基于核空间自解释稀疏表示的分类器设计方法与流程
本发明隶属于模式识别技术领域,具体地说,涉及一种基于核空间自解释稀疏表示的分类器设计方法。
背景技术:
模式识别过程通常包含两个阶段,第一个阶段是特征提取,另一个是构造分类器和标签预测。分类器设计(ClassifierDesign)作为模式识别系统的一个重要环节,一直以来都是模式识别领域研究的核心问题之一。目前,主要的分类器设计方法有以下几种。1、支持向量机方法(英文:SupportVectorMachine)支持向量机方法是CorinnaCortes和Vapnik等于1995年首先提出来的,它旨在通过最大化类别间隔建立最优分类面。该类方法在解决小样本、非线性及高维模式识别中表现出许多特有的优势。然而,该类分类器只有少量的边界点(即支持向量)参与到分类面建立,如果边界点分布的位置不好,那么对于分类是十分不利的。2、基于稀疏表示的多类分类方法(英文:SparseRepresentationbasedClassifier)基于稀疏表示的多类分类方法是由J.Wright等人于2009年提出的,该分类方法首先将测试样本在所有训练集上进行稀疏编码,然后根据产生最小编码误差的类别决定分类结果。该分类方法在多类分类中取得了很大的成功,然而,该分类方法没有训练的过程,直接将每类训练样本构造相应子空间,并没有考虑该分类样本中每个个体对构造子空间的贡献,容易产生较大的拟合误差。3、基于协同表示的多类分类方法(英文:CollaborativeRepresentationbasedClassifier)基于协同表示的多类分类方法是由zhang等人于2011年提出,该分类方法首先将测试样本在所有训练集上进行协同表示,然后根据产生最小编码误差的类别决定分类结果。该分类方法在某些数据集上性能优于基于稀疏表示的多类分类方法。同样地,该分类方法没有训练的过程,直接将每类训练样本构造相应子空间,容易产生较大拟合误差,导致分类性能不高。4、基于词典学习的多类分类方法基于词典学习的多类分类方法是由Yang等人于2010年提出,该分类方法弥补了传统的基于稀疏表示的多类分类方法容易产生较大拟合误差导致分类准确率不高的问题,然而,该分类方法只能在欧式空间中进行,很难处理具有非线性结构的数据,使其使用范围大大受限。由上可知,现有的分类器设计方法均存在拟合误差比较大以及特征的非线性结构缺失而导致分类精确度不高的问题。
技术实现要素:
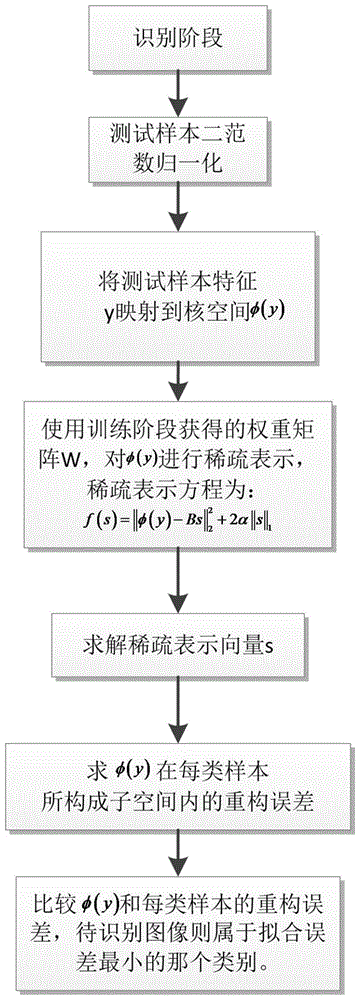
本发明针对现有分类器设计方法设计的分类器存在拟合误差大、精确度不高的上述不足,提供一种基于核空间自解释稀疏表示的分类器设计方法。一方面,本发明考虑了特征的非线性结构,能够更加精确的对特征进行稀疏编码,另一方面,本发明通过学习的方式训练词典,有效地降低拟合误差。从而大大提升分类器的性能。本发明的技术方案是:一种基于核空间自解释稀疏表示的分类器设计方法,含有以下步骤:步骤一:设计分类器,其步骤为:(一)读取训练样本,训练样本一共C类,定义X=[X1,X2,…,Xc,…,XC]∈RD×N表示训练样本,D是人脸特征维度,N是训练样本总的数目,X1,X2,…,Xc,…,XC分别表示第1,2,…,c,…,C类样本,定义N1,N2,…,Nc,…,NC分别表示每类训练样本数目,则N=N1+N2+…+Nc+…+NC;(二)对训练样本进行二范数归一化,得到归一化的训练样本;(三)依次取出训练样本中的每一类,并对该类样本训练词典,训练词典的过程为:(1)取出第c类样本Xc,将Xc映射到核空间φ(Xc);(2)根据φ(Xc)训练基于稀疏编码算法的词典Bc,Bc表示第c类样本学习到的词典,该词典的训练需要满足约束条件,所述约束条件的目标函数为:式中,α为稀疏编码算法中稀疏项约束的惩罚系数,Sc为第c类核空间训练样本的稀疏表示矩阵,K为学习得到的词典的大小,是一个权重矩阵,其每一列表示核空间样本对构造词典中每个词条的贡献大小,词典Bc=φ(Xc)Wc;(3)对步骤(2)中约束条件的目标函数进行求解,即对公式(1)求解,其求解过程为:固定Wc,更新Sc;随机产生矩阵Wc,将其带入约束条件的目标函数,这时该目标函数转化成为一个l1范数正则化最小二乘问题,即目标函数转化为:上述公式(2)可以简化为:κ(Xc,Xc)=<φ(Xc),φ(Xc)>为核函数。进一步把公式(3)分解成一系列子问题求解;针对Sc中的每一个元素进行求解,并剔除掉与求解无关的项,则公式(3)可以简化为:根据抛物线理论,很容易求出公式(4)的解;由于每个样本点是独立的,每次求解Sc的一行,其求解公式如下:式中,E=Wc^Tκ(Xc,Xc)Wc遍历Sc的每一列,完成Sc的一次更新;(4)固定步骤(3)中更新后的Sc,更新Wc,这时约束条件的目标函数转换为一个范数约束的最小二乘问题,即目标函数转化为:上述公式(6)采用拉格朗日乘子的方法求解,最终求得的解为:式中,F=ScScT,(5)交替迭代步骤(3)和步骤(4),最终得到最优稀疏编码词典Bc=φ(Xc)Wc;(6)按照步骤(1)至(5)获得每类样本的最优稀疏编码词典,将每类样本得到的最优稀疏编码词典放在一起,获得词典B=[B1,…,Bc,…,BC];步骤二:对样本进行分类,其步骤为:(1)读取待识别测试样本的图像特征,并对图像特征进行二范数归一化,定义y∈RD×1表示一幅待识别的测试样本图像特征;(2)将测试样本图像特征y映射到核空间φ(y);(3)使用步骤一中获得的词典B,对核空间φ(y)进行拟合,拟合函数为:式中s表示核空间中测试样本图像特征y的稀疏编码;(4)步骤(3)中的拟合函数进行求解,求解结果为:式中,s=[s1,…,sc,…,sC];(5)求核空间φ(y)在每类样本所构成子空间的拟合误差,用r(c)表示,其表达式为:(6)比较核空间φ(y)和每类样本的拟合误差,待识别图像则属于拟合误差最小的那个类别。本发明的有益效果是:本发明结合核技巧和词典学习方法,设计多类分类器,读取训练样本,将训练样本进行非线性变换,变换到高维的核空间,然后在高维核空间对每一类训练样本进行学习,找出该类训练样本中每个个体对于构造该类训练样本子空间所做的贡献(即权重),该类训练样本与权重矩阵的乘积构成词典,将所有类别的词典依次排列构成一个大的词典矩阵;对测试样本通过词典矩阵获得该测试样本在核空间的稀疏编码,即测试样本在词典矩阵的拟合系数,用每一类的词典及词典所对应的的稀疏编码拟合测试样本,并计算该拟合误差;最后,拟合误差最小的类即为测试样本的类别,实现了对每个输入测试样本进行分类。与现有技术相比,一方面,本发明考虑了特征的非线性结构,能够更加精确的对特征进行稀疏编码,另一方面,本发明通过学习的方式训练词典,有效地降低拟合误差。从而大大提升分类器的性能。附图说明图1为本发明具体实施例设计分类器的流程图。图2为本发明具体实施例对样本进行分类的流程图。具体实施方式下面结合一个仿真实例并结合附图对本发明作出进一步说明。一种基于核空间的分类集中稀疏表示的分类器设计方法,含有以下步骤:步骤一:设计分类器,其步骤为:(一)读取训练样本,训练样本一共C类,定义X=[X1,X2,…,Xc,…,XC]∈RD×N表示训练样本,D是人脸特征维度,N是训练样本总的数目,X1,X2,…,Xc,…,XC分别表示第1,2,…,c,…,C类样本,定义N1,N2,…,Nc,…,NC分别表示每类训练样本数目,则N=N1+N2+…+Nc+…+NC;(二)对训练样本进行二范数归一化,得到归一化的训练样本;(三)依次取出训练样本中的每一类,并对该类样本训练词典,训练词典的过程为:(1)取出第c类样本Xc,将Xc映射到核空间φ(Xc);(2)根据φ(Xc)训练基于稀疏编码算法的词典Bc,Bc表示第c类样本学习到的词典,该词典的训练需要满足约束条件,所述约束条件的目标函数为:式中,α为稀疏编码算法中稀疏项约束的惩罚系数,Sc为第c类核空间训练样本的稀疏表示矩阵,K为学习得到的词典的大小,是一个权重矩阵,其每一列表示核空间样本对构造词典中每个词条的贡献大小,词典Bc=φ(Xc)Wc;(3)对步骤(2)中约束条件的目标函数进行求解,即对公式(1)求解,其求解过程为:固定Wc,更新Sc;随机产生矩阵Wc,将其带入约束条件的目标函数,这时该目标函数转化成为一个范数正则化最小二乘问题,即目标函数转化为:上述公式(2)可以简化为:κ(Xc,Xc)=<φ(Xc),φ(Xc)>为核函数。进一步把公式(3)分解成一系列子问题求解;针对Sc中的每一个元素进行求解,并剔除掉与求解无关的项,则公式(3)可以简化为:根据抛物线理论,求出公式(4)的解;由于每个样本点是独立的,每次求解Sc的一行,其求解公式如下:式中,E=Wc^Tκ(Xc,Xc)Wc遍历Sc的每一列,完成Sc的一次更新;(4)固定步骤(3)中更新后的Sc,更新Wc,这时约束条件的目标函数转换为一个范数约束的最小二乘问题,即目标函数转化为:上述公式(6)采用拉格朗日乘子的方法求解,最终求得的解为:式中,F=ScScT,(5)交替迭代步骤(3)和步骤(4),最终得到最优稀疏编码词典Bc=φ(Xc)Wc;(6)按照步骤(1)至(5)获得每类样本的最优稀疏编码词典,将每类样本得到的最优稀疏编码词典放在一起,获得词典B=[B1,…,Bc,…,BC];步骤二:对样本进行分类,其步骤为:(1)读取待识别测试样本的图像特征,并对图像特征进行二范数归一化,定义y∈RD×1表示一幅待识别的测试样本图像特征;(2)将测试样本图像特征y映射到核空间φ(y);(3)使用步骤一中获得的词典B,对核空间φ(y)进行拟合,拟合函数为:式中s表示核空间中测试样本图像特征y的稀疏编码;(4)步骤(3)中的拟合函数进行求解,求解结果为:式中,s=[s1,…,sc,…,sC];(5)求核空间φ(y)在每类样本所构成子空间的拟合误差,用r(c)表示,其表达式为:(6)比较核空间φ(y)和每类样本的拟合误差,待识别图像则属于拟合误差最小的那个类别。通过本发明上述方法可以对每个输入测试样本进行分类,一方面本发明考虑了特征的非线性结构,能够更加精确的对特征进行稀疏编码,另一方面,本发明通过学习的方式训练词典,有效地降低拟合误差。从而大大提升分类器的性能。以上所举实施例仅用为方便举例说明本发明,并非对本发明保护范围的限制,在本发明所述技术方案范畴,所属技术领域的技术人员所作各种简单变形与修饰,均应包含在以上申请专利范围中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1