用于高通量测序的文库构建方法及高通量测序方法与流程
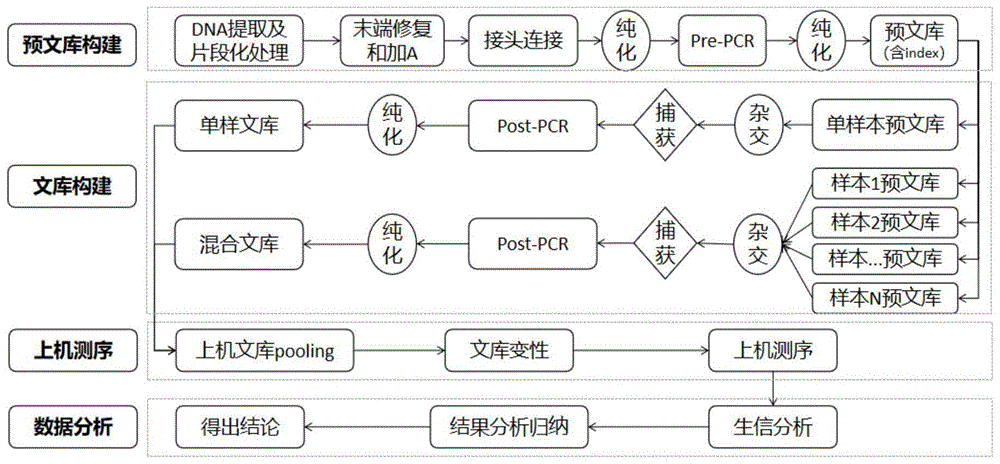
本发明涉及生物领域。具体地,本发明涉及用于高通量测序的文库构建方法及高通量测序方法。
背景技术:
:随着科学技术的进步,高通量测序(ngs)已经发展到了商业化应用阶段,应用范围非常广泛,主要可分为科研服务和医疗服务。其中医疗服务主要是通过对接各个医院科室和医生患者,为广大的患者和健康人提供基因检测服务,如孕妇的产前诊断、癌症早筛、精准用药、免疫治疗等方面。高通量测序极大地加速了基因组学研究的进展和助力了肿瘤等疾病的精准诊断。全基因组测序或者全外显子测序可以提供更全面的基因组学信息,但是也存在测序深度低、测序成本高、不利于靶标基因的深度挖掘和高灵敏度检测、适用人群窄等缺点,不利于推广应用。靶向基因组测序是一种只捕获富集样本目标区域基因组测序技术。靶向富集的方法分为探针捕获和多重pcr富集。探针捕获常规方法是将样本打断构建一个全基因组文库,然后利用探针进行杂交和捕获,然后上机测序,从而得到目标区域基因序列信息。相较而言,基于探针捕获的ngspanel特异性检测和某种疾病相关的靶标基因,既能同时检测单核酸突变、小片段插入或缺失、结构变异和拷贝数变异等多种类型的基因变异,也能对靶标基因进行深度测序,从而对一些突变频率低的靶标基因进行高灵敏度和高精确度检测,为相关疾病进行更精确的用药指导和预后分析指导。其测序成本相对全基因组测序和全外显子测序要低很多,因此适用人群广,具有更好的市场应用前景。安捷伦是最早将探针捕获法应用到ngs测序服务中的生物公司,目前经过近十年的发展完善,其sureselect探针捕获平台已经在ngs测序市场占据较大的比重。文库制备是ngs的前期关键步骤,文库制备的质量对测序结果有着决定性作用。sureselect目前关于微量起始核酸文库构建的实验流程一般都包括采样、运输、收样、核酸提取、文库构建、上机测序、数据分析和报告生成等流程,其中占检测成本较高的实验步骤是捕获建库和上机测序。当前存在的技术难题是:1、建库流程繁琐,整个实验流程耗时长,从接收样本到出具检验报告,往往需要7-14天的时间;2、单人可操作的样本量有限,一个人可操作性的样本数量平均为20个,当样本数量过多时,往往需要更多的实验操作员、实验操作空间、实验操作设备等;3、样本建库成本高,一个样本建库的成本在数百到数千人民币不等,检测费用的增加降低了高通量测序的普及性,不利于高通量测序技术的推广应用。因此,目前用于高通量测序的文库构建方法及高通量测序方法仍有待研究。技术实现要素:本发明旨在至少在一定程度上解决现有技术中存在的技术问题至少之一。为此,本发明提出了用于高通量测序的文库构建方法及高通量测序方法,该文库构建方法可以有效地提高建库效率,降低建库成本,适于规模化应用。在本发明的一个方面,本发明提出了一种用于高通量测序的文库构建方法。根据本发明的实施例,所述方法包括:(1)将至少两种dna样品分别进行步骤(1-1)至(1-4)的操作:(1-1)将所述dna样品进行末端修复,以便获得经过末端修复的dna片段;(1-2)在所述经过末端修复的dna片段的3’末端添加碱基a,以便获得具有粘性末端a的dna片段;(1-3)将所述具有粘性末端a的dna片段与接头相连,以便获得连接产物;(1-4)将所述连接产物进行预扩增及纯化,以便得到预扩增产物;(2)将分别得到的所述预扩增产物进行混合,并将得到的总预扩增产物与探针进行杂交捕获,以便得到目的片段;(3)将所述目的片段进行扩增及纯化,以便得到混合文库;其中,基于3μg所述总预扩增产物,所述探针的添加量为2~4μl。根据本发明实施例的用于高通量测序的文库构建方法预先将经过末端修复、3’末端添加碱基a的dna片段与接头相连,从而添加标签序列,便于在后续多种预扩增产品混合后起到识别作用。然后,将所得到的连接产物进行预扩增及纯化,从而纯化目标片段。接着,将多种不同来源的预扩增产物进行混合,并用探针将混合的预扩增产物进行杂交捕获,从而特异性地获得目标片段,再对该目标片段进行扩增及纯化,从而获得混合文库。由此,相比于对单个样品单独进行杂交捕获以构建文库,本申请采用多个样品混合杂交捕获以构建混合文库具有用时短、效率高、准确性强等优点。进一步地,发明人发现,采用多个预扩增产物混合杂交捕获时,所需要的探针量明显少于多个样品单独杂交捕获累加的添加量,例如,4个预扩增产物单独进行杂交捕获,总共需要近8μl的探针,将这4个预扩增产物混合进行杂交捕获,总共仅需2μl,由此,可以减少探针的使用量,降低成本。进而,发明人经过的大量实验优化总预扩增产物与探针的添加量之间的关系,发现基于3μg总预扩增产物,探针的添加量为2~4μl时,探针能够特异性地捕获目标dna片段,且保证添加量较低。由此,根据本发明实施例的用于高通量测序的文库构建方法可以有效地提高建库效率,降低建库成本,适于规模化应用。根据本发明的实施例,所述用于高通量测序的文库构建方法还可以具有下列附加技术特征:根据本发明的实施例,步骤(2)中,进行杂交捕获的所述总预扩增产物的体积为14μl,当进行所述混合所得到的混合液体积大于14μl时,将所述混合液浓缩至14μl,以便得到所述总预扩增产物;当进行所述混合所得到的混合液体积小于14μl时,用无酶水将所述混合液补足至14μl,以便得到所述总预扩增产物。由此,可以满足杂交捕获的要求,提高捕获的特异性,从而提高混合文库的准确性。根据本发明的实施例,针对din小于4的样品,所得混合文库中所述样品的文库的捕获效率为10~20%,umi利用率为32~45%,文库复杂度为10~14%,平均测序深度为550~1200。由此,对于低质量的样品,采用混合建库方式可以提高所得文库的质量。根据本发明的实施例,针对din不小于4且小于6的样品,所得混合文库中所述样品的文库的捕获效率为28~33%,umi利用率为46~50%,文库复杂度为12.5~13%,平均测序深度为2400~2600。由此,对于中等质量的样品,采用混合建库方式可以提高所得文库的质量。根据本发明的实施例,针对din大于6且不大于10的样品,所得混合文库中所述样品的文库的捕获效率为35~40%,umi利用率为38~52%,文库复杂度为12~14%,平均测序深度为3200~4000。由此,对于高质量的样品,采用混合建库方式可以提高所得文库的质量。在本发明的又一方面,本发明提出了一种高通量测序方法。根据本发明的实施例,所述方法包括:利用前面所述高通量测序建库方法得到混合文库;将所述混合文库上机测序。由此,根据本发明实施例的高通量测序方法可以有效地提高测序效率,降低测序成本,适于规模化应用。本领域技术人员能够理解的是,前面针对用于高通量测序的文库构建方法同样适用于该高通量测序方法,在此不再赘述。本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。附图说明本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:图1显示了根据本发明的一个实施例的构建文库方法流程示意图;图2显示了根据本发明一个实施例的混合预扩增文库构建和单样预扩增文库构建的捕获效率分析示意图;图3显示了根据本发明一个实施例的混合预扩增文库构建和单样预扩增文库构建的文库复杂度分析示意图;图4显示了根据本发明一个实施例的混合预扩增文库构建和单样预扩增文库构建的umi利用率分析示意图;图5显示了根据本发明一个实施例的混合预扩增文库构建和单样预扩增文库构建的平均测序深度分析示意图;图6显示了根据本发明一个实施例的4种不同质量类型的ffpe的核酸分布示意图;图7显示了根据本发明一个实施例的4种不同质量类型的ffpe的din值示意图;具体实施方式下面将结合实施例对本发明的方案进行解释。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件的,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用试剂或仪器未注明生产厂商者,均为可以通过市购获得的常规产品。实施例1实施例1提供一种通过新型的ngs建库方法,流程参见图1,主要包括以下步骤,:1、选取健康人血浆cfdna(实验室自供)、血细胞gdna(实验室自供)和突变细胞系h1650(购自中科院)的混合配制的4种不同质量的核酸样本,样本实验编号为r9105137和r9105141(cfdna:gdna=2:1),r9105138和r9105142(cfdna:gdna=1:3)、r9105139和r9105143(cfdna:gdna=1:9)、r9105140和r9105144(cfdna:gdna=1:0)其中,cfdna比例越高,样品质量越好。样本浓度为1ng/μl,取样30μl,用无酶水补齐至50μl;2、使用covariss220超声破碎仪对上述样品进行打断,最终得到200bp左右的dna片段;3、采用安捷伦的建库试剂盒sureselectxths建库试剂盒前端试剂进行末端修复、加a;4、通过接头连接酶和试剂在上一步的产物中添加携带umi分子标签的接头;5、使用ampure磁珠对连接产物进行纯化,最终得到35μl的纯化后的接头连接产物;6、文库预扩增a、于冰上配置pcr反应混合液,具体配置成分和用量见下表,涡旋震荡混匀;表1预扩增体系反应体系体积μl5×herculaseiireactionbuffer(clearcap)10100mmdntpmix(greencap)0.5forwardprimer(browncap)2herculaseiifusiondnapolymerase(redcap)1total13.5ulb、将接头连接后的产物和反应混合液充分混合;c、为每个样本编排不同的index号,每个样本管中加入编排好的index引物;d、设置运行程序,pcr仪预热后,放入样品,继续运行程序;e、用ampurexp磁珠纯化样品;f、用无酶水洗脱磁珠;7、使用ampure磁珠对预扩增文库进行纯化,最终得到15μl的纯化后的预扩增文库;8、采用qubit3.0和agilent2100对预扩增文库进行质量检测;9、采用基因特异性探针利用sureselect探针捕获平台对预扩增文库进行杂交捕获,具体步骤如下:a、将带有独一无二的umi和index的预扩增文库按照每样750ng进行单样/混合建库;b、当单样预扩增文库/混合预扩增文库体积大于14μl时,浓缩至14μl,以便得到总预扩增产物;当进行单样预扩增文库/混合预扩增文库小于14μl时,用无酶水补足至14μl,以便得到单样预扩增产物/总预扩增产物;c、单样预扩增产物/总预扩增产物和5ulsureselectxthsandxtlowinputblockermix进行混合离心;d、设置杂交捕获pcr程序,放入样品,运行程序;运行至65℃,1分钟时,暂停程序;e、制备sureselectrnaseblock稀释液和杂交混合液,涡旋震荡混匀5s后简短离心;f、预扩增文库和blockermix混合物留在65℃,加入杂交混合液,吹吸8-10次混匀;简短离心后,放回pcr仪中继续运行程序;g、清洗链霉亲和素磁珠:剧烈震荡混匀链霉亲和素磁珠,每样每管分装50μl磁珠;加入200ulsureselectbindingbuffer,吹吸混匀20次,放入磁力架,溶液澄清后,取上清;重复再洗2次,共3次;加入200μlsureselectbindingbuffer重悬磁珠;h、步骤f产物完全转移到含有200μl步骤g洗好的磁珠中,缓慢吹吸5-8次;i、混合液25℃,1500rpm混匀30min;恒温振荡混匀仪调整至70℃预热sureselectwashbuffer2;j、混合液简单离心后,放入磁力架,溶液澄清后去上清;k、sureselectwashbuffer2热清洗磁珠,清洗步骤需保证磁珠悬浮液在70℃;加入200μl70℃预热的sureselectwashbuffer2,吹吸混匀15-20次;70℃孵育5min;简短振荡后离心,离心管放入磁力架,溶液澄清后,去上清;重复清洗5次,共6次,最后一次确保尽弃上清;l、加入无酶水后,吹吸重悬磁珠后放冰上;10、文库扩增a、于冰上配置pcr反应混合液,涡旋震荡混匀;b、将接头连接后的产物和反应混合液充分混合;c、设置扩增反应程序,放入样品,运行pcr仪器;11、扩增得到的文库用ampure磁珠进行纯化12、用qubit2.0和agilent2100bioanalyzer检测文库质量和摩尔浓度;13、样本pooling,在hiseqxten仪器上进行测序;14、测序数据统计分析。实验结果如下:新型的混合预扩增文库构建和传统的单样预扩增文库构建的捕获效率对比见附图2,其中图2中纵坐标代表液相杂交捕获效率,捕获效率是影响测序深度和数据产出的主要参数之一,捕获效率越高,测序数据产出越高,结果判读越准确。从附图2中可以看出,混合预扩增文库杂交捕获建库的捕获效率均显著优于单样预扩增文库。新型的混合预扩增文库构建和传统的单样预扩增文库构建的文库复杂度对比见附图3,其中图3中纵坐标代表文库复杂度,文库复杂度是衡量一个样本数据有效性的重要指标,文库复杂度越高,表明测序数据的有效性越高,从而可以有效地提高实验成功率。从附图3中可以看出混合预扩增文库杂交捕获建库的文库复杂度均优于单样预扩增文库。新型的混合预扩增文库构建和传统的单样预扩增文库构建的umi利用率对比见附图4,其中图4中纵坐标代表umi利用率,umi利用率是带有umi分子标签的reads数和产生的总reads数的占比,umi利用率越高,代表测序数据中含有umi分子标签的数据量越高,有效数据产出占比越高。从附图4中可以看出混合预扩增文库杂交捕获建库的umi利用率均显著优于单样预扩增文库。新型的混合预扩增文库构建和传统的单样预扩增文库构建的平均测序深度对比见附图5,其中图5中纵坐标代表平均测序深度,平均测序深度可以有效提高测序数据的有效性,降低测序成本。从附图5中可以看出混合预扩增文库杂交捕获建库的平均测序深度均显著优于单样预扩增文库。以上实验共采用了4种不同质量的混合样本分别进行单样预扩增文库杂交捕获和混合预扩增文库杂交捕获,从结果上来看,四种不同质量的样本混合预扩增文库杂交建库的方法在捕获效率、文库复杂度、umi利用率和平均测序深度均优于单样预扩增文库杂交捕获。实施例2实施例2提供了一种不同质量ffpe样本的新型的ngs建库方法,主要包括以下步骤:1、选取4种不同质量的石蜡包埋的组织样本(ffpe),分别进行混合预扩增文库建库和单样预扩增文库建库,实验编号分别为r9105221和r9105225(低质量的ffpe样本1,样本编号p9102334),r9105222和r9105227(低质量的ffpe样本2,样本编号为p9102335),r9105223和r9105228(中等质量的ffpe样本3,样本编号p9102448),r9105224和r9105229(高质量的ffpe样本4,样本编号为p9103033),每样取30ng,用无酶水补齐至50ul;2、按照实施例1的步骤2~14进行操作。实验结果如下:从附图6核酸分布图来看,四种样本具有比较大质量差异,其中根据附图中片段分布可知,四种样本的质量排序如下:低质量的ffpe样本1<低质量的ffpe样本2<中等质量的ffpe样本3<高质量的ffpe样本4。质量的高低取决于核酸的完整度(din,dnaintegritynumber),在ffpe样本中,由于石蜡包埋处理、样本常温保存、核酸提取过程中均会对样本质量产生影响,因此设定din值在6-10之间为高质量样本,din值为大于等于4且小于6之间为中等质量样本,din值小于4为低质量样本。由图7所示,高质量的ffpe样本4(p9103033)的din为6.4,中等质量的ffpe样本3(p9102448)的din值为5.7,低等质量的ffpe样本2(p9102335)2的din值为2.7,低等质量的ffpe样本1(p9102334)的din值为2.2。低质量的ffpe样本建库测序效果差主要表现在文库构建和上机测序结果上,通过总预扩增文库混合建库可以改善低质量ffpe样本文库构建和上机测序效果,从而提高检出结果的准确性和精密性。4种不同质量类型的ffpe样本的混合预扩增文库建库和单样预扩增文库的测序数据对比结果见表1,从表中可以看出四种不同质量的ffpe样本,混合预扩增文库建库的捕获效率、umi利用率、文库复杂度和平均测序深度均优于单样预扩增文库建库。表2混合文库特点在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1