因突变的高通量文库构建试剂盒及文库构建方法<130>2020<141>2020-07-09<160>98<170>siposequencelisting1.0<210>1<211>55<212>dna<213>人工序列(artificialsequence)<400>1acactctttccctacacgacgctcttccgatctccccattagcagcatggagagt55<210>2<211>56<212>dna<213>人工序列(artificialsequence)<400>2tgaacaggaagcagaaggacccagatcggaagagcacacgtctgaactccagtctt56<210>3<211>55<212>dna<213>人工序列(artificialsequence)<400>3acactctttccctacacgacgctcttccgatctcaccagcttaccacctccatcc55<210>4<211>56<212>dna<213>人工序列(artificialsequence)<400>4ccacagccagagtggaaagtgaagatcggaagagcacacgtctgaactccagtctt56<210>5<211>55<212>dna<213>人工序列(artificialsequence)<400>5acactctttccctacacgacgctcttccgatctctttgtgcctctcggctgattt55<210>6<211>56<212>dna<213>人工序列(artificialsequence)<400>6tggagcaagcctgtgagttctgagatcggaagagcacacgtctgaactccagtctt56<210>7<211>55<212>dna<213>人工序列(artificialsequence)<400>7acactctttccctacacgacgctcttccgatctgggaaggggcaatcaataggag55<210>8<211>56<212>dna<213>人工序列(artificialsequence)<400>8ctattccacagggcagcaaaccagatcggaagagcacacgtctgaactccagtctt56<210>9<211>55<212>dna<213>人工序列(artificialsequence)<400>9acactctttccctacacgacgctcttccgatctcccgaggagagtgagtgaaacc55<210>10<211>56<212>dna<213>人工序列(artificialsequence)<400>10atgaagcaggagctgcagaaccagatcggaagagcacacgtctgaactccagtctt56<210>11<211>53<212>dna<213>人工序列(artificialsequence)<400>11acactctttccctacacgacgctcttccgatctcaagaagcatggccaccgag53<210>12<211>53<212>dna<213>人工序列(artificialsequence)<400>12gctacacctcccgcaacccagatcggaagagcacacgtctgaactccagtctt53<210>13<211>55<212>dna<213>人工序列(artificialsequence)<400>13acactctttccctacacgacgctcttccgatctaccgtgctgacctccaaatacc55<210>14<211>57<212>dna<213>人工序列(artificialsequence)<400>14ggatagggtaggaaaaggcagggagatcggaagagcacacgtctgaactccagtctt57<210>15<211>56<212>dna<213>人工序列(artificialsequence)<400>15ctttatggctaccagctccgggagatcggaagagcacacgtctgaactccagtctt56<210>16<211>56<212>dna<213>人工序列(artificialsequence)<400>16tgtgactgactctcccactggcagatcggaagagcacacgtctgaactccagtctt56<210>17<211>56<212>dna<213>人工序列(artificialsequence)<400>17acactctttccctacacgacgctcttccgatctggtcagacctccattcttcctga56<210>18<211>55<212>dna<213>人工序列(artificialsequence)<400>18acactctttccctacacgacgctcttccgatctagcagggagaggagggttcttg55<210>19<211>56<212>dna<213>人工序列(artificialsequence)<400>19acagcaccacggcagcttatttagatcggaagagcacacgtctgaactccagtctt56<210>20<211>55<212>dna<213>人工序列(artificialsequence)<400>20acactctttccctacacgacgctcttccgatcttgcatcccctgactctctctcc55<210>21<211>56<212>dna<213>人工序列(artificialsequence)<400>21gctagagcattggtggtcatgcagatcggaagagcacacgtctgaactccagtctt56<210>22<211>55<212>dna<213>人工序列(artificialsequence)<400>22acactctttccctacacgacgctcttccgatctccatgctgagggaacacagcta55<210>23<211>56<212>dna<213>人工序列(artificialsequence)<400>23gcatccctttcagccagttcatagatcggaagagcacacgtctgaactccagtctt56<210>24<211>59<212>dna<213>人工序列(artificialsequence)<400>24acactctttccctacacgacgctcttccgatctcagataaacaaacttggctctgggta59<210>25<211>52<212>dna<213>人工序列(artificialsequence)<400>25caaggcgggtggatcagcagatcggaagagcacacgtctgaactccagtctt52<210>26<211>55<212>dna<213>人工序列(artificialsequence)<400>26acactctttccctacacgacgctcttccgatctcaggaagggccggtgcaaggag55<210>27<211>56<212>dna<213>人工序列(artificialsequence)<400>27ctacacctcccgcaacccgcgtagatcggaagagcacacgtctgaactccagtctt56<210>28<211>55<212>dna<213>人工序列(artificialsequence)<400>28acactctttccctacacgacgctcttccgatctaccgtgctgacctccaaatacc55<210>29<211>54<212>dna<213>人工序列(artificialsequence)<400>29gctggggagggagaactgcaagatcggaagagcacacgtctgaactccagtctt54<210>30<211>52<212>dna<213>人工序列(artificialsequence)<400>30acactctttccctacacgacgctcttccgatcttgggtgtccaggagcaagc52<210>31<211>55<212>dna<213>人工序列(artificialsequence)<400>31actctgcccacagcctgaaggagatcggaagagcacacgtctgaactccagtctt55<210>32<211>55<212>dna<213>人工序列(artificialsequence)<400>32acactctttccctacacgacgctcttccgatctgctgacctgatgcactcctcaa55<210>33<211>56<212>dna<213>人工序列(artificialsequence)<400>33ccagaagtccaccccttccttcagatcggaagagcacacgtctgaactccagtctt56<210>34<211>58<212>dna<213>人工序列(artificialsequence)<400>34acactctttccctacacgacgctcttccgatctggtaaacaaagcaatagctggaacc58<210>35<211>56<212>dna<213>人工序列(artificialsequence)<400>35aggaagtctggaggtgtggacgagatcggaagagcacacgtctgaactccagtctt56<210>36<211>55<212>dna<213>人工序列(artificialsequence)<400>36acactctttccctacacgacgctcttccgatctcctagcgagggagaaagtcagc55<210>37<211>54<212>dna<213>人工序列(artificialsequence)<400>37ctgctctccagcctcgcttcagatcggaagagcacacgtctgaactccagtctt54<210>38<211>54<212>dna<213>人工序列(artificialsequence)<400>38acactctttccctacacgacgctcttccgatctcgcccgtgtgttccccgatcc54<210>39<211>54<212>dna<213>人工序列(artificialsequence)<400>39gggatgggcgggagtggagtagatcggaagagcacacgtctgaactccagtctt54<210>40<211>53<212>dna<213>人工序列(artificialsequence)<400>40acactctttccctacacgacgctcttccgatctgcctggaccgcaggggagtc53<210>41<211>53<212>dna<213>人工序列(artificialsequence)<400>41gttggggtcgggcgctgtcagatcggaagagcacacgtctgaactccagtctt53<210>42<211>51<212>dna<213>人工序列(artificialsequence)<400>42acactctttccctacacgacgctcttccgatctgagacgtcctggcccccg51<210>43<211>56<212>dna<213>人工序列(artificialsequence)<400>43cggcactcttctggtccccacaagatcggaagagcacacgtctgaactccagtctt56<210>44<211>54<212>dna<213>人工序列(artificialsequence)<400>44acactctttccctacacgacgctcttccgatctagggcctccgcaccatactcg54<210>45<211>54<212>dna<213>人工序列(artificialsequence)<400>45ggtttatgcttggggcgcggagatcggaagagcacacgtctgaactccagtctt54<210>46<211>55<212>dna<213>人工序列(artificialsequence)<400>46acactctttccctacacgacgctcttccgatctcctgccgacaagaccaacgtca55<210>47<211>56<212>dna<213>人工序列(artificialsequence)<400>47acaggccaccctcaaccgtcctagatcggaagagcacacgtctgaactccagtctt56<210>48<211>52<212>dna<213>人工序列(artificialsequence)<400>48acactctttccctacacgacgctcttccgatctgggtccacccgaagcttgt52<210>49<211>52<212>dna<213>人工序列(artificialsequence)<400>49gaggagcccgggtcggagagatcggaagagcacacgtctgaactccagtctt52<210>50<211>51<212>dna<213>人工序列(artificialsequence)<400>50acactctttccctacacgacgctcttccgatctgtccgccctgagcgacct51<210>51<211>56<212>dna<213>人工序列(artificialsequence)<400>51ctgcacagctcctaagccactgagatcggaagagcacacgtctgaactccagtctt56<210>52<211>56<212>dna<213>人工序列(artificialsequence)<400>52accacacccagctgccatttttagatcggaagagcacacgtctgaactccagtctt56<210>53<211>56<212>dna<213>人工序列(artificialsequence)<400>53gtccaggggaatttgcactctgagatcggaagagcacacgtctgaactccagtctt56<210>54<211>59<212>dna<213>人工序列(artificialsequence)<400>54acactctttccctacacgacgctcttccgatctgccaaagaaattttgaaaaggaagaa59<210>55<211>54<212>dna<213>人工序列(artificialsequence)<400>55caaggcgggtggatcacaagagatcggaagagcacacgtctgaactccagtctt54<210>56<211>55<212>dna<213>人工序列(artificialsequence)<400>56ccaacttcaggaggctgaggcagatcggaagagcacacgtctgaactccagtctt55<210>57<211>53<212>dna<213>人工序列(artificialsequence)<400>57acactctttccctacacgacgctcttccgatctcaggcggatcacaaggtcag53<210>58<211>56<212>dna<213>人工序列(artificialsequence)<400>58ataggttcctcagcccccagtcagatcggaagagcacacgtctgaactccagtctt56<210>59<211>53<212>dna<213>人工序列(artificialsequence)<400>59atctccgacgaggccctggagatcggaagagcacacgtctgaactccagtctt53<210>60<211>55<212>dna<213>人工序列(artificialsequence)<400>60acactctttccctacacgacgctcttccgatctgtcatcacagggacagggaggt55<210>61<211>54<212>dna<213>人工序列(artificialsequence)<400>61acactctttccctacacgacgctcttccgatctactcaaggaccccaggagacg54<210>62<211>55<212>dna<213>人工序列(artificialsequence)<400>62acactctttccctacacgacgctcttccgatctcatggcttactgcagccttgaa55<210>63<211>56<212>dna<213>人工序列(artificialsequence)<400>63tgagaacacagagcccagatcgagatcggaagagcacacgtctgaactccagtctt56<210>64<211>56<212>dna<213>人工序列(artificialsequence)<400>64acactctttccctacacgacgctcttccgatctgcaatagatggctctgccctgac56<210>65<211>60<212>dna<213>人工序列(artificialsequence)<400>65tgctactaaaaacatcctcctttgcaagatcggaagagcacacgtctgaactccagtctt60<210>66<211>55<212>dna<213>人工序列(artificialsequence)<400>66acactctttccctacacgacgctcttccgatcttctactcccaggagcagggagg55<210>67<211>56<212>dna<213>人工序列(artificialsequence)<400>67tgggcatgtggagacagagaagagatcggaagagcacacgtctgaactccagtctt56<210>68<211>55<212>dna<213>人工序列(artificialsequence)<400>68acactctttccctacacgacgctcttccgatctttcttgccatgagccttcacct55<210>69<211>63<212>dna<213>人工序列(artificialsequence)<400>69attggtctccttaaacctgtcttgtaaccagatcggaagagcacacgtctgaactccagt60ctt63<210>70<211>55<212>dna<213>人工序列(artificialsequence)<400>70acactctttccctacacgacgctcttccgatcttcctttggggatctgtccactc55<210>71<211>60<212>dna<213>人工序列(artificialsequence)<400>71tggttaagttcatgtcataggaagggagatcggaagagcacacgtctgaactccagtctt60<210>72<211>59<212>dna<213>人工序列(artificialsequence)<400>72acactctttccctacacgacgctcttccgatctactaaaacgatcctgagacttccaca59<210>73<211>54<212>dna<213>人工序列(artificialsequence)<400>73ttctcaggatccacgtgcagagatcggaagagcacacgtctgaactccagtctt54<210>74<211>55<212>dna<213>人工序列(artificialsequence)<400>74acactctttccctacacgacgctcttccgatctcgaatgattgcatcagtgtgga55<210>75<211>64<212>dna<213>人工序列(artificialsequence)<400>75tgtgtgcttatttgcatattcataatctccagatcggaagagcacacgtctgaactccag60tctt64<210>76<211>65<212>dna<213>人工序列(artificialsequence)<400>76acactctttccctacacgacgctcttccgatctgtatcattattgccctgaaagaaagag60attag65<210>77<211>71<212>dna<213>人工序列(artificialsequence)<400>77attccaaatagtaatgtactaggcagactgtgtaaagagatcggaagagcacacgtctga60actccagtctt71<210>78<211>65<212>dna<213>人工序列(artificialsequence)<400>78acactctttccctacacgacgctcttccgatctttgcatttgtaattttaaaaaatgctt60tcttc65<210>79<211>66<212>dna<213>人工序列(artificialsequence)<400>79actgatgtaagaggtttcatattgctaatagcagatcggaagagcacacgtctgaactcc60agtctt66<210>80<211>52<212>dna<213>人工序列(artificialsequence)<400>80acactctttccctacacgacgctcttccgatctagaccagcacgttgcccag52<210>81<211>69<212>dna<213>人工序列(artificialsequence)<400>81taacccagaaattatcactgttattctttagaatgagatcggaagagcacacgtctgaac60tccagtctt69<210>82<211>60<212>dna<213>人工序列(artificialsequence)<400>82acactctttccctacacgacgctcttccgatctcccttttgctaatcatgttcatacctc60<210>83<211>57<212>dna<213>人工序列(artificialsequence)<400>83actgggggatattatgaagggccagatcggaagagcacacgtctgaactccagtctt57<210>84<211>55<212>dna<213>人工序列(artificialsequence)<400>84acactctttccctacacgacgctcttccgatctgcattagctgtttgcagcctca55<210>85<211>58<212>dna<213>人工序列(artificialsequence)<400>85ttggacttagggaacaaaggaaccagatcggaagagcacacgtctgaactccagtctt58<210>86<211>57<212>dna<213>人工序列(artificialsequence)<400>86acactctttccctacacgacgctcttccgatcttgtggaactgtgttgtgaggctaa57<210>87<211>58<212>dna<213>人工序列(artificialsequence)<400>87acactctttccctacacgacgctcttccgatctgacatattcaaacttccgcagaaca58<210>88<211>56<212>dna<213>人工序列(artificialsequence)<400>88ttgcttgtttgagcctggctttagatcggaagagcacacgtctgaactccagtctt56<210>89<211>56<212>dna<213>人工序列(artificialsequence)<400>89ccaatgtcaatgcaaaacccaaagatcggaagagcacacgtctgaactccagtctt56<210>90<211>56<212>dna<213>人工序列(artificialsequence)<400>90acttttccaaagcctcccccacagatcggaagagcacacgtctgaactccagtctt56<210>91<211>55<212>dna<213>人工序列(artificialsequence)<400>91acactctttccctacacgacgctcttccgatctctttcaactgggctgtggacat55<210>92<211>66<212>dna<213>人工序列(artificialsequence)<400>92caagatttaaattatggccagtgactagtgctagatcggaagagcacacgtctgaactcc60agtctt66<210>93<211>58<212>dna<213>人工序列(artificialsequence)<400>93tgttgtgttagggatgtggtgacaagatcggaagagcacacgtctgaactccagtctt58<210>94<211>59<212>dna<213>人工序列(artificialsequence)<400>94acactctttccctacacgacgctcttccgatctcagctggacacatataaaatgctgct59<210>95<211>56<212>dna<213>人工序列(artificialsequence)<400>95acactctttccctacacgacgctcttccgatcttggggtgggagaagaaataatgg56<210>96<211>56<212>dna<213>人工序列(artificialsequence)<400>96atgcttgccaaagtgcttctggagatcggaagagcacacgtctgaactccagtctt56<210>97<211>58<212>dna<213>人工序列(artificialsequence)<400>97acactctttccctacacgacgctcttccgatctcatcagagcttaaactgggaagctg58<210>98<211>59<212>dna<213>人工序列(artificialsequence)<400>98ctgaagttgatataaccagggtgccagatcggaagagcacacgtctgaactccagtctt59当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1