一种基于人工神经网络的车辆协同换道方法及其系统与流程
本发明属于车联网安全
技术领域:
,尤其是一种基于人工神经网络的车辆协同换道方法及其系统。
背景技术:
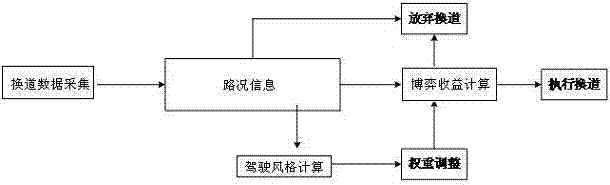
:交通事故是危害人类安全和社会发展的重要问题。据统计,多达90%的交通事故是由超速、醉驾、疲劳、操作不当等人为因素造成。因此,无人驾驶汽车受到越来越多学者和研究人员的关注。智能网联汽车根据智能化程度分为五个等级:驾驶辅助、部分自动驾驶、有条件自动驾驶、高度自动驾驶和完全自动驾驶。现阶段无人驾驶处于发展的起步阶段,实现了人与系统共同驾驶,距离完全自动驾驶还有很长的路,人类因素仍然会长期存在。况且,驾车乐趣是任何先进的技术无法取代的,传统人类驾驶汽车不会完全消失,在未来很长时间内,将会处于无人驾驶与人类驾驶并存的混合行驶环境。如果无人驾驶汽车缺少与人类驾驶汽车的有效协同机制,反而更容易发生事故。换道通常伴随超车,是影响车辆安全的主要行为之一。换道不仅受到交通法规的约束,还与驾驶员的驾驶风格紧密相关。不同驾驶员受自身心理、性格甚至情绪等因素影响会有不同的驾驶风格,具体表现为驾驶过程中的礼让、竞争甚至对抗,应对不同车辆应该选取不同的驾驶策略。驾驶心理是极其复杂的,影响竞争倾向的因素包括刺激、威胁、动机、信息交互等心理因素。因此,在混合行驶环境避免事故需要无人驾驶具有类人行为能力。目前换道方法存在诸多问题:(1)传统方法模型主要依靠无人驾驶自身获取信息进行决策,缺少与人类驾驶之间的协作,不具备类人行为能力,不能适应混合行驶的新型交通环境;(2)传统换道方法追求车辆安全、行驶效率等“理性”因素,实际情况是车辆的行为同样受示威、较劲等“非理性”因素影响,而这些“非理性”因素更容易导致交通事故;(3)大部分研究人员在分析驾驶员风格时,仅仅通过调查取样分类,定性分析不能保证精度,缺少量化分析能力;(4)部分分析算法只是把监测数据与先前样本简单比对,缺少自学习能力,风格分析需要积累一定数量的经验知识才具备预判能力,自学习功能对预测有重要意义。技术实现要素:本发明的目的是提供一种充分考虑理性和非理性因素,处理速度快、更加贴近真实场景的基于人工神经网络的车辆协同换道方法及其系统。本发明解决现有技术问题所采用的技术方案:一种基于人工神经网络的车辆协同换道方法,包括以下步骤:s1:换道数据采集及换道需求判断:a1、换道数据采集:通过安装在车辆上的数据采集模块采集车辆在行驶过程中的路况信息,所述路况信息包括车辆在当前车道的速度及加速度、相邻车道中与当前车辆对应的前导车辆的速度及加速度、相邻车道中与当前车辆对应的滞后车辆的速度及加速度和周边限制要素的运动速度,以及当前车辆与所述前导车辆、滞后车辆以及周边限制要素之间的相对距离;所述前导车辆是位于当前车辆前方的车辆;所述滞后车辆是位于当前车辆后方的车辆;a2、换道需求判断:根据换道需求判断条件,判断当前车辆是否有换道需求:若当前车辆同时不满足换道需求判断条件,则当前车辆不需要换道,即放弃换道;若当前车辆满足需求判断条件中的至少一条,则当前车辆需要换道;所述换道需求判断条件为:其中,δxi为当前车辆i与前导车辆或周边交通要素之间的相对距离,vie为当前车辆i的预设期望速度,vic为当前车辆i的速度,vi+1为与当前车辆i对应的前导车辆的速度,tsafe为预设安全时距,tmin为预设最小反应时间,vbar为周边限制要素的运动速度,i≥1;s2、博弈收益计算:建立与换道行为相对应的博弈换道模型:将步骤a2中需要换道的车辆的可能行为策略作为行描述,将该车辆对应的滞后车辆的可能行为策略作为列描述,建立与换道行为相对应的博弈换道模型;并以博弈收益值数值对作为博弈换道模型的元素,每个博弈收益值数值对作为在对应行描述和列描述条件下的数值表示;提取博弈换道模型的元素构建成为博弈收益矩阵,博弈收益矩阵中的元素为(pij,qij),其中,pij、qij分别为在行描述i和列描述j的条件下,需要换道的车辆及与该车辆对应的滞后车辆的博弈收益值,且通过以下公式获得:pij(或qij)=α*a+β*b其中,α、β为权重系数,且满足α+β=1,α、β的初始值均为0.5;对于需要计算博弈收益的车辆vx,a、b分别由以下公式计算:其中,vx为车辆vx的速度,ax为车辆vx的加速度,δt为采集间隔时间,δxa为车辆vx与前导车辆的相对距离,δxb为车辆vx与滞后车辆的相对距离,vxaccsafe为车辆vx加速时的安全速度,vxdecsafe为车辆vx减速时的安全速度;所述车辆vx加速时的安全速度vxaccsafe的获取方法为:当车辆vx加速时,设车辆va为此时车辆vx的期望前导车辆,车辆va与车辆vx的距离为δx,通过数据采集模块得到期望前导车辆va的速度、加速度分别为va、aa,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx加速后经过t=δt+tmin与va碰撞的速度vmax满足以下条件:求出vmax后,得到车辆vx加速的安全速度vxaccsafe为:车辆vx减速时的安全速度vxdecsafe的获取方法为:当车辆vx减速时,设车辆vc为此时车辆vx的期望前导车辆,通过步骤s1得到车辆vc与车辆vx的距离为δxc,期望前导车辆vc的速度、加速度分别为vc、ac,车辆vx的速度、加速度分别为vx、ax;采集间隔为δt,最小反应时间tmin,则使vx减速后经过t=δt+tmin与vc碰撞的速度vmax1满足以下条件:同时,车辆vx需要避免与其滞后车辆vb发生碰撞,通过步骤s1采集到的车辆vx与车辆vb的相对距离为δxb,vb的速度、加速度分别为vb、ab,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx减速后经过t=δt+tmin与vb碰撞的速度vmax2满足:得到减速后的最大速度vmax、安全减速度asafe分别为:vmax=max{vmax1,vmax2}车辆vx减速的安全速度vxdecsafe为:s3、驾驶风格得分计算:通过人工神经网络使用反向传播算法,将步骤s1得到的速度、加速度和相对距离作为输入值计算速度得分、加速度得分、安全时距得分,并将上述得分作为输入值输入神经网络的输出函数中得到驾驶风格得分:b1、计算速度得分:使用krauss模型的安全速度公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆的安全速度速度得分ev为:其中,visafe(t+δt)为待评分车辆i在t+δt时刻的安全速度,δt为观察时间,vi+1(t)为与待评分车辆i对应的前导车辆i+1在t时刻的速度,δxi(t)为待评分车辆i与前导车辆i+1在t时刻的相对位移,δvi(t)为待评分车辆i与前导车辆i+1在t时刻的相对速度差,t为预设反应时间,a为最大加速度,vmax为预设最高速度,vmin为预设最低速度;b2、计算加速度得分:利用以下公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆加速度积分ia:加速度得分ea为:其中,ia为加速度积分,a为待评分车辆的加速度值,δt为自车辆决定换道到观察分析的时间差,|a|x为人类对加速度的主观感受函数,abrk为车辆最大制动加速度;b3、计算安全时距得分:利用以下公式计算安全时距tsafe:安全时距得分es为:其中,tsafe为安全时距;δxsafe(vi)为使车辆vi完全停止的最小距离,l为车身长度,xbrk为制动距离,vi为当前车辆i的速度,tmin为预设最小反应时间;b4、计算驾驶风格得分:将得到的速度得分、加速度得分和安全时距得分作为输入值输入到神经网络的输出函数中得到驾驶风格得分,其中,采用非线性s型的log-sigmoid函数:其中,为神经元激发函数:其中,n为列描述的个数,xi为车辆i的速度得分、加速度得分、安全时距得分,wji、bj分别为激活函数的权重和偏置,权重和偏置为由人工神经网络自学习调整得到,的值域为(0,1);整个神经网络的误差函数如下所示:其中,d为真实值;通过梯度下降法调整人工神经网络的权值:其中,η为学习速度;s4、权重调整:确定权重系数α、β:由α+β=1,权重即需换道车辆的前导车辆与滞后车辆驾驶风格得分在总分中的占比:其中,oa为前导车辆的驾驶风格得分,ob为滞后车辆的驾驶风格得分;s5、换道决策:根据步骤s4得到的调整后的权重重新计算步骤s2的博弈收益值,设p为当前车辆vc换道的概率,q1为滞后车辆vl加速的概率,q2为滞后车辆vl减速的概率,则vc、vl的混合概率期望收益ec、el如下所示:ec(p,q1,q2)=p[p'13-p'23+q1(p'11+p'23-p'13-p'21)+q2(p'12+p'23-p'13-p'22)]+[p'23+q1(p'21-p'23)+q2(p'22-p'23)]el(p,q1,q2)=q'23+p(q'13-q'23)+q1[q'21-q'23+p(q'11+q'23-q'13-q'21)]+q2[q'22-q'23+p(q'12+q'23-q'13-q'22)]其中,p'ij,q'ij分别为使用步骤s4调整后的权重获得的车辆vc、vl的博弈收益值;通过对求解概率参数(p,q1,q2)的至少一个最优解(p*,q1*,q2*),使ec、el达到最大,即满足:车辆根据(p*,q1*,q2*)的值决定是否执行换道或放弃换道。所述周边限制要素包括障碍物、重型车辆、应急车辆。一种基于人工神经网络的车辆协同换道系统,包括以下模块:换道数据采集及换道需求判断模块:包括以下模块:换道数据采集模块:在车辆上安装数据采集模块用于采集并输出车辆在行驶过程中的路况信息,所述路况信息包括车辆在当前车道的速度及加速度、相邻车道中与当前车辆对应的前导车辆的速度及加速度、相邻车道中与当前车辆对应的滞后车辆的速度及加速度和周边限制要素的运动速度,以及当前车辆与所述前导车辆、滞后车辆以及周边限制要素之间的相对距离;所述前导车辆是位于当前车辆前方的车辆;所述滞后车辆是位于当前车辆后方的车辆;换道需求判断模块:用于根据换道需求判断条件,判断当前车辆是否有换道需求:若当前车辆同时不满足换道需求判断条件,则当前车辆不需要换道,即放弃换道;若当前车辆满足需求判断条件中的至少一条,则当前车辆需要换道;所述换道需求判断条件为:其中,δxi为当前车辆i与前导车辆或周边交通要素之间的相对距离,vie为当前车辆i的预设期望速度,vic为当前车辆i的速度,vi+1为与当前车辆i对应的前导车辆的速度,tsafe为预设安全时距,tmin为预设最小反应时间,vbar为周边限制要素的运动速度,i≥1;博弈收益计算模块:用于建立与换道行为相对应的博弈换道模型:将换道需求判断模块中需要换道的车辆的可能的行为策略作为行描述,将该车辆对应的滞后车辆可能的行为策略作为列描述,建立与换道行为相对应的博弈换道模型;并以博弈收益值数值对作为博弈换道模型的元素,每个博弈收益值数值对作为在对应行描述和列描述条件下的数值表示;提取博弈换道模型的元素构建成为博弈收益矩阵,博弈收益矩阵中的元素为(pij,qij),其中,pij、qij分别为在行描述i和列描述j的条件下,需要换道的车辆,及与该车辆对应的滞后车辆的博弈收益值,且通过以下公式获得:pij(或qij)=α*a+β*b其中,α、β为权重系数,且满足α+β=1,α、β的初始值均为0.5;对于需要计算博弈收益的车辆vx,a、b分别由以下公式计算:其中,vx为车辆vx的速度,ax为车辆vx的加速度,δt为采集间隔时间,δxa为车辆vx与前导车辆的相对距离,δxb为车辆vx与滞后车辆的相对距离,vxaccsafe为车辆vx加速时的安全速度,vxdecsafe为车辆vx减速时的安全速度;所述车辆vx加速时的安全速度vxaccsafe的获取方法为:当车辆vx加速时,设车辆va为此时车辆vx的期望前导车辆,车辆va与车辆vx的距离为δx,通过数据采集模块得到期望前导车辆va的速度、加速度分别为va、aa,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx加速后经过t=δt+tmin与va碰撞的速度vmax满足以下条件:求出vmax后,得到车辆vx加速的安全速度vxaccsafe为:车辆vx减速时的安全速度vxdecsafe的获取方法为:当车辆vx减速时,设车辆vc为此时车辆vx的期望前导车辆,通过换道数据采集及换道需求判断模块得到车辆vc与车辆vx的距离为δxc,期望前导车辆vc的速度、加速度分别为vc、ac,车辆vx的速度、加速度分别为vx、ax;采集间隔为δt,最小反应时间tmin,则使vx减速后经过t=δt+tmin与vc碰撞的速度vmax1满足以下条件:同时,车辆vx需要避免与其滞后车辆vb发生碰撞,通过换道数据采集及换道需求判断模块采集到的车辆vx与车辆vb的相对距离为δxb,vb的速度、加速度分别为vb、ab,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx减速后经过t=δt+tmin与vb碰撞的速度vmax2满足:得到减速后的最大速度vmax、安全减速度asafe分别为:vmax=max{vmax1,vmax2}车辆vx减速的安全速度vxdecsafe为:驾驶风格得分计算模块:用于通过人工神经网络使用反向传播算法,将换道数据采集及换道需求判断模块得到的速度、加速度和相对距离作为输入值计算速度得分、加速度得分、安全时距得分,并将上述得分作为输入值输入神经网络的输出函数中输出驾驶风格得分:包括以下模块:速度得分计算模块:用于使用krauss模型的安全速度公式分别输出需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆的安全速度速度得分ev为:其中,visafe(t+δt)为待评分车辆i在t+δt时刻的安全速度,δt为观察时间,vi+1(t)为与待评分车辆i对应的前导车辆i+1在t时刻的速度,δxi(t)为待评分车辆i与前导车辆i+1在t时刻的相对位移,δvi(t)为待评分车辆i与前导车辆i+1在t时刻的相对速度差,t为预设反应时间,a为最大加速度,vmax为预设最高速度,vmin为预设最低速度。加速度得分计算模块:用于利用以下公式分别输出需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆加速度积分ia:加速度得分ea为:其中,ia为加速度积分,a为待评分车辆的加速度值,δt为自车辆决定换道到观察分析的时间差,|a|x为人类对加速度的主观感受函数,abrk为车辆最大制动加速度;安全时距得分计算模块:用于利用以下公式计算安全时距tsafe:安全时距得分es为:其中,tsafe为安全时距;δxsafe(vi)为使车辆vi完全停止的最小距离,l为车身长度,xbrk为制动距离,vi为当前车辆i的速度,tmin为预设最小反应时间;驾驶风格得分计算模块:将得到的速度得分、加速度得分和安全时距得分作为输入值输入到神经网络的输出函数中得到驾驶风格得分,其中,采用非线性s型的log-sigmoid函数:其中,为神经元激发函数:其中,n为列描述的个数,xi为车辆i的速度得分、加速度得分、安全时距得分,wji、bj分别为激活函数的权重和偏置,权重和偏置为由人工神经网络自学习调整得到,的值域为(0,1);用于计算整个神经网络的误差函数:其中,d为真实值;用于通过梯度下降法调整人工神经网络的权值:其中,η为学习速度;权重调整模块:包括以下部分:用于确定权重系数α、β:由α+β=1,权重即需换道车辆的前导车辆与滞后车辆驾驶风格得分在总分中的占比:其中,oa为前导车辆的驾驶风格得分,ob为滞后车辆的驾驶风格得分;换道决策模块:用于根据权重调整模块得到的调整后的权重重新计算博弈收益计算模块的博弈收益值,设p为当前车辆vc换道的概率,q1为滞后车辆vl加速的概率,q2为滞后车辆vl减速的概率,则车辆vc、vl的混合概率期望收益ec、el如下所示:ec(p,q1,q2)=p[p'13-p'23+q1(p'11+p'23-p'13-p'21)+q2(p'12+p'23-p'13-p'22)]+[p'23+q1(p'21-p'23)+q2(p'22-p'23)]el(p,q1,q2)=q'23+p(q'13-q'23)+q1[q'21-q'23+p(q'11+q'23-q'13-q'21)]+q2[q'22-q'23+p(q'12+q'23-q'13-q'22)]其中,p'ij,q'ij分别为使用权重调整模块调整后的权重获得的vc、vl的博弈收益值;通过对求解概率参数(p,q1,q2)的至少一个最优解(p*,q1*,q2*),使ec、el达到最大,即满足:车辆根据(p*,q1*,q2*)的值输出是否执行换道或放弃换道。所述周边限制要素包括障碍物、重型车辆、应急车辆。(1)本发明的换道方法基于非合作博弈理论在交通环境建立博弈换道模型,与传统只考虑车辆安全和通行效率的方法相比,同时考虑了换道场景中的理性和非理性因素,更加贴近真实场景。(2)本发明的换道方法在计算博弈收益值时,加入了前导车辆、滞后车辆的驾驶风格参数参与计算,与传统的方法相比更加重视驾驶环节中的人类因素,既考虑到车辆的共性,同时兼顾不同驾驶风格的个性,无人驾驶汽车具备一定类人行为能力,对混合行驶场景有更强的适应力。(3)本发明的换道方法对驾驶风格进行量化分析,用于调整不同车辆的影响权重,与传统的人类主观分析样本方法相比,结果更加精确。(4)本发明的换道方法使用了收益再调整方案,按照换道需求、换道可能性、换道决策三部分建模,符合人类思考过程,为进一步提高无人驾驶汽车的类人行为能力奠定了基础。(5)本发明的换道方法使用人工神经网络处理车辆获取的信息,相比传统无人驾驶汽车直接处理信息,算法实现了基本的数据加工,通过神经网络的自学习能力,计算精度会随样本数量的增多更加精确,符合人类在认知过程中积累经验促进认知的学习过程。附图说明图1是本发明换道场景示意图。图2是本发明的方法原理图。图3是本发明的方法流程图。图4是本发明的模块连接示意图。具体实施方式以下结合附图及具体实施例对本发明进行说明:如图2-3所示,一种基于人工神经网络的车辆协同换道方法,包括以下步骤:s1:换道数据采集及换道需求判断:a1、换道数据采集:通过安装在车辆上的数据采集模块(如图像采集模块、测速传感器等)采集车辆在行驶过程中的路况信息,其中,如图1所示,路况信息包括当前车辆(如图1中的v1)在当前车道的速度及加速度、相邻车道中与当前车辆对应的前导车辆v2的速度及加速度、相邻车道中与当前车辆对应的滞后车辆v3的速度及加速度和周边要素的运动速度,以及当前车辆v1与前导车辆v2、滞后车辆v3以及周边要素(如障碍物、重型车辆、应急车辆等,如图1中的b点)之间的相对距离;前导车辆v2是位于当前车辆前方的车辆;滞后车辆v3是位于当前车辆后方的车辆。a2、换道需求判断:根据换道需求判断条件,判断当前车辆是否有换道需求:若当前车辆同时不满足换道需求判断条件,则当前车辆不需要换道,即放弃换道;若当前车辆满足需求判断条件中的至少一条,则当前车辆需要换道;所述换道需求判断条件为:其中,δxi为当前车辆i与前导车辆或周边交通要素之间的相对距离,vie为当前车辆i的预设期望速度,vic为当前车辆i的速度,vi+1为与当前车辆i对应的前导车辆的速度,tsafe为预设安全时距,tmin为预设最小反应时间,vbar为周边限制要素的运动速度,i≥1;s2、博弈收益计算:建立与换道行为相对应的博弈换道模型:将步骤a2中需要换道的车辆的可能的行为策略作为行描述,将该车辆对应的滞后车辆可能的行为策略作为列描述,建立与换道行为相对应的博弈换道模型;并以博弈收益值数值对作为博弈换道模型的元素,每个博弈收益值数值对作为在对应行描述和列描述条件下的数值表示;提取博弈换道模型的元素构建成为博弈收益矩阵,博弈收益矩阵中的元素为(pij,qij),其中,pij、qij分别为在行描述i和列描述j的条件下,需要换道的车辆及与该车辆对应的滞后车辆的博弈收益值,且通过以下公式获得:pij(或qij)=α*a+β*b其中,α、β为权重系数,且满足α+β=1,α、β的初始值均为0.5;对于需要计算博弈收益的车辆vx,a、b分别由以下公式计算:其中,vx为车辆vx的速度,ax为车辆vx的加速度,δt为采集间隔时间,δxa为车辆vx与前导车辆的相对距离,δxb为车辆vx与滞后车辆的相对距离,vxaccsafe为车辆vx加速时的安全速度,vxdecsafe为车辆vx减速时的安全速度;所述车辆vx加速时的安全速度vxaccsafe的获取方法为:当车辆vx加速时,设车辆va为此时车辆vx的期望前导车辆,车辆va与车辆vx的距离为δx,通过数据采集模块得到期望前导车辆va的速度、加速度分别为va、aa,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx加速后经过t=δt+tmin与va碰撞的速度vmax满足以下条件:求出vmax后,得到车辆vx加速的安全速度vxaccsafe为:车辆vx减速时的安全速度vxdecsafe的获取方法为:当车辆vx减速时,设车辆vc为此时车辆vx的期望前导车辆,通过步骤s1得到车辆vc与车辆vx的距离为δxc,期望前导车辆vc的速度、加速度分别为vc、ac,车辆vx的速度、加速度分别为vx、ax;采集间隔为δt,最小反应时间tmin,则使vx减速后经过t=δt+tmin与vc碰撞的速度vmax1满足以下条件:同时,车辆vx需要避免与其滞后车辆vb发生碰撞,通过步骤s1采集到的车辆vx与车辆vb的相对距离为δxb,vb的速度、加速度分别为vb、ab,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx减速后经过t=δt+tmin与vb碰撞的速度vmax2满足:得到减速后的最大速度vmax、安全减速度asafe分别为:vmax=max{vmax1,vmax2}车辆vx减速的安全速度vxdecsafe为:s3、驾驶风格得分计算:通过人工神经网络使用反向传播算法,将步骤s1得到的速度、加速度和相对距离作为输入值计算速度得分、加速度得分、安全时距得分,并将上述得分作为输入值输入神经网络的输出函数中得到驾驶风格得分:b1、计算速度得分:使用krauss模型的安全速度公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆的安全速度速度得分ev为:其中,visafe(t+δt)为待评分车辆i在t+δt时刻的安全速度,δt为观察时间,vi+1(t)为与待评分车辆i对应的前导车辆i+1在t时刻的速度,δxi(t)为待评分车辆i与前导车辆i+1在t时刻的相对位移,δvi(t)为待评分车辆i与前导车辆i+1在t时刻的相对速度差,t为预设反应时间,a为最大加速度,vmax为预设最高速度,vmin为预设最低速度。b2、计算加速度得分:利用以下公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆加速度积分ia:加速度得分ea为:其中,ia为加速度积分,a为待评分车辆的加速度值,δt为自车辆决定换道到观察分析的时间差,|a|x为人类对加速度的主观感受函数,abrk为车辆最大制动加速度;b3、计算安全时距得分:利用以下公式计算安全时距tsafe:安全时距得分es为:其中,tsafe为安全时距;δxsafe(vi)为使车辆vi完全停止的最小距离,l为车身长度,xbrk为制动距离,vi为当前车辆i的速度,tmin为预设最小反应时间;b4、计算驾驶风格得分:将得到的速度得分、加速度得分和安全时距得分作为输入值输入到神经网络的输出函数中得到驾驶风格得分,其中,采用非线性s型的log-sigmoid函数:其中,为神经元激发函数:其中,n为列描述的个数,xi为车辆i的速度得分、加速度得分、安全时距得分,wji、bj分别为激活函数的权重和偏置,权重和偏置为由人工神经网络自学习调整得到,的值域为(0,1);整个神经网络的误差函数如下所示:其中,d为真实值;通过梯度下降法调整人工神经网络的权值:其中,η为学习速度;s4、权重调整:确定权重系数α、β:由α+β=1,权重即需换道车辆的前导车辆与滞后车辆驾驶风格得分在总分中的占比:其中,oa为前导车辆的驾驶风格得分,ob为滞后车辆的驾驶风格得分;s5、换道决策:根据步骤s4得到的调整后的权重重新计算步骤s2的博弈收益值,设p为当前车辆vc换道的概率,q1为滞后车辆vl加速的概率,q2为滞后车辆vl减速的概率,则车辆vc、vl的混合概率期望收益ec、el如下所示:ec(p,q1,q2)=p[p'13-p'23+q1(p'11+p'23-p'13-p'21)+q2(p'12+p'23-p'13-p'22)]+[p'23+q1(p'21-p'23)+q2(p'22-p'23)]el(p,q1,q2)=q'23+p(q'13-q'23)+q1[q'21-q'23+p(q'11+q'23-q'13-q'21)]+q2[q'22-q'23+p(q'12+q'23-q'13-q'22)]其中,p'ij,q'ij分别为使用步骤s4调整后的权重获得的vc、vl的博弈收益值;通过对求解概率参数(p,q1,q2)的至少一个最优解(p*,q1*,q2*),使ec、el达到最大,即满足:车辆根据(p*,q1*,q2*)的值决定是否执行换道或放弃换道。以下通过具体实施例实现上述换道方法:实施例1:以图1场景为例,具体步骤如下:s1:换道数据采集及换道需求判断:a1、换道数据采集:图1中车辆v1-v3在行驶过程中由换道数据采集模块收集路况信息,采集到车辆v1速度为10m/s,期望速度为13.9m/s,加速度为1.4m/s2,距离b点23m,距离前导车辆v216m,距离v34米,前导车辆v2速度为14.4m/s,加速度为0.6m/s2,滞后车辆v3速度为12.5m/s,加速度为0.9m/s2。;a2、换道需求判断:根据以下公式判断车辆是否具有换道需求:其中,δxi表示当前车辆v1与前导车辆v2或周边要素的相对距离,vie表示当前车辆v1的期望速度,vic表示当前车辆v1的实际速度,vi+1表示前导车辆v2的速度,tmin表示最小反应时间,取人类大脑作出反应时间约1.5s(下同),tsafe表示安全时距,此处取tmin的两倍3s(下同),vbar为周边限制要素的运动速度,图1中b点为周边限制要素,其运动速度为0。此时,根据上述公式判断,v1满足公式(1-1),即当前车辆v1具有换道需求。s2、博弈收益计算:建立与换道行为相对应的博弈换道模型:图1中,参与换道的车辆为并道行为中关系最为密切的需要换道的当前车辆v1与选定目标车道的滞后车辆v3,将步骤a2中需要换道的当前车辆v1的可能的行为策略作为行描述,将滞后车辆v3可能的行为策略作为列描述,建立与换道行为相对应的博弈换道模型,因该图1中只有两车道滞后车辆v3无法选择换道避让,因此滞后车辆v3只有两个行为策略,即v3加速和v3减速,得到的博弈换道模型如表1所示:表1博弈收益模型行为策略v3加速v3减速v1换道(p11,q11)(p12,q12)v1不换道(p21,q21)(p22,q22)提取出的博弈收益矩阵为:博弈收益矩阵中的元素为(pij,qij),其中,pij、qij分别为在行描述i和列描述j的条件下需要换道的当前车辆v1及滞后车辆v3的收益值,根据表1的博弈收益模型,p11,q11表示在v1换道,v3加速的情况下,需要换道的当前车辆v1及滞后车辆v3的收益值,收益值的计算方法如下:pij(或qij)=α*a+β*b(2-1)其中,α、β为权重系数,且满足α+β=1,α、β的初始值均为0.5。对于需要计算博弈收益的车辆vx,a、b分别由以下公式计算:其中,vx为vx的采集速度,ax为vx的采集加速度,δt为采集间隔时间,δxa为vx与前导车辆的相对距离,δxb为vx与滞后车辆的相对距离,vxaccsafe为vx选择加速的安全速度,vxdecsafe为vx选择减速的安全速度。vxaccsafe的计算方法:如果车辆vx加速,希望车辆va作为它的前导车辆,它们的距离为δx,va的速度、加速度分别为va、aa,vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则vx加速后经过(t=δt+tmin)正好与va碰撞的速度vmax满足:求出vmax后,可得车辆vx的安全加速度asafe为:车辆vx加速的安全速度vxaccsafe为:vxdecsafe的计算方法:如果车辆vx减速,希望换道车辆vc作为它的前导车辆,它们的距离为δxc,vc的速度、加速度分别为vc、ac,vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则vx减速后经过(t=δt+tmin)正好与vc碰撞的速度vmax1满足:如果车辆vx减速,还需要避免与其滞后车辆vb发生碰撞,它们的距离为δxb,vb的速度、加速度分别为vb、ab,vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则vx减速后经过(t=δt+tmin)正好与vb碰撞的速度vmax2满足:对于vx,上述两个条件均要满足,因此减速后的最大速度vmax、安全减速度asafe分别为:vmax=max{vmax1,vmax2}(2-8)车辆vx减速的安全速度vxdecsafe为:将步骤a1采集到当前车辆v1与前导车辆v2之间的相对距离、当前车辆v1与滞后车辆v3之间的相对距离、由当前车辆v1的速度、前导车辆v2的速度、滞后车辆v3的速度,可得出当前车辆v1与前导车辆v2的相对速度、当前车辆v1与滞后车辆v3的相对速度。如果v3加速,即希望v2作为它的前导车辆,v3最快在下次数据采集时(1s后)完成加速,且v3加速后需要至少预留最小反应时间(1.5s)作为安全时间避免与v2碰撞,经计算,v3加速后的最大安全速度为21.02m/s,加速度为7.62m/s。如果v3减速,即希望v1作为它的前导车辆,v3最快在下次数据采集时(1s后)完成减速,且v3减速后需要至少预留最小反应时间(1.5s)作为安全时间避免与v1碰撞,经计算,v3减速后的最大安全速度为13.18m/s,加速度为-0.22m/s。利用公式(1-3)中可提取出博弈收益矩阵:s3、驾驶风格得分计算:针对换道行为特点,驾驶风格得分计算:通过人工神经网络使用反向传播算法,将步骤s1得到的速度、加速度和相对距离作为输入值计算速度得分、加速度得分、安全时距得分,并将上述得分作为输入值输入神经网络的输出函数中得到驾驶风格得分:b1、计算速度得分:使用krauss模型的安全速度公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆的安全速度速度得分ev为:其中,visafe(t+δt)为待评分车辆i在t+δt时刻的安全速度,δt为观察时间,vi+1(t)为与待评分车辆i对应的前导车辆i+1在t时刻的速度,δxi(t)为待评分车辆i与前导车辆i+1在t时刻的相对位移,δvi(t)为待评分车辆i与前导车辆i+1在t时刻的相对速度差,t为预设反应时间,a为最大加速度,vmax为预设最高速度,vmin为预设最低速度。根据国家法规(gb12676),汽车的满载制动加速度要大于等于5m/s2(下同),vmax为法律规定的最高速度,取19.4m/s(70km/h),vmin为法律规定的最低速度。将步骤s1中采集到的车辆v1速度为10m/s,前导车辆v2速度为14.4m/s,滞后车辆v3速度为12.5m/s,输入到公式(3-1)(3-2)中得到v1、v2和v3的速度得分分别为:0.515、0.742和0.967。b2、计算加速度得分:利用以下公式分别计算需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆加速度积分ia:加速度得分ea为:其中,ia为加速度积分,a为待评分车辆的加速度值,δt为自车辆决定换道到观察分析的时间差,|a|x为人类对加速度的主观感受函数,abrk为车辆最大制动加速度;本实施例采用δt=1s后采集到v1、v2和v3的加速度分别为-1.5m/s2,0.7m/s2,1.1m/s2。得到v1、v2和v3的加速度得分分别为:0.01、0.01和0.04。b3、计算安全时距得分:根据车辆跟随模型(cfm)对于安全距离的定义可知,安全距离是车身长度、制动距离、车速与安全时距的乘积之和。因此利用以下公式计算安全时距tsafe:安全时距得分es为:其中,tsafe为安全时距;δxsafe(vi)为使车辆vi完全停止的最小距离,l为车身长度,xbrk为制动距离,vi为当前车辆i的速度,tmin为预设最小反应时间;得到v1、v2和v3的安全时距得分分别为:0.083、0.574和0.354b4、计算驾驶风格得分:基于反向传播算法设计人工神经网络模块计算输出值用于调整权重参数α、β。输出值即驾驶风格得分,分数越低表明驾驶风格越保守,反之,分数越高表明驾驶风格越激进。将得到的速度得分、加速度得分和安全时距得分作为输入值输入到神经网络的输出函数中得到驾驶风格得分,其中,采用非线性s型的log-sigmoid函数:其中,为神经元激发函数:其中,n为列描述的个数,xi为车辆i的速度得分、加速度得分、安全时距得分,wji、bj分别为激活函数的权重和偏置,权重和偏置为由人工神经网络自学习调整得到,的值域为(0,1)。整个神经网络的误差函数如下所示:其中,d为真实值;通过梯度下降法调整人工神经网络的权值:其中,η为学习速度;s4、权重调整:确定权重系数α、β:由α+β=1,权重即需换道车辆的前导车辆与滞后车辆驾驶风格得分在总分中的占比:其中,oa为前导车辆的驾驶风格得分,ob为滞后车辆的驾驶风格得分;若v1换道,v1调整后的α为0.416,β为0.584,v3调整后的α为1,β为0,因为v3跟驰车辆距离非常远,可忽略影响;若v1不换道,v1调整后的α为1,β为0,v3调整后的α为1,β为0,因为v1、v3跟驰车辆距离非常远,可忽略影响。s5、换道决策:根据步骤s4得到的调整后的权重重新计算步骤s2的博弈收益值,得到的新的博弈收益矩阵如下:设p为当前车辆vc换道的概率,q1为滞后车辆vl加速的概率,q2为滞后车辆vl减速的概率,则vc、vl的混合概率期望收益ec、el如下所示:ec(p,q1,q2)=p[p'13-p'23+q1(p'11+p'23-p'13-p'21)+q2(p'12+p'23-p'13-p'22)]+[p'23+q1(p'21-p'23)+q2(p'22-p'23)](4-3)el(p,q1,q2)=q'23+p(q'13-q'23)+q1[q'21-q'23+p(q'11+q'23-q'13-q'21)]+q2[q'22-q'23+p(q'12+q'23-q'13-q'22)](4-4)其中,p'ij,q'ij分别为使用步骤s4调整后的权重获得的vc、vl的博弈收益值;通过对求解概率参数(p,q1,q2)的至少一个最优解(p*,q1*,q2*),至此,将换道决策转换为寻找博弈均衡点的过程,即求解纳什均衡(p*,q1*,q2*),使ec、el达到最大,即满足:车辆根据(p*,q1*,q2*)的值决定是否执行换道或放弃换道。本实施例得到的最优混合概率解(p*,q1*,q2*)为(1,0,1),即v1应该选择换道避免与b点相撞,v3应该减速让行避免与v1碰撞。根据(p*,q1*,q2*)的值如表2所示:其中,p*为v1最优换道概率,q1*为v3最优加速概率,q2*为v3最优减速概率,计算值分别为(1,0,1),所以纳什均衡是v1换道,v3减速,即表2表2换道策略决策表纳什均衡v1换道v1不换道v3加速v3减速11001本发明根据上述换道方法提供了一种基于人工神经网络的车辆协同换道系统,具体如下:如图4所示,一种基于人工神经网络的车辆协同换道系统,包括以下模块:换道数据采集及换道需求判断模块:包括以下模块:换道数据采集模块:在车辆上安装数据采集模块用于采集并输出车辆在行驶过程中的路况信息,所述路况信息包括车辆在当前车道的速度及加速度、相邻车道中与当前车辆对应的前导车辆的速度及加速度、相邻车道中与当前车辆对应的滞后车辆的速度及加速度和周边限制要素的运动速度,以及当前车辆与所述前导车辆、滞后车辆以及周边限制要素之间的相对距离;所述前导车辆是位于当前车辆前方的车辆;所述滞后车辆是位于当前车辆后方的车辆;换道需求判断模块:用于根据换道需求判断条件,判断当前车辆是否有换道需求:若当前车辆同时不满足换道需求判断条件,则当前车辆不需要换道,即放弃换道;若当前车辆满足需求判断条件中的至少一条,则当前车辆需要换道;所述换道需求判断条件为:其中,δxi为当前车辆i与前导车辆或周边交通要素之间的相对距离,vie为当前车辆i的预设期望速度,vic为当前车辆i的速度,vi+1为与当前车辆i对应的前导车辆的速度,tsafe为预设安全时距,tmin为预设最小反应时间,vbar为周边限制要素的运动速度,i≥1;博弈收益计算模块:用于建立与换道行为相对应的博弈换道模型:将换道需求判断模块中需要换道的车辆的可能的行为策略作为行描述,将该车辆对应的滞后车辆可能的行为策略作为列描述,建立与换道行为相对应的博弈换道模型;并以博弈收益值数值对作为博弈换道模型的元素,每个博弈收益值数值对作为在对应行描述和列描述条件下的数值表示;提取博弈换道模型的元素构建成为博弈收益矩阵,博弈收益矩阵中的元素为(pij,qij),其中,pij、qij分别为在行描述i和列描述j的条件下,需要换道的车辆,及与该车辆对应的滞后车辆的博弈收益值,且通过以下公式获得:pij(或qij)=α*a+β*b其中,α、β为权重系数,且满足α+β=1,α、β的初始值均为0.5;对于需要计算博弈收益的车辆vx,a、b分别由以下公式计算:其中,vx为车辆vx的速度,ax为车辆vx的加速度,δt为采集间隔时间,δxa为车辆vx与前导车辆的相对距离,δxb为车辆vx与滞后车辆的相对距离,vxaccsafe为车辆vx加速时的安全速度,vxdecsafe为车辆vx减速时的安全速度;所述车辆vx加速时的安全速度vxaccsafe的获取方法为:当车辆vx加速时,设车辆va为此时车辆vx的期望前导车辆,车辆va与车辆vx的距离为δx,通过数据采集模块得到期望前导车辆va的速度、加速度分别为va、aa,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx加速后经过t=δt+tmin与va碰撞的速度vmax满足以下条件:求出vmax后,得到车辆vx加速的安全速度vxaccsafe为:车辆vx减速时的安全速度vxdecsafe的获取方法为:当车辆vx减速时,设车辆vc为此时车辆vx的期望前导车辆,通过换道数据采集及换道需求判断模块得到车辆vc与车辆vx的距离为δxc,期望前导车辆vc的速度、加速度分别为vc、ac,车辆vx的速度、加速度分别为vx、ax;采集间隔为δt,最小反应时间tmin,则使vx减速后经过t=δt+tmin与vc碰撞的速度vmax1满足以下条件:同时,车辆vx需要避免与其滞后车辆vb发生碰撞,通过换道数据采集及换道需求判断模块采集到的车辆vx与车辆vb的相对距离为δxb,vb的速度、加速度分别为vb、ab,车辆vx的速度、加速度分别为vx、ax,采集间隔为δt,最小反应时间tmin,则使车辆vx减速后经过t=δt+tmin与vb碰撞的速度vmax2满足:得到减速后的最大速度vmax、安全减速度asafe分别为:vmax=max{vmax1,vmax2}车辆vx减速的安全速度vxdecsafe为:驾驶风格得分计算模块:用于通过人工神经网络使用反向传播算法,将换道数据采集及换道需求判断模块得到的速度、加速度和相对距离作为输入值计算速度得分、加速度得分、安全时距得分,并将上述得分作为输入值输入神经网络的输出函数中输出驾驶风格得分:包括以下模块:速度得分计算模块:用于使用krauss模型的安全速度公式分别输出需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆的安全速度速度得分ev为:其中,visafe(t+δt)为待评分车辆i在t+δt时刻的安全速度,δt为观察时间,vi+1(t)为与待评分车辆i对应的前导车辆i+1在t时刻的速度,δxi(t)为待评分车辆i与前导车辆i+1在t时刻的相对位移,δvi(t)为待评分车辆i与前导车辆i+1在t时刻的相对速度差,t为预设反应时间,a为最大加速度,vmax为预设最高速度,vmin为预设最低速度。加速度得分计算模块:用于利用以下公式分别输出需要换道车辆及与需要换道车辆相对应的前导车辆和滞后车辆加速度积分ia:加速度得分ea为:其中,ia为加速度积分,a为待评分车辆的加速度值,δt为自车辆决定换道到观察分析的时间差,|a|x为人类对加速度的主观感受函数,abrk为车辆最大制动加速度;安全时距得分计算模块:用于利用以下公式计算安全时距tsafe:安全时距得分es为:其中,tsafe为安全时距;δxsafe(vi)为使车辆vi完全停止的最小距离,l为车身长度,xbrk为制动距离,vi为当前车辆i的速度,tmin为预设最小反应时间;驾驶风格得分计算模块:将得到的速度得分、加速度得分和安全时距得分作为输入值输入到神经网络的输出函数中得到驾驶风格得分,其中,采用非线性s型的log-sigmoid函数:其中,为神经元激发函数:其中,n为列描述的个数,xi为车辆i的速度得分、加速度得分、安全时距得分,wji、bj分别为激活函数的权重和偏置,权重和偏置为由人工神经网络自学习调整得到,的值域为(0,1);用于计算整个神经网络的误差函数:其中,d为真实值;用于通过梯度下降法调整人工神经网络的权值:其中,η为学习速度;权重调整模块:包括以下部分:用于确定权重系数α、β:由α+β=1,权重即需换道车辆的前导车辆与滞后车辆驾驶风格得分在总分中的占比:其中,oa为前导车辆的驾驶风格得分,ob为滞后车辆的驾驶风格得分;换道决策模块:用于根据权重调整模块得到的调整后的权重重新计算博弈收益计算模块的博弈收益值,设p为当前车辆vc换道的概率,q1为滞后车辆vl加速的概率,q2为滞后车辆vl减速的概率,则车辆vc、vl的混合概率期望收益ec、el如下所示:ec(p,q1,q2)=p[p'13-p'23+q1(p'11+p'23-p'13-p'21)+q2(p'12+p'23-p'13-p'22)]+[p'23+q1(p'21-p'23)+q2(p'22-p'23)]el(p,q1,q2)=q'23+p(q'13-q'23)+q1[q'21-q'23+p(q'11+q'23-q'13-q'21)]+q2[q'22-q'23+p(q'12+q'23-q'13-q'22)]其中,p'ij,q'ij分别为使用权重调整模块调整后的权重获得的vc、vl的博弈收益值;通过对求解概率参数(p,q1,q2)的至少一个最优解(p*,q1*,q2*),使ec、el达到最大,即满足:车辆根据(p*,q1*,q2*)的值输出是否执行换道或放弃换道以上内容是结合具体的优选技术方案对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属
技术领域:
的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1