用于治疗结晶样视网膜变性的核酸分子及其用途的制作方法
本申请涉及生物医药领域,具体的涉及一种用于基因编辑治疗结晶样视网膜变性的grna和供体核酸分子。
背景技术:
:结晶样视网膜变性((bietticrystallinedystrophy,bcd),又名为结晶样视网膜色素变性、结晶样角膜视网膜变性(bietticrystallinecorneoretinaldystrophy)、结晶样视网膜病变(bietticrystallineretinopathy)、bietti视网膜变性(bietti'sretinaldystrophy))是一种致盲性的常染色体隐性遗传性视网膜变性疾病。cyp4v2基因是目前发现的bcd致病基因之一(li等,amjhumgenet.74:817-826,200)。cyp4v2属于细胞色素p450超家族,是亚铁血红素—硫醇盐蛋白细胞色素p450亚家族4(cyp4)的成员。目前,有多种治疗该病的方法,例如基因替代治疗方案,即使用病毒转染系统或者其他转染系统(如aav、慢病毒、逆转录病毒),将cyp4v2野生型基因转染到基因突变的细胞中,使基因突变细胞可以表达野生型cyp4v2。这种做法仅可以部分恢复突变细胞功能,并且疗效有限。原因为突变型的基因产物仍然存在于细胞中,这些突变蛋白会与正常基因产物存在竞争性抑制作用。因此,更加安全有效的治疗方法亟待被发现。公开于该
背景技术:
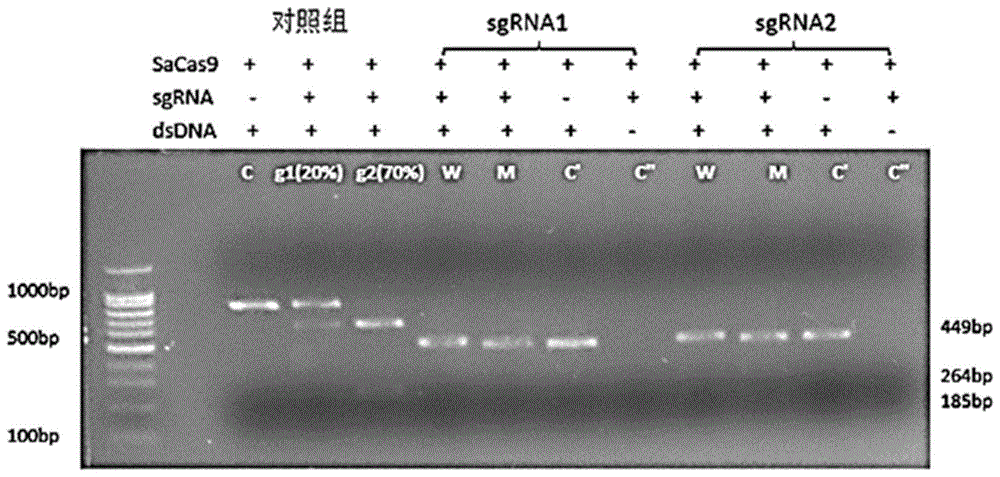
部分的信息仅仅旨在增加对本申请的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。技术实现要素:本申请提供了特异性靶向细胞色素p450家族4亚家族v多肽2(cyp4v2)的grna,其特异性靶向c.802-8_810del17bpinsgc突变位点,所述grna对所述突变位点具有好的切割效果,使得原先突变的cyp4v2基因产物不存在于细胞中。本申请还提供了一种供体核酸分子,其包含了不含c.802-8_810del17bpinsgc突变位点的正确的cyp4v2的核苷酸序列,所述供体核酸分子可以在内源性cyp4v2被所述grna剪切后,在基因突变细胞中修复cyp4v2的突变位点,产生了具有正常功能的cyp4v2蛋白,具有很好修复效果。本申请提供了一种包含所述grna和/或所述供体核酸分子的载体,能够使cyp4v2突变的细胞表达正确的细胞色素p450家族4亚家族v多肽2,具有良好的基因编辑修复效率。一方面,本申请提供了一种特异性靶向细胞色素p450家族4亚家族v多肽2(cyp4v2)基因的grna,其特异性结合c.802-8_810del17bpinsgc突变位点上下200bp内的核苷酸序列。在某些实施方式中,所述的grna包含seqidno:74、78-80、82-84中任一项所示的核苷酸序列。在某些实施方式中,所述的grna包含5’-(x)n-seqidno:74、78-80、82-84-骨架序列-3’,其中x为选自a、u、c和g中任一个的碱基,且n为0-15中的任一整数。在某些实施方式中,所述grna为单链向导rna(sgrna)。另一方面,本申请提供了一种或多种分离的核酸分子,其编码所述的特异性靶向cyp4v2基因的grna。另一方面,本申请提供了供体核酸分子,其包含cyp4v2基因c.802-8_810del17bpinsgc突变位点上下800bp内正常野生型的核苷酸序列。在某些实施方式中,所述的核酸分子包含seqidno:64-66中任一项所示的核苷酸序列。另一方面,本申请提供了一种载体,其包含所述的分离的核酸分子和/或所述的供体核酸分子。在某些实施方式中,所述分离的核酸分子和所述供体核酸分子位于同一载体中。在某些实施方式中,所述的载体为病毒载体。另一方面,本申请提供了细胞,其包含所述的分离的核酸分子、所述的供体核酸分子和/或所述的载体。在某些实施方式中,所述的细胞包括hek293细胞、肾上皮细胞和/或诱导性多能干细胞。在某些实施方式中,所述的细胞经修饰后具备分化能力。在某些实施方式中,所述的细胞可分化为3d-视网膜类器官。另一方面,本申请提供了药物组合物,其包含所述的grna,所述的一种或多种分离的核酸分子,所述的供体核酸分子,和/或所述的载体,以及药学上可接受的载剂。另一方面,本申请提供了所述的grna,所述的一种或多种分离的核酸分子,所述的供体核酸分子,和/或所述的载体在制备治疗疾病的药物中的应用,其中所述疾病包括cyp4v2基因中c.802-8_810del17bpinsgc突变所导致的疾病。在某些实施方式中,所述疾病包括结晶样视网膜变性。另一方面,本申请提供了一种治疗结晶样视网膜变性的方法,所述方法包括以下的步骤:向有需要的受试者导入所述grna,所述的一种或多种分离的核酸分子,所述的供体核酸分子,和/或所述的载体。在某些实施方式中,所述导入获得了正常功能的cyp4v2蛋白。在某些实施方式中,所述导入包括注射。在某些实施方式中,其中所述导入包括视网膜下腔注射。另一方面,本申请提供了一种调节细胞中cyp4v2基因表达的方法,其包括向细胞导入所述的grna,所述的一种或多种分离的核酸分子,和/或所述的载体。本领域技术人员能够从下文的详细描述中容易地洞察到本申请的其它方面和优势。下文的详细描述中仅显示和描述了本申请的示例性实施方式。如本领域技术人员将认识到的,本申请的内容使得本领域技术人员能够对所公开的具体实施方式进行改动而不脱离本申请所涉及发明的精神和范围。相应地,本申请的附图和说明书中的描述仅仅是示例性的,而非为限制性的。附图说明本申请所涉及的发明的具体特征如所附权利要求书所显示。通过参考下文中详细描述的示例性实施方式和附图能够更好地理解本申请所涉及发明的特点和优势。对附图简要说明如下:图1a显示的是本申请所述sgrna1-2对所述突变基因的dsdna剪切结果;图1b显示的是本申请所述sgrna3-5对所述突变基因的dsdna剪切结果;图1c显示的是本申请所述sgrna6-8对所述的突变基因的dsdna剪切结果;图1d显示的是本申请所述sgrna9-11对所述的突变基因的dsdna剪切结果;图1e显示的是本申请所述sgrna12-14对所述的突变基因的dsdna剪切结果;图1f显示的是本申请所述sgrna15对所述的突变基因的dsdna剪切结果;图1g显示的是本申请所述sgrna16-19对所述的突变基因的dsdna剪切结果;图1h显示的是本申请所述sgrna20-22对所述的突变基因的dsdna剪切结果;图1i显示的是本申请所述sgrna23对所述的突变基因的dsdna剪切结果。图2显示的是本申请所述aav-sacas9-puro载体的质粒图谱。图3显示的是经sgrna8、sgrna12、sgrna13、sgrna14、sgrna16、sgrna17、sgrna18切割后片段t7e1酶切实验的结果。图4a显示的是sgrna13切割后基因组dna包含切割位点的pcr片段基因测序结果,图4b显示的是sgrna17切割后基因组dna包含切割位点的pcr片段基因测序结果,图4c显示的是sgrna18切割后基因组dna包含切割位点的pcr片段基因测序结果。图5显示的是sgrna13、sgrna17、sgrna18、sgrna13+17、sgrna13+18在293t细胞中的切割效率的柱形图。图6显示的是donor序列的设计图。具体实施方式以下由特定的具体实施例说明本申请发明的实施方式,熟悉此技术的人士可由本说明书所公开的内容容易地了解本申请发明的其他优点及效果。术语定义在本申请中,术语“cyp4v2”通常是指一种蛋白质,其为细胞色素p450家族4亚家族v成员2。术语“细胞色素p450”,也称作cytochromep450或cyp450,通常是指一类亚铁血红素蛋白家族,属于单氧酶的一类,参与内源性物质或包括药物、环境化合物在内的外源性物质的代谢。根据氨基酸序列的同源程度,其成员又依次分为家族、亚家族和酶个体三级。细胞色素p450酶系统可以缩写为cyp,其中家族以阿拉伯数字表示,亚家族以大写英文字母表示,酶个体以阿拉伯数字表示,例如本申请中的cyp4v2。人cyp4v2基因(hgnc:23198;ncbiid:285440)全长通常为19.28kb,位于4q35,具有11个外显子,在脂肪酸代谢中发挥重要作用(kumars.,bioinformation,2011,7:360-365)。本申请所述的cyp4v2还可包括其功能性变体、片段、同源物等。cyp4v2几乎在所有组织中表达,但是在视网膜和视网膜色素上皮中以高水平表达,而在角膜组织中以稍低的水平表达。cyp4v2基因的突变可能与结晶样视网膜变性和/或视网膜色素变性有关。在本申请中,术语“c.802-8_810del17bpinsgc”是比较常见的一种cyp4v2基因突变,属于内含子6的3’末端和外显子7的5’末端17对碱基对的移除,从而导致外显子7的缺失,导致转录蛋白的结构和活性变化。示例性的野生型cyp4v2的内含子6与外显子7之间的序列可以如下:caaacagaagcatgtgattatcattcaaatcatacaggtcatcgctgaacgggccaatgaaatgaacgccaatga(seqidno:90)。示例性的c.802-8_810dell7insgc突变序列可以如下所示,内含子6序列与外显子7之间的序列缺失了17个bp缺失(在野生型中用大写字母表示的序列),而插入了gc(用大写字母表示):caaacagaagcatgtgattatcattcaaagcgaacgggccaatgaaatgaacgccaatga(seqidno:91)。(xiao等,biochembiophysrescommun.409:181-6,2011;meng等,2014,mol.vis.,20:1806-14;wada等,amjophthalmol.139:894-9,2005;jiao等,europeanjournalofhumangenetics(2017)25,461-471。)。在本申请中,所述“c.802-8_810del17bpinsgc突变位点”可以在seqidno:91所示的核苷酸序列中缺失的部分,或增加cg的位置处。“c.802-8_810del17bpinsgc突变位点上下800bp内”可以包括在caaacagaagcatgtgattatcattcaaatcatacaggtcatcgctgaacgggccaatgaaatgaacgccaatga(seqidno:90)中,与大写字母标识的核苷酸序列的n端相连的碱基(即“a”)处,往5’端方向约800bp内的核苷酸,或者,也可以包括与大写字母标识的核苷酸序列的c端相连的碱基(即“g”)处,往3’端方向约800bp内的核苷酸。在本申请中,术语“突变”通常是指特定蛋白质或核酸(基因,rna)分别相对于野生型蛋白质或核酸的氨基酸或核酸序列的差异。突变的蛋白质或核酸可以由基因的一个等位基因(杂合的)或两个等位基因(纯合的)表达或者在其中找到。突变包括缺失突变、截短、失活、破坏、置换突变或易位。这些类型的突变是本领域众所周知的。在本申请中,与cyp4v2突变相关的,包括但不限于错义(missense)、重复、剪接位、框移、删除、插入、插入或缺失(indel)、无义、多态性(例如单核苷酸多肽性)及提前终止(prematuretermination)以及cyp4v2基因整体缺失。在本申请中,术语“分离的核酸分子”是其与存在于所述核酸的天然来源中的其他核酸分子相分离。这种分离的核酸分子从其通常的或天然的环境中移出的或分离的,或者生产所述分子的方式使其不存在于其通常的或天然的环境中,其与通常的或天然的环境中的多肽、肽、脂质、糖类、其他的多核苷酸或其它材料分离。本申请中的分离的核酸分子可编码rna,例如,可编码特异性靶向cyp4v2基因的grna。在本申请中,术语“供体核酸分子”通常是指向受体(例如,接收核酸分子)提供异源核酸序列的核酸分子。在本申请中,术语“骨架序列”通常是指grna中,除识别或杂交靶序列的部分的其他部分,可包括sgrna中grna配对序列与转录终止子之间的序列。骨架序列一般不会因为靶序列的变化而变化,也不影响grna对靶序列的识别。因此,骨架序列可以是现有技术中任何可行的序列。骨架序列的结构可参见如文献nowaketal.nucleicacidsresearch2016.44:9555-9564中的figure1(图1)中a和b,figure3(图3)中a、b、c,以及figure4(图4)中a、b、c、d、e中所记载的除spacer序列之外的部分。在本申请中,术语“载体”通常是指能够在合适的宿主中自我复制的核酸分子,其能够将插入的核酸分子(例如,外源性序列)转移到宿主细胞中和/或宿主细胞之间。所述载体可包括主要用于将dna或rna插入细胞中的载体、主要用于复制dna或rna的载体,以及主要用于dna或rna的转录和/或翻译的表达的载体。所述载体还包括具有多种上述功能的载体。所述载体可以是当引入合适的宿主细胞时能够转录并翻译成多肽的多核苷酸。通常,通过培养包含所述载体的合适的宿主细胞,所述载体可以产生期望的表达产物。本申请所述的载体可以包括,例如,表达载体,可包括病毒载体(慢病毒载体和/或逆转录病毒载体),噬菌体载体,噬菌粒,粘粒,cosmid,人工染色体如酵母人工染色体(yac)、细菌人工染色体(bac)或p1来源的人工染色体(pac),和/或质粒。在本申请中,术语“grna”通常是指向导rna(guiderna),一种rna分子。在自然界中,crrna和tracrrna通常作为两个独立的rna分子存在,组成grna。术语“crrna”也称为crisprrna,通常是指与所靶向的目标dna互补的一段核苷酸序列,术语“tracrrna”通常是指可与cas核酸酶结合的支架型rna。crrna和tracrna也可以融合成为单链,此时grna也可称为单链向导rna(singleguiderna,sgrna),sgrna已成为本领域技术人员在crispr技术中使用的grna的最常见的形式,因此术语“sgrna”和“grna”在本文中可具有相同的含义。sgrna可以人工合成,也可以在体外或体内由dna模板制备。sgrna可以结合cas核酸酶,也可以靶向目标dna,其可引导cas核酸酶切割与grna互补的dna位点。在本申请中,术语“特异性靶向”通常是指两种分子(例如,分子a和分子b)之间的相互作用(例如,分子a特异性识别和/或结合分子b(如,靶标))。同与其他非b分子的相互作用相比,分子a以统计学显著的程度与分子b相互作用。所述相互作用可以是共价的或非共价的。当涉及多核苷酸时,特异性靶向可以指分子a(或其一条链)与分子b(或其一条链)具有碱基互补配对的关系。在本申请中,“特异性靶向”可以指grna识别和/或结合至靶序列的过程。在本申请中,术语“靶核酸”、“靶核酸”、“靶序列”和“靶区域”可以互换的使用,通常是指可以被grna识别的核酸序列,所述靶核酸可以指双链核酸,也可以指单链核酸。在本申请中,术语“3d-视网膜类器官”通常是指一种具有三维结构、能够自我更新、自我组织并显示视网膜基本功能(例如,感受光)的人工培育的视网膜。3d-视网膜类器官可以由原代组织或干细胞(例如,多功能干细胞)分化而成,具有视网膜中所有接收光线并向大脑发出信号所必需的细胞。在本申请中,术语“结晶样视网膜变性”通常是指一类常染色体隐性遗传眼病。其主要症状包括角膜中的晶体(透明覆盖物),沉积在视网膜的光敏组织中的细小、黄色或白色晶体状的沉积物,以及视网膜、脉络膜毛细血管和脉络膜的进行性萎缩。结晶样视网膜变性可以包括由cyp4v2基因突变引起的疾病。在本申请中,术语“视网膜下腔注射”通常是指将需要导入的物质导入到感光细胞和视网膜色素上皮(rpe)层之间。在视网膜下腔注射期间,将注射的材料(例如,本申请所述的grna,本申请所述的一种或多种分离的核酸分子,本申请所述的供体核酸分子,本申请所述的载体,以及药学上可接受的的载剂)并在其间创建空间。在本申请中,术语“细胞”指其如本领域一般公认的意义。该术语以其通常的生物学含义使用,并且不指完整多细胞生物,例如具体地不指人类。细胞可以存在于生物内,例如鸟类、植物和哺乳动物,例如人、牛、羊、猿、猴、猪、狗和猫。细胞可以是原核的(例如,细菌细胞)或真核的(例如,哺乳动物或植物细胞)。细胞可以具有体细胞或种系起源、全能或多能、分裂或非分裂。细胞还可以衍生自或可以包含配子或胚胎、干细胞、或完全分化的细胞。在本申请中,术语“诱导性多能干细胞”通常是指体细胞在某些条件下恢复到全能性的状态的细胞。所述全能性是指具有的分化成机体所有类型细胞和形成完全胚胎或进一步发育成新个体的能力。例如,在本申请中,所述的诱导多能干细胞包含由肾上皮细胞经培养后获得的、具有分化为视网膜细胞的能力的细胞。在本申请中,术语“hek293细胞”通常是指“人胚胎肾细胞293”,是衍生自人胚胎肾细胞的细胞系,具有易培养,转染效率高的特点,在本领域,是很常用的研究外源基因的细胞株。在本申请中,术语“293t细胞”或“hek293t细胞”是源于“hek293细胞”的一种细胞,也是本领域常用的细胞株。在本申请中,术语“肾上皮细胞”通常是指在人尿液中收集到的肾脏的上皮细胞。在本申请中,其可以是诱导多能干细胞的一个来源。在本领域,利用尿液中的肾上皮细胞诱导多能干细胞符合成本效益,通用,适合于应用各个年龄、性别和种族。这项技术使得获取大量病人样本相较于其它现有方式容易和经济得多。在本申请中,术语“药物组合物”通常是指合适于向有需要的受试者施用的组合物。例如,本申请所述的药物组合物,其可以包含本申请所述的grna、本申请所述一种或多种分离的核酸分子、本申请所述的供体核酸分子和/或本申请所述的载体,以及药学上可接受的的载剂。术语“受试者”或“个体”或“动物”或“患者”在本申请中可互换用于指施用本申请的药物组合物需要的受试者,例如哺乳动物受试者。动物受试者包括人类、非人类灵长类、狗、猫、豚鼠、兔子、大鼠、小鼠、马、黄牛、乳牛等等,例如小鼠。在某些实施方式中,药物组合物可以包含用于视网膜下、非肠道、透皮、内腔内、动脉内、膜内和/或鼻内给药或直接注射入组织的组合物。例如,所述药物组合物通过视网膜下腔注射向受试者给药。除了本文提到的特定蛋白质和核苷酸之外,本申请还可包括变体、衍生物、类似物、同源物及其片段的用途。在本申请的上下文中,任何给定序列的变体是指其中残基的特定序列(无论是氨基酸或核苷酸残基)已经经过修饰而使得所述多肽或多核苷酸基本上保留至少一种内源功能的序列。可以通过天然存在的蛋白质和/或多核苷酸中存在的至少一个氨基酸残基和/或核苷酸残基的添加、缺失、取代、修饰、替换和/或变异来获得变体序列。在本申请中,术语“衍生物”通常是指本申请的多肽或多核苷酸而言包括自/对序列的一个(或多个)氨基酸残基的任何取代、变异、修饰、替换、缺失和/或添加,只要所得的多肽或多核苷酸基本上保留其至少一种内源功能。在本申请中,术语“类似物”通常对多肽或多核苷酸而言,包括多肽或多核苷酸的任何模拟物,即拥有该模拟物模拟的多肽或多核苷酸的至少一种内源功能的化学化合物。通常,可以进行氨基酸取代,例如至少1个(例如,1、2、3、4、5、6、7、8、9、10或20个以上)氨基酸取代,只要经修饰的序列基本上保持需要的活性或能力。氨基酸取代可包括使用非天然存在的类似物。用于本申请的蛋白质或多肽也可以具有氨基酸残基的缺失、插入或取代,所述氨基酸残基产生沉默的变化并导致功能上等同的蛋白质。可以根据残基的极性、电荷、溶解性、疏水性、亲水性和/或两性性质的相似性进行有意的氨基酸取代,只要保留内源性功能即可。例如,带负电荷的氨基酸包括天冬氨酸和谷氨酸;带正电荷的氨基酸包括赖氨酸和精氨酸;并且含具有相似亲水性值的不带电极性头基的氨基酸包括天冬酰胺、谷氨酰胺、丝氨酸、苏氨酸和酪氨酸。在本申请中,术语“同源物”通常是指与野生型氨基酸序列和野生型核苷酸序列具有一定同源性的氨基酸序列或核苷酸序列。术语“同源性”可以等同于“同一性”。同源序列可以包括可以与主题序列是至少70%、75%、80%、85%、90%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%或99.9%相同的氨基酸序列。通常,同源物将包含与主题氨基酸序列相同的活性位点等。同源性可以根据相似性(即具有相似化学性质/功能的氨基酸残基)来考虑,也可以在序列同一性方面表达同源性。在本申请中,提及的氨基酸序列或核苷酸序列的seqidno中的任一项具有百分比同一性的序列是指在所提及的seqidno的整个长度上具有所述百分比同一性的序列。为了确定序列同一性,可进行序列比对,其可通过本领域技术人员了解的各种方式进行,例如,使用blast、blast-2、align、needle或megalign(dnastar)软件等。本领域技术人员能够确定用于比对的适当参数,包括在所比较的全长序列中实现最优比对所需要的任何算法。在本申请中,术语“和/或”应理解为意指可选项中的任一项或可选项的两项。在本申请中,术语“包含”通常是指包括明确指定的特征,但不排除其他要素。在本申请中,术语“约”通常是指在指定数值以上或以下0.5%-10%的范围内变动,例如在指定数值以上或以下0.5%、1%、1.5%、2%、2.5%、3%、3.5%、4%、4.5%、5%、5.5%、6%、6.5%、7%、7.5%、8%、8.5%、9%、9.5%、或10%的范围内变动。发明详述grna一方面,本申请提供一种特异性靶向细胞色素p450家族4亚家族v多肽2的基因(cyp4v2基因)的grna,其特异性靶向cyp4v2基因的突变位点。在某些情形中,cyp4v2的一个或多个内含子和外显子会出现了不同数量(例如1对,2对,3对,4对,10对,20对,50对,100对)的碱基对的移除或增加,核苷酸的突变或替代,从而导致cyp4v2蛋白结构的变化和功能的损失。例如,所述cyp4v2基因的突变位点可以包括表1所示的突变位点。表1cyp4v2基因的突变位点在某些情形中,所述cyp4v2基因的突变位点包含c.802-8_810del17bpinsgc。在本申请中,术语“c.802-8_810del17bpinsgc”是比较常见的一种cyp4v2基因突变,属于内含子6的3’末端和外显子7的5’末端17对碱基对的移除,从而导致外显子7的缺失,导致转录蛋白的结构和活性变化。在某些情形中,所述c.802-8_810del17bpinsgc还可合并其他类别的突变,例如c.992a>c(p.h331p)、c.1091-2a>g(exon9del)。在某些情形中,所述grna可特异性结合c.802-8_810del17bpinsgc突变位点上下100bp、120bp、140bp、160bp、180bp、200bp、250bp、300bp、350bp、400bp或500bp的核苷酸序列。在某些情形中,所述grna可特异性结合c.802-8_810del17bpinsgc突变位点上下200bp的核苷酸序列。在某些情形中,所述grna可特异性结合与c.802-8_810del17bpinsgc突变位点上下200bp的核苷酸序列具有至少70%(例如,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。在某些情形中,所述grna可特异性结合c.802-8_810del17bpinsgc突变位点上下100bp、120bp、140bp、160bp、180bp、200bp、250bp、300bp、350bp、400bp、500bp的核苷酸序列互补的核苷酸序列。在某些情形中,所述grna可特异性结合c.802-8_810del17bpinsgc突变位点上下200bp序列互补的核苷酸序列。在某些情形下,所述grna可特异性结合与c.802-8_810del17bpinsgc突变位点上下200bp序列互补的氨基酸序列具有至少70%(例如,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列互补的核苷酸序列。本申请所述的grna可以与目标靶核酸(例如,cyp4v2基因的突变位点)中的序列结合。grna可以通过杂交(即碱基配对)以序列特异性的方式与靶核酸相互作用。grna的核苷酸序列可以根据目标靶核酸的序列而变化。在本申请中,所述grna可包括seqidno:74、seqidno:78、seqidno:79、seqidno:80、seqidno:82、seqidno:83、seqidno:84中任一项所示的核苷酸序列。本申请中,所述grna可包括与seqidno:74、seqidno:78、seqidno:79、seqidno:80、seqidno:82、seqidno:83、seqidno:84中任一项所示的核苷酸序列具有至少70%(例如,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。在本申请中,所述grna可包括seqidno:74、seqidno:79、seqidno:83、seqidno:84中任一项所示的核苷酸序列。本申请中,所述grna可包括与seqidno:74、seqidno:79、seqidno:83、seqidno:84中任一项所示的核苷酸序列具有至少70%(例如,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。在本申请中,所述grna可包括seqidno:79、seqidno:83、seqidno:84中任一项所示的核苷酸序列。本申请中,所述grna可包括与seqidno:79、seqidno:83、seqidno:84中任一项所示的核苷酸序列具有至少70%(例如,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。在本申请中,所述grna自5’端至3’端可包含(x)n、seqidno:74、78-80、82-84中任一项所示的核苷酸序列和骨架序列,其中x为选自a、u、c和g中任一个的碱基,且n为0-15中的任一整数。在本申请中,所述grna可包含5’-(x)n-seqidno:74、78-80、82-84任一项所示的核苷酸序列-骨架序列-3’,其中x为选自a、u、c和g中任一个的碱基,且n为0-15中的任一整数。例如,本申请所述的骨架序列可以包括来自aav-sacas9-puro的骨架序列。在某些情形中,所述grna可以为单链向导rna(sgrna)。本申请还提供了sgrna组合,所述sgrna组合可包含本申请所述的sgrna。例如,所述sgrna可包含两个或两个以上本申请所示的sgrna。例如,所述sgrna组合可包括sgrna13和sgrna17;又例如,所述sgrna组合可包括sgrna13和sgrna18;又例如,所述sgrna组合可包括sgrna17和sgrna18;又例如,所述sgrna组合可包括sgrna13、sgrna17和sgrna18。本申请提供了一种或多种分离的核酸分子,所述分离的核酸分子可编码上文所述的特异性靶向cyp4v2突变基因的grna。例如,所述分离的核酸分子可包含seqidno:8、seqidno:12、seqidno:13、seqidno:14、seqidno:16、seqidno:17、seqidno:18中任一项所示的核苷酸序列。在本申请中,所述grna序列可以设计成与cas核酸酶可识别的pam序列临近处的靶核酸杂交。所述grna可以与靶序列完全互补或不完全互补。grna与其相应的靶序列之间的互补程度至少为50%(例如,至少为约55%、约60%、约65%、约70%、约75%、约80%、约85%、约90%、约95%、约98%、或更多)。所述“cas核酸酶”通常是指能够使用crispr序列(例如,grna)作为向导,从而识别和切割特定的dna链。例如,cas9核酸酶,csn1或csx12。cas9核酸酶通常包括ruvc核酸酶结构域和hnh核酸酶结构域,分别切割双链dna分子的两条不同的链。已经在不同的细菌物种如嗜热链球菌(s.thermophiles)、无害利斯特氏菌(listeriainnocua)(gasiunas,barrangouetal.2012;jinek,chylinskietal.2012)和化脓性链球菌(s.pyogenes)(deltcheva,chylinskietal.2011)中描述了cas9核酸酶。例如,化脓链球菌(streptococcuspyogenes)cas9蛋白,其氨基酸序列参见swissprot数据库登录号q99zw2;脑膜炎奈瑟氏菌(neisseriameningitides)cas9蛋白,其氨基酸序列见uniprot数据库编号a1iq68;嗜热链球菌(streptococcusthermophilus)cas9蛋白,其氨基酸序列见uniprot数据库编号q03lf7;金黃色葡萄球菌(staphylococcusaureus)cas9蛋白(例如,本申请所述载体中的sacas),其氨基酸序列见uniprot数据库编号j7rua5。cas核酸酶通常可以在dna中识别特定的pam序列。所述“pam”指原间隔序列临近基序(protospaceradjacentmotif),其被crispr核酸酶识别为切割位点,pam随核酸酶(例如,cas9、cpfl等)而变。原间隔区元件序列通常直接位于pam位点上游。例如,所述pam可包含seqidno:24-38中任一项所述的核苷酸序列。本申请所述的grna和/或分离的核酸分子可以使用载体递送。在本申请中,所述载体(例如px601)可以包含或者不包含编码cas核酸酶的核酸。在本申请中,cas核酸酶可以作为一种或多种多肽单独地递送。或者,编码所述cas核酸酶的核酸分子,与一种或多种引导rna,或一种或多种crrna以及tracrrna,单独地递送,或者一起预复合地递送。例如,所述本申请的核酸分子(例如,编码所述特异性靶向cyp4v2基因的sgrna的分离的核酸分子)和编码cas9核酸酶的核酸分子可以位于同一载体(例如,质粒)中。所述载体可包括本领域已知的病毒或非病毒载体。非病毒递送载体可以包括但不限于纳米颗粒、脂质体、核糖核蛋白、带正电荷的肽、小分子rna缀合物、适体-rna嵌合体和rna融合蛋白复合物。在本申请中,所述分离的核酸分子和/或所述编码dna核酸内切酶的核酸分子可以通过质粒递送。在某些情形中,所述载体可以是病毒载体,例如,aav、慢病毒、逆转录病毒、腺病毒、疱疹病毒和肝炎病毒。用于产生包含核酸分子(例如,本申请所述分离的核酸分子)作为载体基因组一部分的病毒载体的方法是本领域公知的,并且本领域技术人员可无需进行过多的实验进行。在另一些情形中,所述载体可以是包装了本申请所述核酸分子的重组aav病毒粒子。产生所述重组aav的方法,可包括将本申请所述核酸分子引入包装细胞系,将表达aav的rep和cap基因的包装质粒引入细胞系中,以及从包装细胞系上清中收集重组的aav。包装的细胞系可以有各种类型的细胞。例如,可以使用的包装细胞系包括但不限于hek293细胞,hela细胞和vero细胞。在某些情形中,所述载体可以为腺病毒相关载体(aav)。在本申请中,术语“腺病毒相关载体”通常指来源于天然存在且可用的腺相关病毒以及人工aav的载体。所述aav可包括不同的血清型aav1、aav2、aav3、aav4、aav5、aav6、aav7、aav8、aav9、aav10、aav11、aav12或aav13,以及任何aav变体或混合物。aav基因组两端通常有末端反向重复序列(itr),术语“itr”或“末端反向重复”是指存在于aav和/或重组aav中的核酸序列段,其可形成完成aav溶解和潜伏生命周期所需的t形回文结构。产生aav载体的技术是本领域的标准技术,其中包括将要递送的多核苷酸、rep和cap基因以及辅助病毒功能的待包装aav基因组提供给细胞。生产aav载体通常需要在单个细胞(此处称为包装细胞)内存在以下成分:raav基因组,与raav基因组分离(例如不在其中)的aavrep和cap基因以及辅助病毒。aavrep和cap基因可以来自任何aav血清型,也可以来自与aav基因组itr不同的aav血清型,包括但不限于本文所述的aav血清型。供体核酸分子和载体另一方面,本申请还提供了供体核酸分子。在本申请中,术语“供体核酸分子”通常是指向受体(例如,接收核酸分子)提供异源核酸序列的核酸分子。在某些情形下,所述供体核酸分子被导入到受体细胞中,可以修复被所述分离的核酸分子切割后的dna片段(例如,断裂后的双链dna)。在另外一些情形下,dna断裂后可以通过供体核酸分子来修复。修复的方式包括但不限于依赖于dna同源性的同源重组(homologousrecombination,hr)修复和非同源末端连接(non-homologousendjoining,nhej)的修复方式。在某些情况下,可以使用hdr将外源多核苷酸序列插入靶核酸切割位点。外源多核苷酸序列可以被称为供体多核苷酸(或供体,或供体序列,或多核苷酸供体模板)。可将供体多核苷酸,供体多核苷酸的一部分,供体多核苷酸的拷贝或供体多核苷酸的拷贝的一部分插入靶核酸切割位点。供体多核苷酸可以是外源多核苷酸序列,即不是天然存在于靶核酸切割位点的序列。hdr利用同源序列或供体序列(例如,所述供体核酸分子)作为模板,在断点处插入特定的dna序列。同源序列可以在内源基因组中,例如姐妹染色单体(sisterchromatid)。或者,所述供体可以是外源核酸,例如质粒、单链寡核苷酸、双链寡核苷酸、双链寡核苷酸或病毒。这些外源核酸可以包含与dna核酸酶切割的基因座具有高度同源性的区域,此外还可包含额外的序列或序列变化(包括可掺入切割的靶基因座的缺失)。例如,本申请利用同源臂,可以将连接在此同源臂上的外源基因片段(例如,本申请所述供体核酸分子)整合到靶位点(例如,本申请所述grna靶向的位点)。本申请所述“同源臂”通常指与dna断裂处的核苷酸序列具有同源性的一段核苷酸序列。利用外源供体模板,可以在同源的侧翼区域之间引入另外的核酸序列(例如,所述靶向载体)或修饰(例如单碱基或多碱基改变或缺失),从而也可以将另外的或改变的核酸序列纳入目标基因座,外源供体可以由质粒载体递送,例如,aav载体和/或ta克隆载体(例如,zt4载体)。本申请所述供体核酸分子,供体核酸分子可以是野生型的人cyp4v2的核苷酸序列、基因片段、同源物。例如,所述的供体核酸分子包含c.802-8_810del17bpinsgc突变位点上下500bp、700bp、750bp、800bp、850bp、900bp、1000bp、2000bp、3000bp、5000bp内的核苷酸序列。在某些情形中,所述供体核酸可以包含c.802-8_810del17bpinsgc突变位点上下800bp。在某些情形中,所述供体核酸可以包含与c.802-8_810del17bpinsgc突变位点上下800bp具有至少50%(例如,至少55%,至少60%,至少65%,至少70%,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。本申请所述可包含cyp4v2核苷酸序列的“核酸分子”与本申请所述特异性靶向cyp4v2的grna或“分离的核酸分子”不同。例如,在本申请中,所述的供体核酸分子可以包含seqidno:64-66中任一项所示的核苷酸序列。又例如,所述供体核酸分子可包括与seqidno:64-66中任一项所示的核苷酸序列具有至少50%(例如,至少55%,至少60%,至少65%,至少70%,至少75%,至少80%,至少85%,至少90%,至少91%,至少92%,至少93%,至少94%,至少95%,至少96%,至少97%,至少98%,至少99%,或至少100%)序列同一性的核苷酸序列。另一方面,本申请提供了载体,其包含所述的分离的核酸分子(例如,编码所述特异性靶向cyp4v2基因的sgrna的分离的核酸分子)和/或所述的供体核酸分子(例如,编码所述人cyp4v2基因的核苷酸分子)。在某些情形中,所述分离的核酸分子和所述供体核酸分子可以位于不同的载体上。在另外一些情形中,所述分离的核酸分子和所述供体核酸分子可以位于同一载体中。在本申请中,包含所述分离的核酸分子的载体和包含所述供体核酸分子的载体同时导入细胞后,cas核酸酶可以切割供体核酸分子和细胞基因组dna,将供体核酸分子整合到细胞基因组的准确位置上(例如,cyp4v2基因片段)。在本申请中,所述载体可以包含一个或多个所述sgrna。例如,可以包含1个、2个、3个、4个、5个、6个、7个或7个以上本申请所述的sgrna。在某些情形中,当使用多个sgrna时,所述多个sgrna可以存在一个或多个载体中,也可以同时或先后施用。例如,所述sgrna可以分别存在不同的载体中施用,也可以存在同一个载体中施用。例如,所述sgrna可以存在于同一个aav载体中施用。例如,所述sgrna可以位于不同的载体中,同时施用。例如,所述sgrna可以位于同一个载体中,先后施用。在某些实施方式中,所述的载体为病毒载体。例如,aav、慢病毒、逆转录病毒、腺病毒、疱疹病毒和肝炎病毒。用于产生包含核酸分子(例如,本申请所述分离的核酸分子)作为载体基因组一部分的病毒载体的方法是本领域公知的,并且本领域技术人员可无需进行过多的实验。细胞、药物组合物、用途和方法本申请提供了细胞,所述细胞可包含所述分离的核酸分子和/或所述供体核酸分子。本申请所述的细胞可表达sgrna和cas核酸酶,具有很好的dna切割效果。本申请所述细胞还可以表达具备正常功能的cyp4v2蛋白。所述细胞可以包括哺乳动物细胞,例如,来自人的细胞。例如,所述细胞可包括cos细胞、cos-1细胞、中国仓鼠卵巢(cho)细胞、hela细胞、hek293细胞、ns0细胞或骨髓瘤细胞、干细胞(例如,多能干细胞和/或全能干细胞)、和/或上皮细胞(例如,肾上皮细胞和/或视网膜上皮细胞)。在本申请中,所述的细胞可包括hek293细胞和/或尿液肾上皮细胞。本申请中,所述的细胞可以经修饰后具备分化能力。所述修饰可包括所述分化能力可包括分化成身体任何细胞类型的能力:神经元、星形胶质细胞、少突胶质细胞、视网膜上皮细胞、表皮、毛发和角质形成细胞、肝细胞、胰岛β细胞、肠上皮细胞、肺泡细胞、造血细胞、内皮细胞、心肌细胞、平滑肌细胞、骨骼肌细胞、肾细胞、脂肪细胞、软骨细胞和/或骨细胞。例如,所述细胞可被重编程为具有关键重编程基因(例如,oct4、klf4、sox2、cmyc、nanog和/或lin28)过表达的诱导多能干细胞(ipsc)。本申请所述细胞可用于评价基因编辑治疗所需物质(例如,sgrna和供体核酸分子)的有效性和安全性。本申请还提供了组织模型,所述组织模型可包括包含正确的人cyp4v2cdna的3d-视网膜类器官。所述细胞和所述组织模型可用于评价基因编辑治疗所需物质(例如,sgrna和供体核酸分子)的有效性和安全性。例如,将编码所述grna的多核苷酸、所述供体核酸分子和/或载体导入到所述细胞和/或所述组织模型后,所述能检测到grna、正确的cyp4v2蛋白的表达,例如,使用pcr测序或凝胶电泳;或者,该细胞和/或组织模型不产生免疫排斥反应、毒性,和/或,导入的物质不影响所述细胞和/或所述组织模型的其他功能。例如,可使用修复效率检测作为评价基因编辑有效性的指标,示例性的方法如实施例4所示。例如,可检测脱靶效率作为评价基因编辑安全性的指标,例如,可使用全基因组测序法检测脱靶效率。本申请提供了所述的grna,所述的一种或者多种分离的核酸分子,所述供体核酸分子,和/或所述的载体在制备治疗疾病的药物中的应用,其中所述疾病包括cyp4v2基因突变所导致的疾病。例如,cyp4v2基因中c.802-8_810del17bpinsgc突变所导致的疾病。例如,所述疾病可包括视网膜色素变性。例如,所述疾病可包括结晶性视网膜色素变性。本申请提供了药物组合物,所述药物组合物包含所述的grna,所述的一种或多种分离的核酸分子,所述的供体核酸分子,所述的载体,以及药学上可接受的载剂。所述载剂应当是无毒的,并且不应干扰活性成分的功效。本申请所述的药物组合物可通过各种方法导入,例如,包括但不限于,玻璃体内注射(例如,前部、中间或后部玻璃体注射)、结膜下注射、前房内注射、经由颞侧注射到前房中、基质内注射、注射到脉络膜下间隙中、角膜内注射、视网膜下腔注射和眼内注射局部地投予眼睛。所述导入可包括视网膜下腔注射,视网膜下腔注射为注射到视网膜下空间,即感觉神经性视网膜下面。在视网膜下注射期间,将注射的材料(例如,所述的靶向载体,所述的grna,和/或所述的质粒)直接导入感光细胞和视网膜色素上皮(rpe)层之间,并在其间创建空间。本申请提供了一种治疗结晶样视网膜变性的方法,所述方法包括以下的步骤:向有需要的受试者导入所述的grna(例如,特异性靶向cyp4v2基因的sgrna),所述的一种或多种分离的核酸分子(编码所述特异性靶向cyp4v2基因的sgrna的分离的核酸分子),所述的供体核酸分子(编码所述人cyp4v2基因的核苷酸分子),和/或所述的载体。其中,所述导入使受试者获得了正常功能的cyp4v2蛋白。本申请所述方法可包括离体的方法。在某些情形中,可以获得受试者特异性的诱导多能干细胞(ipsc)。然后,可以使用本申请所述的方法编辑这些ipsc细胞的基因组dna。例如,该方法可以包括在ipsc的cyp4v2基因的突变位点内或附近进行编辑,使得其不编码具有突变的cyp4v2蛋白。接下来,可以将经基因编辑的ipsc分化为其他细胞,例如感光细胞或视网膜祖细胞。最后,可以将分化的细胞(例如感光细胞或视网膜祖细胞)植入受试者体内。在某些情形中,可以获得受试者特异性的诱导多能干细胞(ipsc)。然后,可以将诱导多能干细胞分化为任何类型的细胞,例如感光细胞或者视网膜祖细胞。在本申请中,可以是3d视网膜类器官。接下来,可以使用本申请所述的方法编辑这些3d视网膜类器官细胞的基因组dna。例如,该方法可以包括在3d视网膜类器官细胞的cyp4v2基因的突变位点内或附近进行编辑,使得其不编码具有突变的cyp4v2蛋白。最后,可以将3d视网膜类器官细胞植入受试者体内。在另一些情形中,可以从受试者中分离出感光细胞或视网膜祖细胞。接下来,可以使用本申请所述的方法编辑这些感光细胞或视网膜祖细胞的基因组dna。例如,该方法可以包括在感光细胞或视网膜祖细胞的cyp4v2基因的突变位点内或附近进行编辑,使得其不具有突变的cyp4v2。最后,可以将经基因编辑的感光细胞或视网膜祖细胞植入受试者体内。所述方法可包括在给药前对治疗剂进行全面分析。例如,对校正细胞的整个基因组进行测序,以确保没有脱靶效应(如果有的话)可以处于与对受试者的最小风险相关的基因组位置。此外,可以在植入之前分离特定细胞的群,包括克隆细胞群。本申请所述的方法可包括使用定点核酸酶在基因组中精确的靶标位置切割dna,从而在基因组内特定位置产生单链或双链dna断裂的方法。此类断裂可以通过内源性细胞过程进行定期修复,例如同源重组、非同源末端连接。本申请所述的方法可包括在目标基因座中靠近靶序列的位置创建一个或两个dna断裂,两个dna断裂可以为双链断裂或两个单链断裂。所述断裂可通过定点(site-directed)多肽来实现。定点多肽(例如dna核酸内切酶)可以在核酸(例如基因组dna)中引入双链断裂或单链断裂。双链断裂可以刺激细胞的内源性dna修复途径,例如,hr、nhej。利用外源供体模板,可以在同源的侧翼区域之间引入另外的核酸序列(例如,所述靶向载体)或修饰(例如单碱基或多碱基改变或缺失),从而也可以将另外的或改变的核酸序列纳入目标基因座,外源供体可以由质粒载体递送,例如,aav载体和/或ta克隆载体(例如,zt4载体)。本申请提供了一种调节细胞中cyp4v2基因表达的方法,其包括向细胞导入所述的grna,所述的一种或多种分离的核酸分子,和/或中任一项所述的载体。本申请中所述方法可以是将所述grna导入到所述细胞中。例如,所述grna靶向受体细胞基因组的cyp4v2基因片段,在核酸酶的帮助下将其剪切,从而产生cyp4v2基因翻译为蛋白的机会变少、翻译的蛋白不能执行正常功能的效果。本申请中所述方法可以是将所述的一种或多种分离的核酸分子导入到所述细胞中。例如,编码所述特异性靶向cyp4v2基因的sgrna的分离的核酸分子,使得所述的cyp4v2基因片段被破坏,从而产生cyp4v2基因翻译为蛋白的机会变少、翻译的蛋白不能执行正常功能的效果。本申请中所述方法可以是将所述载体导入到所述细胞中。所述载体包含所述的分离的核酸分子和/或所述的供体核酸分子。在某些情形下,所述载体含有所述分离的核酸分子和所述的供体核酸分子,使得所述细胞中cyp4v2基因为所述供体核酸分子替代,从而产生了cyp4v2基因翻译为蛋白的机会的变化(例如,由不存在cyp4v2蛋白的表达转变为达到正常表达量)、翻译的蛋白功能由异常转为正常的效果。在某些情形下,所述载体含有所述分离的核酸分子,使得所述的cyp4v2基因片段被破坏,从而产生cyp4v2基因翻译为蛋白的机会变少、翻译的蛋白不能执行正常功能的效果。在另一些情形下,所述载体含有所述供体核酸分子,使得所述细胞内含有更多的cyp4v2基因片段,可以转录并翻译出更多的cyp4v2蛋白。不欲被任何理论所限,下文中的实施例仅仅是为了阐释本申请的核酸分子、蛋白、制备方法和用途等,而不用于限制本申请发明的范围。实施例实施例1sgrna的合成1.sgrna的靶点针对cyp4v2突变基因突变位点c.802-8_810del17bpinsgc设计sgrna。使用crispr-cas9系统将其中1条染色体中的cyp4v2突变基因从突变细胞中敲除,如果2条染色体中的突变相同,可以同时敲除2条染色体中的突变。2.sgrna设计在cyp4v2的突变位点区域设计pam序列为nngrrt和nngrr(staphylococcusaureus(金黄色葡萄球菌),sa;sacas9),长度为21bp的sgrna序列;设计的23条sgrna序列分别如seqidno:67-89。编码所述sgrna的核酸序列见表2。表2编码sgrna的核酸序列3.sgrna体外编辑有效性检测(1)sgrna的体外转录:1)sgrna体外转录的引物设计见表3表3sgrna体外转录的引物注:f:forward正义链r:reverse反义链2)sgrna体外转录模板的构建pcr反应体系如下:pcr反应程序如下:40个循环3)使用2.0%dna凝胶跑胶,使用omega胶回收试剂盒回收grna体外转录模板胶回收的步骤如下:a)将pcr反应产物中加入等体积的膜结合液,切胶回收的需要每1mg加入1μl的膜结合液,50-60℃加热7min,直至所有的凝胶溶解完全,涡旋混匀,过柱回收。b)将上述液体降入到回收柱中,10000×g离心1min,去滤液。c)加入700μl的清洗缓冲液,>13000×g离心1min,去滤液。d)重复步骤c)。e)空管>13000×g离心10min。f)将离心柱转移到新的1.5ml的ep管中,做好标记,加入20-30μl的洗脱缓冲液或ddh2o,室温放置2min。g)>13000×g离心1min,弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。4)sgrna的体外转录(20μl体系):注意:t7rna聚合酶混合物最后放,混合后置于37℃恒温孵箱,反应;反应结束,加入2μldna酶i,37℃反应30min后跑胶。5)omega胶回收剂盒说明书回收grna,步骤同上。(2)cyp4v2sgrna切割模板的制备提取cyp4v2c.802-8_810del17bpinsgc纯合的患者来源的ipscs的dna,以此为模板制备cyp4v2sgrna切割模板dsdna。1)基因组dna提取:a)400×g离心5min收集细胞,弃上清液。加入220μlpbs(磷酸盐缓冲液)、10mlrna酶溶液和20μlpk工作液至样品中,重悬细胞。室温静置15min以上。b)加入250μlgb缓冲液至细胞重悬液中,涡旋混匀,65℃水浴15-30min,过柱纯化;c)加入250μl无水乙醇至消化液中,涡旋混匀15-20s。d)将gdna吸附柱置于2ml收集管中。将上一步所得混合液(包括沉淀)转移至吸附柱中。12000×g离心1min。若出现堵柱现象,再14000×g离心3-5min。若混合液超过750μl需分次过柱。e)弃滤液,将吸附柱置于收集管中。加入500μl清洗缓冲液a至吸附柱中。12000×g离心1min。f)弃滤液,将吸附柱置于收集管中。加入650μl清洗缓冲液b至吸附柱中。12000×g离心1min。g)重复步骤4。h)弃滤液,将吸附柱置于收集管中。12000×g空管离心2min。i)将吸附柱置于新的1.5ml离心管。加入30-100μl预热至70℃的洗脱缓冲液至吸附柱的膜中央,室温放置3min。12000×g离心1min。注意:对于dna含量丰富的组织,可再加入30-100μl洗脱缓冲液重复洗脱。弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。2)pcr过程使用引物见表4:表4sgrna体外切割实验dsdna片段pcr引物3)pcr反应体系如下:pcr反应程序如下:30个循环4)使用1.5%dna凝胶跑胶,使用omega胶回收试剂盒回收pcr产物,步骤同前。(3)sacas9-sgrna体外酶切反应:反应体系如下:充分混匀,37℃反应30min,加入3μldna上样缓冲液混合后65℃煮5min,2%的琼脂糖凝胶分析酶切结果。理论切割片段长度见表5,实验结果如图1a-1i所示,结果显示,sgrna8、sgrna12、sgrna13、sgrna14、sgrna16、sgrna17、sgrna18均对目标片段具有好的切割效果,可以将dsdna切割为相应的长度的片段。而其他sgrna不能将dsdna切割为相应的片段。表5sgrna体外切割实验dsdna片段理论切割长度实施例2细胞水平sgrna靶点验证1.sgrna合成根据体外切割实验,选择有效的sgrna:sgrna8;sgrna12;sgrna13;sgrna14;sgrna16;sgrna17;sgrna18。酶切位点bbs1序列,在设计的sgrna上下游添加bbs1酶切位点(大写字母),编码所述sgrna的核酸分子见表6:表6编码所述sgrna的核酸序列编号序列cyp4v2-sgrna8-facacggggccaatgaaatgaacgccag(seqidno:44)cyp4v2-sgrna8-raaaactggcgttcatttcattggcccc(seqidno:45)cyp4v2-sgrna12-facacggaaataggcttagaaaaataag(seqidno:46)cyp4v2-sgrna12-raaaacttatttttctaagcctatttcc(seqidno:47)cyp4v2-sgrna13-facacgtaggcttagaaaaataaatgag(seqidno:48)cyp4v2-sgrna13-raaaactcatttatttttctaagcctac(seqidno:49)cyp4v2-sgrna14-facacgaaagaaactagcatattttatg(seqidno:50)cyp4v2-sgrna14-raaaacataaaatatgctagtttctttc(seqidno:51)cyp4v2-sgrna16-facacgatgataatcacatgcttctgtg(seqidno:52)cyp4v2-sgrna16-raaaacatgataatcacatgcttctgtc(seqidno:53)cyp4v2-sgrna17-facacgaatgaacgccaatgaagactgg(seqidno:54)cyp4v2-sgrna17-raaaaccagtcttcattggcgttcattc(seqidno:55)cyp4v2-sgrna18-facacgtgaagactgtagaggtgatggg(seqidno:56)cyp4v2-sgrna18-raaaacccatcacctctacagtcttcac(seqidno:57)2.sgrna载体构建与质粒提取(1)sgrna退火将上述合成的各sgrna(f、r)分别稀释成50μmol,取sgrnaf.r各5μl配成sgrnamix1~7。将t4pnk及10×t4连接缓冲液于冰上融化备用。配制如下反应体系:将第5步配制的反应体系置于pcr仪上,运行如下反应程序37℃30min95℃5min以5℃/min缓慢降至25℃25℃永久回收反应产物。(2)载体酶切构建sgrna载体,所用质粒为aav-sacas9-puro载体。质粒图谱如图2所示。使用bbsi酶切释放sgrna结合位点,在1.5mlpcr管中配制如下酶切反应体系:酶切1-2h/(或者4℃过夜酶切),回收纯化,测定浓度,稀释到50ng/μl。(3)连接使用上一步的回收载体和退火的sgrna配制如下连接体系(200μlpcr管):将上一步的连接反应体系置于37℃连接约1-2h,完成sgrna载体构建。(4)质粒转化1)取出transstbl3化学感受态细胞(北京全式金生物技术有限公司cd-521-02)置于冰上解冻。2)取1μl连接产物至于50μl感受态细胞中,冰上孵育半小时,42℃热激90s,冰上2min。3)加入无抗培养基500μl于37℃,200rpm摇1h。4)800rpm/min离心5min,弃上清剩约100μl,使用含氨苄抗生素的lb琼脂培养基筛选阳性克隆。5)第二天挑筛选出的阳性克隆菌(培养基500μl)摇3-4小时,取200μl送测序。(5)质粒提取(按照omega去内毒素质粒大提试剂盒进行)1)将测序正确的质粒进行过夜大摇(50-200ml),37℃摇床培养12-16h,以扩增质粒,第二天进行提取(摇菌时间摇小于16h)。2)取50-200ml的菌液,于室温下4000×g离心10min,收集菌体。3)弃去培养基。往沉淀中加入10ml溶液i/rna酶混合液,通过移液枪吹打或者漩涡振荡使细胞完全重新悬浮。4)加入10ml溶液ii,盖上盖子,轻轻上下颠倒离心管8-10次以获得澄清裂解物。5)加入5ml预冷的n3缓冲液,盖好盖子,并温和地上下颠倒离心管10次,直至形成白色絮狀沉淀,可在室温下静置孵育2min。6)准备一个针筒过滤器,拉出针筒中的活塞,将针筒竖直放在一个合适的试管架上,在注射器下端出口处放置一个收集管,针筒开口朝上。立即将裂解液倒入过滤器的针筒中。细胞裂解液在针筒中停留5min。此时白色絮状物会漂浮于裂解液表面。细胞裂解液可能已从过滤注射器口流出。用新的50ml试管收集细胞裂解液。小心轻轻地将注射器活塞插入针筒中,慢慢推动活塞以使裂解液流入到收集试管中。7)加入0.1倍体积的etr溶液(蓝色)至已流出的过滤裂解液中,颠倒试管10次,然后于冰浴中静置10min。8)将上述裂解液于42℃下水浴5min。裂解液又将再次出现浑浊。此时于25℃,4000×g离心5min,etr缓冲液将在试管底部形成蓝色分层。9)将上清液移至另一新的50ml试管中,加入0.5倍体积室温的无水乙醇,轻轻颠倒试管6-7次,室温放置1-2min。10)将一个dnamaxi结合柱套入50ml收集试管中,加入20ml过滤液至dnamaxi结合柱中。室温下,4000×g离心3min。弃滤液。11)将dnamaxi结合柱套入同一个收集管中,重复步骤10直至剩余的过滤液全部结合到dnamaxi结合柱中,按同样条件离心。12)将dnamaxi结合柱套入同一个收集管中,加入10mlhbc缓冲液至dnamaxi结合柱中,室温下4000×g离心3min,弃滤液。13)将dnamaxi结合柱套入同一个收集管中,加入15mldna清洗液(用无水乙醇稀释的)至dnamaxi结合柱中,室温下4000×g离心3min,弃去滤液。14)将dnamaxi结合柱套入同一个收集管中,加入10mldna清洗液(用无水乙醇稀释的)至dnamaxi结合柱中,室温下4000×g离心3min,弃去滤液。15)最高速(不超过6000×g)空甩以干燥dnamaxi结合柱的基质10min。16)(选做)进一步风干dnamaxi结合柱(可选)选择下面任一种方法来进一步干燥dnamaxi结合柱,再进行洗脱dna(有必要的话):a)把dnamaxi结合柱放在真空容器中15min来干燥乙醇:在室温下把柱子移到真空室,连接好所有真空室的装置。密封真空室,真空15min。移走dnamaxi结合柱进行下一步操作。b)在真空烘箱烘干柱子或65℃干燥10-15min。移走dnamaxi结合柱,进行下一步骤操作。17)把dnamaxi结合柱置于一干净的50ml离心管上,直接加入1-3ml无内毒素洗脱缓冲液到dnamaxi结合柱基质上(所加的量取决于预期终产物浓度),室温静置5min。18)4000×g,离心5min以洗脱出dna。19)弃除柱子,把dna产物保存于-20℃。20)再次将提取的质粒送测序以确保构建的质粒正确。3.293t细胞验证sgrna有效性(1)293t细胞培养1)冻存细胞的复苏a)将恒温水浴锅温度调至37℃,将冻存细胞从液氮中取出,用镊子夹住盖子,在水中快速晃动。b)将冻存液转移到15ml刻度离心管中,缓慢地加入10ml的细胞培养液,并轻轻的晃动混匀液体。拧紧盖子,过火,1000rpm/min,离心3min。c)过火,加入适量培养液,轻轻吹打底部的细胞沉淀,然后将细胞转移至培养瓶中放到培养箱中培养。293t细胞使用的培养基为添加10%胎牛血清和100u/ml双抗的高糖dmem,5%co2于37℃培养。2)细胞传代a)倒置显微镜下观察细胞的形态和密度,当细胞在培养瓶中的汇合度到达80%-90%时,开始对细胞进行传代。b)将细胞培养瓶中的旧培养液洗出来,用pbs清洗3次。向培养瓶中加入500μl的含edta的胰蛋白酶,放入培养箱中孵育1分钟左右,带细胞间隙变大,细胞变圆时,立即向培养瓶中加入1ml的培养液终止消化,并用吸管轻轻吹打细胞,待细胞全部从瓶底飘起后,将培养瓶中的液体转移到离心管中,1000rpm/min离心2min。c)弃掉上清,再向离心管中加入2ml培养基使沉淀的细胞重新悬浮。将细胞悬浮液分装到4个新培养瓶中,每个加入4ml的培养液,轻摇培养瓶,使细胞混合均匀铺满培养瓶,放入细胞培养箱中进行培养。d)转染之前1d,每孔中分别加入密度为80%、细胞舒展、细胞间隙均匀的293t细胞100万,次日细胞长到80-90%汇合度时进行质粒转染。(2)采用pei(聚乙烯亚胺)法转染293t细胞1)取1.5ml的ep管,按以上顺序进行编号,每管中加入250μl的dmem培养基(无血清),分别加入1.5μgaav-cyp4v2-sgrna8、sgrna12、sgrna13、sgrna14、sgrna16、sgrna17、sgrna18质粒和空载质粒,充分涡旋混匀后,每管加入7.5μl的pei转染试剂,涡旋混匀,室温放置20min后进行转染。另设置阴性对照。2)逐滴加入培养基中(六孔板培养基加无血清dmem=2ml/孔),孵箱培养,12-18h之内半量换液。次日,荧光显微镜下观察gfp的表达情况,以评估转染效率,转染效率良好的情况下继续培养转染后的质粒。3)抗性细胞筛选a)配液:10mg/ml(母液)稀释为1μg/ml的嘌呤霉素,筛选细胞。b)换液:转染后两日,在每个空中(包括阴性对照组)加入3ml含嘌呤霉素的293t细胞培养基,开始筛选转染阳性的细胞,以后每日观察细胞的存活情况,每2日换液,换液时加上相应量的嘌呤霉素。待到阴性对照的孔的细胞完全死亡,而实验组和对照组的细胞有存活的(说明转染成功),停止抗生素筛选,改用正常培养基。(3)293t细胞基因组dna的提取1)待6孔板细胞长到80-90%汇合度后,传代到6cm培养皿培养。2)待细胞长到80-90%汇合度后,收细胞,准备提取基因组dna,整个过程在7-10d左右。基因组的提取使用南京诺唯赞细胞提取试剂盒,实验步骤如下:a)400×g离心5min收集细胞,弃上清液。加入220μlpbs、10mlrna酶缓冲液和20μlpk工作液至样品中,重悬细胞。室温静置15min以上。b)加入250μlgb缓冲液至细胞重悬液中,涡旋混匀,65℃水浴15-30min,过柱纯化。c)加入250μl无水乙醇至消化液中,涡旋混匀15-20s。d)将gdna吸附柱置于2ml收集管中。将上一步所得混合液(包括沉淀)转移至吸附柱中。12000×g离心1min。若出现堵柱现象,再14000×g离心3-5min。若混合液超过750μl需分次过柱。e)弃滤液,将吸附柱置于收集管中。加入500μl清洗缓冲液a至吸附柱中。12000×g离心1min。f)弃滤液,将吸附柱置于收集管中。加入650μl清洗缓冲液b至吸附柱中。12000×g离心1min。g)重复步骤4。h)弃滤液,将吸附柱置于收集管中。12000×g空管离心2min。i)将吸附柱置于新的1.5ml离心管。加入30-100μl预热至70℃的洗脱缓冲液至吸附柱的膜中央,室温放置3min。12000×g离心1min。注意:对于dna含量丰富的组织,可再加入30-100μl洗脱缓冲液重复洗脱。j)弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。(4)t7e1酶切实验1)用提取上述转染了aav-cyp4v2-sgrna8、sgrna12、sgrna13、sgrna14、sgrna16、sgrna17、sgrna18质粒的293t细胞的基因组dna为模板,围绕靶点附近,利用上下游引物对提取的基因组dna进行扩增,进行dna片段pcr,引物序列见表7。表7t7e1酶切实验的引物2)使用液体回收试剂盒(omegagelextractionkit(200)d2500-02)对上述pcr产物进行液体dna回收;dna回收步骤如下:a)将pcr反应产物中加入等体积的膜结合液,切胶回收的需要每1mg加入1μl的膜结合液,50-60℃加热7min,直至所有的凝胶溶解完全,涡旋混匀,过柱回收;b)将上述液体降入到回收柱中,10000×g离心1min,去滤液;c)加入700μl的清洗缓冲液,>13000×g离心1min,去滤液;d)重复步骤c);e)空管>13000×g离心10min;f)将离心柱转移到新的1.5ml的ep管中,做好标记,加入20-30μl的洗脱缓冲液或ddh2o,室温放置2min;g)>13000×g离心1min,弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。3)t7e1酶切实验进行sgrna效率验证将上述获得的pcr回收或切胶回收产物进行t7e1酶切反应。a)t7e1酶切退火体系(19.5μl):b)t7e1酶切退火程序:c)t7e1酶切反应体系试剂体积(μl)退火产物9.75或9.5t7e1酶0.25或0.537℃孵育20mind)酶切产物跑胶配胶:2.5%凝胶,加双倍染料跑胶程序:140v,20min到30mine)查看跑胶结果酶切结果见图3;各片段切割后片段长度见表8。表8sgrna切割后片段长度表结果显示,sgrna8、sgrna13、sgrna17、sgrna18皆对靶点有切割效果,并且切割后的片段与表8所示是一致的。(5)基因组dna包含切割位点pcr片段基因测序,套峰检验将上述dna扩增片段测序,测序峰图如图4a-c所示。结果显示,sgrna13、sgrna17、sgrna18切割效率高,sgrna切割位点附近有套峰出现。4.双sgrna切割效率有效性验证(1)双sgrna-aav-sacas9-puro质粒构建、提取根据上述实验结果,sgrna13.17.18切割效率高。在上述实验构建的aav-sacas9-sgrna13质粒中,sa-grnascaffold与aavitr区之间用noti酶切处理后,分别插入u6promoter(启动子)-sgrna17-sascaffold(sa支架)片段与u6promoter-sgrna18-sa-grnascaffold,构建aav-sacas9-sgrna13-sgrna17、aav-sacas9-sgrna13-sgrna18质粒。1)u6promoter-sgrna17-sascaffold片段与u6promoter-sgrna18-sa-grnascaffold片段pcr引物序列见表9。表9u6-sacffold引物序列其中,大写字母部分为同源臂序列pcr反应体系如下:pcr反应程序如下:40个循环2)使用2.0%dna凝胶跑胶,使用omega胶回收试剂盒回收grna体外转录模板胶回收的步骤如下:a)将pcr反应产物中加入等体积的膜结合液,切胶回收的需要每1mg加入1μl的膜结合液,50-60℃加热7min,直至所有的凝胶溶解完全,涡旋混匀,过柱回收;b)将上述液体降入到回收柱中,10000×g离心1min,去滤液;c)加入700μl的清洗缓冲液,>13000×g离心1min,去滤液;d)重复步骤c);e)空管>13000×g离心10min;f)将离心柱转移到新的1.5ml的ep管中,做好标记,加入20-30μl的洗脱缓冲液或ddh2o,室温放置2min;g)>13000×g离心1min,弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。3)酶切载体使用noti酶切释放位点,在1.5mlpcr管中配制如下酶切反应体系:酶切1-2h/(k过夜酶切),回收纯化,测定浓度,稀释到50ng/μl。4)连接使用上一步的回收载体和退火的sgrna配制如下连接体系(200μlpcr管):将上一步的连接反应体系置于37℃连接约1-2h,完成sgrna载体构建。5)质粒转化a)取出transstbl3化学感受态细胞置于冰上解冻。b)取1μl连接产物至于50μl感受态细胞中,冰上孵育半小时,42度热激90s,冰上2min。c)加入无抗培养基500μl于37摄氏度,200rpm摇1h。d)800rpm/min离心5min,弃上清剩约100μl,使用含氨苄抗生素的lb琼脂培养基筛选阳性克隆。e)第二天挑筛选出的阳性克隆菌(培养基500μl)摇3-4小时,取200μl送测序。6)质粒提取(按照omega去内毒素质粒大提试剂盒进行)步骤同前。(2)293t细胞验证双sgrna与单sgrna有效性1)293t细胞培养a)冻存细胞的复苏i)将恒温水浴锅温度调至37℃,将冻存细胞从液氮中取出,用镊子夹住盖子,在水中快速晃动。ii)将冻存液转移到15ml刻度离心管中,缓慢地加入10ml的细胞培养液,并轻轻的晃动混匀液体。拧紧盖子,过火,1000rpm/min,离心3min。iii)过火,加入适量培养液,轻轻吹打底部的细胞沉淀,然后将细胞转移至培养瓶中放到培养箱中培养。293t细胞使用的培养基为添加10%胎牛血清和100u/ml双抗的高糖dmem,5%co2于37℃培养。b)细胞传代i)倒置显微镜下观察细胞的形态和密度,当细胞在培养瓶中的汇合度到达80%-90%时,开始对细胞进行传代。ii)将细胞培养瓶中的旧培养液洗出来,用pbs清洗3次。向培养瓶中加入500μl的含edta的胰蛋白酶,放入培养箱中孵育1min左右,带细胞间隙变大,细胞变圆时,立即向培养瓶中加入1ml的培养液终止消化,并用吸管轻轻吹打细胞,待细胞全部从瓶底飘起后,将培养瓶中的液体转移到离心管中,1000rpm/min离心2min。iii)弃掉上清,再向离心管中加入2ml培养基使沉淀的细胞重新悬浮。将细胞悬浮液分装到4个新培养瓶中,每个加入4ml的培养液,轻摇培养瓶,使细胞混合均匀铺满培养瓶,放入细胞培养箱中进行培养。iv)转染之前1d,每孔中分别加入密度为80%、细胞舒展、细胞间隙均匀的293t细胞100万,次日细胞长到80-90%汇合度时进行质粒转染。(2)采用pei(聚乙烯亚胺)法转染293t细胞a)取1.5ml的ep管,按以上顺序进行编号,每管中加入250ml的dmem培养基(无血清),依次加入1.5mgaav-cyp4v2-sgrna13质粒;aav-cyp4v2-sgrna17质粒;aav-cyp4v2-sgrna18质粒;aav-cyp4v2-sgrna13-sgrna17质粒;aav-cyp4v2-sgrna13-sgrna18质粒和空载质粒,充分涡旋混匀后,每管加入7.5ml的pei转染试剂,涡旋混匀,室温放置20min后进行转染。另设置阴性对照。b)逐滴加入培养基中(六孔板培养基加无血清dmem=2ml/孔),孵箱培养,12-18h之内半量换液。次日,荧光显微镜下观察gfp的表达情况,以评估转染效率,转染效率良好的情况下继续培养转染后的质粒。c)抗性细胞筛选i)配液:10mg/ml(母液)稀释为1μg/ml的嘌呤霉素,筛选细胞ii)换液:转染后两日,在每个空中(包括阴性对照组)加入3ml含嘌呤霉素的293t细胞培养基,开始筛选转染阳性的细胞,以后每日观察细胞的存活情况,每2日换液,换液时加上相应量的嘌呤霉素。待到阴性对照的孔的细胞完全死亡,而实验组和对照组的细胞有存活的(说明转染成功),停止抗生素筛选,改用正常培养基。3)293t细胞基因组dna的提取a)待6孔板细胞长到80-90%汇合度后,传代到6cm培养皿培养。b)待细胞长到80-90%汇合度后,收细胞,准备提取基因组dna,整个过程在7-10d左右。基因组的提取使用南京诺唯赞细胞提取试剂盒,实验步骤如下:i)400×g离心5min收集细胞,弃上清液。加入220μlpbs、10mlrna酶溶液和20μlpk工作液至样品中,重悬细胞。室温静置15min以上;ii)加入250μlgb缓冲液至细胞重悬液中,涡旋混匀,65℃水浴15-30min,过柱纯化;iii)加入250μl无水乙醇至消化液中,涡旋混匀15-20s;iv)将gdna吸附柱置于2ml收集管中。将上一步所得混合液(包括沉淀)转移至吸附柱中。12000×g离心1min。若出现堵柱现象,再14000×g离心3-5min。若混合液超过750μl需分次过柱。v)弃滤液,将吸附柱置于收集管中。加入500μl清洗缓冲液a至吸附柱中。12000×g离心1min。vi)弃滤液,将吸附柱置于收集管中。加入650μl清洗缓冲液b至吸附柱中。12000×g离心1min。vii)重复步骤4。viii)弃滤液,将吸附柱置于收集管中。12000×g空管离心2min。ix)将吸附柱置于新的1.5ml离心管。加入30-100μl预热至70℃的洗脱缓冲液至吸附柱的膜中央,室温放置3min。12000×g离心1min。注意:对于dna含量丰富的组织,可再加入30-100μl洗脱缓冲液重复洗脱。x)弃掉吸附柱,将dna保存于2-8℃,测浓度并记录,长期保存需放置于-20℃。4)基因组dna包含切割位点pcr片段基因测序,套峰检验。a)将上述dna跨切割靶点设计引物,扩增片段。引物序列见表10。表10基因组dna包含切割位点序列的扩增引物大写字母部分为同源臂序列(pmd-19t-mcs载体mlui与kpni酶切后同源臂)。b)载体线性化及连接质粒载体为pmd-19t-mcs载体,载体线性化方法同前,所用酶为mlui酶与kpni酶,此处不再赘述。将pcr产物回收纯化,测序,连接pmd-19t-mcs线性化载体。方法同前,此处不再赘述。c)质粒转化i)取出transstbl3化学感受态细胞置于冰上解冻。ii)取1μl连接产物至于50μl感受态细胞中,冰上孵育半小时,42度热激90s,冰上2min。iii)加入无抗培养基500μl于37摄氏度,200rpm摇1h。iv)800rpm/min离心5min,弃上清剩约100μl,使用含氨苄抗生素的lb琼脂培养基筛选阳性克隆。v)第二天挑筛选出的阳性克隆菌,各挑取80个送测序。d)阳性率分析经过计算测序峰图,阳性率如下:sgrna13阳性率54%,sgrna17阳性率48.5%,sgrna18阳性率62.5%,sgrna13+17阳性率64%,sgrna13+18阳性率51.2%。可以发现一定程度上,双sgrna阳性率升高。实验结果如图5所示。实施例3donor(供体核酸分子)筛选1.donor设计donor设计采用hdr方法。考虑到sgrna13切割位点在intron6,sgrna17、sgrna18切割位点在exon7,因此,我们在sgrna17与sgrna18切割位点之间选取插入(具体为exon7:c.802+42位点)egfp基因,同时在egfp基因左右各加800bp同源臂。donor设计图如图6所示。donor序列如:seqidno:64-66中任一项所示。2.pmd19-t-donor质粒构建、提取步骤同前,此处不再赘述。3.293t细胞验证donor有效性(1)293t细胞培养步骤同前,此处不再赘述。(2)采用pei(聚乙烯亚胺)法293t细胞共转染1)取1.5ml的ep管,按以上顺序进行编号,每管中加入250μl的dmem培养基(无血清),依次加入1.5μgaav-cyp4v2-sgrna13质粒;aav-cyp4v2-sgrna17质粒;aav-cyp4v2-sgrna18质粒;aav-cyp4v2-sgrna13-sgrna17质粒;aav-cyp4v2-sgrna13-sgrna18质粒和空载质粒,充分涡旋混匀后,每管加入各自对应的1.5μgpmd19-t-donor质粒(对应关系见下表),混匀后各加7.5μl的pei转染试剂,涡旋混匀,室温放置20min后进行转染。另设置阴性对照。表11sgrna和donor序列对应表2)逐滴加入培养基中(六孔板培养基加无血清dmem=2ml/孔),孵箱培养,12-18h之内半量换液。次日,荧光显微镜下观察gfp的表达情况,以评估转染效率,转染效率良好的情况下继续培养转染后的质粒。3)抗性细胞筛选a)配液:10mg/ml(母液)稀释为1μg/ml的嘌呤霉素,筛选细胞。b)换液:转染后两日,在每个空中(包括阴性对照组)加入3ml含嘌呤霉素的293t细胞培养基,开始筛选转染阳性的细胞,以后每日观察细胞的存活情况,每2日换液,换液时加上相应量的嘌呤霉素。待到阴性对照的孔的细胞完全死亡,而实验组和对照组的细胞有存活的(说明转染成功),停止抗生素筛选,改用正常培养基。4)流式细胞筛选将抗生素筛选后细胞(约7天)进行流式细胞筛选,步骤如下:a)吸去六孔板里的培养基,用dpbs(dulbecco's磷酸盐缓冲液)洗2次;b)加入500μl的0.05%胰酶,37℃孵育消化4min;c)加入3-5倍体积的dmem中和胰酶,800r/min,2min离心;d)吸去上清,加入pbs重悬细胞,800r/min,2min离心,重复一次;e)吸去上清,加入200μl含2%的fbs的pbs重悬细胞;f)将上一步所得液体加入过滤管,使其全部通过滤网;g)上机,将筛选后阳性细胞转至12孔板或者6孔板培养。5)293t细胞基因组dna的提取a)待6孔板细胞长到80-90%汇合度后,传代到6cm培养皿培养。b)待细胞长到80-90%汇合度后,收细胞,准备提取基因组dna,整个过程在7-10d左右。基因组的提取使用南京诺唯赞细胞提取试剂盒,实验步骤如上,此处不再赘述。6)目的片段测序a)围绕donor上下游设计引物,同时在引物上下游添加酶切位点。b)载体线性化及连接质粒载体为pmd-19t-mcs载体,载体线性化方法同前,所用酶为mlui酶与kpni酶,此处不再赘述。将pcr产物回收纯化,测序,连接pmd-19t-mcs线性化载体,方法同前,此处不再赘述。c)质粒转化方法同前。d)测序各挑取各个质粒送测序,统计测序结果。实施例4使用患者3d视网膜组织体外验证sgrna的基因编辑效率1.患者肾上皮细胞的提取和培养使用北京赛贝公司提供的肾上皮细胞分离和培养试剂盒进行,实验步骤如下:1)将urineasy分离完全培养基、添加剂、gelatin(明胶)、洗涤液带到细胞间。2)照上紫外灯及12孔板、50ml离心管、15ml离心管、电动移液器、移液管、吸管、5ml枪及枪头、1ml枪及枪头;打开37℃水浴锅。3)取尿:戴手套、消毒、最好中段尿、并用封口膜封口。4)gelatin750μl/孔,包被皿底(3个孔)不少于半小时,置于37℃。5)75%酒精消毒尿瓶外表面,分装至50ml锥形底离心管中,封口后400×g离心10min。6)取出urineasy分离完全培养基+添加剂并配置(每0.5ml添加剂与5ml基础培养基混合)。7)最小速度移液管,沿上液面,缓慢吸取上清至1ml。8)重悬至15ml离心管中,加入10ml洗涤液,混匀,200×g离心10min。9)取出12孔板,吸去gelatin,用洗涤液清洗一次(500μl),每孔加入750μlurineasy分离完全培养基,置于37℃。10)取出15ml离心管,剩余0.2ml细胞团。11)urineasy分离完全培养基重悬细胞团:男性一孔,女性两孔,记为d0(第0天)。12)观察:第1天:观察有无污染;第2天:补充分离培养基——女性:500μl/孔;男性:250μl/孔;第4天:若无贴壁:半量换液,每两天换液,缓慢沿壁加入1ml分离完全培养基。13)直到出现贴壁:细胞出现贴壁(3~7天或9~10天)后,urineasy扩增完全培养基培养两天,500μl,全量换液。贴壁后大概9~12天(不超过14天)80~90%汇合度时传代,依次传代至6孔板,6cm培养皿和10cm培养皿后冻存,备用。(2)ipscs的诱导将患者来源的(c.802-8_810del17bpinsgc)肾上皮细胞诱导成ipscs,步骤如下:1)体细胞汇合度达到70-90%即可进行消化传代,将细胞接种于96孔板中;接种密度控制在5000—15000个/孔,可根据细胞情况设置3个密度梯度,每个梯度设置3个复孔。细胞接种当天记为第-1天。2)第0天:镜下观察细胞的汇合度以及状态,选择不同梯度的复孔进行消化计数,选择细胞量达到10000-20000个的孔进行重编程。重编程培养基a配方如下:重编程培养基a体积体细胞培养基10ml重编程添加剂ⅰ10μl3)先将重编程添加剂ⅱ离心,再将97μl重编程培养基a到加入到重编程添加剂ⅱ管中,混匀配成重编程培养基b,将100μl重编程培养基b加入选定的符合条件的一个96孔中,将培养板放回培养箱。4)第1-2天:镜下观察,并拍照记录细胞的形态变化。若细胞形态变化明显即可撤去重编程培养基b,换为重编程培养基a继续培养;若形态变化不明显,可不换液。5)第3天:若细胞形态在前两天就已经发生了明显的形变,且细胞生长速度较快,可以进行胰酶消化传代。根据细胞状态和细胞量将细胞传至六孔板的2-6个孔,加入重编程培养基c,尽量形成单细胞贴壁。重编程培养基c配方如下:重编程培养基c体积重编程培养基a9.8ml(上述剩余)重编程添加剂ⅲ5μl6)第4天:观察细胞的贴壁情况,若大部分细胞贴壁良好,则更换新鲜的体细胞培养基继续培养。7)第5天:镜下观察,若有小簇克隆(4个细胞以上的克隆团块)形成,可将体细胞培养基换为reproeasy人体细胞重编程培养基。若暂无小簇克隆形成,可继续观察一到两天,再更换reproeasy人体细胞重编程培养基。8)第6-8天:镜下观察,若小簇克隆变大,一个克隆团块有10个以上的细胞,可直接将reproeasy人体细胞重编程培养基换为psceasy人多潜能干细胞培养基(或pgm1人多潜能干细胞培养基)。若换液前观察到死细胞较多,可用室温平衡后的pbs清洗后,再进行换液。9)第9-20天:镜下观察,并拍照记录细胞形态变化。每天更换经过室温平衡的新鲜psceasy人多潜能干细胞培养基。10)第21天:镜下观察,若单个细胞克隆能填满整个10倍镜视野,可用1ml注射器针头(或其他器具如玻璃针)切割克隆,并将其挑取至提前包被matrigel(基质胶)的48孔板中(若克隆状态好,细胞厚实且生长较快,可直接挑取到24孔板中)。11)克隆挑出后用psceasy人多潜能干细胞复苏培养基接种,细胞贴壁后可以更换为psceasy人多潜能干细胞培养基继续培养至所需的代数。(3)患者来源的3d视网膜细胞的诱导具体步骤见表12。表12患者来源的3d视网膜细胞诱导步骤(4)aav8病毒的构建和包被1)质粒扩增。构建好的aav载体(sgrna和donor均改造自质粒px601-aav-cmv-sacas9(addgeneplasmid#61591),为方便描述,下文将sgrna的质粒命名为aav-cyp4v2-sgrna,donor质粒命名为aav-cyp4v2-donor,其中aav-cyp4v2-donor含有部分egfp序列,同上述pmd-19t-donor序列)、包装质粒和辅助质粒需经过大量去内毒素抽提,使用qiagen大抽试剂盒进行质粒的大量抽提,步骤同前。2)aav8-293t细胞转染。转染当天观察细胞密度,80-90%满即可将载体质粒、包装质粒和辅助质粒进行转染。3)aav8病毒收毒:病毒颗粒同时存在于包装细胞和培养上清中。可以将细胞和培养上清都收集下来以获得最好的收率。4)aav的纯化、-80℃长期保存。(5)3d视网膜组织体外验证sgrna基因编辑效率1)使用aav8感染3dretina(视网膜)组织。2)验证基因编辑效率。1)t7e1酶切实验步骤同前。2)topopcr克隆为了将aav-cyp4v2-sgrna,aav-cyp4v2-donor的编辑效率量化并将实验组和对照组的切割效率进行统计学分析,我们使用invitrogen的zeroblunttopopcrcloningkit进行实验,挑菌,sanger(桑格)测序。a)使用3d视网膜组织感染aav病毒后获得的dna作为扩增模板,使用invitrogen的platinumsuperfitm系列的dna聚合酶进行pcr反应,反应体系如下(50μl体系):b)touchdownpcr程序:步骤同前。c)topopcr克隆反应如下配好上述体系,轻轻混匀,室温放置5min;置于冰上,去除感受态细胞,准备转化。d)topopcr克隆反应转化感受态细胞取50或100μl的感受态细胞,加入2μl的上述topopcr克隆反应液体,冰上放置5-30min;42℃热激30s,不要晃动;立刻将反应转至冰上,加入250μl的s.o.c.培养基;37℃,200rpm,摇晃复苏1h;取出相应数量的lb培养板(加入25μg/mlzeocin(博来霉素),取100μl上述菌液进行涂板,置于37℃孵箱过夜培养。e)挑菌送sanger测序。次日早上,取出菌板,每个板子上挑出80个菌;37℃,200rpm,摇菌3-4h;每个菌样取200μl送sanger测序。实施例5在人源化小鼠模型上验证基因编辑效率1.在人源化小鼠模型上验证基因编辑效率1)人源化小鼠的构建人源化小鼠的构建工作由北京百奥赛图公司完成。针对人的突变位点,我们委托北京百奥赛图基因生物技术有限公司构建了cyp4v2人源化的小鼠模型。2)技术内容:a)设计构建识别靶序列的sgrna;b)构建致靶基因切割的crispr/cas9载体;c)sgrna/cas9的活性检测;d)设计构建基因敲进的打靶载体,按照方案中设计的替换6-8号外显子(包括内含子序列);体外转录sgrna/cas9mrna;e)小鼠受精卵注射sgrna/cas9mrna和打靶载体;f)cyp4v2基因敲进f0代小鼠检测及扩繁;g)cyp4v2基因敲进f1代杂合子小鼠的获得及基因型鉴定(southernblotting(dna杂交)验证,包含外源及内源探针各一个)。3)技术方法:a)小鼠基因组靶序列的扩增和测序,设计并构建针对靶序列的crispr/cas9载体质粒,并进行活性检测:b)小鼠基因组dna提取,扩增识别靶序列的sgrna;c)设计并构建致目的序列切割的crispr/cas9载体质粒;d)利用百奥赛图自主开发的检测试剂盒对sgrna/cas9进行活性检测。e)选择高活性的sgrna/cas9靶位点序列信息设计并构建cyp4v2基因敲进的打靶载体;f)小鼠受精卵原核注射sgrna/cas9mrna和打靶载体,f0/f1代阳性小鼠的获得,该项实验过程主要包括如下内容:sgrna/cas9mrna的体外转录;收集小鼠受精卵;小鼠受精卵注射rna和打靶载体;受精卵移植代孕小鼠输卵管;cyp4v2基因人源化点突变的f0代小鼠基因型鉴定及扩繁;cyp4v2基因人源化点突变的f1代小鼠的获得及基因型鉴定(包含pcr检测和southernblotting杂交验证)。(2)饲养和繁育获得两种人源化小鼠之后,让f1代杂合的小鼠进行内交,尽快获得足够数量的f2代或f3代人源化纯合的小鼠,用作aav病毒注射。(3)小鼠视网膜下腔注射aav病毒将aav-cyp4v2-sgrna(提供sacas9)和aav-cyp4v2-donor载体包装成腺相关病毒,注射cyp4v2突变模型小鼠的视网膜,以验证所设计的sgrna和donor在体内的编辑和修复效率。以aav-cyp4v2-sgrna13+aav-cyp4v2-donor13为例(sgrna17-18组实验方法同此。)具体步骤如下:1)实验设计a)空白对照组:生理盐水。b)实验组:aav-cyp4v2-sgrna13(提供sacas9)和aav-cyp4v2-donor13。2)aav(腺相关病毒)血清型选择选择对视网膜偏嗜性好的aav2/8血清型。3)病毒包装将aav-cyp4v2-donor13,aav-cyp4v2-sgrna13载体分别和aav2/8及aav-helper包装成腺相关病毒(aav)。4)小鼠注射实验取20只cyp4v2突变模型小鼠,每组5只分4组进行实验。实验计划如下:a)空白对照组:小鼠每只眼睛注射2μl生理盐水。b)实验组:将包装的aav-cyp4v2-sgrna13和aav-cyp4v2-donor13病毒分别按照1:1的比例等量混合,小鼠每只眼睛注射2μl(1e10vg)。c)一个月后检测治疗效果。实验步骤如下:a)注射前30分钟用1%阿托品散瞳;麻醉前再次散瞳。b)按80mg/kg氯胺酮+8mg/kg甲苯噻嗪安腹腔内注射小鼠,麻醉后将小鼠放置在眼外科手术显微镜的动物实验平台前方,在小鼠眼睛上滴一滴0.5%的丙美卡因局麻。以100:1的浓度在aav病毒里加入荧光素钠原液,低速离心混匀。c)用胰岛素针在小鼠眼睛睫状体平坦部位预扎一个小孔,用微量注射器的针头穿过该小孔后进入小鼠眼睛玻璃体腔,这时在小鼠眼睛上滴加适量2%羟甲基纤维素使在镜下能清晰见到小鼠眼底,再继续将针头避开玻璃体插入对侧周边的视网膜下,缓慢推入带有荧光素钠的aav病毒,每只眼睛注射量为1μl,以荧光素钠为指示剂判断是否注射入视网膜下腔。d)术后观察小鼠有无异常,给予新霉素眼膏预防感染。5)评价基因编辑治疗的效果:实验结果发现各实验组治疗效果基本一致,因此选取aav-cyp4v2-sgrna13和aav-cyp4v2-donor13病毒组为代表来说明基因编辑治疗效果。(4)评估aav8-aav-cyp4v2-sgrna在人源化小鼠中的编辑效率验证方法见“实施例4中(5)3d视网膜组织体外验证sgrna基因编辑效率”。实验结果发现各实验组治疗效果基本一致,因此选取aav-cyp4v2-sgrna13和aav-cyp4v2-donor13病毒组为代表来说明基因编辑治疗效果。通过erg(视网膜电生理)评价治疗后小鼠功能改变,在治疗后,突变小鼠模型的视网膜功能有改善;取材切片后,通过he染色观察小鼠视网膜形态学变化,形态接近野生型小鼠的视网膜状态;通过免疫荧光染色观察基因编辑治疗载体是否在视网膜相应位置表达,基因编辑治疗载体在视网膜相应位置表达;通过一系列视网膜特殊marker的染色标记观察视网膜组织形态变化,发现治疗后,小鼠的视网膜组织形态有改善。最后应说明的是:以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。序列表<110>北京大学第三医院(北京大学第三临床医学院);北京中因科技有限公司<120>用于治疗结晶样视网膜变性的核酸分子及其用途<130>0138-pa-006cn<160>91<170>patentinversion3.5<210>1<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna1<400>1catttcattggcccgttcgct21<210>2<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna2<400>2atcacatgcttctgtttggac21<210>3<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna3<400>3agcatgtgattatcattcaaa21<210>4<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna4<400>4tgtgattatcattcaaagcga21<210>5<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna5<400>5tcattcaaagcgaacgggcca21<210>6<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna6<400>6caaagcgaacgggccaatgaa21<210>7<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna7<400>7tagggtgcatccaagtccaaa21<210>8<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna8<400>8gggccaatgaaatgaacgcca21<210>9<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna9<400>9gaagactgtagaggtgatggc21<210>10<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna10<400>10ggccctgcgtttatttttgga21<210>11<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna11<400>11tgccccctccaaaaataaacg21<210>12<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna12<400>12gaaataggcttagaaaaataa21<210>13<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna13<400>13taggcttagaaaaataaatga21<210>14<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna14<400>14aaagaaactagcatattttat21<210>15<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna15<400>15tttataagaaaatgtgttaac21<210>16<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna16<400>16atgataatcacatgcttctgt21<210>17<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna17<400>17aatgaacgccaatgaagactg21<210>18<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna18<400>18tgaagactgtagaggtgatgg21<210>19<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna19<400>19tgcgtttatttttggaggggg21<210>20<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna20<400>20aggccctgcgtttatttttgg21<210>21<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna21<400>21aaggccctgcgtttatttttg21<210>22<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna22<400>22gaaaggccctgcgtttatttt21<210>23<211>21<212>dna<213>人工序列(artificialsequence)<220><223>sgrna23<400>23agaaaggccctgcgtttattt21<210>24<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna1-pam1<400>24ttgaa5<210>25<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna2/16/23<400>25ttgga5<210>26<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna3-pam3<400>26gcgaa5<210>27<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna4-pam4<400>27acggg5<210>28<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna5/6/8/12<400>28atgaa5<210>29<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna7-pam7<400>29cagaa5<210>30<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna9/20<400>30agggg5<210>31<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna10-pam10<400>31ggggg5<210>32<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna11/18<400>32caggg5<210>33<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna13/14<400>33aagaa5<210>34<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna15-pam15<400>34taggg5<210>35<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna17-pam17<400>35tagag5<210>36<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna19-pam19<400>36cagag5<210>37<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna21-pam21<400>37gaggg5<210>38<211>5<212>dna<213>人工序列(artificialsequence)<220><223>sgrna22-pam22<400>38tggag5<210>39<211>39<212>dna<213>人工序列(artificialsequence)<220><223>f-cyp-sgrna<400>39taatacgactcactataggttttagtactctggaaacag39<210>40<211>22<212>dna<213>人工序列(artificialsequence)<220><223>r-cyp-sgrna<400>40atctcgccaacaagttgacgag22<210>41<211>22<212>dna<213>人工序列(artificialsequence)<220><223>f-s-cyp4v2-dsdna<400>41ttagcgcaatccaatctctagg22<210>42<211>23<212>dna<213>人工序列(artificialsequence)<220><223>r1-s-cyp4v2-dsdna<400>42cttcatgacttagcctgttccct23<210>43<211>21<212>dna<213>人工序列(artificialsequence)<220><223>r2-s-cyp4v2-dsdna<400>43ccacatggagaactgagagca21<210>44<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna8-f<400>44acacggggccaatgaaatgaacgccag27<210>45<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna8-r<400>45aaaactggcgttcatttcattggcccc27<210>46<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna12-f<400>46acacggaaataggcttagaaaaataag27<210>47<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna12-r<400>47aaaacttatttttctaagcctatttcc27<210>48<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna13-f<400>48acacgtaggcttagaaaaataaatgag27<210>49<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna13-r<400>49aaaactcatttatttttctaagcctac27<210>50<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna14-f<400>50acacgaaagaaactagcatattttatg27<210>51<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna14-r<400>51aaaacataaaatatgctagtttctttc27<210>52<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna16-f<400>52acacgatgataatcacatgcttctgtg27<210>53<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna16-r<400>53aaaacatgataatcacatgcttctgtc27<210>54<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna17-f<400>54acacgaatgaacgccaatgaagactgg27<210>55<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna17-r<400>55aaaaccagtcttcattggcgttcattc27<210>56<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna18-f<400>56acacgtgaagactgtagaggtgatggg27<210>57<211>27<212>dna<213>人工序列(artificialsequence)<220><223>cyp4v2-sgrna18-r<400>57aaaacccatcacctctacagtcttcac27<210>58<211>22<212>dna<213>人工序列(artificialsequence)<220><223>t7e1-f<400>58ctcattagcgcaatccaatctc22<210>59<211>20<212>dna<213>人工序列(artificialsequence)<220><223>t7e1-r<400>59agcaatctctggctgctctt20<210>60<211>46<212>dna<213>人工序列(artificialsequence)<220><223>u6-sacffold-f<400>60cttgttggcgagatttttgcggccgagggcctatttcccatgattc46<210>61<211>20<212>dna<213>人工序列(artificialsequence)<220><223>u6-sacffold-r<400>61ccatcactaggggttcctgc20<210>62<211>42<212>dna<213>人工序列(artificialsequence)<220><223>f<400>62agagattttaattaaggtacctcattagcgcaatccaatctc42<210>63<211>40<212>dna<213>人工序列(artificialsequence)<220><223>r<400>63gaaacatgtattaatacgcgagcaatctctggctgctctt40<210>64<211>2503<212>dna<213>人工序列(artificialsequence)<220><223>donor13<400>64ttctttcatttatttttctaagcctagtagcaggtttggtcaattacctggtaggaaaag60aaggttgaaatgtacaaccaaattaagtgtattggccttcattcttttatccatccaaga120aatatctagtgagtatttgttaaatgccaagcagtgctctagaggttggaaatgtatcaa180tgaacaaagacatgcacaagcatggcagtgtttgagttgtaagagaaagatgctaaataa240taagtataacgtaagtataatatcacattataataataagtatgacagaagtatcacata300atgtcaggtggcaagggaaatggagaaaaagcattgttaggaggcgtcgcagtgctaggg360acaggggtagcagggatgagggaggtctctctgatcgtgtgacaatgagcagagatctgg420aagaagggagggggcagccgtgcaggcctctgaggaaagcatttcaggcagcagaaatcg480caagcatagagggtgaattcactaatctgcttgctgtttcttttctcctctacaacatgt540aattaagtctataattagactgttgtataatgattgcattcactctaccacttaaacttt600ttctcattagcgcaatccaatctctagggtactatctagtagactatgattctattcttg660tgttggaaagactgcaaaaatagcacttgaaaattaggaatttgcgtgacattaaatttg720tttttaaaagtttcaccagataatccccaaaatattaatgaggctttactgtattttcac780aagagcctatgttgtcgaaatgttgaaataggcttagaaaaataaatgaaaaaaactagc840atattttataagaaaatgtgttaactagggtgcatccaagtccaaacagaagcatgtgat900tatcattcaaatcatacaggtcatcgctgaacgggccaatgaaatgaacgccaatgaaga960catggtgagcaagggcgaggagctgttcaccggggtggtgcccatcctggtcgagctgga1020cggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgagggcgatgccaccta1080cggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgtgccctggcccac1140cctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccccgaccacatgaa1200gcagcacgacttcttcaagtccgccatgcccgaaggctacgtccaggagcgcaccatctt1260cttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcgagggcgacaccct1320ggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaacatcctggggca1380caagctggagtacaactacaacagccacaacgtctatatcatggccgacaagcagaagaa1440cggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcagcgtgcagctcgc1500cgaccactaccagcagaacacccccatcggcgacggccccgtgctgctgcccgacaacca1560ctacctgagcacccagtccgccctgagcaaagaccccaacgagaagcgcgatcacatggt1620cctgctggagttcgtgaccgccgccgggatcactctcggcatggacgagctgtacaagtg1680tagaggtgatggcaggggctctgccccctccaaaaataaacgcagggcctttcttgactt1740gcttttaagtgtgactgatgacgaagggaacaggctaagtcatgaagatattcgagaaga1800agttgacaccttcatgtttgaggtattgtatattgttaggttcagatatcattaaacaaa1860tttcagttattgttagaatctttagcattattttttaaaacaatcaaattttaaagtagt1920ttaactaaagaagattcattatattttaattagaaattacaaaatttaagaaactgatta1980agtaccagctcaacttcttcagaaaacgattttgactagtgctgggcacagcagtagaca2040catttgtttttcctcaagaaaacctaagatttgtcagagttttcccaagcagaagagcag2100ccagagattgctctcagttctccatgtggcttcaggcttccttctaacctcccagacatg2160caagtccacttcctcaccacctgctttctgaggttccagcagatgagcacttagctgctg2220ccatgagctactctacctagaggacagttaagagccctccaacagagaatcagccagttc2280atgattctaaaaagatctctgatctcaaatttatacatacatatgtgaagtacattttag2340caagatagcctaaatattaaatcctacaaagagggactttctctatatgtggattgcaaa2400ataaataaaacatggtttttagaagccatgtagtaatatcgtccacatggggcagagtga2460aaggcacctgagtttttttctttcatttatttttctaagccta2503<210>65<211>2503<212>dna<213>人工序列(artificialsequence)<220><223>donor17<400>65ctctacagtcttcattggcgttcattgtagcaggtttggtcaattacctggtaggaaaag60aaggttgaaatgtacaaccaaattaagtgtattggccttcattcttttatccatccaaga120aatatctagtgagtatttgttaaatgccaagcagtgctctagaggttggaaatgtatcaa180tgaacaaagacatgcacaagcatggcagtgtttgagttgtaagagaaagatgctaaataa240taagtataacgtaagtataatatcacattataataataagtatgacagaagtatcacata300atgtcaggtggcaagggaaatggagaaaaagcattgttaggaggcgtcgcagtgctaggg360acaggggtagcagggatgagggaggtctctctgatcgtgtgacaatgagcagagatctgg420aagaagggagggggcagccgtgcaggcctctgaggaaagcatttcaggcagcagaaatcg480caagcatagagggtgaattcactaatctgcttgctgtttcttttctcctctacaacatgt540aattaagtctataattagactgttgtataatgattgcattcactctaccacttaaacttt600ttctcattagcgcaatccaatctctagggtactatctagtagactatgattctattcttg660tgttggaaagactgcaaaaatagcacttgaaaattaggaatttgcgtgacattaaatttg720tttttaaaagtttcaccagataatccccaaaatattaatgaggctttactgtattttcac780aagagcctatgttgtcgaaatgttgaaataggcttagaaaaataaatgaaaaaaactagc840atattttataagaaaatgtgttaactagggtgcatccaagtccaaacagaagcatgtgat900tatcattcaaatcatacaggtcatcgctgaacgggccaatgaaatgaacgccaatgaaga960catggtgagcaagggcgaggagctgttcaccggggtggtgcccatcctggtcgagctgga1020cggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgagggcgatgccaccta1080cggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgtgccctggcccac1140cctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccccgaccacatgaa1200gcagcacgacttcttcaagtccgccatgcccgaaggctacgtccaggagcgcaccatctt1260cttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcgagggcgacaccct1320ggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaacatcctggggca1380caagctggagtacaactacaacagccacaacgtctatatcatggccgacaagcagaagaa1440cggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcagcgtgcagctcgc1500cgaccactaccagcagaacacccccatcggcgacggccccgtgctgctgcccgacaacca1560ctacctgagcacccagtccgccctgagcaaagaccccaacgagaagcgcgatcacatggt1620cctgctggagttcgtgaccgccgccgggatcactctcggcatggacgagctgtacaagtg1680tagaggtgatggcaggggctctgccccctccaaaaataaacgcagggcctttcttgactt1740gcttttaagtgtgactgatgacgaagggaacaggctaagtcatgaagatattcgagaaga1800agttgacaccttcatgtttgaggtattgtatattgttaggttcagatatcattaaacaaa1860tttcagttattgttagaatctttagcattattttttaaaacaatcaaattttaaagtagt1920ttaactaaagaagattcattatattttaattagaaattacaaaatttaagaaactgatta1980agtaccagctcaacttcttcagaaaacgattttgactagtgctgggcacagcagtagaca2040catttgtttttcctcaagaaaacctaagatttgtcagagttttcccaagcagaagagcag2100ccagagattgctctcagttctccatgtggcttcaggcttccttctaacctcccagacatg2160caagtccacttcctcaccacctgctttctgaggttccagcagatgagcacttagctgctg2220ccatgagctactctacctagaggacagttaagagccctccaacagagaatcagccagttc2280atgattctaaaaagatctctgatctcaaatttatacatacatatgtgaagtacattttag2340caagatagcctaaatattaaatcctacaaagagggactttctctatatgtggattgcaaa2400ataaataaaacatggtttttagaagccatgtagtaatatcgtccacatggggcagagtga2460aaggcacctgagtttttctctacagtcttcattggcgttcatt2503<210>66<211>2503<212>dna<213>人工序列(artificialsequence)<220><223>donor18<400>66ccctgccatcacctctacagtcttcagtagcaggtttggtcaattacctggtaggaaaag60aaggttgaaatgtacaaccaaattaagtgtattggccttcattcttttatccatccaaga120aatatctagtgagtatttgttaaatgccaagcagtgctctagaggttggaaatgtatcaa180tgaacaaagacatgcacaagcatggcagtgtttgagttgtaagagaaagatgctaaataa240taagtataacgtaagtataatatcacattataataataagtatgacagaagtatcacata300atgtcaggtggcaagggaaatggagaaaaagcattgttaggaggcgtcgcagtgctaggg360acaggggtagcagggatgagggaggtctctctgatcgtgtgacaatgagcagagatctgg420aagaagggagggggcagccgtgcaggcctctgaggaaagcatttcaggcagcagaaatcg480caagcatagagggtgaattcactaatctgcttgctgtttcttttctcctctacaacatgt540aattaagtctataattagactgttgtataatgattgcattcactctaccacttaaacttt600ttctcattagcgcaatccaatctctagggtactatctagtagactatgattctattcttg660tgttggaaagactgcaaaaatagcacttgaaaattaggaatttgcgtgacattaaatttg720tttttaaaagtttcaccagataatccccaaaatattaatgaggctttactgtattttcac780aagagcctatgttgtcgaaatgttgaaataggcttagaaaaataaatgaaaaaaactagc840atattttataagaaaatgtgttaactagggtgcatccaagtccaaacagaagcatgtgat900tatcattcaaatcatacaggtcatcgctgaacgggccaatgaaatgaacgccaatgaaga960catggtgagcaagggcgaggagctgttcaccggggtggtgcccatcctggtcgagctgga1020cggcgacgtaaacggccacaagttcagcgtgtccggcgagggcgagggcgatgccaccta1080cggcaagctgaccctgaagttcatctgcaccaccggcaagctgcccgtgccctggcccac1140cctcgtgaccaccctgacctacggcgtgcagtgcttcagccgctaccccgaccacatgaa1200gcagcacgacttcttcaagtccgccatgcccgaaggctacgtccaggagcgcaccatctt1260cttcaaggacgacggcaactacaagacccgcgccgaggtgaagttcgagggcgacaccct1320ggtgaaccgcatcgagctgaagggcatcgacttcaaggaggacggcaacatcctggggca1380caagctggagtacaactacaacagccacaacgtctatatcatggccgacaagcagaagaa1440cggcatcaaggtgaacttcaagatccgccacaacatcgaggacggcagcgtgcagctcgc1500cgaccactaccagcagaacacccccatcggcgacggccccgtgctgctgcccgacaacca1560ctacctgagcacccagtccgccctgagcaaagaccccaacgagaagcgcgatcacatggt1620cctgctggagttcgtgaccgccgccgggatcactctcggcatggacgagctgtacaagtg1680tagaggtgatggcaggggctctgccccctccaaaaataaacgcagggcctttcttgactt1740gcttttaagtgtgactgatgacgaagggaacaggctaagtcatgaagatattcgagaaga1800agttgacaccttcatgtttgaggtattgtatattgttaggttcagatatcattaaacaaa1860tttcagttattgttagaatctttagcattattttttaaaacaatcaaattttaaagtagt1920ttaactaaagaagattcattatattttaattagaaattacaaaatttaagaaactgatta1980agtaccagctcaacttcttcagaaaacgattttgactagtgctgggcacagcagtagaca2040catttgtttttcctcaagaaaacctaagatttgtcagagttttcccaagcagaagagcag2100ccagagattgctctcagttctccatgtggcttcaggcttccttctaacctcccagacatg2160caagtccacttcctcaccacctgctttctgaggttccagcagatgagcacttagctgctg2220ccatgagctactctacctagaggacagttaagagccctccaacagagaatcagccagttc2280atgattctaaaaagatctctgatctcaaatttatacatacatatgtgaagtacattttag2340caagatagcctaaatattaaatcctacaaagagggactttctctatatgtggattgcaaa2400ataaataaaacatggtttttagaagccatgtagtaatatcgtccacatggggcagagtga2460aaggcacctgagtttttccctgccatcacctctacagtcttca2503<210>67<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna1-rna<400>67cauuucauuggcccguucgcu21<210>68<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna2-rna<400>68aucacaugcuucuguuuggac21<210>69<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna3-rna<400>69agcaugugauuaucauucaaa21<210>70<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna4-rna<400>70ugugauuaucauucaaagcga21<210>71<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna5-rna<400>71ucauucaaagcgaacgggcca21<210>72<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna6-rna<400>72caaagcgaacgggccaaugaa21<210>73<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna7-rna<400>73uagggugcauccaaguccaaa21<210>74<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna8-rna<400>74gggccaaugaaaugaacgcca21<210>75<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna9-rna<400>75gaagacuguagaggugauggc21<210>76<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna10-rna<400>76ggcccugcguuuauuuuugga21<210>77<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna11-rna<400>77ugcccccuccaaaaauaaacg21<210>78<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna12-rna<400>78gaaauaggcuuagaaaaauaa21<210>79<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna13-rna<400>79uaggcuuagaaaaauaaauga21<210>80<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna14-rna<400>80aaagaaacuagcauauuuuau21<210>81<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna15-rna<400>81uuuauaagaaaauguguuaac21<210>82<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna16-rna<400>82augauaaucacaugcuucugu21<210>83<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna17-rna<400>83aaugaacgccaaugaagacug21<210>84<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna18-rna<400>84ugaagacuguagaggugaugg21<210>85<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna19-rna<400>85ugcguuuauuuuuggaggggg21<210>86<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna20-rna<400>86aggcccugcguuuauuuuugg21<210>87<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna21-rna<400>87aaggcccugcguuuauuuuug21<210>88<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna22-rna<400>88gaaaggcccugcguuuauuuu21<210>89<211>21<212>rna<213>人工序列(artificialsequence)<220><223>sgrna23-rna<400>89agaaaggcccugcguuuauuu21<210>90<211>21<212>dna<213>人工序列(artificialsequence)<220><223>示例性的野生型cyp4v2内含子6和外显子7交界处核苷酸序列<400>90caaacagaagcatgtgattatcattcaaatcatacaggtcatcgctgaacgggccaatga60aatgaacgccaatga75<210>91<211>21<212>dna<213>人工序列(artificialsequence)<220><223>示例性的c.802-8_810dell7insgc突变型cyp4v2内含子6和外显子7交界处核苷酸序列<400>91caaacagaagcatgtgattatcattcaaagcgaacgggccaatgaaatgaacgccaatga60当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1