用于从无细胞DNA检测瘤形成的改进的方法与流程
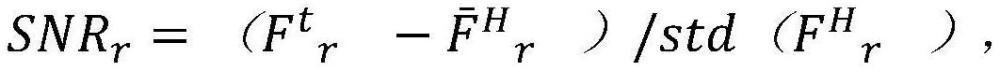
背景技术:
1、早期瘤形成(例如,癌症或肿瘤)诊断和快速治疗性干预对于降低癌症发病率和死亡率至关重要。然而,由于灵敏度和特异性低以及缺乏在各种癌症类型中普遍适用性,来自血液的现有基于蛋白质的生物标志物通常不适用于泛癌筛查。此外,利用肿瘤分数(tf)估计的癌症检测工具如果不仅用于检测早期癌症,而且用于早期检测可能在治疗下产生的耐药性克隆,则其在临床上将是最强大的,从而为另外的治疗性干预提供机会以遏制全面耐药性。
2、鉴于前述,对于用于检测和表征受试者的瘤形成的方法存在迫切且未满足的需求。
技术实现思路
1、如下文所述,本发明的特征是可用于表征受试者的瘤形成的组合物和方法。本文公开的方法通常包括确定无细胞dna(cfdna)中肿瘤来源的dna的分数(肿瘤分数;tf),以及使用拷贝数改变数据和片段长度分布数据的组合计算所述cfdna中肿瘤来源的dna的分数。
2、在一个方面,本公开的特征是一种用于表征来自患有或疑似患有瘤形成的受试者的生物样品中的dna的方法。所述方法包括(a)对源自生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述方法还包括(b)对所述序列信息进行分析以确定拷贝数谱和dna片段长度丰度谱。所述方法还包括(c)基于所述拷贝数谱和所述片段长度丰度谱计算所述cfdna中的肿瘤分数,从而表征所述生物样品中的所述dna。
3、在另一个方面,本公开的特征是一种用于表征来自患有或疑似患有瘤形成的受试者的生物样品中的dna的方法。所述方法包括(a)对源自生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述方法还包括(b)对所述序列信息进行分析以计算拷贝数谱和dna片段长度丰度谱。所述片段长度丰度谱具有至少2的信噪比(snr)和至少0.1的绝对相关系数,并且log2转换的拷贝率与瘤形成相关。所述方法还包括(c)使用将所述拷贝数谱和所述dna片段长度丰度谱组合的概率模型来计算所述cfdna中的肿瘤分数,从而表征所述生物样品中的所述dna。
4、在另一个方面,本公开的特征是一种用于鉴定来自患有或疑似患有瘤形成的受试者的生物样品中瘤形成的存在的方法。所述方法包括(a)对源自来源于所述受试者的生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述方法还包括(b)对所述序列信息进行分析以确定拷贝数谱和dna片段长度丰度谱。所述方法还包括(c)基于所述拷贝数谱和所述片段长度丰度谱计算所述cfdna中的肿瘤分数。所述方法鉴定所述生物样品中瘤形成的存在或不存在。
5、在另一个方面,本公开的特征是一种用于检测正针对瘤形成进行治疗的受试者中对疗法的耐药性的方法。所述方法包括(a)对源自来源于所述受试者的两个或更多个生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述生物样品在治疗过程期间的一个或多个时间点获得。所述方法还包括(b)对所述序列信息进行分析以确定拷贝数谱和dna片段长度丰度谱。所述方法还包括(c)基于所述拷贝数谱和所述片段长度丰度谱计算所述cfdna中的肿瘤分数。肿瘤分数随时间推移的显著增加和/或肿瘤分数高于阈值检测出耐药性。
6、在另一个方面,本公开的特征是一种用于监测正针对瘤形成进行治疗的受试者中的疗法的方法。所述方法包括(a)对源自来源于所述受试者的两个或更多个生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述生物样品在治疗过程期间的一个或多个时间点获得。所述方法还包括(b)对所述序列信息进行分析以确定拷贝数谱和dna片段长度丰度谱。所述方法还包括(c)基于所述拷贝数谱和所述片段长度丰度谱计算所述cfdna中的肿瘤分数,从而监测所述疗法。
7、在另一个方面,本公开的特征是一种用于表征受试者的疾病状态的方法。所述方法包括(a)对源自生物样品的无细胞dna(cfdna)进行测序以获得序列信息。所述方法还包括(b)在所述序列信息中确定长度为约261至约310bp的dna片段的dna片段长度丰度谱。所述方法还包括(c)使用概率模型来基于所述dna片段长度丰度谱计算所述cfdna中的肿瘤分数。非零肿瘤分数表明所述受试者患有瘤形成。
8、在任何上述方面或其实施方案中,所述dna片段长度丰度谱具有至少2的信噪比(snr)和至少0.1的绝对相关系数,并且log2转换的拷贝率与瘤形成相关。
9、在任何上述方面或其实施方案中,所述生物样品含有液体或固体样品。在任何上述方面或其实施方案中,所述生物样品含有体液。在实施方案中,所述体液含有腹水、血液、血浆、胸膜液、血清、脑脊液、痰、唾液、尿液、精液、粪便、前列腺液、母乳或泪液。在实施方案中,所述固体样品是组织样品。在实施方案中,所述组织样品是活检物。
10、在任何上述方面或其实施方案中,所述受试者是哺乳动物。在任何上述方面或其实施方案中,所述受试者是人。
11、在任何上述方面或其实施方案中,针对介于约100与约500个碱基对之间的片段长度计算所述片段长度丰度谱。在任何上述方面或其实施方案中,针对介于约100与约400个碱基对之间的片段长度计算所述片段长度丰度谱。在任何上述方面或其实施方案中,针对介于约200与约400个碱基对之间的片段长度计算所述片段长度丰度谱。在任何上述方面或其实施方案中,针对介于约261与约310个碱基对之间的片段长度计算所述片段长度丰度谱。
12、在任何上述方面或其实施方案中,在计算所述片段长度丰度谱的片段长度范围内的连续片段长度箱体(bin)内计算snr。在任何上述方面或其实施方案中,所述snr被计算为snri,j,其中i是无细胞dna样品,j是片段长度的箱体,并且snri,j是样品i中的那些片段j的分数减去一组健康供体中的平均分数,然后除以所述一组健康供体中的分数的标准偏差。在任何上述方面或其实施方案中,所述snr是在计算所述dna片段长度丰度谱的片段长度范围内的箱体中计算的最大snr。在实施方案中,所述箱体的大小是5bp、10bp、15bp或20bp。在任何上述方面或其实施方案中,所述snr被计算为其中ftr表示生物样品t中的dna片段长度箱体r,并且表示片段长度箱体r中dna片段的分数在正常健康组内的平均值。在任何上述方面或其实施方案中,所述snr是至少约3或4。
13、在任何上述方面或其实施方案中,所述相关系数是斯皮尔曼(spearman)相关系数。在任何上述方面或其实施方案中,所述绝对相关系数是至少约0.2或0.3。在任何上述方面或其实施方案中,所述相关系数是在所述log_2转换的拷贝率与dna片段长度箱体r中的片段的分数之间计算的,所述dna片段长度箱体r跨越具有对应于扩增的最高拷贝率的那些基因组区段的前10%和具有对应于缺失的拷贝率的那些基因组区段的后10%。
14、在任何上述方面或其实施方案中,所述cfdna中的肿瘤分数是使用贝叶斯(bayesian)模型计算的。在任何上述方面或其实施方案中,所述概率模型是贝叶斯模型。在实施方案中,所述贝叶斯模型是可解释的贝叶斯图形模型。
15、在任何上述方面或其实施方案中,所述肿瘤分数小于约0.03。在任何上述方面或其实施方案中,所述肿瘤分数是约1e-4至约0.03。在任何上述方面或其实施方案中,所述肿瘤分数是约5e-3至约0.15。在任何上述方面或其实施方案中,所述肿瘤分数介于约1e-5与约0.1之间。在任何上述方面或其实施方案中,所述肿瘤分数小于0.01。
16、在任何上述方面或其实施方案中,所述方法还包括将所述拷贝数谱和所述片段长度丰度谱与匹配的正常样品进行比较。在实施方案中,所述匹配的正常样品来自健康受试者。在实施方案中,所述健康受试者是从其收集所述生物样品的同一受试者。
17、在任何上述方面或其实施方案中,所述瘤形成选自以下中的一者或多者:胆管癌、膀胱癌、乳腺癌、结肠癌、头颈癌、肝癌、肺癌、肝内胆管癌、前列腺癌、卵巢癌、皮肤癌、胃癌、甲状腺癌和慢性淋巴细胞白血病(richter转化)。
18、在任何上述方面或其实施方案中,测序覆盖度小于约5x。在任何上述方面或其实施方案中,测序覆盖度是约0.1x或0.2x。
19、在任何上述方面或其实施方案中,确定所述肿瘤分数,平均绝对误差为约0%至约20%。在任何上述方面或其实施方案中,确定所述肿瘤分数,平均绝对误差为约4.5%至约11%。
20、在任何上述方面或其实施方案中,所述测序是下一代测序。在任何上述方面或其实施方案中,所述测序是超低通全基因组测序。
21、在任何上述方面或其实施方案中,所述计算是在计算机系统上进行的。
22、在任何上述方面或其实施方案中,所述阈值是至少约5%。在任何上述方面或其实施方案中,所述阈值是至少约10%。在任何上述方面或其实施方案中,所述增加是至少1%增加。在任何上述方面或其实施方案中,所述增加是至少2倍增加。
23、在任何上述方面或其实施方案中,所述方法还包括约每天、每3天、每1周、每2周、每3周或每月一次从所述受试者收集生物样品,并确定每个生物样品的cfdna中的肿瘤分数。在任何上述方面或其实施方案中,所述方法还包括约每1年一次从所述受试者收集生物样品,并确定每个生物样品的cfdna中的肿瘤分数。
24、在任何上述方面或其实施方案中,所述疗法是化学疗法、放射或免疫疗法。
25、在任何上述方面或其实施方案中,所述拷贝数谱和/或所述dna片段长度丰度谱是在所述序列信息中表示的1、2、3、4、5个或所有基因组基因座内计算的。
26、本发明提供了可用于确定无细胞dna(cfdna)中肿瘤来源的dna的分数(肿瘤分数;tf)的组合物和方法。由本发明定义的组合物和物品是经过分离的或结合下文提供的实施例以其它方式制造的。根据具体实施方式和权利要求,本发明的其它特征和优点将显而易见。
27、定义
28、除非另外定义,否则本文所用的所有技术和科学术语具有本发明所属领域的技术人员通常理解的含义。以下参考文献为技术人员提供本发明中所使用的许多术语的一般定义:singleton等人,dictionary of microbiology and molecular biology(第2版1994);the cambridge dictionary of science and technology(walker编辑,1988);theglossary of genetics,第5版,r.rieger等人(编辑),springer verlag(1991);以及hale和marham,the harper collins dictionary of biology(1991)。除非另外指明,否则如本文所使,以下术语具有下文赋予它们的含义。
29、“剂(agent)”意指任何小分子化学化合物、抗体、核酸分子或多肽或其片段。
30、如本文所用,术语“算法”是指采用一个或多个输入或参数(无论是连续的还是分类的)并计算输出值、指数、指数值或得分的任何公式、模型、数学方程式、算法、分析或编程过程,或统计技术或分类分析。算法的实例包括但不限于比率、总和、回归算子(如指数或系数)、生物标志物值转换和归一化(包括但不限于基于临床参数如年龄、性别、种族等的归一化方案)、规则和指南、统计分类模型、统计权重以及在群体或数据集上训练的神经网络。此外,在如本文所述的tufest的上下文中使用的是可用于推断循环无细胞dna(cfdna)中的潜在肿瘤分数和/或总拷贝数谱的贝叶斯模型。
31、“改善”意指减少、阻遏、减弱、减轻、阻止或稳定疾病的发展或进展。
32、“改变”是指如通过本领域已知的标准方法(如本文所述的那些)所检测,基因或多肽的结构、表达水平或活性的变化。改变可以是增加或减少。如本文所用,改变包括表达水平的10%变化,优选25%变化,更优选40%变化,并且最优选表达水平的50%或更大变化。在实施方案中,改变是氨基酸或核碱基序列改变。
33、“类似物”是指不相同但具有类似功能或结构特征的分子。例如,多肽类似物保留相应天然存在的多肽的生物活性,同时相对于天然存在的多肽具有增强类似物的功能的某些生物化学修饰。此类生物化学修饰可增加类似物的蛋白酶抗性、膜通透性或半衰期,而不改变例如配体结合。类似物可包括非天然氨基酸。
34、“箱体(bin)”是指一组成员。在一个实施方案中,本文所述的箱体包含一组特定长度的多核苷酸片段。箱体可通过落在所述箱体内的最大大小的片段与最小大小的片段之间的差异来指定。例如,大小为10bp的箱体表示跨越10bp的片段长度范围内的多核苷酸片段长度范围。更具体地,在一个实例中,10bp的箱体可对应于具有约261bp至约270bp大小的那些dna片段。在实施方案中,箱体对应于落入较大片段长度范围内的一组多核苷酸片段长度。
35、术语“癌症”是指恶性肿瘤。在本公开的范围内还考虑本文的技术可应用于检测和/或监测受试者的癌症。
36、在本公开中,“包含”和“具有”等可具有专利法赋予它们的含义,并且可意指“包括”等;“基本上由……组成”或同样具有专利法赋予的含义,并且所述术语是开放式的,从而允许超出所叙述的存在,只要所叙述的基本或新颖特征不被超过叙述的存在改变,但是排除现有技术实施方案。被指定为“包含”特定组分或元件的任何实施方案在一些实施方案中也被设想为“由所述特定组分或元件组成”或“基本上由所述特定组分或元件组成”。
37、“对照”或“参考”意指比较的标准。在一个方面,如本文所用,“与对照相比发生变化”的样品或受试者被理解为具有与来自正常、未处理或对照样品的样品在统计学上不同的水平。对照样品包括例如培养中的细胞、一种或多种实验室试验动物或一种或多种人受试者。选择和测试对照样品的方法在本领域技术人员的能力范围内。统计显著性的确定在本领域技术人员的能力范围内,例如,与构成阳性结果的平均值的标准偏差的数量。在实施方案中,参考是受试者或来自未患有癌症的受试者的样品或在治疗或施用药物或治疗的改变之前的受试者。在实施方案中,参考是匹配的正常样品,其中在一些情况下,匹配的正常样品是来自健康受试者和/或未患有癌症的受试者(例如,在被诊断患有癌症或肿瘤之前的受试者)。
38、“拷贝数谱”是指相对于参考,生物样品中存在的一组拷贝数改变。在实施方案中,生物样品包含无细胞dna。在一些情况下,参考是参考序列,其是健康受试者的基因组或来自健康受试者或一组健康受试者的无细胞dna的序列。
39、如本文所用,术语“覆盖度”是指与参考序列中的特定基因座比对的序列读数的数量。在实施方案中,参考序列是参考基因组。例如,关于以下参考序列的末端碱基,由于在此基因座只有一个比对的样品碱基(读数2中的粗体胞嘧啶),因此在此基因座存在1x参考序列覆盖度。在5'端,在5'末端鸟嘌呤处存在3x参考序列覆盖度。
40、参考序列:5’gggaagggcgatc 3’(seq id no:1)
41、读数1
42、读数2
43、读数3
44、当对基因组进行测序时,将存在大量被测序的核苷酸。如果单个基因组仅测序一次,则将存在大量测序错误。为了提高测序精确度,将需要对单个基因组进行多次测序。整个基因组的平均覆盖度可从原始基因组的长度(g)、读数的数量(n)和平均读取长度(l)计算为n x l/g。在另一个实例中,从8个平均长度为500个核苷酸的读数中重构的具有2,000个碱基对的假定基因组将具有2×冗余。此参数还使人们能够估计其它数量,如读数所覆盖的基因组的百分比(有时也称为覆盖广度)。在0.1x的覆盖度下,只有10%的参考序列被序列读数覆盖。在实施方案中,对样品多核苷酸进行测序,达到约、至少约和/或不超过约1e-8、1e-7、1e-6、1e-5、1e-4、1e-3、1e-2、0.05x、0.1x、0.2x、0.3x、0.4x、0.5x、1x、2x、3x、4x、5x、7x、8x、9x、10x、20x、30x、40x、50x、60x、70x、90x、100x或更大的覆盖度。
45、“超低覆盖度”是指小于至少5x的覆盖度。在一些情况下,超低覆盖度是小于0.5x、0.2x或0.1x的覆盖度。
46、“检测”是指鉴定待检测的分析物的存在、不存在或量。
47、“可检测标记”是指当与目标分子连接时使所述分子可通过光谱、光化学、生物化学、免疫化学或化学手段检测的组合物。例如,有用的标记包括放射性同位素、磁珠、金属珠、胶体颗粒、荧光染料、电子致密试剂、酶(例如,如elisa中常用的)、生物素、地高辛或半抗原。
48、“疾病”意指损害或干扰细胞、组织或器官的正常功能的任何疾患或病症。在实施方案中,疾病是瘤形成。
49、“疾病状态”是指疾病的存在、不存在和/或严重程度。
50、“dna片段长度丰度谱”是指在一个或多个遗传基因座处的一组dna片段长度丰度测量值。在实施方案中,在样品的约、至少约或不超过约1、2、3、4、5、6、7、8、9、10、100、1000、10000、100000、1000000个或所有基因组基因座处确定落入预定长度范围(例如,约261bp至约310bp)内的dna片段的dna片段长度丰度谱。
51、“有效量”是足以实现有益的或所需的结果的量。例如,治疗量是实现所需治疗效果的量。此量可与预防有效量相同或不同,预防有效量是预防疾病或疾病症状的发作所必需的量。有效量可以一次或多次施用、施加或剂量来施用。治疗性化合物的治疗有效量(即,有效剂量)取决于所选择的治疗性化合物。组合物可每天施用一次或多次至每周施用一次或多次;包括每隔一天一次。本领域的技术人员将了解,某些因素可影响有效治疗受试者所需的剂量和时程,所述因素包括但不限于,疾病或病症的严重程度、先前治疗、受试者的一般健康状况和/或年龄以及存在的其它疾病。此外,用治疗有效量的本文所述的治疗性化合物治疗受试者可包括单次治疗或一系列治疗。
52、“片段”意指多肽或核酸分子的一部分。此部分优选含有参考核酸分子或多肽的全长的至少10%、20%、30%、40%、50%、60%、70%、80%或90%。片段可含有10、20、30、40、50、60、70、80、90或100、200、300、400、500、600、700、800、900或1000个核苷酸或氨基酸。
53、“杂交”是指互补核碱基之间的氢键合,所述氢键合可以是沃森-克里克(watson-crick)、霍氏(hoogsteen)或反霍氏氢键合。例如,腺嘌呤与胸腺嘧啶是通过形成氢键配对的互补核碱基。
54、“增加”是指相对于参考正向改变至少5%。增加可以是增加5%、10%、25%、30%、50%、75%或甚至100%。
55、术语“分离的”、“纯化的”或“生物上纯的”是指在不同程度上不含如同在其天然状态中所发现的通常伴随它的组分的材料。“分离”表示与原始来源或周围物分开的程度。“纯化”表示高于分离的分开程度。“纯化的”或“生物上纯的”蛋白质充分不含其它材料,这样使得任何杂质不实质上影响蛋白质的生物性质或导致其它不利后果。即,如果当本发明的核酸或肽通过重组dna技术产生时基本上不含细胞材料、病毒材料或培养基,或者当本发明的核酸或肽化学合成时基本上不含化学前体或其它化学物质,则所述核酸或肽是纯化的。纯度和均质性通常使用分析化学技术,例如聚丙烯酰胺凝胶电泳或高效液相色谱法来确定。术语“纯化的”可表示核酸或蛋白质在电泳凝胶中基本上产生一个条带。对于可经受修饰(例如,磷酸化或糖基化)的蛋白质,不同修饰可产生不同的分离蛋白质,所述蛋白质可单独纯化。
56、“分离的多核苷酸”是指不含在本发明的核酸分子所来源的生物体的天然存在的基因组中位于基因的侧翼的基因的核酸。所述术语因此包括(例如)并入载体中、并入自主复制质粒或病毒中、或并入原核生物或真核生物的基因组dna中的重组dna,或作为独立于其它序列的单独分子存在的重组dna(例如,通过pcr或限制性核酸内切酶消化产生的cdna或基因组或cdna片段)。此外,所述术语包括从dna分子转录的rna分子,以及作为编码另外多肽序列的杂合基因的一部分的重组dna。
57、“分离的多肽”是指已与天然伴随它的组分分离的本发明多肽。通常,当多肽至少60重量%不含与其天然缔合的蛋白质和天然存在的有机分子时,所述多肽是分离的。优选地,制剂是至少75重量%、更优选至少90重量%、并且最优选至少99重量%的本发明多肽。本发明的分离多肽可例如通过从天然源提取、通过表达编码这种多肽的重组核酸或通过化学合成蛋白质而获得。可通过任何适当的方法,例如柱色谱法、聚丙烯酰胺凝胶电泳或通过hplc分析测量纯度。
58、“液体活检”是指来自血液或其它体液的肿瘤来源的材料的分离和分析。在实施方案中,所述材料含有dna、rna和/或完整细胞。在一些情况下,所述材料不含完整细胞。在一些情况下,肿瘤来源的材料是无细胞dna(cfdna)。
59、“标志物”是指在表达水平或活性方面具有与发育状态、疾患、疾病或病状相关的改变的任何蛋白质或多核苷酸。
60、“瘤形成”意指特征在于过度增殖或细胞凋亡减少的疾病或病症。在实施方案中,瘤形成是癌症或肿瘤。说明性瘤形成包括乳腺癌、食道癌、头颈癌、胰腺癌、皮肤癌、结肠直肠癌、肝细胞癌、膀胱癌、胆管癌、管腔和非管腔膀胱癌、基底膀胱癌、肌肉浸润性膀胱癌和非肌肉浸润性膀胱癌、胰腺癌、白血病(例如,急性白血病、急性淋巴细胞性白血病、急性髓细胞性白血病、急性成髓细胞性白血病、急性早幼粒细胞性白血病、急性粒单核细胞性白血病、急性单核细胞性白血病、急性红白血病、慢性白血病、慢性髓细胞性白血病、慢性淋巴细胞性白血病)、真性红细胞增多症、淋巴瘤(霍奇金病、非霍奇金病)、瓦尔登斯特伦氏巨球蛋白血症、重链病和实体瘤如肉瘤和癌(例如,纤维肉瘤、粘液肉瘤、脂肪肉瘤、软骨肉瘤、骨原性肉瘤、脊索瘤、血管肉瘤、内皮肉瘤、淋巴管肉瘤、淋巴管内皮肉瘤、滑膜瘤、间皮瘤、尤文氏瘤、平滑肌肉瘤、横纹肌肉瘤、结肠癌、卵巢癌、前列腺癌、鳞状细胞癌、基底细胞癌、腺癌、汗腺癌、皮脂腺癌、乳头状癌、乳头状腺癌、囊腺癌、髓样癌、支气管癌、肾细胞癌、肝癌、胆管癌、绒毛膜癌、精原细胞瘤、胚胎性癌、威尔姆氏肿瘤、肝癌、宫颈癌、子宫癌、睾丸癌、肺癌、小细胞肺癌、膀胱癌、上皮癌、神经胶质瘤、多形性成胶质细胞瘤、星形细胞瘤、成神经管细胞瘤、颅咽管瘤、室管膜瘤、松果体瘤、成血管细胞瘤、听神经瘤、少突胶质细胞瘤、神经鞘瘤、脑膜瘤、黑素瘤、成神经细胞瘤和成视网膜细胞瘤)。在实施方案中,瘤形成可以是结肠腺癌(coad)、胃腺癌(stad)、胃癌和子宫体子宫内膜癌(ucec)。在实施方案中,瘤形成可以是液体肿瘤,例如白血病或淋巴瘤。在实施方案中,癌症是胆管癌、膀胱癌、乳腺癌、结肠癌、头颈癌、肝癌、肺癌和/或肝内胆管癌、肺癌、卵巢癌、前列腺癌、皮肤癌、甲状腺癌或胃癌,或慢性淋巴细胞性白血病(richter转化)。
61、如本文所用,术语“下一代测序(ngs)”是指多种高通量测序技术,所述技术使测序过程并行化,从而一次产生数千或数百万个序列读数。测序反应的ngs并行化可在单次仪器运行中产生数百兆碱基至千兆碱基的核苷酸序列读数。与常规测序技术如桑格测序不同,桑格测序通常报告分子聚合集合的平均基因型,ngs技术通常以数字方式将众多单独dna片段的序列制成表格(序列读数在下文详细论述),使得可检测到低频变体(例如,在异质核酸分子群体中以低于约10%、5%或1%频率存在的变体)。术语“大规模并行”也可用于指ngs从许多不同的模板分子同时生成序列信息。ngs测序平台包括但不限于以下:大规模并行签名测序(lynx therapeutics);454焦磷酸测序(454life sciences/roche diagnostics);固相、可逆染料终止子测序(solexa/illumina);solid技术(applied biosystems);离子半导体测序(ion torrent);和dna纳米球测序(complete genomics)。某些ngs平台的描述可在以下中找到:shendure,等人,“next-generation dna sequencing,”nature,2008,第26卷,第10期,135-1 145;mardis,“the impact of next-generation sequencingtechnology on genetics,”trends in genetics,2007,第24卷,第3期,第133-141页;su,等人,“next-generation sequencing and its applications in moleculardiagnostics”expert rev mol diagn,2011,11(3):333-43;以及zhang等人,“the impactof next-generation sequencing on genomics,”j genet genomics,201,38(3):95-109。
62、如本文所用,如“获得剂”中的“获得”包括合成、购买或以其它方式获得剂。
63、“多肽”或“氨基酸序列”是指任何氨基酸链,与长度或翻译后修饰无关。在各种实施方案中,翻译后修饰是糖基化或磷酸化。在各种实施方案中,可对多肽进行保守氨基酸取代以提供功能上等效的变体,或多肽的同源物。在一些方面,本发明包括导致保守氨基酸取代的序列改变。在一些实施方案中,“保守氨基酸取代”是指不改变进行保守氨基酸取代的蛋白质的相对电荷或尺寸特征的氨基酸取代。变体可根据用于改变多肽序列的方法来制备,所述方法为本领域的普通技术人员已知,如在汇编此类方法的参考文献中所发现,例如,molecular cloning:a laboratory manual,j.sambrook,等人,编辑,第二版,coldspring harbor laboratory press,cold spring harbor,n.y.,1989;或currentprotocols in molecular biology,f.m.ausubel,等人,编辑,john wiley&sons,inc.,newyork。氨基酸的保守取代的非限制性实例包括在以下组内的氨基酸之间进行的取代:(a)m、i、l、v;(b)f、y、w;(c)k、r、h;(d)a、g;(e)s、t;(f)q、n;以及(g)e、d。在各种实施方案中,可对本文公开的蛋白质和多肽的氨基酸序列进行保守氨基酸取代。
64、“概率模型”是指用于基于一个或多个概率分布定义变量之间的关系的统计模型。概率模型的非限制性实例是贝叶斯模型,如可解释的贝叶斯图形模型。
65、“减少”是指相对于参考负向改变至少5%。减少可以是减少5%、10%、25%、30%、50%、75%或甚至100%。
66、“参考序列”是用作序列比较的基础的定义序列。参考序列可以是指定序列的子集或全部;例如,全长cdna或基因序列的区段,或完整cdna或基因序列。对于多肽,参考多肽序列的长度通常将是至少约10个氨基酸,优选至少约20个氨基酸,更优选至少约25个氨基酸,并且甚至更优选约35个氨基酸、约50个氨基酸或约100个氨基酸。对于核酸,参考核酸序列的长度通常将是至少约50个核苷酸,优选至少约60个核苷酸,更优选至少约75个核苷酸,并且甚至更优选约100个核苷酸或约300个核苷酸,或其附近或之间的任何整数。在实施方案中,“参考序列”是指来自健康供体的单个基因组或反映来自一组基因组的输入的代表性基因组。在一些情况下,“参考序列”是从健康受试者或从一组健康受试者收集的多核苷酸样品(例如,cfdna样品)的序列。在实施方案中,“参考序列”是对应于一组健康受试者的多核苷酸序列的集合。
67、“信噪比(snr)”是指相对于不希望的背景变化的水平,所需信号的水平。
68、“特异性地结合”意指化合物或抗体识别并结合本发明的多肽,但是基本上不识别并结合样品(例如,生物样品,其天然地包含本发明的多肽)中的其它分子。
69、可用于本发明方法中的核酸分子包括编码本发明的多肽或其片段的任何核酸分子。此类核酸分子不需要与内源核酸序列100%同一,但通常将表现出实质同一性。与内源性序列具有“实质同一性”的多核苷酸通常能够与双链核酸分子的至少一条链杂交。可用于本发明方法中的核酸分子包括编码本发明的多肽或其片段的任何核酸分子。此类核酸分子不需要与内源核酸序列100%同一,但通常将表现出实质同一性。与内源性序列具有“实质同一性”的多核苷酸通常能够与双链核酸分子的至少一条链杂交。“杂交”是指在各种严格度条件下配对以在互补多核苷酸序列(例如本文所述的基因)或其部分之间形成双链分子。(参见例如,wahl,g.m.和s.l.berger(1987)methods enzymol.152:399;kimmel,a.r.(1987)methods enzymol.152:507)。
70、例如,严格盐浓度通常将是小于约750mm nacl和75mm柠檬酸三钠,优选小于约500mm nacl和50mm柠檬酸三钠,更优选小于约250mm nacl和25mm柠檬酸三钠。在不存在有机溶剂例如甲酰胺的情况下可获得低严格度杂交,而在存在至少约35%甲酰胺且更优选至少约50%甲酰胺的情况下可获得高严格度杂交。严格温度条件通常将包括至少约30℃、更优选至少约37℃且最优选至少约42℃的温度。改变另外的参数,如杂交时间、洗涤剂例如十二烷基硫酸钠(sds)的浓度以及载体dna的包含或排除对于本领域技术人员来说是众所周知的。通过根据需要组合这些不同条件来实现各种严格度水平。在一个优选的实施方案中,杂交将在30℃在750mm nacl、75mm柠檬酸三钠和1% sds中发生。在一个更优选的实施方案中,杂交将在37℃在500mm nacl、50mm柠檬酸三钠、1% sds、35%甲酰胺和100μg/ml变性鲑鱼精子dna(ssdna)中发生。在最优选的实施方案中,杂交将在42℃在250mm nacl、25mm柠檬酸三钠、1% sds、50%甲酰胺和200μg/ml ssdna中发生。关于这些条件的有用变化对于本领域技术人员来说将是显而易见的。
71、对于大多数应用,杂交后的洗涤步骤的严格度方面也将不同。洗涤严格度条件可通过盐浓度和温度来定义。如上所述,洗涤严格度可通过降低盐浓度或通过提高温度来增加。例如,洗涤步骤的严格盐浓度将是优选小于约30mm nacl和3mm柠檬酸三钠,并且最优选小于约15mm nacl和1.5mm柠檬酸三钠。洗涤步骤的严格温度条件通常将包括至少约25℃、更优选至少约42℃且甚至更优选至少约68℃的温度。在一个优选实施方案中,洗涤步骤将在25℃在30mm nacl、3mm柠檬酸三钠和0.1% sds中发生。在一个更优选的实施方案中,洗涤步骤将在42c在15mm nacl、1.5mm柠檬酸三钠和0.1%sds中发生。在一个更优选的实施方案中,洗涤步骤将在68℃在15mm nacl、1.5mm柠檬酸三钠和0.1% sds中发生。关于这些条件的另外变化对于本领域技术人员来说将是显而易见的。杂交技术是本领域技术人员是众所周知的并且描述于例如benton和davis(science 196:180,1977);grunstein和hogness(proc.natl.acad.sci.,usa 72:3961,1975);ausubel等人(current protocols inmolecular biology,wiley interscience,new york,2001);berger和kimmel(guide tomolecular cloning techniques,1987,academic press,new york);以及sambrook等人,molecular cloning:a laboratory manual,cold spring harbor laboratory press,newyork中。
72、“基本上同一”是指多肽或核酸分子表现出与参考氨基酸序列(例如,本文所述的氨基酸序列中的任一个)或核酸序列(例如,本文所述的核酸序列中的任一个)的至少50%同一性。优选地,这样的序列在氨基酸水平或核酸水平上与用于比较的序列具有至少60%、更优选80%或85%且更优选90%、95%或甚至99%的同一性。
73、序列同一性通常使用序列分析软件(例如,genetics computer group的序列分析软件包,威斯康星大学生物技术中心,1710university avenue,madison,wis.53705;blast、bestfit、gap或pileup/prettybox程序)进行测量。这种软件通过对不同的取代、缺失和/或其它修饰的同源性程度进行赋值而将同一或相似的序列进行匹配。保守取代通常包括以下组内的取代:甘氨酸,丙氨酸;缬氨酸,异亮氨酸,亮氨酸;天冬氨酸,谷氨酸,天冬酰胺,谷氨酰胺;丝氨酸,苏氨酸;赖氨酸,精氨酸;以及苯丙氨酸,酪氨酸。在确定同一性程度的示例性方法中,可使用blast程序,其中介于e-3与e-100之间的概率分数指示密切相关的序列。
74、“受试者”是指动物。动物可以是哺乳动物。哺乳动物可以是人或非人哺乳动物,如牛科动物、马科动物、犬科动物、绵羊科动物、啮齿动物或猫科动物。
75、本文提供的范围应理解为所述范围内的所有值的简写。例如,1至50的范围应理解为包括来自由以下组成的组的任何数字、数字组合或子范围:1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50。
76、如本文所用,术语“治疗”等是指获得所需药理学和/或生理学作用。如本文所用,“治疗”涵盖哺乳动物,特别是人的疾病或疾患的治疗,并且包括抑制疾病(例如,阻止其发展)和/或缓解疾病(例如,引起疾病消退)。在实施方案中,治疗改善瘤形成的至少一种症状。例如,治疗可导致肿瘤大小、肿瘤生长、癌细胞数量、癌细胞生长或转移或转移风险降低。“肿瘤来源的dna”是指来源于癌细胞而非健康对照细胞的dna。肿瘤来源的dna通常包括指示癌症的结构变化。此类结构变化可在染色体水平,其包括序列的非整倍性(染色体数目异常)、重复、缺失或倒位或改变。
77、术语“肿瘤分数”是指样品中来源于或预计来源于肿瘤细胞的dna部分。在实施方案中,dna是无细胞dna(cfdna)。
78、除非明确规定或从上下文显而易见,否则如本文所使用,术语“或”被理解为包括在内。除非明确规定或根据上下文显而易见,否则如本文所用,术语“一个/种”和“所述”应理解为单数或复数。
79、除非明确规定或从上下文显而易见,否则如本文所用,术语“约”应理解为在本领域的正常公差范围内,例如在平均值的2个标准偏差以内。除非另外从上下文显而易见,否则本文提供的所有数值都由术语“约”修饰。
80、在本文中变量的任何定义中引述化学基团的清单包括定义所述变量作为任何单一基团或所列基团的组合。在本文中引述变量或方面的实施方案包括作为任何单一实施方案或与任何其它实施方案组合或其部分的所述实施方案。
81、本文提供的任何组合物或方法可与本文提供的任何其它组合物和方法中的一者或多者组合。
- 还没有人留言评论。精彩留言会获得点赞!