一种针对垃圾的视听触数据库建立方法
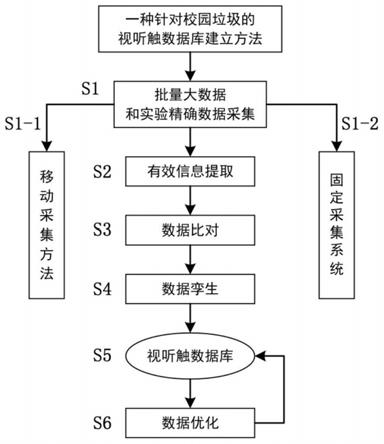
1.本发明涉及一种信息采集和数据库建立方法,尤其是针对垃圾的视听触数 据采集方法以及数据库的建立方法,属于垃圾的数据库建立领域。
背景技术:
[0002]“如何减少碳排放”成为各界人士十分关注的话题。而在目前阶段,对垃 圾源头进行有效的分类处理,是一种比较可行的节能减排手段。但在这个过程 中,涉及了两个难点。
[0003]
第一个难点是:目前的垃圾分类,主要集中在一线城市的居民生活中。而 针对垃圾的分类问题,目前鲜有强制的行政手段。基于此,国内外学者开始探 讨基于深度学习技术的垃圾源头分类问题。而深度学习技术需要建立在大数据 的基础上,目前国内外尚未有关于垃圾的大型数据库可供使用。更甚之,相关 学者往往也缺少批量采集垃圾数据的客观条件。这就使得该研究出现了瓶颈。
[0004]
第二个难点是:目前深度学习技术主要依靠的是图像数据。而图像数据往 往无法准确辨别“外形相同而材质不同”的垃圾,这就使得单纯依靠图像数据 的分类技术具有很大的局限性。
技术实现要素:
[0005]
为了解决以上问题,本发明的目的在于提供一种针对垃圾的多层次数据采 集方法和数据库建立方法,时对视觉(图片)、听觉(声音)、触觉(传感信 号)三种类型的数据进行采集和匹配,有效建立了垃圾的视听触数据库,为研 究和产业应用提供数据基础。
[0006]
为了解决上述问题,本发明的技术方案是包括:
[0007]
数据采集方法s1;
[0008]
有效信息提取方法s2;
[0009]
数据比对方法s3;
[0010]
数据孪生方法s4;
[0011]
数据库构建方法s5;
[0012]
数据优化方法s6。
[0013]
所述数据库中数据种类同时包含同一种垃圾的视觉数据、听觉数据、触觉 数据。特别的,视觉数据指的是图片;听觉数据指的是声音;触觉数据指的是 触觉类信号。
[0014]
所述的数据采集方法s1,包括批量大数据采集方法s1-1和实验精确数据采 集方法s1-2,通过批量大数据采集方法s1-1获得批量大数据,通过实验精确数 据采集方法s1-2获得实验精确数据,批量大数据的数据量大于实验精确数据的 数据量,且批量大数据仅有视觉数据,实验精确数据具有完整的视觉数据、听 觉数据、触觉数据。
[0015]
所述的有效信息提取方法s2,包括对数据采集方法s1获得数据中的图片数 据有效信息数值化并提取、对声音数据有效信息数值化并提取、对触觉数据有 效信息数值化并提取。
[0016]
所述的图片数据有效信息,包含但不局限于类别、名称、材质、形状、颜 色、尺寸等。
[0017]
所述的声音数据有效信息,包含但不局限于音调、音量、音色等。
[0018]
所述的触觉数据有效信息,包含但不局限于压力、形状、温度、硬度、粗 糙度、导热性、滑动感等。
[0019]
所述的数据比对方法s3,是仅对有效信息提取方法s2处理过的数据中的图 片数据有效信息的比对,比对结果分为不同垃圾、相同垃圾、相似垃圾三种情 况。
[0020]
相同垃圾是指垃圾的类别、材质、名称、形状、以及尺寸均相同;相似垃 圾是指垃圾的类别、材质、名称相同,但形状和尺寸不相同;不同垃圾为相同 垃圾、相似垃圾以外的情况。
[0021]
所述的数据孪生方法s4,包括精准孪生方法和近似孪生方法:
[0022]
根据所述数据比对方法s3的比对结果为相同垃圾时,采用精准孪生,处理 获得精准孪生数据;根据所述数据比对方法s3的比对结果为相似垃圾时,采用 近似孪生,处理获得近似孪生数据。
[0023]
所述的精准孪生方法为:
[0024]
将实验精确数据采集方法s1-2所采集的实验精确数据中的某个垃圾的声音 数据和触觉数据,复制于来自批量大数据采集方法s1-1所采集的批量大数据中 的仅垃圾图片有效信息相同的图片数据并结合,组成一组精准孪生数据组,进 而构成精准孪生数据。
[0025]
所述的近似孪生方法为:
[0026]
首先,将来自批量大数据采集方法s1-1所采集的批量大数据中的垃圾的图 片数据和来自实验精确数据采集方法s1-2所采集的批量大数据中的垃圾的图片 数据通过所述数据比对方法s3得到的比对结果为相似垃圾的所有垃圾分别各自 提取出来组建待匹配数据库,获得实验精确数据的待匹配数据库和的批量大数 据的待匹配数据库;
[0027]
然后,在各自待匹配数据库中按垃圾的尺寸信息进行排布,并分别计算各 自的均值和标准差,以两个待匹配数据库的标准差的比值作为扩充比,将数据 量较小的待匹配数据库按照扩充比进行数据复制扩充;扩充后,在各自待匹配 数据库中重新按垃圾的尺寸信息进行排布;
[0028]
接着,对照两个待匹配数据库中数据的排布位置,将相同排布位置的两个 图片数据进行配对;配对后,将其中来自实验精确数据采集方法s1-2所采集的 该图片数据对应垃圾的声音数据和触觉数据,复制于来自批量大数据采集方法 s1-1所采集的该图片数据对应垃圾的图片数据并结合,组成一组近似孪生数据 组,进而构成近似孪生数据。
[0029]
所述的数据库构建方法s5,包括两部分数据,第一部分数据是数据孪生方 法s4获得的精准孪生数据和近似孪生数据;第二部分数据是实验精确数据采集 方法s1-2所采集的实验精确数据。
[0030]
所述的数据优化方法s6,包括仅对所述的近似孪生数据进行逐步优化,优 化方法是:
[0031]
所述的近似孪生数据与所述实验精确数据采集方法s1-2新采集的实验精确 数据依次进行图片有效信息的循环比对,仅比对图片有效信息,若比对结果为 相同垃圾,则采用精准孪生的方法重组近似孪生数据,即将属于相同垃圾的实 验精确数据中的听觉数据、
触觉数据替换原先的近似孪生数据中的听觉数据、 触觉数据。
[0032]
本发明的有益效果是:
[0033]
本发明能有效建立针对垃圾有效准确的视听触数据库,有效解决科研领域 内垃圾识别研究面临的数据严重缺乏问题。
附图说明
[0034]
图1为整体方法流程图;
[0035]
图2为视听触总数据库搭建方法流程逻辑图;
[0036]
图3为数据优化方法流程逻辑图;
[0037]
图4为“相同垃圾”样例图;
[0038]
图5为“相似垃圾”样例图;
[0039]
图6为“相似垃圾”样例图。
具体实施方式
[0040]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实 施例进行详细说明。应该理解,此处所具体描述的发明例仅用以解释本发明, 并不限定于本发明。
[0041]
本发明实施例如图1至图3所示,具体如下:
[0042]
数据采集方法s1:
[0043]
如图1所示,数据采集方法s1,包括批量大数据采集方法s1-1和实验精确 数据采集方法s1-2,通过批量大数据采集方法s1-1获得批量大数据,通过实验 精确数据采集方法s1-2获得实验精确数据,批量大数据的数据量和实验精确数 据的数据量不一致,批量大数据的数据量大于实验精确数据的数据量,且批量 大数据仅有视觉数据,实验精确数据具有完整的视觉数据、听觉数据、触觉数 据。
[0044]
批量大数据采集方法s1-1具体实施是从已知图片数据库中提取,或者从网 络上爬虫获得。
[0045]
实验精确数据采集方法s1-2采用实验精确数据采集系统采集。
[0046]
有效信息提取方法s2:
[0047]
如图2所示,有效信息提取方法s2,包括对数据采集方法s1获得数据中的 图片数据有效信息数值化并提取、对声音数据有效信息数值化并提取、对触觉 数据有效信息数值化并提取。
[0048]
第一部分是所采集的批量大数据中的图片,将其命名为picture(i),其中 i为编号。提取picture(i)的有效信息,包括但不局限于类别、形状、颜色、材 质、名称、尺寸等。
[0049]
第二部分是实验精确数据,包括图片、声音、触觉数据等,分别将其命名 为photo(s)、voice(s)、touch(s),其中s为编号。图片photo(s)提取 的有效信息包括但不局限于类别、形状、颜色、材质、名称、尺寸等;声音voice (s)提取的有效信息包括但不局限于音调、音量、音色等;触觉数据touch(s) 提取的有效信息包含但不局限于压力、温度、粗糙度、滑动觉、导热性等。
[0050]
数据比对方法s3:
[0051]
如图2所示,数据比对方法s3,是仅对有效信息提取方法s2处理过的数据 中的图
片数据有效信息的比对,比对结果分为不同垃圾、相同垃圾、相似垃圾 三种情况。特别的,比对方法是:循环比对。特别的,比对次序依次是:类别
‑ꢀ
材质-名称-形状-尺寸。
[0052]
数据比对方法s3(图2)指的是进行图片有效信息的循环比对,特别的, 只比对图片有效信息。参与比对的图片分别批量大数据的图片picture(i)和实 验精确数据的图片数据photo(s),比对的形式为循环比对,比对的内容涉及 类别、材质、名称、形状、尺寸等。根据比对结果判断二者是属于相同垃圾还 是属于相似垃圾还是不同垃圾。
[0053]
如果类别、材质、名称存在任何一项信息不同,则更换下一张photo(s) 的照片再次进行比对;如果类别、材质、名称均相同,则进一步比对二者的形 状和尺寸是否相同,如果形状和尺寸仍然相同,则认定参与比对的两张照片 picture(i)和photo(s)所涉及的垃圾是相同垃圾;如果形状和尺寸存在任 何一项不同,则认定参与比对的两张照片picture(i)和photo(s)所涉及的 垃圾是相似垃圾。
[0054]
实施例如图4-图6所示。
[0055]
图4为相同垃圾的样例图,其中左图为可口可乐铝制易拉罐瓶,右图为可 口可乐铝制易拉罐瓶。
[0056]
(1)图4中左图来源于实验精确数据,与该图对应的声音数据和触觉数据 均来自于实验精确采集系统;而右图来源于批量大数据(手机采集),该数据 只有图片数据,并无听觉和触觉数据。
[0057]
(2)对图4中两张图片信息依次进行“类别、材质、名称、形状、尺寸
”ꢀ
判定对比,对比结果完全相同,认定这两个垃圾为“相同垃圾”。
[0058]
(3)将图4中左图所对应的听觉和触觉信息,复制给右图,进行精准孪生。
[0059]
同样的,图5为相似垃圾的样例图,其中左图为可口可乐铝制易拉罐瓶, 右图为可口可乐铝制易拉罐瓶(小号瓶)。
[0060]
(1)图5中左图来源于实验精确数据,与该图对应的声音数据和触觉数据 均来自于实验精确采集系统;而右图来源于批量大数据(手机采集),该数据 只有图片数据,并无听觉和触觉数据。
[0061]
(2)对图5中两张图片信息依次进行“类别、材质、名称、形状、尺寸
”ꢀ
判定对比,其中“类别、材质、名称”一致,“形状”和“尺寸”不同。因此, 认定这两个垃圾为“相似垃圾”。
[0062]
同样的,图6为相似垃圾的样例图,其中左图为可口可乐铝制易拉罐瓶, 右图为芬达铝制易拉罐瓶。
[0063]
(1)图6中左图来源于实验精确数据,与该图对应的声音数据和触觉数据 均来自于实验精确采集系统;而右图来源于批量大数据(手机采集),该数据 只有图片数据,并无听觉和触觉数据。
[0064]
数据孪生方法s4:
[0065]
如图2所示,数据孪生方法s4,包括精准孪生方法和近似孪生方法:
[0066]
根据数据比对方法s3的比对结果为相同垃圾时,采用精准孪生,处理获得 精准孪生数据;根据数据比对方法s3的比对结果为相似垃圾时,采用近似孪生, 处理获得近似孪生数据。
[0067]
精准孪生方法为:将实验精确数据采集方法s1-2所采集的实验精确数据中 的某个垃圾的声音数据和触觉数据,复制于来自批量大数据采集方法s1-1所采 集的批量大数
据中的仅垃圾图片有效信息相同的图片数据并结合,仅垃圾图片 有效信息相同是指比对结果为相同垃圾,组成一组精准孪生数据组,进而所有 垃圾构成精准孪生数据。
[0068]
近似孪生方法为:首先,将来自批量大数据采集方法s1-1所采集的批量大 数据中的垃圾的图片数据和来自实验精确数据采集方法s1-2所采集的批量大数 据中的垃圾的图片数据通过数据比对方法s3得到的比对结果为相似垃圾的所有 垃圾分别各自提取出来组建待匹配数据库,获得实验精确数据的待匹配数据库 和的批量大数据的待匹配数据库;
[0069]
然后,在各自待匹配数据库中按垃圾的尺寸信息进行排布,并分别计算各 自的均值和标准差,以两个待匹配数据库的标准差的比值作为扩充比,将数据 量较小的待匹配数据库按照扩充比进行数据复制扩充;扩充后,在各自待匹配 数据库中重新按垃圾的尺寸信息进行排布;
[0070]
接着,对照两个待匹配数据库中数据的排布位置,将相同排布位置的两个 图片数据进行配对;配对后,将其中来自实验精确数据采集方法s1-2所采集的 该图片数据对应垃圾的声音数据和触觉数据,复制于来自批量大数据采集方法 s1-1所采集的该图片数据对应垃圾的图片数据并结合,组成一组近似孪生数据 组,进而所有垃圾构成近似孪生数据。
[0071]
比对结果为不同垃圾情况,不作处理。
[0072]
具体实施中,若通过图片判定两者垃圾为相似垃圾,则将其中实验精确数 据拷贝至“photo(s)待匹配数据库”,同时,将批量大数据的图片数据拷贝至
ꢀ“
picture(i)待匹配数据库”。然后将两个待匹配数据库的图片数据按照垃圾 的尺寸信息排序,并将数据量较小的“photo(s)待匹配数据库”进行扩充,扩 充至两个待匹配数据库的数据量相同。扩充后,两个待匹配数据库中的图片数 据仍然按照垃圾的尺寸信息进行排序。排序后,将两个待匹配数据库中对应位 置的图片数据分别进行配对。配对后,将“photo(s)待匹配数据库”中的图片 数据所对应的听觉数据和触觉数据,按照次序,分别复制给“picture(i)待匹 配数据库”中相应位置的图片数据,组成多组新的视听触数据。这种孪生方法 定义为近似孪生。
[0073]
具体地,当认定照片picture(i)和photo(s)所涉及的垃圾是相同垃圾 时,将photo(s)对应的voice(s)和touch(s)复制,复制后的voice(s)、 touch(s)与picture(i),组成新的视听触数据组(精准孪生数据)。近似 孪生方法的实施方式为:当认定照片picture(i)和photo(s)所涉及的垃圾 是相似垃圾时,则将其中来自实验终端所采集的图片数据拷贝至“photo(s) 待匹配数据库”,同时,将其中来自学生群体所采集的图片数据拷贝至“picture (i)待匹配数据库”。然后从两个待匹配数据库中分别取一个尺寸中值作为正 态分布的中值,并分别按照正态分布进行排布,同时确定各自的均值μ和标准 差σ。两个待匹配数据库的标准差σ(i)与σ(s)的比值作为photo(s)待匹配 数据库的扩充比,将photo(s)待匹配数据库按扩充比扩增至两个待匹配数据 库的数据量相同。扩充后,两个待匹配数据库中的图片数据仍然按照垃圾的尺 寸信息进行排序。排序后按照两个数据库中各数据的正态分布位置,将对应位 置的picture(i)与photo(s)配对。配对后,将图片photo(s)所对应的声音 信息voice(s)
[0074]
和触觉信息touch(s)进行复制,复制后的voice(s)和touch(s)信息按照正 态分布公式
[0075]
进行数值优化,优化后匹配给picture(i),组成多组新的视听触数据组(近 似孪
生数据)。
[0076]
数据库构建方法s5:
[0077]
数据库构建方法s5的实施方式(图2)为:将“视听触孪生数据库”和实 验精确数据采集方法s1-2所采集的实验精确数据进行相加融合,构建“视听触 总数据库”。
[0078]
由此,本发明按照上述方法建立的垃圾数据能同时满足数据量大且高效准 确的要求,可用于数据的训练和处理。
[0079]
单纯依托于图片数据进行垃圾分类的研究方法,其准确率并不理想,并且 识别过程容易受制于外部环境(例如光线)的限制;而本发明采用视觉听觉触 觉多种类的数据进行融合分析,可以有效提高垃圾识别的准确率,同时提高识 别的稳定性。
[0080]
垃圾分类方法,需要丰富的数据支撑。其中较容易获得的数据是图片数据, 而声音数据和触觉数据则需要专业的设备提取。采用本发明所提供的方法,可 以有效解决数据的种类、数量、精度问题。能够带来稳定有效的数据库支撑, 实现垃圾分类的多模态稳定性和精确性,提高垃圾分类准确率,为相关研究提 供数据基础。
[0081]
如图2所示,数据库构建方法s5,总数据库中的数据有两部分来源,包括 两部数据,第一部分数据是数据孪生方法s4获得的精准孪生数据和近似孪生数 据,精准孪生数据和近似孪生数据共同组成的“视听触孪生数据库”;第二部 分数据是实验精确数据采集方法s1-2所采集的实验精确数据,即视听触实验数 据。
[0082]
数据优化方法s6:
[0083]
如图3所示,数据优化方法s6,包括仅对近似孪生数据进行逐步优化,能 够显著提升数据库的准确度,优化方法是:
[0084]
近似孪生数据与实验精确数据采集方法s1-2新采集的实验精确数据(新增 数据)依次进行图片有效信息的循环比对,仅比对图片有效信息,比对内容包 括类别、材质、名称、形状、尺寸;若比对结果为相同垃圾,则采用精准孪生 的方法重组近似孪生数据,即将属于相同垃圾的实验精确数据中的听觉数据、 触觉数据替换原先的近似孪生数据中的听觉数据、触觉数据。若对比结果显示 二者涉及的垃圾为相似垃圾,则该组数据不进行更新。
[0085]
这样,如果参与比对的有效信息相同则认定为相同垃圾,并进行二次精准 孪生,替换原先的近似孪生数据。继而优化数据库的准确度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1