结核分枝杆菌H37Rv编码基因及其应用的制作方法
本发明涉及基因检测领域,具体涉及对病原菌物种进行鉴定。
背景技术:
结核分枝杆菌(Mycobacterium tuberculosis,MTB)是引起人类结核病的病原菌。可入侵全身各器官,但以肺结核为最多见。结核病是至今极为重要的传染病,严重威胁人类生命健康。据WHO报道,每年约有800万新病例发生,至少有300万人死于该病。MTB的临床菌株难培养、生长缓慢、与其它分枝杆菌能交叉感染、结核病与其它呼吸道感染症状难区分等特征,给临床快速诊断和治疗带来了极大的困难。故建立快速、准确、特异、敏感、廉价的结核病检测方法,是有效治疗、控制结核病蔓延的必要前提,也是临床实验室分枝杆菌检测面临的新挑战和新任务。
结核分枝杆菌复合群(Mycobacterium tuberculosis complex,MTBC),包括M.tuberculosis、M.africanum、M.orygis、M.bovis、M.microti、M.canettii、M.caprae、M.pinnipedii、M.suricattae、M.mungi等分枝杆菌类群,这些物种均会引起人和其它生命体结核病。目前国内外对MTBC的鉴定方法主要分为以下三类:传统分离培养法;分子水平检测(IS6110、限制性片段长度多态性分析、多位点可变数目重复片段多态性分析等);菌体成分(脂肪酸、分枝菌酸)色谱分析方法。三类方法虽都有各自的优点,但也有不足之处,如传统分离培养周期长和菌体可培养率低;目前分子水平检测在特异性、灵敏性和简便性方面尚差些;菌体成分特性分析成本较高、操作复杂。
MTB H37Rv于1998年完成全基因组测序,是最早完成全图测序的MTB菌株。自此,各国研究者们基于算法优化、注释软件更新、转录组学和蛋白质组学等策略,一直在完善、补充H37Rv基因注释数据库。然而,由于MTB属于原核生物,由于原核生物基因组注释技术本身的不足,在基因组注释中尚可能存在注释错误(过度注释、基因边界错误和ORF起始、终止位点错误、可变剪接、核糖体移位、漏注释),给深入、准确解析生物学机制带来了困扰。为解决此难题,蛋白质基因组学(Proteogenomics)虽已被用于H37Rv已注释基因的校正,然而,高比例假阳性、常规技术难以进行注释基因预测、新基因验证、新基因功能分析及其应用等是该领域所面临的难题。总的来说,传统结核分枝杆菌复合群(MTBC)鉴定策略具有周期长、步骤繁琐、特异性和灵敏度不高等缺陷。为进一步完善对H37Rv全基因组重新注释,发现H37Rv中遗漏注释基因,确保H37Rv全基因组遗漏注释基因及其在MTBC分子鉴定中的应用技术得到有效保护,开发利用H37Rv新基因在MTBC类群中快速精准鉴别的方法势在必行。
技术实现要素:
本发明的一个目的是提供一种结核分枝杆菌H37Rv新的编码基因,该基因为H37Rv漏注释编码基因Rv2003(-|2249260-2249457|),其可用作结核分枝杆菌复合群条形码分子标记,用于检测结核分枝杆菌复合群,其序列如SEQ ID NO.1所示。
本发明的其他目的包括提供可用于扩增上述编码基因的特异性PCR引物以及提供一种检测或鉴定样品中是否存在结合分枝杆菌复合群的检测方法;本发明还提供与上述编码基因相关的检测试剂盒和上述基因的应用。
根据本发明的一个方面,通过比较蛋白质基因组学研究技术,发现了H37Rv中一个难以被基因预测软件发现的蛋白编码序列,该基因能有效地将MTBC与同属的其它物种区分开来。该基因是一个结核分枝杆菌(Mycobacterium tuberculosis H37Rv)的遗漏注释基因,即Rv2003(-|2249260-2249457|),经NCBI-BLASTP后,与M.tuberculosis Bir 105相似性为100%,M.tuberculosis J09701920相似性为98%,M.canettii RefSeq(WP_041179674.1)的相似性为97%,,其它物种相似性均低于77%,其功能注释蛋白是Phosphoenolpyruvate synthase。经比较基因组学研究发现该基因序列能将结核分枝杆菌复合群(MTBC)菌株与分枝杆菌属的其它种鉴别开来。
具体地,设计能对MTBC的Rv2003(-|2249260-2249457|)基因实现特异性扩增引物,即为本发明所提出的引物,引物序列为:
F:5’-CCAACCATCACTGTCAGC-3’;
R:5’-AGCAACAATCGGCGTTC-3’。
根据待测样品中的该基因DNA序列PCR产物的有无或DNA序列的差异,可以快速准确鉴定MTBC。
根据本发明的另一个方面,基于上述结核分枝杆菌H37Rv新的标准编码基因,本发明具体地建立了检测或鉴定结核分枝杆菌复合群的方法,步骤如下:
(1)从待测样品中分离提取基因组DNA;
(2)以步骤(1)获得的DNA为模板,采用下述引物进行PCR扩增:
F:5’-CCAACCATCACTGTCAGC-3’(SEQ ID NO.4);
R:5’-AGCAACAATCGGCGTTC-3’(SEQ ID NO.5)。
(3)对步骤(2)扩增得到的DNA产物进行凝胶电泳分析或进行测序;
(4)将步骤(3)的结果与条形码基因Rv2003(-|2249260-2249457|)进行比对,如果同源性大于99%,判定待测样品含有结核分枝杆菌复合群。
进一步地,上述检测方法,根据DNA条形码原理,初步对PCR产物进行电泳分析,如果待测菌株没有目标条带,说明该菌株不是MTBC;如果有条带,则可进一步测序验证,将测序得到系列与H37Rv的Rv2003(-|2249260-2249457|)的标准序列进行同源比较和比对,获得序列间的相似性,若序列同源性大于99%,即可判定菌株可能为MTBC;根据待鉴定鉴定菌株的DNA条形码序列与标准序列聚类情况来区分MTBC家族与非结核分枝杆菌、呼吸道常见病原菌及呼吸道常见病毒。
该检测方法即可用于对结核分枝杆菌复合群的菌种鉴定研究,也可用于临床快速检验。待测样品可以是从H37Rv菌株、其它MTBC、非结核分枝杆菌、呼吸道常见病原菌、呼吸道常见病毒菌株;或者直接使用结核病和其它呼吸道患者痰液、唾液或者血液。
在上述方法的基础上,本发明也提供检测试剂盒,试剂盒容器内装有用以检测结核分枝杆菌H37Rv新的标准编码基因的试剂,与之同时提供的可以是经政府药物管理机构审核的、有关药品或生物制品的制造、使用及销售信息。例如,采用PCR扩增后,直接检测样品中Rv2003(-|2249260-2249457|)基因的试剂,例如可含有扩增引物、dNTP、用于PCR反应的DNA聚合酶及其缓冲液、酶切反应和/或测序反应所需试剂等的一种或多种。本领域技术人员已知,以上组分仅是示意性的,例如,所述引物可以采用上述特异性PCR引物,所述的用于PCR反应的DNA聚合酶是能够用于PCR扩增的酶。本发明的编码基因的检测也可以以集成的例如基因芯片的方式提供。
有益效果:本发明提供了一种用作结核分枝杆菌复合群(Mycobacterium tuberculosis complex,MTBC)分子鉴定的标准基因及分子鉴定方法,该基因能有效地将MTBC与同属的其它物种区分开来,应用该基因的鉴定方法克服了现有结核分枝杆菌复合群鉴定过程中的引物设计多重性、结果重复性差等缺点,具有通用、易扩增、易比对的特点,可以准确地将该类群从亲缘关系很近的其它分枝杆菌或其它呼吸道感染病菌中鉴定出来,为结核流行病学调查及临床结核病患者快速诊断、鉴别提供有力的技术手段和研究工具。
附图说明
图1:支持发现的新编码基因的肽谱匹配证据;
图2:合成肽段质谱图与原鉴定肽段质谱图对比;
图3:肽段坐落区域ORF编码的蛋白质序列对应图;下划线部分为蛋白质组学鉴定并被合成肽段验证的肽段;
图4:Rv2003(-|2249260-2249457|)标准基因序列同源性比较;
图5:H37Rv菌株Rv2003(-|2249260-2249457|)基因所对应的蛋白序列BLASTP结果;
图6:Rv2003(-|2249260-2249457|)特异引物PCR扩增产物琼脂糖凝胶电泳结果;
其中,各泳道样品信息见表1。
图7:Rv2003(-|2249260-2249457|)基因PCR扩增测序结果和标准序列比较。
具体实施方式
下面结合具体实施方式对本发明做进一步说明,但不限制本发明权利要求范围。本发明所用试剂均为市售。
实施例1:寻找H37Rv菌株基因组的漏注释编码基因
1.1对H37Rv菌株基因组的高覆盖蛋白质组验证
利用高覆盖蛋白质组技术对H37Rv菌株进行了蛋白质组的深度覆盖研究。基于Tuberculosis(20160307)数据库,使用pFind 3引擎对其基因组进行了注释编码基因验证。为了发现新的蛋白编码区,我们基于蛋白质基因组学技术,用pAnno软件对H37Rv在NCBI发表的全基因组(NC_000962.3)文件进行六阅读框数据库翻译,并利用这个数据库对质谱数据进行了新肽段和新蛋白质的鉴定。为了降低假阳性率,我们在数据过滤的过程中使用了3种对已注释肽段和新肽段分开估计类别FDR的过滤方法,分别是S-FDR,T-FDR I和T-FDR II。
经数据分析,我们共鉴定到3238个H37Rv已注释基因,覆盖度高达该菌株的80%以上,这是至今报道最大的H37Rv蛋白质谱数据。此外,经3种FDR≤1过滤后,我们获得新肽段。为了进一步确保新肽段质量,我们对上述过滤剩余的新肽段所对应的谱图进行了谱图质量筛选,最终保留了一些谱图质量好的肽段。为进一步排查这些谱图质量较高的肽段并非由于已注释肽段发生单个氨基酸突变所致,我们进行了氨基酸突变核查,确保这些新肽段为H37Rv新鉴定肽段。
1.2对Rv2003(-|2249260-2249457|)基因的编码蛋白和数据库验证
经过高覆盖蛋白质组验证后,我们发现一些疑似的新的漏注释肽段,对上述高可信得疑似新肽段进行肽段合成验证,据新肽段原始谱和肽段合成谱相似度打分≥0.8作为相似度阈值,经打分筛选后,有数条肽段通过验证,对应于新开放阅读框(Open Reading Frame,ORF),即目前的H37Rv菌株的潜在漏注释基因。
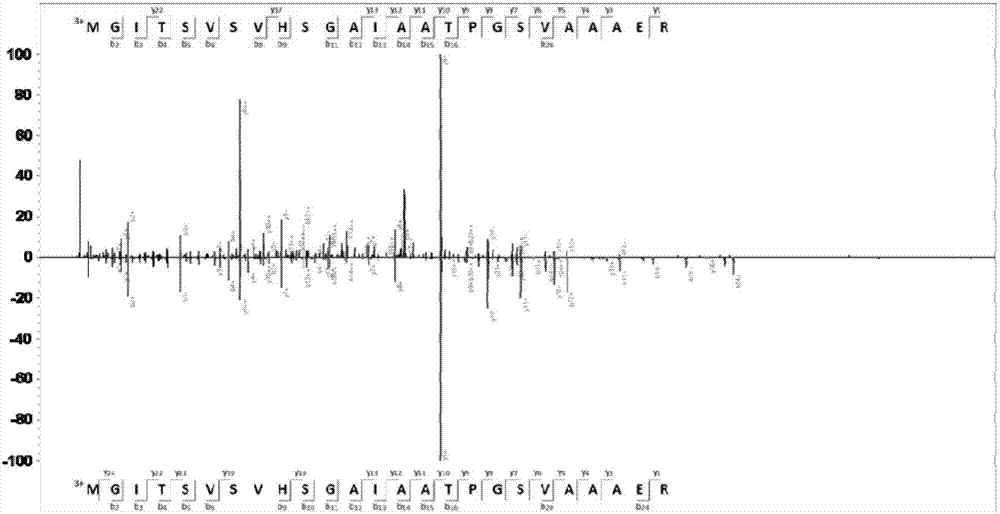
其中,我们发现新的漏注释基因Rv2003(-|2249260-2249457|),经BLASTP比较,与M.tuberculosis Bir 105相似性为100%,M.tuberculosis J09701920相似性为98%,M.canettii RefSeq(WP_041179674.1)的相似性为97%,其它物种相似性均低于77%,其功能注释蛋白是Phosphoenolpyruvate synthase。我们检测到肽段MGITSVSVHSGAIAATPGSVAAAER(SEQ ID NO.6),且对应于新基因Rv2003(-|2249260-2249457|),如图1所示,谱图质量很好,有连续5个b/y离子连续匹配,杂峰信号较低,结果很可信。
为进一步确证这个鉴定结果,我们按照我们新鉴定肽段的氨基酸序列化学合成了该肽段,并利用上述的质谱分析条件产生了该合成肽段的二级谱图。
我们对合成肽段产生的高能量碰撞MS2进行了核实,一级母离子和二级子离子均符合理论值,表明我们合成的肽段序列正确;在此基础上,我们手工检查了根据大规模蛋白质组数据鉴定到的新肽段序列的合成肽段的MS2和大规模鉴定新肽段谱图,两者几乎完全一致以子离子相似性获得的cosin值为0.87,证明我们从H37Rv中鉴定到的新肽段正确无误。(图2)。
在确认上述漏注释肽段的序列后,根据上述肽段所在的基因位置,以前一个终止密码子和后一个终止密码子包括的区域为界,得到包含上述新漏注释肽段的开放阅读框(ORF)DNA序列,如SEQ ID NO.2所示。
TGAGCGCTCCGTGGGACAGGCCTACCACATCTGGCGCAGCGCGATCTGAGAACGCCGAAAGGAAAACCGATGCCAACCATCACTGTCAGCAGCACATCGTCGCTGTGTGGTCAAGCGCTCTCGGGCAACCCGACTTTCGCCGAGCATCTGGTCCGGATGGGAATCACCTCAGTGTCGGTCCATTCGGGCGCGATTGCTGCTACCCCGGGGTCGGTCGCGGCCGCCGAACGCCGATTGTTGCTGGAATCAGCTCGCGGTGACGCCTGA(SEQ ID NO.2)
该开放阅读框编码与氨基酸序列的对应关系如图3所示。
进一步翻译验证,发现真实的基因序列(SEQ ID NO.1)从上述开放阅读框DNA(SEQ ID NO.2)中的ATG开始,共198bp,编码65个氨基酸,其理论分子量6.51kDa,即为Rv2003(-|2249260-2249457|)基因。
ATGCCAACCATCACTGTCAGCAGCACATCGTCGCTGTGTGGTCAAGCGCTCTCGGGCAACCCGACTTTCGCCGAGCATCTGGTCCGGATGGGAATCACCTCAGTGTCGGTCCATTCGGGCGCGATTGCTGCTACCCCGGGGTCGGTCGCGGCCGCCGAACGCCGATTGTTGCTGGAATCAGCTCGCGGTGACGCCTGA(SEQID NO.1)
该基因理论编码产物氨基酸序列如SEQ ID NO.3所示:
MPTITVSSTSSLCGQALSGNPTFAEHLVRMGITSVSVHSGAIAATPGSVAAAERRLLLESARGDA(SEQ ID NO.3)
对该SEQ ID NO.3所示理论基因编码产物的氨基酸顺序进行NCBI-BLASTP分析,与M.tuberculosis Bir 105相似性为100%,M.tuberculosis J09701920相似性为98%,M.canettii RefSeq(WP_041179674.1)的相似性为97%,其它物种相似性均低于77%,其功能注释蛋白是Phosphoenolpyruvate synthase(见图4)。表明我们检测到的Rv2003(-|2249260-2249457|)基因产物在H37Rv菌株数据库中被遗漏注释。
我们将该Rv2003(-|2249260-2249457|)基因的DNA序列进行比较基因组本地BLAST分析,如图5所示,结果表明Rv2003(-|2249260-2249457|)基因序列属于MTBC家族特异性基因,在其它物种中没有同源性较高的序列,这表明我们在H37Rv菌株中发现的Rv2003(-|2249260-2249457|)基因序列具有较好的序列特异性,可将MTBC与同属内其它分枝杆菌及其它呼吸道感染细菌区分开。
实施例2:建立鉴定MTBC复合群的方法
(1)设计引物:
基于如SEQ ID NO.1所示的Rv2003(-|2249260-2249457|)基因的CDS序列,采用Oligo7.0设计了PCR引物,引物序列如下:
F:5’-CCAACCATCACTGTCAGC-3’(SEQ ID NO.4);
R:5’-AGCAACAATCGGCGTTC-3’(SEQ ID NO.5)
上述引物在与Rv2003(-|2249260-2249457|)基因的位置关系如下所示,其中引物对应位置下标单划线。
ATGCCAACCATCACTGTCAGCAGCACATCGTCGCTGTGTGGTCAAGCGCTCTCGGGCAACCCGACTTTCGCCGAGCATCTGGTCCGGATGGGAATCACCTCAGTGTCGGTCCATTCGGGCGCGATTGCTGCTACCCCGGGGTCGGTCGCGGCCGCCGAACGCCGATTGTTGCTGGAATCAGCTCGCGGTGACGCCTGA
(SEQ ID NO.1)
(2)提取包括M.tuberculosis H37Rv在内的待测菌株的总DNA,40株分枝杆菌属标准菌株由中国医学细菌菌种保藏管理中心(CMCC)保藏,其余16株非结核分枝杆菌是中国人民解放军309医院临床分离株,已经完成菌种16SRNA基因测序、比对及NCBI序列提交工作,待测菌株如表1所示:
表1.选用的相关菌株
(3)扩增DNA片段,进行聚合酶链式(PCR)反应,所用上述F/R引物进行扩增。
PCR体系(25μL)为ddH2O(9.5μL)、2XTaq PCR MasterMix(TIANGEN,12.5μL)引物F(10μM,1μL)、引物R(10μM,1μL)、DNA模板(1μL);
扩增程序:94℃预变性3min、94℃变性30s、58℃退火30s、72℃延伸1min、35个循环,72℃延伸5min。
(4)扩增产物电泳检测,在琼脂糖凝胶、1×TBE电泳液中电泳检测。结果如图6所示,MTBC和对照组在170bp处出现了扩增条带,且实际扩增结果和预期相符,特异性为98.3%。
(5)为了进一步验证扩增的DNA的序列,我们对扩增序列进行了测序并和原序列比较,如图7所示,结果与预期完全相符,序列正确无误,这进一步验证了新漏注释基因的存在。
这表明基于Rv2003(-|2249260-2249457|)基因进行MTBC复合群鉴定的方法真实可靠。
SEQUENCE LISTING
<110> 北京蛋白质组研究中心
<120> 结核分枝杆菌H37Rv编码基因及其应用
<130> BJ1936-17P121796
<160> 6
<170> PatentIn version 3.3
<210> 1
<211> 198
<212> DNA
<213> Artificial
<220>
<223> 结核分枝杆菌H37Rv编码基因Rv2003(-|2249260-2249457|)
<400> 1
atgccaacca tcactgtcag cagcacatcg tcgctgtgtg gtcaagcgct ctcgggcaac 60
ccgactttcg ccgagcatct ggtccggatg ggaatcacct cagtgtcggt ccattcgggc 120
gcgattgctg ctaccccggg gtcggtcgcg gccgccgaac gccgattgtt gctggaatca 180
gctcgcggtg acgcctga 198
<210> 2
<211> 267
<212> DNA
<213> Artificial
<220>
<223> 包含漏注释肽段的开放阅读框DNA序列
<400> 2
tgagcgctcc gtgggacagg cctaccacat ctggcgcagc gcgatctgag aacgccgaaa 60
ggaaaaccga tgccaaccat cactgtcagc agcacatcgt cgctgtgtgg tcaagcgctc 120
tcgggcaacc cgactttcgc cgagcatctg gtccggatgg gaatcacctc agtgtcggtc 180
cattcgggcg cgattgctgc taccccgggg tcggtcgcgg ccgccgaacg ccgattgttg 240
ctggaatcag ctcgcggtga cgcctga 267
<210> 3
<211> 65
<212> PRT
<213> Artificial
<220>
<223> Rv2003(-|2249260-2249457|)基因理论编码产物氨基酸序列
<400> 3
Met Pro Thr Ile Thr Val Ser Ser Thr Ser Ser Leu Cys Gly Gln Ala
1 5 10 15
Leu Ser Gly Asn Pro Thr Phe Ala Glu His Leu Val Arg Met Gly Ile
20 25 30
Thr Ser Val Ser Val His Ser Gly Ala Ile Ala Ala Thr Pro Gly Ser
35 40 45
Val Ala Ala Ala Glu Arg Arg Leu Leu Leu Glu Ser Ala Arg Gly Asp
50 55 60
Ala
65
<210> 4
<211> 18
<212> DNA
<213> Artificial
<220>
<223> F引物序列
<400> 4
ccaaccatca ctgtcagc 18
<210> 5
<211> 17
<212> DNA
<213> Artificial
<220>
<223> R引物序列
<400> 5
agcaacaatc ggcgttc 17
<210> 6
<211> 25
<212> PRT
<213> Artificial
<220>
<223> 漏注释肽段
<400> 6
Met Gly Ile Thr Ser Val Ser Val His Ser Gly Ala Ile Ala Ala Thr
1 5 10 15
Pro Gly Ser Val Ala Ala Ala Glu Arg
20 25
- 还没有人留言评论。精彩留言会获得点赞!
- 一种敲除c‑di‑AMP分解酶的重组耻垢分枝杆菌株及其应用的制造方法与工艺
- 检测结核分枝杆菌感染的抗原多肽池及其应用的制造方法与工艺
- 一种猕猴桃分枝定位器的制造方法与工艺
- 一种xanthone类化合物及其单晶的制备方法与作为抗海分枝杆菌药物的应用与制造工艺
- 一种糖肽类抗生素耐药基因检测试剂盒的制造方法与工艺
- 分枝杆菌快速分离培养方法与制造工艺
- 一种用于检测潜在结核的特异性标志物及其应用的制造方法与工艺
- 结核分枝杆菌抗原蛋白Rv2941及其T细胞表位肽的应用的制造方法与工艺
- 一种微流控芯片上基于荧光量子点磁性富集并分离结核分枝杆菌TB的方法及装置与制造工艺
- 二肽meso‑DAP‑D‑Ala和/或四肽L‑Ala‑D‑Glu‑L‑Lys‑D‑Ala的新用途的制造方法与工艺