基于红外光谱分析物质成分含量的方法与流程
本发明涉及红外光谱分析领域,具体而言,涉及一种基于红外光谱分析物质成分含量的方法。
背景技术:
通过红外光谱分析可获知物质成分含量。通过测量红外光谱,对其进行分析,从而获知物质成分含量,不仅可以定性分析,也可定量分析。但是在现有的红外光谱测量过程中,测量仪器或测量条件的改变,都将导致原有标定模型失效,重新建立模型将浪费大量的时间和成本,造成分析结果不准确,分析效率低下的情况。
技术实现要素:
本发明为了解决现有的重新建模效率低的问题,提出了一种基于红外光谱分析物质成分含量的方法,包括以下步骤:
S1,根据源域红外光谱数据和与所述源域红外光谱数据对应的源域物质成分含量建立第一回归模型,求取所述第一回归模型中的参数;
S2,获取目标域红外光谱数据,建立目标域红外光谱数据与源域红外光谱数据之间的转移模型,求取所述转移模型中的参数;
S3,根据所述目标域红外光谱数据、所述转移模型,利用所述第一回归模型获取与所述目标域红外光谱数据对应的目标域物质成分含量。
进一步地,所述第一回归模型为偏最小二乘回归模型,所述步骤S1包括,对所述源域红外光谱数据进行特征提取获取第一光谱特征,根据所述第一光谱特征和源域物质成分含量建立所述偏最小二乘回归模型,求出回归系数。
进一步地,所述目标域红外光谱数据包括目标域红外光谱标准数据和目标域红外光谱测试数据,所述步骤S2包括根据所述目标域红外光谱标准数据进行特征提取获取第二标准光谱特征;根据所述第一光谱特征和所述第二标准光谱特征建立所述转移模型,求出转移矩阵。
进一步地,所述步骤S3包括,根据所述目标域红外光谱测试数据获取第三光谱特征,将所述第三光谱特征和所述转移模型带入到所述最小偏二乘回归模型中获取所述目标域物质成分含量。
进一步地,所述对所述源域红外光谱数据进行特征提取获取第一光谱特征的步骤包括,对所述源域红外光谱数据和源域物质成分含量进行中心化处理,根据中心化处理后的源域红外光谱数据和源域物质成分含量建立最小二乘回归模型获取所述第一光谱特征。
进一步地,还获取包括目标域标准物质成分含量,所述根据所述目标域红外光谱标准数据进行特征提取获取第二标准光谱特征的步骤包括:对所述目标域红外光谱标准数据和所述目标域标准物质成分含量进行中心化处理,根据中心化处理后的目标域红外光谱标准数据和目标域标准物质成分含量建立偏最小二乘回归模型获取第二标准光谱特征。
进一步地,所述步骤S2获取第二标准光谱特征的同时,还获取了第二标准投影数据和第二标准载荷数据;所述步骤S3中根据所述目标域红外光谱测试数据获取第三光谱特征的步骤包括,利用所述目标域红外光谱标准数据的均值对所述目标域红外光谱测试数据进行中心化处理,利用中心化处理后的目标域红外光谱测试数据按照下式依次递推获取第三光谱特征:其中,i大于等于1且小于等于k,TT_test为第三光谱特征,k为第三光谱特征的个数,为第二标准投影数据的第i个分量,为中心化处理后的目标域红外光谱测试数据的第i个残差项,为第二标准载荷数据的第i个分量。
进一步地,通过求解下式的最优化问题,其中,B表示基于源域特征回归模型的系数,M表示目标域特征到源域特征的转移矩阵,WS和WT分别表示源域和目标域的投影矩阵;通过TS=XS*WS求解第一光谱特征,其中第一光谱特征为i大于等于1且小于等于k,k为第一光谱特征的个数;通过计算回归系数ΒT=[b1,b2,...,bk],y表示源域物质成分含量。
进一步地,通过下式求取第二标准光谱特征,TT=XT*WT,其中第二标准光谱特征为i大于等于1且小于等于k,k为第二光谱特征的个数。
进一步地,利用第二标准光谱特征和第一光谱特征通过下式获取转移矩阵Μ=[m1,m2,...,mk],i大于等于1且小于等于k,k为第二标准光谱特征的个数,其中从中选取。
通过上述实施例的技术方案,本发明的基于红外光谱分析物质成分含量的方法建立源域和目标域样本特征之间的转移关系,一方面可以去除冗余信息,获得更加准确简单的转移关系,进而可以获得较好的预测效果,另一方面对于高维小样本数据集可以很大程度上减少运算量。
附图说明
通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
图1为本发明实施例基于红外光谱分析物质成分含量的方法的流程示意图;
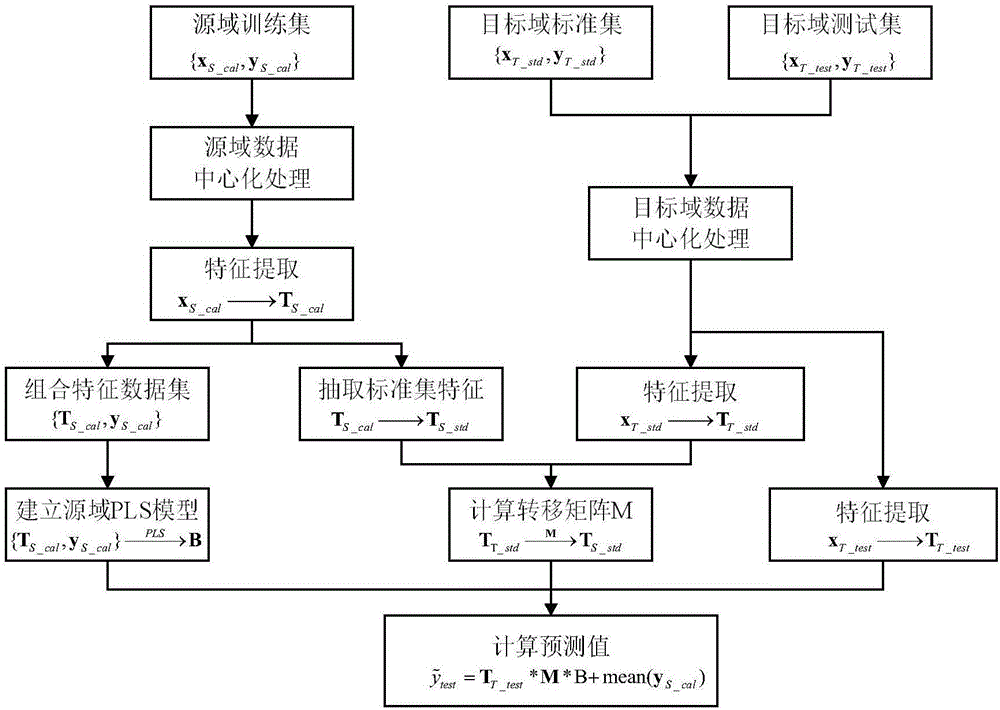
图2为本发明实施例基于红外光谱分析物质成分含量的方法的流程示意图;
图3为对本发明的分析方法进行验证的玉米数据集的主从光谱及偏差光谱;
图4为本发明的分析方法进行验证的药片数据集的主从光谱及偏差光谱;
图5为本发明的分析方法进行验证的玉米的PLS模型的主成分数选取过程;
图6为本发明的分析方法进行验证的玉米的PDS模型的窗口大小选择过程;
图7为本发明的分析方法进行验证的玉米中水份在各个模型下真实值与预测值的比较示意图;
图8为本发明的分析方法进行验证的玉米中油份在各个模型下真实值与预测值的比较示意图;
图9为对本发明的分析方法进行验证的玉米中蛋白质含量在各个模型下真实值与预测值的比较示意图;
图10为对本发明的分析方法进行验证的玉米中淀粉含量在各个模型下真实值与预测值的比较示意图;
图11为对本发明的分析方法进行验证的玉米中水份含量在标定迁移前后的预测值和真实值的比较示意图;
图12为对本发明的分析方法进行验证的玉米中油份含量在标定迁移前后的预测值和真实值的比较示意图;
图13为对本发明的分析方法进行验证的玉米中蛋白质含量在标定迁移前后的预测值和真实值的比较示意图;
图14为对本发明的分析方法进行验证的玉米中淀粉含量在标定迁移前后的预测值和真实值的比较示意图;
图15为对本发明的分析方法进行验证的玉米的PLS模型的主成分数选取过程示意图;
图16为对本发明的分析方法进行验证的玉米的PDS模型的窗口大小选择过程示意图;
图17为对本发明的分析方法进行验证的药片中第一种活性成分在不同模型下的预测值与真实值的比较示意图;
图18为对本发明的分析方法进行验证的药片中第二种活性成分在不同模型下的预测值与真实值的比较示意图;
图19为对本发明的分析方法进行验证的药片中第三种活性成分在不同模型下的预测值与真实值的比较示意图;
图20为对本发明的分析方法进行验证的药片中活性成分1含量在标定迁移前后的预测值和真实值的比较示意图;
图21为对本发明的分析方法进行验证的药片中活性成分2含量在标定迁移前后的预测值和真实值的比较示意图;
图22为对本发明的分析方法进行验证的药片中活性成分3含量在标定迁移前后的预测值和真实值的比较示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一
如图1所示,本发明提供了一种基于红外光谱分析物质成分含量的方法,包括以下步骤:
S101,根据源域红外光谱数据和与所述源域红外光谱数据对应的源域物质成分含量建立第一回归模型,求取所述第一回归模型中的参数;所述第一回归模型例如为偏最小二乘回归模型,对所述源域红外光谱数据进行特征提取获取第一光谱特征,根据所述第一光谱特征和源域物质成分含量建立所述偏最小二乘回归模型,求出回归系数;具体地,所述对所述源域红外光谱数据进行特征提取获取第一光谱特征的步骤包括,对所述源域红外光谱数据和源域物质成分含量进行中心化处理,根据中心化处理后的源域红外光谱数据和源域物质成分含量建立最小二乘回归模型获取所述第一光谱特征。中心化处理的操作为,用源域红外光谱数据减去源域红外光谱数据的均值,用源域物质成分含量减去源域物质成分含量的均值,减少偏差对建立模型的影响。
具体地,通过求解下式的最优化问题,其中,B表示基于源域特征回归模型的系数,M表示目标域特征到源域特征的转移矩阵,WS和WT分别表示源域和目标域的投影矩阵。通过TS=XS*WS求解第一光谱特征,其中第一光谱特征为i大于等于1且小于等于k,k为第一光谱特征的个数;通过计算回归系数ΒT=[b1,b2,...,bk],y表示源域物质成分含量。
S102,获取目标域红外光谱数据,建立目标域红外光谱数据与源域红外光谱数据之间的转移模型,求取所述转移模型中的参数;所述目标域红外光谱数据包括目标域红外光谱标准数据和目标域红外光谱测试数据,根据所述目标域红外光谱标准数据进行特征提取获取第二标准光谱特征;根据所述第一光谱特征和所述第二标准光谱特征建立所述转移模型,求出转移矩阵,为了提高准确性,可从所述第一光谱特征中选取部分光谱特征与所述第二标准光谱特征建立转移模型,选取时对应按照物质浓度相对应选取,如可采取,源域物质成分含量与目标域标准物质浓度相同的数据集来进行运算。
具体地,通过下式求取第二标准光谱特征,TT=XT*WT,其中第二标准光谱特征为i大于等于1且小于等于k,k为第二光谱特征的个数。
利用第二标准光谱特征和第一光谱特征通过下式获取转移矩阵Μ=[m1,m2,...,mk],i大于等于1且小于等于k,k为第二标准光谱特征的个数,其中从中选取。
S103,根据所述目标域红外光谱数据、所述转移模型,利用所述第一回归模型获取与所述目标域红外光谱数据对应的目标域物质成分含量;根据所述目标域红外光谱测试数据获取第三光谱特征,将所述第三光谱特征和所述转移模型带入到所述最小偏二乘回归模型中获取所述目标域物质成分含量。
本发明实施例还包括获取目标域标准物质成分含量,所述根据所述目标域红外光谱标准数据进行特征提取获取第二标准光谱特征的步骤包括:对所述目标域红外光谱标准数据和所述目标域标准物质成分含量进行中心化处理,根据中心化处理后的目标域红外光谱标准数据和目标域标准物质成分含量建立偏最小二乘回归模型获取第二标准光谱特征。中心化处理的步骤与上述对源于红外光谱数据的处理步骤类似。
本发明实施例中所述步骤S102获取第二标准光谱特征的同时,还获取了第二标准投影数据和第二标准载荷数据;所述步骤S103中根据所述目标域红外光谱测试数据获取第三光谱特征的步骤包括,利用所述目标域红外光谱标准数据的均值对所述目标域红外光谱测试数据进行中心化处理,利用中心化处理后的目标域红外光谱测试数据按照下式依次递推获取第三光谱特征:其中,i大于等于1且小于等于k,TT_test为第三光谱特征,k为第三光谱特征的个数,为第二标准投影数据的第i个分量,为中心化处理后的目标域红外光谱测试数据的第i个残差项,为第二标准载荷数据的第i个分量。
本发明的基于红外光谱分析物质成分含量的方法建立源域和目标域样本特征之间的转移关系,一方面可以去除冗余信息,获得更加准确简单的转移关系,因此可以获得较好的预测效果,另一方面对于高维小样本数据集可以很大程度上减少运算量。此外,仅有偏最小二乘算法(PLS算法)的潜变量一个参数需要设置,实现过程十分简单。需要说明的是,本发明中采用了“红外光谱”一词,可理解成包括了近红外光谱,也可包括中红外光谱、远红外光谱。
实施例二
本发明的基于红外光谱分析物质成分含量的方法结合迁移学习和PLS算法,形成了一种迁移标定算法(CT_pls算法),其基础思想来源于基于特征的迁移学习方法,将目标域特征映射至源域特征空间,进而可以利用源域的模型对目标域的数据进行处理。该方法首先利用PLS算法对源域样本和目标样本进行特征提取,然后建立基于源域特征的多元标定模型以及源域和目标域特征之间的线性转移模型,最后在以相同的方式对未知的目标域样本进行特征提取后转移后,利用源域标定模型对转移后的特征进行预测。
假设分别存在源域数据集{XS,y}和目标域数据集{XT,y},其中XS和XT分别由主光谱仪和从光谱仪测得,建立源域和目标域之间的标定迁移模型,实际上是求解公式(3.1)的最优化问题。
在公式(3.1)中,B表示基于源域特征回归模型的系数,M表示目标域特征到源域特征的转移矩阵,WS和WT分别表示源域和目标域的投影矩阵。本文选择偏最小二乘算法作为主体算法,WS和WT分别通过建立{XS,y}和{XS,y}的PLS模型求得,源域的特征TS和目标域的特征TT通过公式(3.2)求得。
在获得源域特征TS后,利用源域特征数据{TS,yS}建立多元标定模型,其中计算回归系数ΒT=[b1,b2,...,bk],k表示提取的主特征个数。
为了实现源域模型对目标域数据的有效预测,需要利用标准集进行光谱空间进行变换,公式(3.4)(3.5)表明光谱特征从目标域变换到源域的实现方法。
Τ'S←ΤTΜ (3.4)
其中,Τ'S和TT分别是源域和目标域样本集的特征,Τ'S从中获得TS,用于计算转移矩阵Μ=[m1,m2,...,mk]。
在建立源域的标定模型以及源域和目标域之间的转移模型后,即可实现对目标域样本的有效预测,如公式(3.6)所示。
yT=TT*M*B (3.6)
具体地,如图2所示,本发明的基于红外光谱分析物质成分含量的方法包括获取源域训练集,即获取源域红外光谱数据和源域物质成分含量;获取目标域标准集,即获取目标域红外光谱标准数据和目标域标准物质成分含量;获取目标域测试集,即获取目标域红外光谱测试数据和目标域测试物质成分含量;对源域数据进行中心化处理,对目标域数据进行中心化处理;对源域数据利用pls模型进行第一光谱特征提取,形成组合特征数据集,从中抽取与标准集对应的特征(即物质成分含量对应),利用组合特征数据集和pls算法建立第一回归模型,目标域标准集利用pls进行特征提取获取第二标准光谱特征,通过pls模型求取挑选后的第一光谱特征和第二标准光谱特征之间的转移矩阵,对目标域测试数据利用pls模型求取第三光谱特征,将第三光谱特征和转移矩阵带入到第一回归模型中,从而获取与目标域测试数据相对应的物质成分含量。具体实现过程,包括数据预处理、特征提取、建立源域标定模型、计算转移关系、对未知目标域数据进行预测等步骤。
具体地,可通过载有计算机程序的处理器电路来实现,计算机程序流程如下:
本发明实施例的基于红外光谱分析物质成分含量的方法采用了偏最小二乘回归分析,偏最小二乘回归分析(PLS)提供一种多对多线性回归建模的方法,特别当两组变量的很多,且都存在多重相关性,而观测数据的数量(样本量)有较少时,用偏最小二乘回归分析建立的模型具有传统的经典回归分析等方法所没有的优点。当同一物品的两组测量样本来自不同测量仪器或测量状态时,两组样本不相同却相关,所以可以将来自新空间的样本迁移至参考空间,进而可以直接利用参考空间的模型对新样本进行预测。重新利用了原有模型,减小了建模成本。
1.建立基于光谱特征的PLS回归模型
首先对红外光谱数据及其对应的成分浓度建立偏最小二乘回归模型,用于获取光谱特征,光谱特征的个数通过交叉验证方法进行选取。然后对光谱特征及其对应的成分浓度重新建立PLS模型,用于计算模型的回归系数,此时的主特征(光谱特征)个数依然通过交叉验证方法进行选择。对红外光谱数据两次建立PLS模型与一次直接建立PLS模型在预测精度上基本没有影响,使用光谱特征计算的回归系数可直接对转移后目标域的光谱特征进行预测。
2.实现光谱特征间的迁移学习
不同光谱仪测得红外光谱数据的条件概率或边缘概率分布可能不同,使得原有的多元标定模型无法对目标域的红外光谱数据进行准确的预测,往往会存在很大的预测偏差,由于重新建模成本很高,因此需要将目标域的光谱特征迁移至源域,进而缩小源域和目标域在分布上差异。首先对源域和目标域中的标准光谱样本进行特征提取,然后建立特征对特征的PLS模型,计算转移矩阵。使目标域特征与转移矩阵相乘,即可实现特征的迁移。
3.对目标域光谱数据进行预测
将目标域的特征迁移至源域的特征空间后,即可直接利用源域基于特征的回归模型,对目标域的特征进行预测。从而避免了对目标域样本重新建立模型,很大程度上减小了建模成本。
针对本发明中的分析方法分别对玉米和药片数据进行了分析,具体如下:
1.玉米数据集
玉米数据集有80个样本,对应着水分、油分、蛋白质、淀粉四种物质的含量,可以从(http://www.eigenvector.com/Data/Data_sets.html)获得。对于红外光谱数据集分别由m5,mp5,mp6三种不同的仪器在波长范围1100–2498nm以2nm为间隔测得,共700个频道。本实验中将m5测得的光谱作为主光谱,光谱数据作为源域数据集XS,由于mp6测得的光谱与m5测得的差异大些,被选为从光谱,对应的数据集作为目标域数据集XT。光谱图如图3所示,其中子图(A)、(B)、(C)分别表示主光谱图,从光谱图,以及主光谱与从光谱之间的光谱差异图。
实验中,利用Kennard-Stone(KS)算法对数据集进行划分,首先从源域和目标域数据集中分别抽取20%的数据作为测试样本,分别为16个,其中目标域的测试样本用于测试标定迁移模型。剩余的80%样本作为训练样本,分别为64个,其中源域的训练样本用于建立参考模型,可对目标域的迁移样本进行预测,目标域的用于建立目标域的标准模型,以便于对比其他迁移模型的性能。再从源域和目标域的训练样本中通过KS算法分别抽取若干样本作为标准样本集,用于建立源域样本和目标域样本之间的转移关系。标准样本的数量对转移关系影响较大,标准样本数量太少,无法获取充分的样本信息,数量太多,容易引入冗余信息,这两种情况都无法获得准确的转移关系。为了兼顾二者,本实验利用KS算法从源域和目标域的训练样本中分别抽取50%的样本作为标准样本集,分别为32个。
2.药片数据集
2002年,在国际漫反射会议(IDRC)上发布的”Shootout”数据集包含由两台光谱仪分别在波长范围600-1898nm以2nm间隔测得的药片样本的红外光谱数据,分别作为源域数据和目标域数据,均包含650个变量,用于分析药片中三种活性成分的含量。这些样本分别被划分为源域标定样本集和目标域标定样本集,各包含155个样本,源域测试集和目标域测试集,各包含460个样本。通过KS算法从源域和目标域的标定集中分别抽取50%的样本作为标准集,分别为78个。药片的红外光谱图在图4中给出,其中图4(A)表示主光谱,图4(B)表示从光谱,图4(C)表示主光谱与从光谱之间的光谱差异图。从图4(C)中中可以看出在波数和的范围,主光谱和从光谱存在着差异且在前端的差异存在着较大的波动,而在其他波数范围,存在的差异较小。说明在光谱的两端更容易引入噪声。由于主光谱和从光谱之间的差异并不大,因此可以猜想到,在模型迁移前后,预测的性能不会有太大的转变。
具体过程如下:
1.数据预处理方法
在训练模型前,选择中心化的方法对数据进行预处理,可以避免由于数值差异较大引起的偏差。
2.参数选择
模型的参数选择对模型性能可以产生很大的影响,选择一个最佳的参数,可以使得模型获得最优的性能。例如,对于PLS算法,选择最佳的主成分数,可以使模型获得最好的预测效果。本发明实验中,SBC(斜率和偏差校正方法),MSC(多元散射校正),PDS(分段直接标准),CT_pls均采用PLS算法建立主光谱数据的多元标定模型,因此在确定标准样本数量之后,SBC和CT_pls算法仅有主成分数一个参数需要被设置,PDS算法除主成分数之外还需要对窗口大小进行设置。本发明中,选择10折交叉验证的方法对PLS算法的主成分个数进行选择,设置主成分数从1到5,间隔为1,分别计算其对应的交叉验证误差(RMSECV),选取最小的RMSECV对应的主成分数为最佳主成分数。对于PDS算法,由于标准数据集样本数较少,在对各个窗口建立PLS子模型时,采用5折交叉验证,设置窗口大小从3到20,间隔为2,窗口大小应为不小于3的奇数,计算每个窗口大小对应的RMSECV,对应最小RMSECV的抽口为最佳窗口。模型评估
本发明实验中,以均方根误差(RMSE)作为参数选择及模型评估的指标。RMSE的计算方法如公式(3.11)。
其中,为预测值,为参考值(真实值或比较值),为测试样本数。
RMSEC表示标定集的训练误差,RMSEP表示测试集的预测误差,RMSECV表示交叉验证误差。对于PLS算法的交叉验证误差,表示真实值。对于PDS算法,选取窗口大小的交叉验证误差,表示主光谱标准集的预测值。
为了更加直观地比较本发明提出的CT_pls模型与其他经典模型以及PLS基准模型的在预测性能上的差异程度,使用公式(3.12)计算CT_pls算法相对其他算法性能的改善率或下降率。
在公式(3.12)中,RMSEPCT_pls表示CT_pls算法的预测误差,表示其他对比算法的预测的误差。
此外,本发明利用秩和检验方法来检验CT_pls方法与其他算法之间是否存在显著性差异,使用python中scipy包中的wilcoxon函数直接计算预测值之间的p值,若p>0.05,则说明两种算法之间不存在显著性差异,否则说明存在显著性差异。
本发明选用玉米数据集、药片数据集进行实验。对于SBC、PDS、CT_pls算法均采用PLS算法作为主体算法,使用源域数据建立多元标定模型作为参考模型,用于对迁移的目标域预测样本进行预测。同时,采用PLS算法,建立目标域训练样本的多元标定模型,用于对比标定迁移模型的预测性能,便于对SBC、PDS、CT_pls标定迁移方法做出更全面、准确的评估。实验结果主要包含以下几个部分:
(1)PLS算法的主成分数选取过程以及RMSEC、RMSEP、RMSECV的结果展示。
(2)PDS算法窗口大小的选择过程。
(3)在不同的标准样本数下,SBC、PDS、CT_pls三种迁移算法的RMSEP的变化情况。
(4)设置固定的标准样本数,SBC、PDS、CT_pls三种迁移算法预测能力的比较。
(5)标定迁移前后,模型预测能力的比较及参数设置。
采用玉米数据集进行实验。表3.1展示了直接使用玉米的目标域训练集建立对应水份、油分、蛋白质、淀粉含量的PLS模型的训练误差、交叉验证误差、预测误差以及主成分数。
表3.1玉米的目标域数据集PLS模型的误差及参数
从表3.1中可以看出,玉米中每种成分的RMSEC、RMSECV、RMSEP没有很大的差别,说明未出现过拟合现象,且RMSEP较小,说明也未出现欠拟合现象,进而可以说明主成分数选取的合理。本发明采用10折交叉验证方法对PLS算法的主成分进行选取,图5(A)(B)(C)(D)分别给出了关于玉米中水份、油份、蛋白质、淀粉含量的PLS模型的RMSECV随主成分数的变化过程,分别在主成分数为5,5,5,5时,取得RMSECV的最小值,因此关于玉米中各个组分含量的PLS模型的最佳主成分数分别为5,5,5,5。虽然设置最大主成分数为5,玉米数据集各个组分RMSECV未随着主成分数的变化而收敛,无法取得全局的最小值,但是如果主成分数选取过大会出现过拟合现象,且会增加PLS模型的复杂度,通过多次实验分析,选取最大主成分为5可以获得较为满意的效果。
对于PDS算法,需要对窗口大小进行合理选择,本发明通过5折交叉验证的方法对窗口大小进行选择,图6(A)(B)(C)(D)分别给出了关于玉米中水份、油份、蛋白质、淀粉含量的PDS模型的窗口大小选择过程,选取最小RMSECV对应的窗口大小为PDS模型的最佳窗口。从图6中对于水份含量的PDS模型,最佳窗口大小为13,而其他三种成分的PDS模型,最佳窗口大小为3。
对于SBC、PDS、CT_pls算法,其预测性能受标准样本数量影响。因为标准样本的数量影响着转移关系,转移关系又直接影响着预测精度,所以标准样本的数量影响着标定迁移模型的预测性能。表3.2-表3.5展示了在标准样本数不同的情况下,玉米中水分、油分、蛋白质、淀粉四种物质含量在不同模型下的预测误差,其中第一行的N表示标准样本数。此处的PLS模型表示直接使用目标域训练数据建立的基准模型,因此在对目标域测试样本进行预测时,不需要对样本进行迁移,所以预测误差与标准样本数无关。
表3.2玉米中水分含量的预测误差
从表3.2中可以看出,对于SBC算法,最小的预测误差为0.3081,与PLS方法的预测误差为0.1916,二者相差较大。由于SBC仅适用于系统化误差的情况下,说明对于水分的预测,SBC方法并不适合。对于PDS算法,最小的预测误差在N=45处获得,RMSECP=0.1767,对于CT_pls算法,最小的预测误差在N=13处获得,RMSEP=0.1678,二者的较小的预测误差均在N=32处取得,分别为0.1860,0.1831。由此可见,标准样本数过多或过少都不能获得最佳的转移关系。
从表3.3中可以看出,SBC方法在N=52时获得最小的预测误差0.0668,但在除N=26外的其他的标准样本数下的预测误差都与其接近,且都接近PLS的预测误差0.0624,说明SBC方法适合油分的预测。PDS算法的最小预测误差在N=52处取得,RMSEP=0.0787,CT_pls算法的最小预测误差在N=45处取得,RMSEP=0.0723,较小值都在N=32处取得,分别为0.0832和0.0740,且自N=32以后,PDS和CT_pls的RMSEP变化都不大。
表3.3玉米中油分含量的预测误差
表3.4玉米中蛋白质含量的预测误差
从表3.4可以看出,SBC方法在N=39处取得最小预测误差,RMSEP=0.2552,且在整个标准样本数变化的过程中,RMSEP的变化并不大。PDS算法,在N=45处取得最小值0.2296,且自N=32以后,RMSEP相对稳定。CT_pls算法在N=45处取得最小预测误差0.2093,且自N=26以后,RMSEP相对稳定。
表3.5玉米中淀粉含量的预测误差
从表3.5可以看出,SBC算法的最小预测误差在N=39处取得,RMSEP=0.5775,且RMSEP相对稳定。PDS算法在N=32处取得,RMSEP=0.4964,较小值在N=26和N=39处取得,分别为0.5101,0.5270。CT_pls算法在N=52处取得预测误差最小值0.4592,且在N=(26,32,39,45)处取得较小值。
通过对表3.2-表3.5进行分析,可以得出以下结论:第一,标准样本数的变化对SBC算法的预测能力并不大,且SBC算法的预测能力并不稳定。例如,对于油份的预测取得很好的效果,稍好于PDS和CT_pls算法,且接近PLS算法,但是对于水份的预测的效果却很差,远不及PDS和CT_pls算法,又与PLS的预测误差相差较大。第二,对于PDS和CT_pls算法的预测误差受标准样本数影响较大,大体上,在N<32时,预测误差较大,且随着样本数的增加,RMSEP会下降,在N=32处取得最小值或较小值,此后,随着样本数增加RMSEP变化不大或者下降,因此选择32个标准样本(即训练样本的50%)可以获得较好的迁移效果。第三,综合比较SBC、PDS、CT_pls算法的预测性能,CT_pls的预测性能最佳,其次是PDS算法,再次是SBC算法。
为了更加公平、直观地比较标定迁移算法的预测效果,本发明均选择32个标准样本建立源域和目标域之间的转移关系,图7-图10给出了对应于玉米中各种组分的各个算法预测值与真实值的比较图,预测值越接近真实值,相应的标注点则越接近y=x这条直线,因此可以根据每种算法对应的标注点在直线y=x附近的集中程度,来判断算法的预测性能,进而可以更加直观地观察它们的预测效果。
由于PDS、CT_pls模型的预测误差差别不大,通过图7-图10无法根据标注点的集中程度对比出两种算法优劣,因此在表3.6中展示了对应于图7-图10预测值的预测误差。同时表3.7-表3.10给出了CT_pls对PLS、SBC、PDS算法的预测误差改善率或下降率以及它们之间进行秩和检验的p值。
表3.6玉米数据集各个成分浓度在不同模型下的预测误差
表3.7玉米中水份含量CT_pls算法对其他算法的改善率和秩和检验的p值
表3.8玉米中油份含量CT_pls算法对其他算法的改善率和秩和检验的p值
表3.9玉米中蛋白质含量CT_pls算法对其他算法的改善率和秩和检验的p值
表3.10玉米中淀粉含量CT_pls算法对其他算法的改善率和秩和检验的p值
从表3.6-表3.10,进一步说明了SBC、PDS、CT_pls三种迁移算法中,CT_pls算法的预测性能最优,PDS算法次之,SBC算法最差。并且,由于表3.7-3.10中的p值均大于0.05,说明CT_pls算法与其他算法之间不存在显著性差异。
最后,利用直接利用源域模型对未进行转移目标域测试样本进行预测,并与使用CT_pls算法进行的预测进行比较,进而可以直观地对CT_pls模型的迁移能力进行评估。图11-图14给出了未进行标定迁移的模型的预测值和真实值的比较图和使用CT_pls算法进行标定迁移的预测值和真实值的比较图。
在图11-图14中,圆点表示未进行标定迁移时,目标域测试样本真实值与预测值之间的关系点,五角星表示使用CT_pls算法进行标定迁移后的目标域预测值和真实值之间的关系点。从图11-图14可以看出,深色的圆点都严重偏离直线y=x,而五角星都集中在直线y=x附近,说明直接使用源域模型对目标域数据进行预测会出现很大的偏差,这种偏差由不同的测量仪器引入,而在使用CT_pls算法进行标定迁移后,可以在很大程度上缩小源域数据和目标域数据之间的偏差,进而可以直接使用源域模型对转移后的目标与数据进行预测,并且获得和很好的预测效果。
采用药片数据集进行实验。表11展示了直接使用药片的目标域训练集建立对应三种活性成分含量的PLS模型的训练误差、交叉验证误差、预测误差以及主成分数。
表3.11药片的目标域数据集PLS模型的误差及参数
从表3.11中可以看出,药片中每种成分的RMSEC、RMSECV、RMSEP都在相同的数量级上,说明未出现过拟合现象,且RMSEP较小,说明也未出现欠拟合现象,进而可以说明主成分数选取的合理。本发明的实施例采用10折交叉验证方法对PLS算法的主成分进行选取,图15(A)(B)(C)分别给出了关于药片中三种活性成分含量的PLS模型的RMSECV随主成分数的变化过程,分别在主成分数为3,2,5时,取得RMSECV的最小值,因此关于药片中各个组分含量的PLS模型的最佳主成分数分别为3,2,5。
对于PDS算法,本发明的实施例通过5折交叉验证的方法对窗口大小进行选择,图16(A)(B)(C)分别给出了关于药片三种活性成分含量的PDS模型的窗口大小选择过程。从图16中可以看出,对应第一种活性成分的PDS模型,最佳窗口大小为19,而其两种活性成分的PDS模型,最佳窗口大小分别为3和13。
对于SBC、PDS、CT_pls算法,表12-表14展示了在标准样本数不同的情况下,药片中三种活性成分含量在不同模型下的预测误差,其中第一行的N表示标准样本数,PLS模型为目标域训练数据建立的模型。
表3.12药片中第一种活性成分含量的预测误差
表3.13药片中第二种活性成分含量的预测误差
表3.14药片中第三种活性成分含量的预测误差
从表3.12-表3.14中可以看出,在标准样本数的变化过程中,CT_pls算法可以预测误差基本上都稍低于PDS算法的预测误差,且SBC算法的预测误差往往高于PDS算法的预测误差。说明CT_pls算法的预测性能优于PDS算法,PDS算法的预测性能优于SBC算法,并且CT_pls和PDS算法的预测误差都接近PLS算法的预测误差,说明二者都有较好的标定迁移能力。此外SBC算法在对第二种活性成分的预测误差也接近PLS算法的预测误差,但对第一种活性成分的预测误差与PLS算法的相差较大,进一步说明了SBC算法应用的不广泛性。
图17、图18、图19分别展示了在N=78时(即训练集的50%的样本),对应于三种活性成分的PLS、SBC、PDS、CT_pls四种模型的真实值与预测值的比较图。
通过图17、图18、图19无法很明确地根据标注点的集中程度对比出两种算法优劣,因此在表3.14中展示了对应于图17、图18、图19预测值的预测误差。同时表3.16、表3.17、表3.18给出了CT_pls对PLS、SBC、PDS算法的预测误差改善率或下降率以及它们之间进行秩和检验的p值。
表3.15药片数据集各个活性成分含量在不同模型下的预测误差
表3.16药片中活性成分1含量的CT_pls模型对其他模型的改善率和秩和检验的p值
表3.17药片中活性成分2含量的CT_pls模型对其他模型的改善率和秩和检验的p值
表3.18药片中活性成分3含量的CT_pls模型对其他模型的改善率和秩和检验的p值
从表3.15-表3.17中可以看出,对于药片数据活性成分含量的预测,CT_pls算法的预测性能达到最佳,甚至优于直接使用目标域数据建立的PLS模型,PDS算法的预测性能十分接近PLS模型,SBC模型的预测性能最差。并且每组p值都小于0.05,说明CT_pls算法和其他算法之间存在着显著性差异。
图20、图21、图22给出了未进行标定迁移的模型的预测值和真实值的比较图和使用CT_pls算法进行标定迁移的预测值和真实值的比较图。
从图20、图21、图22中可以看出,五角星型的标注点比圆点型的标注点更加接近且集中于直线y=x附近,说明使用CT_pls算法进行标定迁移后,获得了更好的预测效果。然而,与玉米数据集相比,药片数据集的迁移效果并不明显,这是因为药片数据集的主光谱和从光谱差异并不太大,这一点从图4可以看出。
本发明的分析方法使用目标域训练样本建立PLS模型作为基准模型,用于对比SBC、PDS、CT_pls三种标定迁移模型的迁移能力。实验结果表明,PDS和CT_pls模型的预测误差都接近PLS的预测误差,说明二者都具有较好的迁移能力,并且CT_pls模型的预测误差小于PDS模型的预测误差。而SBC模型不是总能获得好的预测效果,说明其稳定性及预测能力远不及PDS和CT_pls模型。因此,综合来看,三种迁移模型中,CT_pls模型具有最佳的预测性能,PDS次之,SBC最差。
在本发明中,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。术语“多个”指两个或两个以上,除非另有明确的限定。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!