一种基于网格搜索的规则权重分配siRNA设计方法与流程
本发明涉及生物信息学技术领域,具体的,涉及一种基于网格搜索的规则权重分配sirna设计方法。
背景技术:
rna干扰(rnainterference,rnai)是一种由短双链rna(smallinterferingrna,sirna)诱导的转录后基因沉默现象,具有特异性、选择性、高效性、作用迅速等特点,被广泛用于基因功能探索、基因表达调控机制等领域,加快了功能基因组学的研究,同时也推动了基因治疗等相关领域的研究。
sirna是由20~27个碱基对组成的双链rna,其效率受到靶基因mrna序列和自身序列等诸多因素影响,其中一个关键因素就是sirna序列设计,大量研究证明针对同一靶mrna设计的sirna作用效果差别很大。如何筛选高效沉默靶基因的sirna是一个难题,采用生物实验的方法进行一一验证,存在实验成本高、时间周期长、效率低下等问题,所以通过生物信息学与计算机辅助sirna设计、缩小高沉默效率sirna的筛选范围,可以有效降低rna干扰技术的研究和应用成本。
一般通过比较分析高效的sirna序列和低效率的sirna序列差异,总结出一些高沉默效率sirna的序列规则,对候选sirna序列按满足规则的情况进行打分,一般情况下,得分较高的认为会有较高的rna干扰效率。然而单纯基于现有规则的sirna设计一方面总结的经验有较强的偏好性,通常只适用于某些特定数据;另一个方面基于现有规则的方法把每条规则的权重看成是一样的,没有考虑按不同的权重来区别对待每条规则。
技术实现要素:
针对sirna设计中存在的问题,本发明充分考虑不同规则对sirna效率的不同影响,开发了一套sirna设计的生物信息学方法。根据本发明方案,提供了一种由计算机实现的基于网格搜索的规则权重赋值的sirna设计的生物信息学方法,具体方案为:
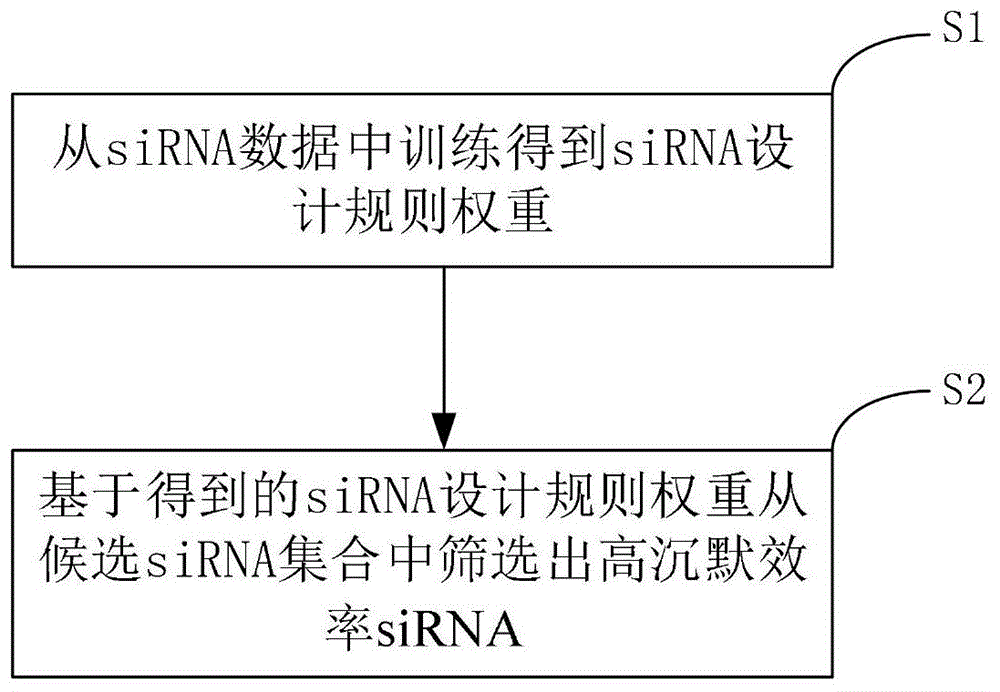
一种基于网格搜索的规则权重分配sirna设计方法,包括以下步骤:
s1、从sirna数据中训练得到sirna设计规则权重;
s2、基于得到的sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna。
进一步地,步骤s1包括以下子步骤:
s101、获取并处理sirna数据;
s102、获取sirna设计规则;
s103、对sirna设计规则设置sirna设计规则权重值;
s104、根据sirna设计规则权重值计算得到sirna设计规则得分矩阵;
s105、根据s101获取的sirna数据和s104获取的sirna设计规则得分矩阵,确定最佳sirna设计规则权重。
优选地,s101中所述sirna数据包括sirna序列和sirna的rna干扰效率值。
优选地,s101中所述获取并处理sirna数据,包括对所述sirna的rna干扰效率值进行处理,将所有的sirna的rna干扰效率值均一化,其中效率为0代表不能进行rna干扰,效率为100表示完全rna干扰,通过实验不能检测到相应的mrna或者蛋白。
优选地,s101中所述获取并处理sirna数据,包括将所述sirna数据随机地将数据分为两部分,其中占总数据比例2/3部分作为训练集数据,占总数据比例1/3部分作为测试集数据。
sirna由双链rna序列构成,其中与mrna互补链为guide链,也称为antisense链,另一条链为passenger链,也称为sense链,基于此,
优选地,s102中所述sirna设计规则包括以下规则中的一种或二种以上:
规则1:由于基因5’utr区域存在丰富的调控蛋白结合位点,可能影响rna诱导沉默复合体(rna-inducedsilencingcomplex,risc)和靶序列的结合,因此sirna靶序列需在基因cds转录起始位点下游100bp以后;
规则2:过低gc含量影响sirna结合mrna效率,过高则使双链结构不容易在risc中解旋形成具有识别能力的单链结构。因此sirna靶序列gc含量应在35%到55%之间。
规则3:sirna序列中不存在“发卡结构”序列,发卡结构(hairpinstructure)是指由于核苷酸单链分子通过自身回折使得互补的碱基对相遇,形成氢键结合而成的结构。
规则4:避免sirna靶序列中有重复的单碱基重复序列以及c/g碱基重复、t/g碱基重复;
规则5:sirnaantisense链5’端第2至8位序列为种子(seedregion),主要依靠此区域与靶基因结合,sirna种子区域的退火温度小于25℃;
规则6:sirnaantisense链5’端含有较多的a/u碱基,具体的,antisense链5’端前5个碱基有至少3个a/u碱基,前7个碱基有至少4个a/u碱基;
规则7:sirnaantisense链中存在“energyvalley”,具体的,antisense链5’端第9到第14位序列g/c碱基个数小于前8位序列g/c碱基个数,且前8位序列g/c碱基个数小于第15位至末尾序列g/c碱基个数。
规则8:sirna第10位u碱基和沉默效率高度相关,因此sirnasense链第10位为u碱基;
规则9:sirnasense链第一位为g/c碱基,第10位为a/u碱基,第13到19位有3个以上a/u碱基,第19位为a/u碱基。
优选地,s103中所述设置sirna设计规则权重值包括:给每一个设计规则设置合理的权重取值范围,然后将每个规则的权重遍历组合,最终得到每个规则的权重值。
优选地,所述合理的权重取值范围为每一个规则设置初始权重范围0、0.5、1.5、2、2.5、3,然后利用python工具包itertools形成所有的组合。
优选地,s104中计算得到sirna设计规则得分矩阵的步骤包括:根据sirna设计规则权重值,计算所有sirna设计规则在所有不同规则权重组合下的得分,遍历权重组合集与sirna数据,即得到sirna设计规则得分矩阵。
优选地,所述计算sirna设计规则得分的模型为:
其中,score表示sirna设计规则得分,i表示第i个规则,n为不小于1的正整数,表示对应的规则个数;w为sirna设计规则权重值,r表示sirna设计规则满足情况,若满足则取值为1,否则取值为0。
优选地,s105确定最佳sirna设计规则权重步骤包括:计算训练集数据每一个sirna设计规则权重组合的tpr、fpr值,筛选出tpr、fpr值均大于0.9的组合,然后计算这些组合的tpr、fpr值二者之和,筛选出所得二者之和最大的组合为最佳sirna设计规则权重,并在测试集数据中进行验证,以避免数据过拟合。
进一步地,步骤s2包括以下子步骤:
s201、根据目标靶基因外显子区域核苷酸序列,获取候选sirna集合;
s202、根据sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna。
优选地,s201所述获取候选sirna集合包括:对目标靶基因外显子区域进行设定长度的核苷酸子序列的搜索,并根据基因互补规则,得出相应的sirna双链序列,作为候选sirna集合中的候选sirna。
所述候选sirna的序列长度优选为21。
优选地,s202包括:根据sirna设计规则权重对候选sirna集合中的候选sirna进行评分,按得分从高到低排序,筛选得分高者为高沉默效率sirna。
优选地,所述得分高者筛选比例为选取得分在前5%的sirna作为高沉默效率sirna。
用于实现上述方法的系统包括:训练模块和筛选模块,
训练模块用于从sirna数据中训练得到sirna设计规则权重;
筛选模块用于基于得到的sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna。
以上方法通过以下系统实现:基于网格搜索的规则权重分配sirna设计系统,包括数据获取、处理及存储模块,权重设置模块,矩阵获取模块,最佳sirna设计规则权重筛选模块,候选sirna集合获取模块,高沉默效率sirna筛选模块;
数据获取、处理及存储模块用于获取并处理sirna数据、获取sirna设计规则,并存储基于网格搜索的规则权重分配sirna设计过程中产生的全部数据;权重设置模块用于对sirna设计规则设置sirna设计规则权重值,矩阵获取模块用于根据sirna设计规则权重值计算得到sirna设计规则得分矩阵,最佳sirna设计规则权重筛选模块用于根据s101获取的sirna数据和s104获取的sirna设计规则得分矩阵,确定最佳sirna设计规则权重;
候选sirna集合获取模块用于根据目标靶基因外显子区域核苷酸序列,获取候选sirna集合,高沉默效率sirna筛选模块用于根据sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna。
有益效果
网格搜索法是指定参数值的一种穷举搜索方法,将各个参数可能的取值进行排列组合,列出所有可能的组合结果生成“网格”。然后将各组合用于训练,并使用验证数据对表现进行评估。在拟合函数尝试了所有的参数组合后,返回一个合适的分类器,自动调整至最佳参数组合。因此,通过网格搜索确定sirna设计规则权重值,可以有效筛选rna干扰效率高的sirna。
本发明的有益效果在于:
1、本发明按照不同权重来区别对待每条规则,基于不同权重的多规则设计,可以避免将所有规则按同等重要程度对待,突出其中的重要规则,可以区分出有效的sirna和无效的sirna,并且能定量预测候选sirna序列的效率。
2、本发明收集的大量的sirna数据用于模型训练,并针对不同实验条件训练不同模型(如rt-pct、luciferase),可以避免由于所采用的样本集不同,或者样本量不够大等因素使得经验规则中带有碱基偏好性。
附图说明
图1为本发明实施例中一种网格搜索的规则权重分配sirna设计方法的流程示意图;
图2为本发明实施例中s1子步骤流程示意图;
图3为本发明实施例中s2子步骤流程示意图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
本发明的一个实施例:一种基于网格搜索的规则权重分配sirna设计方法,包括以下步骤:
s1、从sirna数据中训练得到sirna设计规则权重;
s2、基于得到的sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna。
本实施方式的基于网格搜索的规则权重分配sirna设计方法,主要分为两步,第一步为从大规模sirna数据中训练得到sirna设计规则权重;第二步为基于规则权重设计高沉默效率sirna。图2为s1子步骤的流程图,图3为s2子步骤的流程图;采用大规模sirna数据进行sirna设计规则权重分配,按不同的权重来区别对待每条规则,突出其中的重要规则,可以有效保证筛选到的sirna的rna干扰效率。
本发明的另一个实施例中,步骤s1具体包括:
步骤s101:获取并处理sirna数据
具体地,获取大规模sirna数据需要包括sirna序列,还需要包括sirna的rna干扰效率值,并将所有的rna干扰效率值均一化,其中效率为0代表不能进行rna干扰,效率为100表示完全rna干扰,通过实验不能检测到相应的mrna或者蛋白。然后随机地将数据分为两部分,其中训练集数据占2/3,测试集数据占1/3。
步骤s102:获取sirna设计规则
sirna由双链rna序列构成,其中与mrna互补链为guide链,也称为antisense链,另一条链为passenger链,也称为sense链;优选地,可以包括如下规则:
规则1:由于基因5’utr区域存在丰富的调控蛋白结合位点,可能影响rna诱导沉默复合体(rna-inducedsilencingcomplex,risc)和靶序列的结合,因此sirna靶序列需在基因cds转录起始位点下游100bp以后;
规则2:过低gc含量影响sirna结合mrna效率,过高则使双链结构不容易在risc中解旋形成具有识别能力的单链结构。因此sirna靶序列gc含量应在35%到55%之间。
规则3:sirna序列中不存在“发卡结构”序列,发卡结构(hairpinstructure)是指由于核苷酸单链分子通过自身回折使得互补的碱基对相遇,形成氢键结合而成的结构。
规则4:避免sirna靶序列中有重复的单碱基重复序列以及c/g碱基重复、t/g碱基重复;
规则5:sirnaantisense链5’端第2至8位序列为种子(seedregion),主要依靠此区域与靶基因结合,sirna种子区域的退火温度小于25℃;
规则6:sirnaantisense链5’端含有较多的a/u碱基,具体的,antisense链5’端前5个碱基有至少3个a/u碱基,前7个碱基有至少4个a/u碱基;
规则7:sirnaantisense链中存在“energyvalley”,具体的,antisense链5’端第9到第14位序列g/c碱基个数小于前8位序列g/c碱基个数,且前8位序列g/c碱基个数小于第15位至末尾序列g/c碱基个数。
规则8:sirna第10位u碱基和沉默效率高度相关,因此sirnasense链第10位为u碱基;
规则9:sirnasense链第一位为g/c碱基,第10位为a/u碱基,第13到19位有3个以上a/u碱基,第19位为a/u碱基;
步骤s103:对sirna设计规则设置sirna设计规则权重值
具体地,给每一个设计规则设置合理的权重取值范围,然后将每个规则的权重遍历组合。具体地,给每一个规则设置初始权重范围0、0.5、1.5、2、2.5、3,然后利用python工具包itertools形成所有的组合。
步骤s104:根据sirna设计规则权重值计算得到sirna设计规则得分矩阵
计算sirna设计规则得分的模型为:
其中,score表示sirna设计规则得分,i表示第i个规则,n为不小于1的正整数,表示对应的规则个数;w为sirna设计规则权重值,r表示sirna设计规则满足情况,若满足则取值为1,否则取值为0。
具体地,计算所有sirna在不同所有规则权重组合下的得分,遍历权重组合集与sirna数据,即得到sirna得分矩阵。
步骤s105:根据s101获取的sirna数据和s104获取的sirna设计规则得分矩阵,确定最佳sirna设计规则权重
具体的,计算训练集数据每一个规则权重组合的tpr、fpr值,然后选取tpr、fpr均大于0.9的组合,然后从选择二者之和最大的组合为最佳得分权重,同时在测试集数据中进行验证。
本实施例的有益效果为:筛选sirna设计规则有利于获取最佳的sirna序列;采用测试集数据对结果进行验证,能够避免数据过拟合;按照不同权重来区别对待每条规则,基于不同权重的多规则设计,可以避免将所有规则按同等重要程度对待,突出其中的重要规则,可以区分出有效的sirna和无效的sirna,并且能定量预测候选sirna序列的效率;收集的大量的sirna数据用于模型训练,并针对不同实验条件训练不同模型(如rt-pct、luciferase),可以避免由于所采用的样本集不同,或者样本量不够大等因素使得经验规则中带有碱基偏好性
在本发明的另一个实施例中,步骤s2包括以下子步骤:
步骤s201:根据目标靶基因外显子区域核苷酸序列,获取候选sirna集合
具体地,对目标靶基因外显子区域进行设定长度的核苷酸子序列的搜索,并根据基因互补规则,得出相应的sirna双链序列。
优选的,程序默认设计的候选sirna序列长度为21。
步骤s202:根据sirna设计规则权重从候选sirna集合中筛选出高沉默效率sirna
具体地,根据得到的规则权重值对候选sirna进行评分,然后按得分从高到低挑选高沉默效率sirna。
优选的,程序默认挑选得分在前5%的sirna。
本实施例的有益效果为:能够筛选得到最高什么效率的sirna。
本发明所用软件具体提参数如下:
使用自主开发的程序对数据集进行划分,其示例命令为:
1.python3data.split.py-isirna.csv--trainsirna.train.csv--testsirna.test.csv
其中-i是已整理的sirna数据集,--train后为生成的训练数据集,--test后为生成的测试数据集;
使用自主开发的程序生成所有可能的权重集,其示例命令为:
2.python3generate_scoring_set.py-irules.csv-oset.csv
其中-i是规则权重取值范围列表,-o后为形成的所有组合,第一列为组合编号,后面为每个规则对应的权重值。
使用自主开发的程序对sirna进行打分,其示例命令为:
3.python3scoring_results.py-isirna.csv-rrule_set.csv-oout.csv
其中-i后为训练集sirna数据,-r后为权重集,-o为打分结果文件;
使用自主开发的程序设计sirna,其示例命令为:
4.python3design.py-igene.csv-oout.csv
其中,-i为靶基因列表,-o为候选sirna文件;
使用自主开发的程序筛选高沉默效率sirna,其示例命令为:
5.python3pick.py-icandidate.sirna.csv-rrule.csv-oout.csv
其中-i为候选sirna序列文件,-r为筛选规则权重,-o为结果文件;
以上对本发明优选的具体实施方式和实施例作了详细说明,但是本发明并不限于上述实施方式和实施例,在本领域技术人员所具备的知识范围内,还可以在不脱离本发明构思的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!