检测测序数据中的交叉污染的制作方法
1.本技术总体涉及检测样本中的污染,并且更具体地,涉及检测样本中的污染,包括用于癌症早期检测的靶向测序。2.对相关技术的描述基于下一代测序的循环肿瘤dna化验必须达到高灵敏度和特异度,以便及早检测癌症。早期癌症检测和液体活检两者都需要高灵敏度的方法来检测低肿瘤负担,以及特定的方法来减少假阳性识别。来自邻近样本的污染dna可能会损害特异度,其可能导致假阳性识别。在各种情况下,特异度受损可能是因为来自污染物的罕见snp可能看起来像是低水平的突变。目前存在用于检测和评估全基因组测序数据中污染的方法,通常来自相对较低深度的测序研究。然而,现有方法不被设计用于检测来自癌症检测样本的测序数据中的污染,这通常需要高深度测序研究,并且包括可能以不同频率存在的(例如,克隆性和/或亚克隆性肿瘤衍生突变)肿瘤衍生突变(例如,单碱基突变和/或副本数变异(cnv))。需要在用于癌症检测的测试样本的测序数据中检测交叉样本污染的新方法。
背景技术:
技术实现思路
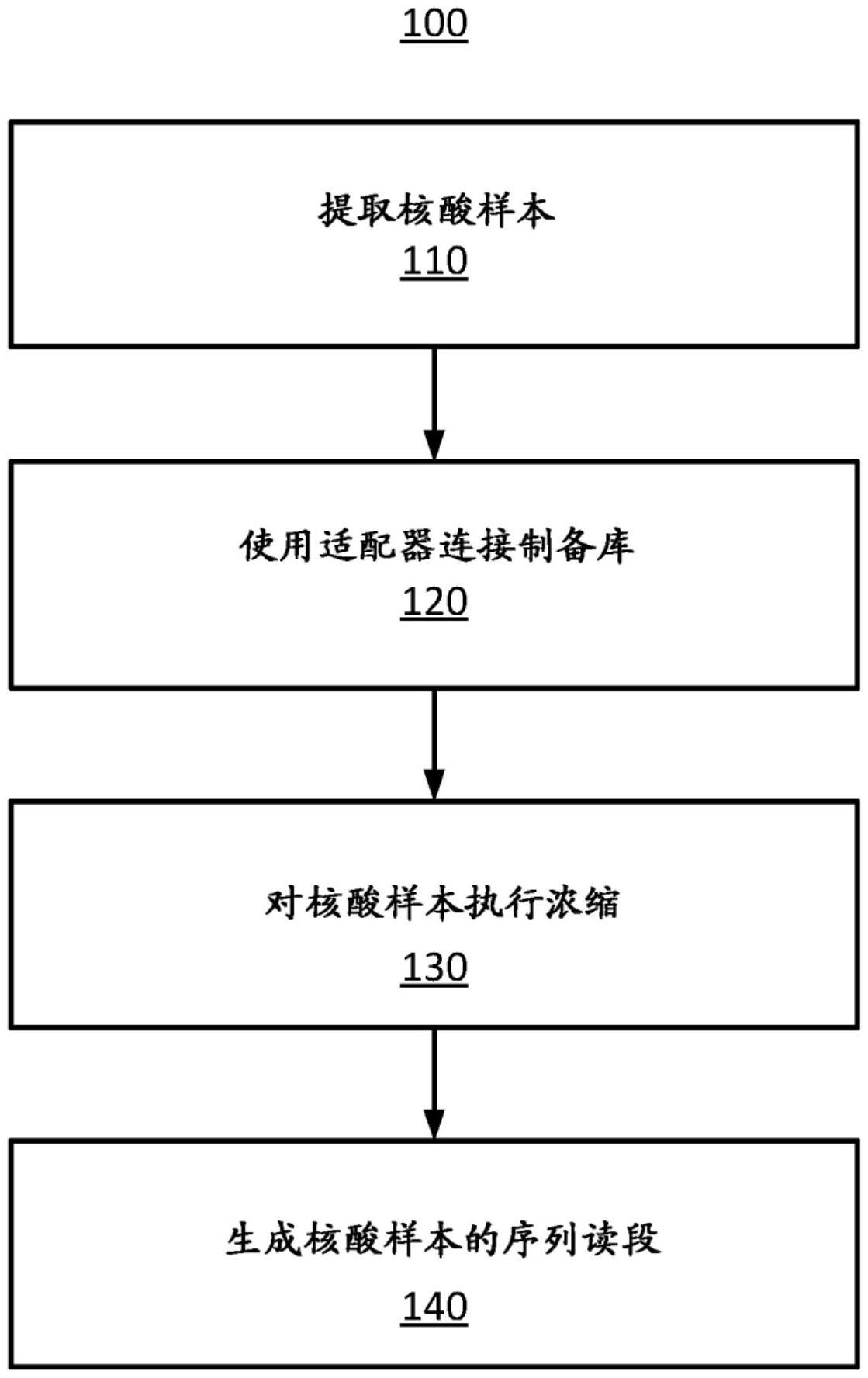
1、本文描述的系统和方法可用于确定用于确定受试者中的癌症的测试样本之间的交叉污染。测试样本是使用基因组测序技术准备的。每个测试样本包括多个序列读段对。每个序列读段对包括正向链序列读段和反向链序列读段。通常,通过甲基化感知的序列过程获得序列读段对,并且每个序列读段对包括至少一个单核苷酸多态性。
2、该系统和方法可以以各种方式过滤序列读段对以生成过滤后的群体。在一个示例中,过滤包括根据第一规则集过滤正向链序列读段和根据第二规则集过滤反向链序列读段。第一规则集描述可能指示污染的正向链序列读段,并且第二规则集描述可能指示污染的反向链序列读段。
3、该系统和方法可以基于每个snp的次要等位基因频率来确定序列读段对的群体的每个snp的先验污染概率。为此,该系统和方法可以应用污染模型(例如,应用于群体的负二项分布)。污染模型包括使用该序列读段对中的snp的污染概率来测试群体的序列读段对的至少一个似然测试。至少一个似然测试中的每一个可以被配置为产生表示序列读段对是污染的似然性的测试污染概率。当测试样本中的污染时,该系统和方法可以在污染概率高于似然阈值时,标识测试样本中的污染。
4、基于规则集的过滤过程可以基于哪个核苷酸碱基在snp位点上。更具体地,过滤可以基于哪个核苷酸碱基在正向链序列读段上的snp位点上,以及对应的反向链序列上的对应snp位点上的任何确定的核苷酸碱基。为了解释,序列读段对x正向序列就绪y和反向链序列读段z是对应的序列读段。正向链序列就绪y和反向链序列读段z中的每一个分别包括位点iy和iz处的snp。snp位点iy和iz是对应的所述snp位点。序列读段对x的snp位点iy和iz处的核苷酸碱基可能指示癌症。
5、给定此上下文,该系统和方法可以在过滤过程中应用来自规则集的各种规则。
6、在一个示例中,该系统和方法可以标识群体中的序列读段对,其中核苷酸碱基是正向链序列读段中的snp位点上的胞嘧啶碱基,而对应的核苷酸碱基是在对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱基。一旦被标识,该系统和方法可以从群体中移除所标识的序列读段对。
7、在一个示例中,该系统和方法可以标识群体中的序列读段对,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦被标识,该系统和方法可以从群体中移除所标识的序列读段对。
8、在一个示例中,该系统和方法可以标识群体中的序列读段对,其中核苷酸碱基是正向链序列读段中的snp位点的腺嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胸腺嘧啶碱基。一旦被标识,该系统和方法可以在群体中保留所标识的序列读段对。
9、在一个示例中,该系统和方法可以标识群体中的序列读段对,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦被标识,该系统和方法可以在群体中保留所标识的序列读段对。
10、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的腺嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱基。一旦被标识,该系统和方法可以在群体中保留所标识的正向链序列读段。
11、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胸腺嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱基。一旦标识,该系统和方法可以在群体中保留所标识的正向链序列读段。
12、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的腺嘌呤碱基。一旦标识,该系统和方法可以在群体中保留所标识的正向链序列读段。
13、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胸腺嘧啶碱基。一旦标识,该系统和方法可以在群体中保留所标识的正向链序列读段。
14、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胞嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱基。一旦标识,该系统和方法可以在群体中移除所标识的正向链序列读段。
15、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胞嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的腺嘌呤碱基。一旦标识,该系统和方法可以在群体中移除所标识的正向链序列读段。
16、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的腺嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦标识,该系统和方法可以在群体中移除所标识的正向链序列读段。
17、在一个示例中,该系统和方法可以标识群体中的正向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胸腺嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦标识,该系统和方法可以在群体中移除所标识的正向链序列读段。
18、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的腺嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦标识,该系统和方法可以在群体中保留所标识的反向链序列读段。
19、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胸腺嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胞嘧啶碱基。一旦标识,该系统和方法可以在群体中保留所标识的反向链序列读段。
20、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胞嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的腺嘌呤碱基。一旦标识,该系统和方法可以在群体中保留所标识的反向链序列读段。
21、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胞嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胸腺嘧啶碱基。一旦标识,该系统和方法可以在群体中保留所标识的反向链序列读段。
22、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的腺嘌呤碱基。一旦标识,该系统和方法可以在群体中移除所标识的反向链序列读段。
23、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的鸟嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的胸腺嘧啶碱基。一旦标识,该系统和方法可以在群体中移除所标识的反向链序列读段。
24、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的腺嘌呤碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱。一旦标识,该系统和方法可以在群体中移除所标识的反向链序列读段。
25、在一个示例中,该系统和方法可以标识群体中的反向链序列读段,其中核苷酸碱基是正向链序列读段中的snp位点的胸腺嘧啶碱基,而对应的核苷酸碱基是对应的所述反向链序列读段中的对应snp位点的鸟嘌呤碱基。一旦标识,该系统和方法可以在群体中移除所标识的反向链序列读段。
26、该系统和方法可以使用附加方法来过滤群体。例如,该系统和方法可以通过移除在snp移除表中包括的一个或多个snp位点包括一个或多个核苷酸碱基的序列读段对来过滤多个序列就绪对。snp移除表中的snp位点指示snp指示污染的snp。类似地,该系统或方法可以移除在snp移除表中包括的一个或多个对应snp位点包括一个或多个对应核苷酸碱基的序列读段对,snp移除表指示不准确地指示污染的snp。
27、测试样本可以来自各种位点,并且可以是多种样本类型中的一种或多种。例如,测试样本可以是血浆样本,或者包括多个无细胞dna分子。
28、此外,序列读段对可能是可变的。例如,可以从甲基化感知测序获得多个序列读段对。在这种情况下,序列读段对可以包括多个处理后的无细胞dna(cfdna)分子,使得cfdna分子中未甲基化的胞嘧啶碱基被转化为尿嘧啶碱基。序列读段对可以被处理为cfdna分子。序列读段对可以用例如亚硫酸氢钠处理。在另一个示例中,序列读段对可以用胞苷脱氨酶处理。处理后的序列可以经由全基因组亚硫酸氢盐测序和/或配对端大规模平行测序获得。在一些示例中,该系统和方法可以在执行甲基化感知测序之前扩大多个靶向cfdna分子的测试样本。
- 还没有人留言评论。精彩留言会获得点赞!