L型环状氨基酸的制造方法与流程
l型环状氨基酸的制造方法
技术领域
1.本发明涉及在产业上有用的l型环状氨基酸的制造方法。
背景技术:
2.l型环状氨基酸是作为凝血酶抑制剂、hiv蛋白酶抑制剂、nmda受体拮抗剂、tnf-α转换酶抑制剂、血管紧张素转换酶抑制剂、抗炎剂等的药物中间原料有用的物质。
3.作为l型环状氨基酸,已知下述化学式所示的l-脯氨酸(l-proline)、l-羟脯氨酸(l-hydroxyproline)等5元环氨基酸、l-哌可酸(l-pipecolic acid)等6元环氨基酸、氮杂环丁烷-2-甲酸(azetidine-2-carboxylic acid)等4元环氨基酸等氨基酸。
[0004][0005]
另外,还已知作为杂环的l-硫代脯氨酸(l-thioproline)、l-吗啉甲酸(l-3-morpholine carboxylic acid)、l-硫代吗啉甲酸(l-3-thiomor pholine carboxylic acid)等作为药物中间原料有用的物质。
[0006][0007]
作为l型环状氨基酸的制造方法,已知有机合成方法、生物化学方法。
[0008]
作为通过有机合成方式制造l型环状氨基酸的方法,已知garcia等人提出的哌可酸(pipecolic acid)的制造方法(非专利文献1)等。但是,这些方法难以称为光学纯度、收率均能够在工业上实用化的方法。
[0009]
作为通过生物化学方式制造l型环状氨基酸的方法,已知利用吡咯啉-5-羧酸还原酶(ec 1.5.1.2)的由l-赖氨酸(l-lysine)起始的l-哌可酸(l-pipecolic acid)的制造方法(非专利文献2)、利用鸟氨酸环化脱氨酶的由l-鸟氨酸起始的l-脯氨酸的制造方法(非专利文献3)、利用鸟氨酸环化脱氨酶的由各种二氨基酸(diamino acid)起始的各种环状氨基酸的制造方法(专利文献1)等。
[0010]
fujii等人(非专利文献2)报道的方法为对l-赖氨酸使用l-赖氨酸6-氨基转移酶(l-lysine 6-aminotransferase)而生成作为中间体的δ
1-哌啶-6-甲酸、再使还原酶与其接触而得到l-哌可酸(l-pipecolic acid)的方法,但该方法仅能够应对原料为l-赖氨酸的情况,不能适应于其它l型环状氨基酸的制造。
[0011]
costilow等人(非专利文献3:journal of biological chemistry(1971))报道的方法为对l-鸟氨酸(l-ornithine)使用鸟氨酸环化酶(ornithine cyclase)而得到l-脯氨酸(l-proline)的方法,但是关于脯氨酸以外的产物则没有记载。
[0012]
denis等人(专利文献1)报道了使用鸟氨酸环化酶得到l-哌可酸(l-pipecolic acid)、l-硫代吗啉-2-甲酸(l-thiomorpholine-2-carboxylic acid)、5-羟基-l-哌可酸(5-hydroxy-l-pipecolic acid)等的方法,但是没有关于收率、光学纯度等的记载。
[0013]
另外,在上述任一方法中,作为产物的l型环状氨基酸的光学纯度均取决于原料氨基酸的光学纯度,认为由外消旋体的原料难以以高效率得到l型环状氨基酸。
[0014]
另一方面,经由在1位具有双键的环状氨基酸作为中间体的方法能够使用外消旋体的环状氨基酸、二氨基酸作为原料,因此在工业上有利。
[0015]
例如,作为对在1位具有双键的环状氨基酸进行还原的酶,报道了例如:来自动物或来自霉菌的吡咯啉-2-羧酸还原酶(pyrroline-2-carboxylate reductase:ec 1.5.1.1)将δ
1-吡咯啉-2-甲酸(δ
1-pyrroline-2-carboxylic acid)还原而生成脯氨酸、以及将δ
1-哌啶-2-甲酸(δ
1-piperidine-2-carboxylic acid)还原而生成哌可酸(非专利文献4)。
[0016]
另外,报道了以δ
1-哌啶-2-甲酸(δ
1-piperidine-2-carboxylic acid)为中间体由d-赖氨酸生成l-哌可酸的假单胞菌(pseudomonas)属细菌的代谢,其中还报道了哌啶-2-羧酸还原酶(piperideine-2-carboxylate reductase:ec 1.5.1.21)进行还原反应(非专利文献5)。
[0017]
但是,这些报道仅是在生物化学上确认到酶反应,并不是工业化生产的例子。
[0018]
另外,还记载了来自动物的酶非常不稳定,使用这些酶的工业化生产难以实用化。
[0019]
专利文献2记载了:由二氨基酸、外消旋体的环状氨基酸得到作为中间体的在1位具有双键的环状氨基酸,将其用来自假单胞菌属细菌的n-甲基-l-氨基酸脱氢酶还原而制造l型环状氨基酸。该方法想要提供廉价地生产高纯度的l型环状氨基酸的方法,但是为了在工业上进行实用化,要求以更高效率生成l型环状氨基酸。
[0020]
现有技术文献
[0021]
专利文献
[0022]
专利文献1:wo 02/101003
[0023]
专利文献2:日本专利第4590981号
[0024]
非专利文献
[0025]
非专利文献1:concepcion f garcia et al.,tetrahedron asymmetry(1995)vol.6,pp.2905-2906
[0026]
非专利文献2:tadashi fujii et al.,bioscience biotechnology biochem(2002)vol.66,pp.1981-1984
[0027]
非专利文献3:ralph n costilow et al.,journal of biological chemistry(1971)vol.246,pp.6655-6660
[0028]
非专利文献4:alton meister et al.,journal of biological chemistry(1957)vol.229,pp.789-800
[0029]
非专利文献5:cecil w payton et al.,journal of bacteriology(1982)
vol.149,pp.864-871
技术实现要素:
[0030]
发明所要解决的问题
[0031]
本发明的课题在于,提供更廉价、高效率且工业化地由在1位具有双键的环状氨基酸制造高纯度的l型环状氨基酸的方法。另外,本发明的课题还在于,提供通过由廉价的二氨基酸得到作为中间体的在1位具有双键的环状氨基酸、将其利用生物化学方法还原而更廉价、高效率且工业化地制造高纯度的l型环状氨基酸的方法。
[0032]
用于解决问题的方法
[0033]
认为通过使用具有将在1位具有双键的环状氨基酸还原而生成l型环状氨基酸的催化性能、在酶学上稳定且上述催化性能高的亚氨基酸还原酶而解决上述课题,能够更廉价、高效率且工业化地制造高纯度的l型环状氨基酸。
[0034]
本发明人们为了解决上述课题进行了深入研究,结果发现,来自拟南芥、海滨山黧豆或桑的亚氨基酸还原酶以高于公知的酶的催化效率将在1位具有双键的环状氨基酸还原。
[0035]
另外,在1位具有双键的环状氨基酸可以使用公知的酶由廉价的二氨基酸高效率地制造。因此,发现通过将由二氨基酸制造在1位具有双键的环状氨基酸的方法与以高的催化效率将在1位具有双键的环状氨基酸还原的方法组合,能够更廉价、高效率且工业化地由廉价的二氨基酸制造作为药物中间原料有用的高纯度的l型环状氨基酸。
[0036]
本发明是基于这些见解而完成的。
[0037]
即,本发明如下所述。
[0038]
[1]一种l型环状氨基酸的制造方法,其特征在于,使以下的(a)、(b)或(c)所示的多肽、具有生产上述多肽的能力或包含上述多肽的微生物或细胞、上述微生物或细胞的处理物和/或对上述微生物或细胞进行培养而得到的包含上述多肽的培养液与下述通式(i)所示的在1位具有双键的环状氨基酸接触,生成下述通式(ii)所示的l型环状氨基酸,
[0039][0040]
(式中,a表示链长为1~4原子、可在链中或末端包含选自由硫原子、氧原子和氮原子组成的组中的至少一种杂原子、且可具有取代基的亚烷基链。)
[0041][0042]
(式中,a与上述含义相同。)
[0043]
(a)具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽;
[0044]
(b)为在序列号2、4、6、8、10或12所示的氨基酸序列中缺失、置换和/或添加1个~两个以上氨基酸而成的氨基酸序列、且催化下述式(1)所示的反应的具有l型环状氨基酸生
成能力的多肽,
[0045]
式(1):
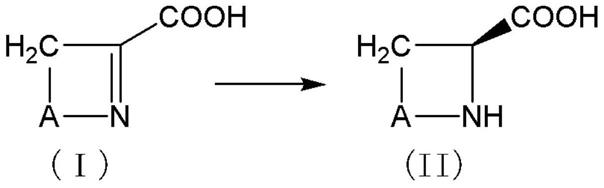
[0046]
(式中,a与上述含义相同。);或者
[0047]
(c)具有与序列号2、4、6、8、10或12所示的氨基酸序列具有90%以上的序列一致性的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。
[0048]
[2]根据[1]所述的制造方法,其中,上述多肽由以下的(d)、(e)或(f)所示的核酸编码:
[0049]
(d)包含序列号1、3、5、7、9或11所示的碱基序列的核酸;
[0050]
(e)为在序列号1、3、5、7、9或11所示的碱基序列中置换、缺失和/或添加1个或两个以上碱基而成的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸;或者
[0051]
(f)为与序列号1、3、5、7、9或11所示的碱基序列的互补链在严格条件下进行杂交的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸。
[0052]
[3]一种l型环状氨基酸的制造方法,其特征在于,使能够将二氨基酸的α位的氨基转换为酮基而生成α酮酸的酶与下述通式(iii)所示的链状的α,ω-二氨基酸反应,生成下述通式(i)所示的在1位具有双键的环状氨基酸,然后利用[1]或[2]所述的方法使所得到的在1位具有双键的环状氨基酸生成下述通式(ii)所示的l型环状氨基酸。
[0053][0054]
(式中,a表示链长为1~4原子、可在链中或末端包含选自由硫原子、氧原子和氮原子组成的组中的至少一种杂原子、且可具有取代基的亚烷基链。)
[0055][0056]
(式中,a与上述含义相同。)
[0057]
[0058]
(式中,a与上述含义相同。)
[0059]
[4]根据[3]所述的l型环状氨基酸的制造方法,其中,能够将二氨基酸的α位的氨基转换为酮基而生成α酮酸的酶为选自由d-氨基酸氧化酶、l-氨基酸氧化酶、d-氨基酸脱氢酶、l-氨基酸脱氢酶、d-氨基酸转移酶和l-氨基酸转移酶组成的组中的一种以上的酶。
[0060]
[5]根据[1]~[4]中任一项所述的l型环状氨基酸的制造方法,其中,上述通式(i)所示的在1位具有双键的环状氨基酸为δ
1-哌啶-2-甲酸,上述通式(ii)所示的l型环状氨基酸为l-哌可酸。
[0061]
[6]一种多肽,其为:
[0062]
(a)具有序列号4、6、8、10或12所示的氨基酸序列的多肽;
[0063]
(b)为在序列号2、4、6、8、10或12所示的氨基酸序列中缺失、置换和/或添加1个~两个以上氨基酸而成的氨基酸序列、且催化下述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽,
[0064]
式(1):
[0065]
(式中,a表示链长为1~4原子、可在链中或末端包含选自由硫原子、氧原子和氮原子组成的组中的至少一种杂原子、且可具有取代基的亚烷基链。);或者
[0066]
(c)具有与序列号2、4、6、8、10或12所示的氨基酸序列具有90%以上的序列一致性的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。
[0067]
[7]一种核酸,其编码[6]所述的多肽。
[0068]
[8]根据[7]所述的核酸,其中,核酸来自植物。
[0069]
[9]根据[8]所述的核酸,其中,植物为桑或海滨山黧豆。
[0070]
[10]根据[7]~[9]中任一项所述的核酸,其中,上述核酸为以下的(d)、(e)或(f)所示的核酸:
[0071]
(d)包含序列号3、5、7、9或11所示的碱基序列的核酸;
[0072]
(e)为在序列号1、3、5、7、9或11所示的碱基序列中置换、缺失和/或添加1个或两个以上碱基而成的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸;或者
[0073]
(f)为与序列号1、3、5、7、9或11所示的碱基序列的互补链在严格条件下进行杂交的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸。
[0074]
[11]一种重组载体,其包含[7]~[10]中任一项所述的核酸。
[0075]
[12]一种转化体,其包含[11]所述的重组载体。
[0076]
[13]一种酶制剂组合物,其包含:以下的(a)、(b)或(c)所示的多肽、具有生产上述多肽的能力或包含上述多肽的微生物或细胞、上述微生物或细胞的处理物和/或对上述微生物或细胞进行培养而得到的包含上述多肽的培养液,
[0077]
具有由下述通式(i)所示的在1位具有双键的环状氨基酸生成下述通式(ii)所示
的l型环状氨基酸的能力,
[0078][0079]
(式中,a表示链长为1~4原子、可在链中或末端包含选自由硫原子、氧原子和氮原子组成的组中的至少一种杂原子、且可具有取代基的亚烷基链。)
[0080][0081]
(式中,a与上述含义相同。)
[0082]
(a)具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽;
[0083]
(b)为在序列号2、4、6、8、10或12所示的氨基酸序列中缺失、置换和/或添加1个~两个以上氨基酸而成的氨基酸序列、且催化下述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽,
[0084]
式(1)
[0085]
(式中,a与上述含义相同。);或者
[0086]
(c)具有与序列号2、4、6、8、10或12所示的氨基酸序列具有90%以上的序列一致性的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。
[0087]
发明效果
[0088]
根据本发明,通过使用具有将在1位具有双键的环状氨基酸还原而生成l型环状氨基酸的催化性能、在酶学上稳定且上述催化性能高的酶,能够更廉价、高效率且工业化地制造高纯度的l型环状氨基酸。另外,通过将由二氨基酸制造在1位具有双键的环状氨基酸的方法与以高的催化效率将在1位具有双键的环状氨基酸还原的方法组合,能够更廉价、高效率且工业化地由廉价的二氨基酸制造作为药物中间原料有用的高纯度的l型环状氨基酸。
附图说明
[0089]
图1为示出实施例2的(2)酶反应产物的解析中的、生成的哌可酸的hplc分析结果的图。
[0090]
图2为示出实施例2的(3)酶催化活性的解析中的、哈尼斯-伍尔夫图(hanes-woolf plot)的线性近似线的图。
[0091]
图3为示出实施例2的(3)酶催化活性的解析中的、基于anemona的米海利斯-曼恬模型(michaelis-menten model)的图。
具体实施方式
[0092]
以下对本发明进行详细说明。
[0093]
本发明的通式(i)、(ii)及(iii)中,a表示链长为1~4原子、可在链中或末端包含选自由硫原子、氧原子和氮原子组成的组中的至少一种杂原子、且可具有取代基的亚烷基链。
[0094]
作为亚烷基链,可列举例如-ch
2-、-c2h
4-、-c3h
6-、-c2h3ch
3-、-c4h
8-、-c3h5ch
3-、-ch2chch3ch
2-等碳原子数1~4的直链状或支链状亚烷基链。这些中,优选能够形成5元环、6元环或7元环的l型环状氨基酸的碳原子数2~4的直链状亚烷基链。例如,a的碳原子数为2的情况下形成l-脯氨酸(proline)等5元环氨基酸,碳原子数为3的情况下形成l-哌可酸(pipecolic acid)等6元环氨基酸,碳原子数为4的情况下形成氮杂环庚烷-2-甲酸(azepane-2-carboxylic acid)等7元环氨基酸。这些化合物的化学式如下所示。
[0095][0096]
另外,亚烷基链中,可以在链中或末端包含硫原子、氧原子、氮原子等杂原子。由包含这些杂原子的亚烷基链形成杂环。亚烷基链中,可以包含一种或两种以上或者一个或两个以上的硫原子、氧原子、氮原子等杂原子。作为所含的杂原子的个数,优选为1~3个。作为包含杂原子的亚烷基链,可列举例如-chohch
2-、-ch2chohch
2-、-sch
2-、-sc2h
4-、-sc3h
6-、-och
2-、-oc2h
4-、-oc3h
6-、-nhch
2-、-nhc2h
4-、-nhc3h
6-、-nhch2chcooh-、-c2h4nhco-、-c2h4nhcn-、-c2h4chcooh-、-sch2chcooh-、-sc2h4chcooh-、-nhchcoohch
2-等。
[0097]
a为包含硫原子的亚烷基链时,作为l型环状氨基酸,可列举硫代脯氨酸、3-硫代吗啉甲酸、[1,4]硫氮杂环庚烷-3-甲酸([1,4]thiazepane-3-carboxylic acid)等。a为包含氧原子的亚烷基链时,作为l型环状氨基酸,可列举4-唑烷甲酸、3-吗啉甲酸等。a为包含两个以上氮原子的亚烷基链时,作为l型环状氨基酸,可列举哌嗪-2-甲酸等。将这些化合物的化学式示于以下。
[0098][0099]
另外,上述亚烷基链或包含杂原子的亚烷基链可具有取代基。作为取代基,只要是不会对反应造成不良影响的基团就没有特别限定。具体而言,虽然没有限定,但是可列举碳原子数1~4的烷基、碳原子数6~12的芳基、碳原子数1~4的烷氧基、羧基、卤素基、氰基、氨基、硝基、羟基等,优选羟基。作为包含取代基的l型环状氨基酸,可列举例如羟脯氨酸(hydroxyproline)、羟基哌可酸等。将这些的化学式示于以下。
[0100][0101]
这些之中,作为a,优选碳原子数2~4的直链状亚烷基链,特别优选碳原子数3的直链状亚烷基链。
[0102]
1.亚氨基酸还原酶
[0103]
本发明中使用的亚氨基酸还原酶为催化下述式(1)所示的反应的酶。
[0104]
式(1):
[0105]
(式中,a与上述含义相同。)
[0106]
催化上述式(i)所示的反应的酶是指具有如下性能的酶,所述性能为:使亚氨基酸还原酶(多肽)、具有生产上述多肽的能力或包含上述多肽的微生物或细胞、上述微生物或细胞的处理物和/或对上述微生物或细胞进行培养而得到的包含上述多肽的培养液与上述通式(i)所示的在1位具有双键的环状氨基酸接触而生成上述通式(ii)所示的l型环状氨基酸。
[0107]
是否具有“由通式(i)所示的在1位具有双键的环状氨基酸生成通式(ii)所示的l型环状氨基酸的性能”这一点例如可如下确认:在含有δ
1-哌啶-2-甲酸作为底物、而且含有nad(p)
+
或nad(p)h作为辅酶的反应体系中,使作为测定对象的酶作用于δ
1-哌啶-2-甲酸而还原δ
1-哌啶-2-甲酸,直接测定所生成的l-哌可酸的量,由此来进行确认。
[0108]
接触方法没有特别限定,可列举例如向包含亚氨基酸还原酶的液体中加入上述通式(i)所示的在1位具有双键的环状氨基酸,在适当的温度(例如10℃~45℃左右)、压力(例如大气压左右)下进行反应等。关于反应时间,也是可以根据酶种类、目标产物等适宜设定的范围。
[0109]
本发明中,特别优选催化下述式(2)所示的反应(还原δ
1-哌啶-2-甲酸(δ
1-piperidine-2-carboxylic acid)而生成l-哌可酸的反应)的酶。
[0110]
式(2):
[0111]
另外,该亚氨基酸还原酶例如优选为以还原型烟酰胺腺嘌呤核苷酸(nadh)或还原型烟酰胺腺嘌呤二核苷酸磷酸(nadph)(以下有时将两者统称为“nad(p)h”)作为辅酶、还原通式(i)所示的在1位具有双键的环状氨基酸而生成通式(ii)所示的l型环状氨基酸的酶。
[0112]
这样的亚氨基酸还原酶例如可以从拟南芥(arabidopsis thaliana)、勘察加拟南芥(arabidopsis kamchatica subsp.kamchatica)、叶芽拟南芥(arabidopsis halleri subsp.gemmifera var.senanensis)等拟南芥属(genus arabidopsis)的植物、桑、家桑(morus alba)、鲁桑等桑属(genus morus)的植物或海滨山黧豆(lathyrus japonicus)、山黧豆、香豌豆等山黧豆属(genus lathyrus)等植物中利用公知方法提取、纯化而得到。
[0113]
亚氨基酸还原酶特别优选来自拟南芥、家桑或海滨山黧豆的亚氨基酸还原酶。例如,优选由拟南芥、家桑或海滨山黧豆提取、纯化而得到的亚氨基酸还原酶。另外,本发明已经明确了来自拟南芥、家桑或海滨山黧豆的亚氨基酸还原酶的序列,因此也优选使用通过公知方法利用相同序列合成的亚氨基酸还原酶。
[0114]
酶从植物中的提取可以基于通常的植物酶的提取方法(例如瓜谷郁三,志村宪助,中村道德,船津胜编、生物化学实验法14高等植物的二次代谢研究法(1981)学会出版中心;堀尾武一,山下仁平编、蛋白质
·
酶的基础实验法(1981)南江堂)来进行。
[0115]
为了从得到的提取物中除去残渣,应用过滤、离心分离等固液分离手段,制成粗酶提取液。从粗酶提取液中纯化目标酶的操作可应用公知的分离、纯化方法。例如,利用硫酸铵盐析法、有机溶剂沉淀法等从粗酶提取液中得到粗酶蛋白,再对其适当组合使用离子交换层析、凝胶过滤层析、亲和层析等各种层析,由此可得到纯化酶。
[0116]
具体而言,本发明中使用的亚氨基酸还原酶为:包含由序列号2、4、6、8、10或12所示的氨基酸序列构成的多肽的亚氨基酸还原酶;或者,包含由与该氨基酸序列具有高度一致性的氨基酸序列(以下有时称为“氨基酸序列的同源物”。)构成且催化上述式(1)所示的反应的、具有l型环状氨基酸生成能力的多肽的亚氨基酸还原酶(以下有时称为“亚氨基酸
还原酶的同源物”。)。
[0117]
更具体而言,包含以下的(a)、(b)或(c)所示的多肽。
[0118]
(a)具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽;
[0119]
(b)为在序列号2、4、6、8、10或12所示的氨基酸序列中缺失、置换和/或添加1个~两个以上氨基酸而成的氨基酸序列、且催化下述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽,
[0120]
式(1)
[0121]
(式中,a与上述含义相同。);或者
[0122]
(c)具有与序列号2、4、6、8、10或12所示的氨基酸序列具有90%以上的序列一致性的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。
[0123]
本发明中,具有序列号2、4、6、8、10或12所示的氨基酸序列的亚氨基酸还原酶的同源物包含上述多肽(b)或(c)所示的多肽。
[0124]
(b)所示的多肽为在序列号2、4、6、8、10或12所示的氨基酸序列中缺失、置换和/或添加1个~两个以上氨基酸而成的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。
[0125]
在置换的情况下,优选对1个~两个以上氨基酸进行保守性置换。本说明书中,“对氨基酸进行保守性置换”是指化学性质等类似的氨基酸彼此之间的置换,可列举例如用碱性氨基酸置换碱性氨基酸、用酸性氨基酸置换酸性氨基酸等。
[0126]“1个~两个以上氨基酸”通常为1个~100个、优选为1个~50个、更优选为1个~20个、进一步优选为1个~10个、特别优选为1个~5个、最优选为1个~3个氨基酸。
[0127]
(c)所示的多肽为具有与序列号2、4、6、8、10或12所示的氨基酸序列具有90%以上的序列一致性的氨基酸序列、且催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽。优选为具有与序列号2、4、6、8、10或12所示的氨基酸序列的全长具有80%以上、更优选为90%以上、进一步优选为95%以上、特别优选为98%以上、最优选为99%以上的序列一致性的氨基酸序列、且具有催化上述式(1)所示的反应的活性的多肽。
[0128]
本说明书中的氨基酸序列的同源性(也称为一致性或类似性)可以使用同源性计算算法ncbi blast(national center for biotechnology information basic local alignment search tool),例如在以下的条件(期待值=10;允许空隙;矩阵=blosum62;过滤=off)下进行计算。作为用于确定氨基酸序列的同源性的其它算法,可列举例如:karlin等,proc.natl.acad.sci.usa,90:5873-5877(1993)中记载的算法[该算法整合于nblast及xblast程序(version 2.0)(altschul等,nucleic acids res.,25:3389-3402(1997))];needleman等,j.mol.biol.,48:444-453(1970)中记载的算法[该算法整合于gcg软件包中的gap程序];myers及miller,cabios,4:11-17(1988)中记载的算法[该算法整合于作为cgc序列比对软件包的一部分的align程序(version2.0)];pearson等,proc.natl.acad.sci.usa,85:2444-2448(1988)中记载的算法[该算法整合于gcg软件包中
的fasta程序]等,它们也同样可以优选使用。
[0129]
另外,本发明的亚氨基酸还原酶还可以通过如下方法制造:培养含有编码该亚氨基酸还原酶的核酸的转化体,从得到的培养物中分离纯化该亚氨基酸还原酶。编码本发明的亚氨基酸还原酶的核酸可以为dna,可以为rna,或者,可以为dna/rna嵌合体。优选列举dna。另外,该核酸可以为双链,也可以为单链。在双链的情况下,可以为双链dna、双链rna或dna:rna的杂合体。在单链的情况下,可以为有义链(即,编码链),也可以反义链(即,非编码链)。
[0130]
作为编码本发明的亚氨基酸还原酶的dna,可列举合成dna等。例如可以如下获得:使用由来自拟南芥、桑(鸡桑)或海滨山黧豆的细胞或组织制备的总rna或mrna级分作为模板,利用逆转录酶(reverse transcriptase)-pcr直接扩增,将所得到的全长亚氨基酸还原酶cdna使用公知的试剂盒、例如mutantm-super express km(takara bio inc.)、mutantm-k(takara bio inc.)等通过oda-la pcr法、带缺口的双链体(gapped duplex)法、孔克尔(kunkel)法等公知方法或基于这些的方法进行转换,由此而获得。或者,也可以利用菌落或噬菌斑杂交法或pcr法等从将上述总rna或mrna的片段插入适当的载体中而制备的cdna文库中进行克隆,将所得cdna按照上述方法进行转换而获得。用于文库的载体可以为噬菌体、质粒、柯斯质粒、噬菌粒等中的任一者。
[0131]
另外,出于易于纯化、使性质维持为更理想的状态的目的,本发明的亚氨基酸还原酶可以为与亲和性多肽的融合蛋白。作为这样的融合蛋白,可列举与谷胱甘肽-s-转移酶(gst)、组氨酸标签、麦芽糖结合蛋白(mbp)、ha标签、flag标签、生物素化肽、绿色荧光蛋白等公知的亲和性多肽的融合蛋白。这样的融合蛋白可以通过亲和纯化等得到。
[0132]
本发明中,优选与gst的融合蛋白。具有序列号8、10或12所示的氨基酸序列的多肽为分别使序列号2、4或6中记载的氨基酸序列所示的多肽与gst融合而成的融合蛋白。
[0133]
作为编码具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽的核酸,可分别列举包含序列号1、3、5、7、9或11所示的碱基序列的核酸。只要编码具有催化式(1)所示的反应的活性的多肽,则也可以是包含与序列号1、3、5、7、9或11所示的碱基序列具有高度一致性的碱基序列的核酸(以下有时称为“核酸的同源物”)。即,作为编码该多肽的核酸,可列举以下的具有(d)、(e)或(f)所示的碱基序列的核酸。
[0134]
(d)包含序列号1、3、5、7、9或11所示的碱基序列的核酸;
[0135]
(e)为在序列号1、3、5、7、9或11所示的碱基序列中置换、缺失和/或添加1个或两个以上碱基而成的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸;或者
[0136]
(f)为与序列号1、3、5、7、9或11所示的碱基序列的互补链在严格条件下进行杂交的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸。
[0137]
作为上述(e)所示的核酸的同源物,可列举包含在序列号1、3、5、7、9或11所示的碱基序列中缺失、置换、插入和/或添加1个~两个以上碱基而成的碱基序列、且编码具有催化上述式(1)所示的反应的活性的多肽的核酸。置换、插入或添加的情况下,优选置换、插入或添加1个~两个以上碱基。在此,“1个~两个以上碱基”例如为1个~300个、优选为1个~150个、更优选为1个~60个、进一步优选为1个~30个、特别优选为1个~15个、最优选为1个~5
个碱基。
[0138]
需要说明的是,序列号1、3、5所示的碱基序列分别为对来自拟南芥、桑(鸡桑)、海滨山黧豆的亚氨基酸还原酶的基因优化密码子以用于大肠杆菌表达的碱基序列。此种根据作为转化对象的宿主优化了密码子的dna当然包括在本发明中可使用的编码具有催化上述式(1)所示的反应的活性的多肽的核酸中。
[0139]
作为上述(f)所示的核酸的同源物,可列举(f)为与序列号1、3、5、7、9或11所示的碱基序列的互补链在严格条件下进行杂交的碱基序列、且编码催化上述式(1)所示的反应的具有l型环状氨基酸生成能力的多肽的核酸。优选为具有与序列号1、3、5、7、9或11所示的碱基序列具有80%以上、更优选为90%以上、进一步优选为95%以上、更进一步优选为98%以上、最优选为99%以上的同源性(也称为一致性)的碱基序列、且编码具有催化上述式(1)所示的反应的活性的多肽的核酸。
[0140]
本说明书中的碱基序列的同源性(也称为一致性)可以使用同源性计算算法ncbi blast(national center for biotechnology information basic local alignment search tool)在例如以下条件(期待值=10;允许空隙;过滤=on;匹配得分=1;错配得分=-3)下进行计算。作为用于确定碱基序列的同源性的其它算法,可同样地优选例示上述的氨基酸序列的同源性计算算法。
[0141]
作为上述(f)所示的核酸的同源物,只要编码具有催化上述式(1)所示的反应的活性的多肽则也可以是与序列号1、3、5、7、9或11所示的碱基序列的互补链在严格条件下进行杂交的核酸。在此,作为“严格条件”,可以参考已报道的条件(例:current protocols in molecular biology,john wiley&sons,6.3.16.3.6,1999)适宜设定,具体而言,可列举例如:在与通常的southern杂交的洗涤条件、即60℃、1x ssc、0.1%sds、优选为0.1x ssc、0.1%sds、进一步优选为65℃、0.1x ssc、0.1%sds或68℃、0.1x ssc、0.1%sds等(高严格条件)相当的盐浓度及温度下洗涤1次、更优选2~3次的条件等。
[0142]
本领域技术人员可通过使用定点诱变法(nucleic acids res.10,pp.6487(1982)、methods in enzymol.100,pp.448(1983)、molecular cloning、pcr a practical approach irl press pp.200(1991))等在序列号1、3、5、7、9或11所示的核酸中适宜地进行置换、缺失、插入和/或添加而导入期望的变异,由此得到上述的核酸的同源物。
[0143]
本发明的核酸能够编码具有催化上述式(1)所示的反应的活性的多肽。本发明的核酸具有序列号1、3、5、7、9或11所示的碱基序列、或者与序列号1、3、5、7、9或11所示的碱基序列具有高度一致性的碱基序列的情况下,包含由该核酸编码的多肽的亚氨基酸还原酶的l型环状氨基酸生成能力的程度可以与包含具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽的亚氨基酸还原酶、或包含具有该氨基酸序列的同源物的多肽的亚氨基酸还原酶在定量上同等,但可以在可接受的范围(例如,包含具有序列号2、4、6、8、10或12所示的氨基酸序列的多肽的亚氨基酸还原酶、或包含具有该氨基酸序列的同源物的多肽的亚氨基酸还原酶的氨基酸生成能力的约0.1倍~约5倍、优选为约0.3倍~约3倍)内不同。
[0144]
另外,还可以以序列号2、4、6、8、10或12所示的氨基酸序列或其一部分、序列号1、3、5、7、9或11所示的碱基序列或其一部分为基础对例如dna databank of japan(ddbj)等数据库进行同源检索,获得具有催化式(1)所示的反应的活性的多肽的氨基酸序列信息或编码该氨基酸序列的dna的碱基序列信息。
[0145]
后述的本发明的制造方法中,可以将亚氨基酸还原酶直接用于上述式(1)所示的反应,但优选使用具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物和/或对该微生物或细胞进行培养而得到的包含该酶的培养液。
[0146]
作为具有生产本发明的亚氨基酸还原酶的能力的微生物或细胞,可以使用原本就具有生产该亚氨基酸还原酶的能力的微生物或细胞,也可以是通过育种而赋予了上述生产能力的微生物或细胞。作为微生物或细胞,死活均可,例如,可以优选使用休眠菌体等。作为具有生产本发明的亚氨基酸还原酶的能力的微生物或细胞的种类,可列举后文作为“宿主微生物”或“宿主细胞”记载的微生物或细胞。
[0147]
作为通过育种来赋予上述生产能力的手段,可采用基因重组处理(转化)、变异处理等公知的方法。作为转化的方法,可列举导入目标dna的方法、在染色体上改造启动子等表达调控序列以强化目标dna的表达的方法等。
[0148]
这些之中,优选使用利用编码上述本发明的多肽的dna进行了转化的微生物或细胞。
[0149]
如上所述,编码本发明的多肽(亚氨基酸还原酶)的核酸(dna)例如可以通过使用来自拟南芥、家桑或海滨山黧豆的染色体dna作为模板、使用适当的引物进行pcr来克隆。
[0150]
另外,如上所述,编码本发明的多肽(亚氨基酸还原酶)的核酸(dna)例如可以通过使用来自拟南芥、桑(鸡桑)或海滨山黧豆的总rna或mrna作为模板且利用rt-pcr法直接扩增而制备全长亚氨基酸还原酶cdna后、使用适当的引物进行pcr来克隆。
[0151]
例如,通过将如上所述地得到的编码本发明的多肽的dna以能表达的配置插入到公知的表达载体中,从而可提供本发明的多肽基因表达载体。并且,通过用该表达载体转化宿主微生物或细胞,能够得到导入了编码本发明的多肽的dna的转化体。转化体也可以通过利用同源重组等方法以能够表达的方式将编码本发明的多肽的dna整合到宿主的染色体dna中而得到。
[0152]
本说明书中,“表达载体”是指:用于通过整合编码具有期望功能的蛋白质的多核苷酸并导入到宿主微生物或细胞中、从而在上述宿主微生物或细胞中复制及表达具有期望功能的蛋白质的遗传因子。可列举例如质粒、病毒、噬菌体、柯斯质粒等,但是不限于这些。表达载体优选为质粒。
[0153]
本说明书中,“转化体”是指:使用上述表达载体等导入了目标基因、从而能够表现与具有期望功能的蛋白质有关的期望性状的微生物或细胞。
[0154]
作为转化体的制作方法,没有具体限定,可例示将向宿主微生物或宿主细胞中稳定存在的质粒载体、噬菌体载体、病毒载体中导入编码本发明的多肽的dna而构建的表达载体导入到该宿主微生物或宿主细胞中的方法、直接向宿主基因组中导入该dna并转录和翻译其遗传信息的方法。这种情况下,优选在宿主中在dna的5
’‑
侧上游连接适当的启动子,进而,更优选在3
’‑
侧下游连接终止子。作为这样的启动子及终止子,只要是已知在作为宿主使用的细胞中发挥功能的启动子及终止子,就没有特别限定,可以使用例如“微生物学基础讲座8基因工程学
·
共立出版”中详述的载体、启动子及终止子。
[0155]
作为成为用于表达本发明的亚氨基酸还原酶的转化对象的宿主微生物,只要宿主本身不会对原料、中间产物造成不良影响就没有特别限定,可列举例如以下所示的微生物。
[0156]
属于埃希氏菌(escherichia)属、芽孢杆菌(bacillus)属、假单胞菌
(pseudomonas)属、沙门氏菌(serratia)属、短杆菌(brevibacterium)属、棒杆菌(corynebacterium)属、链球菌(streptococcus)属、乳杆菌(lactobacillus)属等的已经建立了宿主载体系统的细菌。
[0157]
属于红球菌(rhodococcus)属、链霉菌(streptomyces)属等的已经建立了宿主载体系统的放线菌。
[0158]
属于酵母(saccharomyces)属、克鲁维酵母(kluyveromyces)属、裂殖酵母(schizosaccharomyces)属、接合酵母(zygosaccharomyces)属、耶氏酵母(yarrowia)属、丝孢酵母(trichosporon)属、红冬孢酵母(rhodosporidium)属、汉逊酵母(hansenula)属、毕赤酵母(pichia)属、假丝酵母(candida)属等的已经建立了宿主载体系统的酵母。
[0159]
属于链孢霉(neurospora)属、曲霉(aspergillus)属、头孢霉(cephalosporium)属、木霉(trichoderma)属等的已经建立了宿主载体系统的霉菌。
[0160]
用于制作转化体的步骤、适合于宿主的重组载体的构建及宿主的培养方法可以依据分子生物学、生物工程学、基因工程学的领域中惯用的技术来进行(例如molecular cloning中记载的方法)。
[0161]
以下具体列举优选的宿主微生物、各微生物的优选的转化方法、载体、启动子、终止子等的例子,但是本发明不受这些例子限定。
[0162]
在埃希氏菌属、特别是大肠杆菌(escherichia coli)中,作为质粒载体,可列举pbr、puc系质粒等,可列举lac(β-半乳糖苷酶)、trp(色氨酸操纵子)、tac、trc(lac、trp的融合)、来自λ噬菌体pl、pr等的启动子等。另外,作为终止子,可列举来自trpa、来自噬菌体、来自rrnb核糖体rna的终止子等。
[0163]
在芽孢杆菌属中,作为载体,可列举pub110系质粒、pc194系质粒等,另外,也可以整合到染色体上。作为启动子及终止子,可利用碱性蛋白酶、中性蛋白酶、α-淀粉酶等酶基因的启动子、终止子等。
[0164]
在假单胞菌属中,作为载体,可列举:由恶臭假单胞菌(pseudomonas putida)、洋葱假单胞菌(pseudomonas cepacia)等建立的常规宿主载体系统;和以参与甲苯化合物的分解的质粒、tol质粒为基础的广宿主载体(包含来自rsf1010等的自主复制所需的基因)pkt240(gene,26,273-82(1983))等。
[0165]
在短杆菌属、特别是乳糖发酵短杆菌(brevibacterium lactofermentum)中,作为载体,可列举paj43(gene 39,281(1985))等质粒载体。作为启动子及终止子,可使用大肠杆菌中使用的各种启动子及终止子。
[0166]
在棒杆菌属、特别是谷氨酸棒杆菌(corynebacterium glutamicum)中,作为载体,可列举pcs11(日本特开昭57-183799号公报)、pcb101(mol.gen.genet.196,175(1984))等质粒载体。
[0167]
在酵母(saccharomyces)属、特别是酿酒酵母(saccharomyces cerevisiae)中,作为载体,可列举yrp系、yep系、ycp系、yip系质粒等。另外,可利用醇脱氢酶、甘油醛-3-磷酸脱氢酶、酸性磷酸酶、β-半乳糖苷酶、磷酸甘油酸激酶、烯醇化酶这样的各种酶基因的启动子、终止子。
[0168]
在裂殖酵母(schizosaccharomyces)属中,作为载体,可列举mol.cell.biol.6,80(1986)中记载的来自粟酒裂殖酵母的质粒载体等。特别是,paur224已由宝生物株式会社销
售,可以容易地进行利用。
[0169]
在曲霉(aspergillus)属中,霉菌中研究得最多的是黑曲霉(aspergillusniger)、米曲霉(aspergillus oryzae)等,可以利用向质粒、染色体中的整合,可以利用来自菌体外蛋白酶、淀粉酶的启动子(trendsin biotechnology 7,283-287(1989))。
[0170]
另外,除了上述以外,还建立了与各种微生物相应的宿主载体系统,也可以适宜地使用这些。
[0171]
另外,除了微生物以外,在植物、动物中也建立了各种宿主-载体系统,特别地,已建立了在昆虫(例如蚕)等动物中(nature315,592-594(1985))或油菜籽、玉米、马铃薯等植物中大量表达异种蛋白的系统,以及使用大肠杆菌无细胞提取液、小麦胚芽等无细胞蛋白质合成系统的系统,也可以适宜地利用。
[0172]
作为具有生产本发明的亚氨基酸还原酶的能力的微生物或细胞的处理物,可列举例如:将该微生物或细胞用丙酮、二甲基亚砜(dmso)、甲苯等有机溶剂、表面活性剂进行处理而成的物质、经冷冻干燥处理的物质、经物理方式或酶方式破碎的物质等细胞制备物;将微生物或细胞中的酶级分以粗制物或纯化物形式提取出的物质;以及将这些固定化于以聚丙烯酰胺凝胶、卡拉胶凝胶等为代表的载体而成的物质等。
[0173]
作为对具有生产本发明的亚氨基酸还原酶的能力的微生物或细胞进行培养而得到的包含该酶的培养液,可列举例如:该微生物或细胞与液体培养基的悬浮液;在该细胞为分泌表达型细胞时,通过离心分离等除去该细胞而得的上清或其浓缩物。
[0174]
本发明的亚氨基酸还原酶可以特别优选用于还原δ
1-哌啶-2-甲酸而制造l-哌可酸的方法中。
[0175]
本发明中使用的转化体为大肠杆菌等原核生物、酵母菌等真核生物的情况下,培养这些微生物的培养基只要为含有该微生物能同化的碳源、氮源、无机盐类等且能够高效率地进行转化体的培养的培养基,则天然培养基、合成培养基均可。培养优选在振荡培养或深部通气搅拌培养等需氧条件下进行,培养温度通常为15~40℃,培养时间通常为16小时~7天。培养中,ph保持在3.0~9.0。ph的调节使用无机或有机的酸、碱溶液、尿素、碳酸钙、氨等来进行。另外,培养中可根据需要向培养基中添加氨苄青霉素、四环素等抗生素。
[0176]
从转化体的培养物中单离纯化上述亚氨基酸还原酶时,使用通常的蛋白质的单离、纯化方法即可。
[0177]
例如,在细胞内以溶解状态表达上述亚氨基酸还原酶的情况下,在培养结束后,利用离心分离回收细胞并悬浮于水系缓冲液后,利用超声波破碎机、弗氏压碎器、manton gaulin匀浆机、戴诺磨等破碎细胞,得到无细胞提取液。从通过对该无细胞提取液进行离心分离而得到的上清,单独或组合使用通常的蛋白质的单离纯化方法、即溶剂提取法、利用硫酸铵等的盐析法、脱盐法、利用有机溶剂的沉淀法、使用二乙基氨基乙基(deae)琼脂糖、diaion hpa-75(三菱化学公司制)等树脂的阴离子交换层析法、使用s-sepharose ff(法玛西亚公司制)等树脂的阳离子交换层析法、使用丁基琼脂糖、苯基琼脂糖等树脂的疏水性层析法、使用分子筛的凝胶过滤法、亲和层析法、聚焦层析法、等电点电泳等电泳法等方法,可以得到纯化标品。
[0178]
另外,上述亚氨基酸还原酶在细胞内形成不溶体而表达的情况下,可以同样地回收细胞后进行破碎,进行离心分离,从由此得到的沉淀级分中利用通常的方法回收该亚氨
基酸还原酶,然后,用蛋白质变性剂使该n-甲基-l-氨基酸脱氢酶的不溶体可溶化。将该可溶化液在不含蛋白质变性剂或蛋白质变性剂的浓度稀薄到n-甲基-l-氨基酸脱氢酶不会发生变性的程度的溶液中进行稀释或者透析,使该亚氨基酸还原酶构成为正常的立体结构后,利用与上述相同的单离纯化方法得到纯化标品。
[0179]
2.本发明的组合物
[0180]
本发明的组合物(酶制剂)包含本发明的亚氨基酸还原酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物和/或培养该微生物或细胞而得到的包含上述酶的培养液,具有上述l型环状氨基酸生成性能。本发明的组合物通过作为催化剂使用而能够更廉价、高效率且工业化地制造高纯度的l型环状氨基酸,因此是有用的。
[0181]
本发明的组合物除了有效成分(酶等)以外还可以含有赋形剂、缓冲剂、悬浮剂、稳定剂、保存剂、防腐剂、生理盐水等。作为赋形剂,可以使用乳糖、山梨醇、d-甘露醇、白糖等。作为缓冲剂,可以使用磷酸盐、柠檬酸盐、乙酸盐等。作为稳定剂,可以使用丙二醇、抗坏血酸等。作为保存剂,可以使用苯酚、苯扎氯铵、苄醇、氯丁醇、对羟基苯甲酸甲酯等。作为防腐剂,可以使用苯扎氯铵、对羟基苯甲酸、氯丁醇等。
[0182]
3.l型环状氨基酸的制造方法
[0183]
根据本发明,提供使本发明的亚氨基酸还原酶与下述通式(i)所示的在1位具有双键的环状氨基酸接触,制造下述通式(ii)所示的l型环状氨基酸的方法。
[0184][0185]
(式中,a与上述含义相同。)
[0186][0187]
(式中,a与上述含义相同。)
[0188]
在使本发明的亚氨基酸还原酶与通式(i)所示的在1位具有双键的环状氨基酸接触时,通过使经纯化或粗纯化的本发明的亚氨基酸还原酶、具有生产本发明的亚氨基酸还原酶的能力的微生物或细胞(例如具有编码本发明的多肽的dna的转化体等)、该微生物或细胞的处理物和/或培养该微生物或细胞而得到的包含该酶的培养液与通式(i)所示的在1位具有双键的环状氨基酸接触,从而能够还原该环状氨基酸而制造通式(ii)所示的l型环状氨基酸。
[0189]
本发明的亚氨基酸还原酶可以直接用于反应,但是优选使用具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物和/或培养该微生物或细胞而得到的包含该酶的培养液,这些之中,优选使用具有编码本发明的多肽的dna的转化体。
[0190]
关于添加到反应液中的微生物或细胞、该微生物或细胞的处理物和/或培养该微生物或细胞而得到的包含该酶的培养液的量,在添加微生物或细胞的情况下,以该微生物或细胞的浓度通常以湿菌体重量计达到0.1w/v%~50w/v%左右、优选0.1w/v%~10w/v%
的方式添加到反应液中,使用处理物、培养液的情况下,求出酶的比活性,在添加时添加达到上述微生物或细胞浓度的量。在此,w/v%表示重量(weight)/体积(volume)%。
[0191]
接触方法(反应方法)没有特别限定,可以向包含本发明的亚氨基酸还原酶的液体中加入成为底物的通式(i)所示的在1位具有双键的环状氨基酸,在适当的温度、压力(例如大气压左右)下反应。关于反应时间,也可以根据酶种类、目标产物等适宜地设定。
[0192]
成为反应底物的通式(i)所示的在1位具有双键的环状氨基酸通常以反应液中的底物浓度达到0.0001w/v%~90w/v%、优选0.01w/v%~30w/v%的范围来使用。反应底物可以在反应开始时一次性添加,但从降低存在酶的底物抑制时的影响的观点、提高产物的蓄积浓度的观点出发,优选连续或间歇地添加。
[0193]
另外,上述反应(还原反应)优选在辅酶存在下进行。作为辅酶,优选nad(p)
+
或nad(p)h。在此,nad(p)
+
表示氧化型烟酰胺腺嘌呤核苷酸(nad
+
)或氧化型烟酰胺腺嘌呤二核苷酸磷酸(nadp
+
)。
[0194]
辅酶以使反应液中的浓度通常达到0.001mmol/l~100mmol/l、优选0.01mmol/l~10mmol/l的方式来添加。
[0195]
在添加辅酶的情况下,为了提高生产效率,优选使由nad(p)h生成的nad(p)+再生为nad(p)h。作为再生方法,可列举:<1>利用宿主微生物本身的nad(p)+还原能力的方法;<2>向反应体系中添加具有由nad(p)+生成nad(p)h的能力的微生物或其处理物、或葡萄糖脱氢酶、甲酸脱氢酶、醇脱氢酶、氨基酸脱氢酶、有机酸脱氢酶(苹果酸脱氢酶等)等能够用于nad(p)h的再生的酶(再生酶)的方法;<3>制造转化体时将能够用于nad(p)h的再生的酶、即上述再生酶类的基因与本发明的dna同时导入到宿主中的方法;等。
[0196]
其中,在上述<1>的方法中,优选向反应体系中添加葡萄糖、乙醇、甲酸等。在上述<2>的方法中,可以使用:包含上述再生酶类的微生物;用编码上述再生酶类的dna转化而得的微生物;对该微生物菌体进行丙酮处理而得的物质、进行冷冻干燥处理而得的物质、利用物理破碎或酶法破碎而得的物质等菌体处理物;将该酶级分以粗制物或纯化物的形式提取出的物质;以及将这些固定化于以聚丙烯酰胺凝胶、卡拉胶凝胶等为代表的载体而得的物质等,另外也可以使用市售的酶。
[0197]
这种情况下,作为上述再生酶的使用量,具体而言以相较于亚氨基酸还原酶以酶活性计通常为0.01倍~100倍、优选0.01倍~10倍左右的方式进行添加。
[0198]
另外,也需要添加成为上述再生酶的底物的化合物、例如利用葡萄糖脱氢酶时的葡萄糖、利用甲酸脱氢酶时的甲酸、利用醇脱氢酶时的乙醇或异丙醇等,作为其添加量,相对于作为反应原料的含二羰基化合物,通常添加1~10摩尔倍量、优选1.0~1.5摩尔倍量。
[0199]
另外,在上述<3>的方法中,可以使用将亚氨基酸还原酶的dna和上述再生酶类的dna整合到染色体中的方法、在单一的载体中导入两种dna并转化宿主的方法、及将两种dna分别导入到各载体中后转化宿主的方法,在将两种dna分别导入到各载体中后转化宿主的方法的情况下,需要考虑两载体彼此的不相合性来选择载体。
[0200]
在单一的载体中导入两个以上基因的情况下,还可以为将启动子及终止子等表达调控相关区域与各个基因连接的方法、以乳糖操纵子之类的包含两个以上顺反子的操纵子形式表达。
[0201]
上述反应(还原反应)优选在含有反应底物及转化体、以及根据需要添加的各种辅
酶及其再生系统的水性介质中或水性介质与有机溶剂的混合物中进行。
[0202]
作为水性介质,可列举水或缓冲液。作为有机溶剂,可以使用甲醇、乙醇、1-丙醇、2-丙醇、1-丁醇、叔丁醇、四氢呋喃、丙酮、二甲基亚砜等作为反应底物的通式(i)所示的在1位具有双键的环状氨基酸的溶解度高的水溶性有机溶剂。另外,可以使用乙酸乙酯、乙酸丁酯、甲苯、氯仿、正己烷等对反应副产物的除去等有效的非水溶性有机溶剂等。
[0203]
上述反应(还原反应)可根据使用的酶、目标产物等适宜地调整,在通常4~60℃、优选10~50℃的反应温度下、通常ph4~11、优选ph5~10下进行。反应时间通常为1小时~72小时左右。
[0204]
上述反应(还原反应)也可以利用膜反应器等来进行。
[0205]
对于通过上述反应(还原反应)生成的通式(ii)所示的l型环状氨基酸,可以在反应结束后利用离心分离、膜处理等本领域技术人员公知的分离或纯化方法对反应液中的菌体、蛋白质进行分离后,将利用乙酸乙酯、甲苯等有机溶剂的提取、蒸馏、使用离子交换树脂或硅胶等的柱层析、等电点下的结晶、基于一盐酸盐、二盐酸盐、钙盐等的结晶适宜地组合而进行纯化。
[0206]
另外,作为底物的通式(i)所示的在1位具有双键的环状氨基酸可以利用公知的方法由二氨基酸、外消旋体的环状氨基酸通过有机合成方法、生物化学方法来制造。从成本、处理性出发,在工业上优选由二氨基酸进行制造。作为二氨基酸,优选链状的α,ω-二氨基酸。
[0207]
由链状的α,ω-二氨基酸进行制造的情况下,如果如下述反应式那样将α,ω-二氨基酸的α位的氨基转换为酮基而生成α酮酸,则该α酮酸发生非酶促脱水闭环而成为在1位具有双键的环状氨基酸。
[0208][0209]
(式中,a与上述含义相同。)
[0210]
在此,α,ω-二氨基酸的α位的氨基被氧化而成的α酮酸与在1位具有双键的环状氨基酸通常在水性介质中以平衡混合物形式存在,因此将这些视为等效物。因此,本发明的反应(还原反应)体系中,可以添加或含有在1位具有双键的环状氨基酸、δ
1-哌啶-2-甲酸、α,ω-二氨基酸的α位的氨基被氧化而成的α酮酸和在1位具有双键的环状氨基酸、或者α,ω-二氨基酸的α位的氨基被氧化而成的α酮酸,这些方式中的任一方式均包含在本发明中。
[0211]
由α,ω-二氨基酸通过生物化学方式制造在1位具有双键的环状氨基酸的情况下,只要为能够使α,ω-二氨基酸的α位的氨基转换为酮基而生成α酮酸的酶即可,没有特别限定,可列举例如d-氨基酸氧化酶(d-aminoacid oxidase)、l-氨基酸氧化酶(l-aminoacid oxidase)等氨基酸氧化酶、d-氨基酸脱氢酶(d-aminoacid dehydrogenase)、l-氨基酸脱氢酶(l-aminoacid dehydrogenase)等氨基酸脱氢酶、d-氨基酸转移酶(d-aminoacid aminotransferase)、l-氨基酸转移酶(l-aminoacid aminotransferase)等氨基酸转移酶等酶。
[0212]
这些中,优选底物特异性宽的酶。具体而言,优选enzyme and microbial technology vol.31(2002)p77-87中记载的l-氨基酸氧化酶、西格玛奥德里奇公司制造的d-氨基酸氧化酶等。
[0213]
在上述氨基酸氧化酶、氨基酸脱氢酶或氨基酸转移酶仅与二氨基酸反应且与本发明的还原反应中能够使用的辅酶对应的情况下,可成为辅酶的再生系统的替代系统,因此是优选的。即,在本发明的还原反应中使用nad(p)h作为辅酶的情况下,nad(p)h会随着本反应的还原化而成为nad(p)
+
,另一方面,在由二氨基酸制造在1位具有双键的环状氨基酸时能够利用该nad(p)
+
向nad(p)h转换,因此是优选的。
[0214]
另外,在由二氨基酸制造在1位具有双键的环状氨基酸时使用各种氨基酸氧化酶的情况下,会随着反应而生成过氧化氢,认为其会降低酶活性等对反应造成不良影响,因此优选组合其它酶以除去过氧化氢。作为除去过氧化氢的酶,只要是与过氧化氢反应的酶就没有特别限定,具体而言,优选过氧化氢酶、过氧化物酶。与过氧化氢反应的酶的使用量只要为可高效地除去所生成的过氧化氢的范围就没有特别限定,具体而言,以相对于氨基酸氧化酶通常为0.01倍活性~100万倍活性、优选0.1倍活性~10万倍活性的范围使用。
[0215]
另外,使用氨基酸氧化酶的情况下,通过使用作为辅酶的黄素腺嘌呤二核苷酸(fad),能够提高活性。fad以使反应液中的浓度达到通常0.00001毫摩尔浓度~100毫摩尔浓度、优选0.001毫摩尔浓度~10毫摩尔浓度的范围的方式使用。
[0216]
在将反应底物设为二氨基酸的情况下,通常底物浓度为0.01~90%w/v,优选为0.1~30%w/v的范围。
[0217]
由二氨基酸通过生物化学方式制造在1位具有双键的环状氨基酸的方法没有特别限定,可以利用公知的方法进行制造。
[0218]
例如,可以向包含上述酶的液体中加入作为反应底物的二氨基酸,在适当的温度、压力(例如大气压左右)下反应。
[0219]
作为反应底物的二氨基酸通常以反应液中的底物浓度为0.01w/v%~90w/v%、优选0.1w/v%~30w/v%的范围来使用。反应底物可以在反应开始时一次性添加,但从减小存在酶的底物抑制时的影响的观点、提高产物的蓄积浓度的观点出发,优选连续或间歇地添加。
[0220]
上述反应在通常4~60℃、优选10~50℃的反应温度下、通常ph4~11、优选ph5~10下进行。反应时间通常为1小时~72小时左右。
[0221]
使用氨基酸氧化酶的情况下,为了供给反应所需要的氧,在与氧气或空气充分混合的条件下进行反应。例如,可以提高反应容器的振荡或旋转速度,也可以在液体中使氧气、空气进行通气。通常,通气速度优选为0.1vvm~5.0vvm,优选以0.1vvm~1.0vvm的范围使用。
[0222]
上述反应还可以利用膜反应器等来进行。
[0223]
对于通过上述反应生成的通式(i)所示的在1位具有双键的环状氨基酸,可以在反应结束后利用离心分离、膜处理等本领域技术人员公知的分离或纯化方法对反应液中的菌体、蛋白质进行分离后,将利用乙酸乙酯、甲苯等有机溶剂的提取、蒸馏、使用离子交换树脂或硅胶等的柱层析、等电点下的结晶、基于一盐酸盐、二盐酸盐、钙盐等的结晶适宜地组合而进行纯化。
[0224]
本发明中,在得到在1位具有双键的环状氨基酸后,可以进行分离纯化而供于后续的得到l型环状氨基酸的工序,也可以不进行分离纯化而直接供于后续的得到l型环状氨基酸的工序。另外,可以在不同的反应器中进行得到在1位具有双键的环状氨基酸的工序和得到l型环状氨基酸的工序,也可以在同一反应器中进行两工序。
[0225]
实施例
[0226]
以下通过实施例进一步详细地说明本发明,但是本发明不限定于此。
[0227]
需要说明的是,在以下的实施例及参考例中,m表示mol/l,w/v表示重量/容量,dmso表示二甲基亚砜,etda表示乙二胺四乙酸,iptg表示异丙基-β-硫代吡喃半乳糖苷,pipc2表示δ
1-哌啶-2-甲酸,pipa表示哌可酸。
[0228]
<实施例1>(来自植物的亚胺还原酶基因的克隆)
[0229]
(1)来自植物体的目标基因的扩增
[0230]
从自发芽起生长了约1个月的拟南芥、海滨山黧豆分别提取总rna。从自发芽起生长了约1个月的家桑的叶提取总rna。提取中,使用rneasy植物小量试剂盒(plant mini kit)(qiagen公司制)。操作参考该试剂盒记载的规程在室温下进行。从得到的总rna中,使用revertra ace(注册商标)含gdna去除剂的qpcr rt反应混合物(qpcr rt master mix with gdna remover)(toyobo公司制)合成cdna。以得到的cdna文库为基础构建在各植物体中表达的基因的数据库。
[0231]
以得到的cdna为模板进行pcr反应。pcr用的引物按照下述表所记载的那样来制作。作为用于插入到大肠杆菌表达用载体中的限制酶识别位点,在引物的n末端、c末端添加限制酶。
[0232]
[表1]
[0233]
表1
[0234][0235]
pcr基于takara ex taq(注册商标)热启动版本(hot start version)(takara公司制)的规程来进行。组成设为:ex taq hs 0.1μl、10
×
ex taq缓冲液2μl、dntp混合物(各2.5mm)1.6μl、cdna 2μl、10μm正向引物1μl、10μm反向引物1μl、milli-q(注册商标)12.3μl,总量20μl。作为亚胺还原酶基因atp2cr扩增用的引物,使用序列号13中记载的序列作为正向引物,使用序列号14中记载的序列作为反向引物。关于map2cr基因,使用序列号15中记载的序列作为正向引物,使用序列号16中记载的序列作为反向引物。关于ljp2cr基因,使用序列号17中记载的序列作为正向引物,使用序列号18中记载的序列作为反向引物。关于反应条件,在95℃下进行2分钟初始变性,接着在95℃下进行30秒的变性、在60℃下进行30秒的
退火、在72℃下进行1分10秒的延伸反应,将上述重复30个循环,最后在72℃下进行5分钟延伸反应。将反应产物供于使用利用gelred(商标)核酸凝胶染色液(
×
10000)dmso溶液染色且用1
×
tae缓冲液(tris-乙酸-edta缓冲液)制作的2%(w/v)琼脂糖凝胶的电泳。电泳后,用手术刀从琼脂糖凝胶上切出目标1100bp附近的单一条带,使用wizard(注册商标)sv gel and pcr clean-up system(promega公司制)提取cdna。操作按照该系统所附带的规程进行。
[0236]
将得到的各纯化后dna片段4μl、t-vector pmd19(takara bio公司制)1μl、及dna连接试剂盒mighty mix(takara公司制)5μl混合,在反应温度16℃下进行30分钟的连接反应。使用该连接溶液转化大肠杆菌dh5α。
[0237]
为了获得所插入的dna片段的碱基序列,使用得到的质粒约100ng,利用bigdye(注册商标)terminator v3.1/1循环测序试剂盒(cycle sequencing kit)(applied biosystems公司制)进行测序反应。将得到的试样供于abi prism(商标)基因分析仪(genetic analyzer),由此确认各基因序列。
[0238]
对插入的基因序列进行确认的结果是,确认了atp2cr的基因序列为序列号1所示的序列、所编码的氨基酸序列为序列号2所示的序列。另外,确认了map2cr的基因序列为序列号3所示的序列、所编码的氨基酸序列为序列号4,ljp2cr的基因序列为序列号5所示的序列、所编码的氨基酸序列为序列号6。
[0239]
(2)表达载体的制备
[0240]
将上述(1)中亚克隆到pmd19中的候补基因atp2cr、map2cr及ljp2cr用各限制酶进行处理,从多克隆位点切断。利用电泳进行消化确认后,切出作为目标的dna片段,纯化后,将纯化后的克隆的dna片段与上述(1)同样地连接及转化到同样地进行了限制酶处理的作为大肠杆菌表达用载体的pgex 4t-1载体(takara公司制)中。约18小时后,使形成的菌落在lb液体培养基(100μg/ml氨苄青霉素)2ml中生长,与上述(1)同样地进行质粒提取、限制酶处理并确认插入序列。将构建的表达载体分别命名为pgex-atp2cr、pgex-map2cr、pgex-ljp2cr。各载体所表达的酶均为gst融合型蛋白。确认了:gst融合型atp2cr的基因序列为序列号7所示的序列、所编码的氨基酸序列为序列号8,gst融合型map2cr的基因序列为序列号9所示的序列、所编码的氨基酸序列为序列号10,gst融合型ljp2cr的基因序列为序列号11所示的序列、所编码的氨基酸序列为序列号12。
[0241]
(3)重组菌的培养
[0242]
使用上述(2)中制作的表达载体转化大肠杆菌bl21(de3)。约18小时后,将形成的菌落用牙签挑起,放入到lb液体培养基(100μl/ml氨苄青霉素)2ml中,培养一晚,作为预培养液。将预培养液500μl加入到lb液体培养基(100μg/ml氨苄青霉素)50ml中,在培养温度37℃、225rpm下培养至浊度(od600)达到0.5左右,然后添加iptg以使终浓度达到0.1mm。将其在培养温度18℃、150rpm下培养约18小时。作为阴性对照,使用未插入外源基因的载体进行同样的表达操作。
[0243]
(4)基因表达的确认
[0244]
将上述(3)中得到的各可溶性蛋白质级分用gst-tagged蛋白质纯化试剂盒(clontech laboratories公司制)进行纯化(gst-tag纯化),得到酶液。操作按照该试剂盒附带的规程进行。
[0245]
将进行gst-tag纯化而得到的酶液(可溶性蛋白质)供于sds-page,确认了目标蛋白质的表达。其结果是,确认各重组酶的分子量分别为添加了约25kda的标签的约60kda。
[0246]
<实施例2>(来自植物的亚胺还原酶的活性的确认)
[0247]
(1)酶反应
[0248]
使用实施例1中得到的各酶液(p2cr纯化重组酶液)进行酶反应。作为反应容器,使用1.5ml艾本德管(eppendorf tube),以酶反应溶液的体积为100μl来进行。作为底物的pipc2没有市售,因此使用利用后述的参考例1中得到的氨基转移酶maald1由l-赖氨酸进行酶合成而得的pipc2。表2示出pipc2酶反应溶液的组成。
[0249]
[表2]
[0250]
表2
[0251][0252]
酶反应使用振荡恒温器(亚速旺公司制)在反应温度30℃、1000rpm下振荡来进行。反应时间设为120分钟。在反应温度98℃下加热5分钟而使酶失活,停止反应。然后,在室温、15000rpm下离心分离10分钟,将得到的上清作为pipc2酶合成溶液。
[0253]
向该pipc2酶合成溶液中以使终浓度为10mm的方式加入*nadph,加入实施例1中得到的各p2cr纯化重组酶20μl,在与使用上述酶maald1的反应相同的条件下进行反应,得到酶反应产物。
[0254]
(2)酶反应产物的解析
[0255]
利用液相色谱-质谱分析法(lcms)进行酶反应产物的分析。首先,进行各样品(酶反应产物)的衍生化处理。使用accq
·
tag ultra衍生化试剂盒(derivatization kit)(waters公司制)以表3所示的配合进行混合。需要说明的是,衍生化试剂溶液(derivatizating reagent solution)在最后加入。混合后,在55℃下保温10分钟。
[0256]
[表3]
[0257]
表3
[0258][0259]
将进行衍生化处理而得的物质用纯水稀释至2倍,作为lcms解析用样品。将hplc-ms的分析条件示于表4。
[0260]
[表4]
[0261]
表4
[0262][0263]
将酶反应产物供于lcms分析,确认活性的结果是,确认到与标品的l-pipa相同的保留时间且ms图案的新的峰。另外,对照中未能检测到pipa。
[0264]
由该结果表明,atp2cr、map2cr及ljp2cr具有将pipc2还原而转换为pipa的能力。
[0265]
为了确定生成的pipa为d型还是l型,使用手性柱astec clc-d4.6
×
150mm(5μm)(sigma-aldrich公司制)供于hplc分析。将其结果示于图1。明确了由拟南芥、海滨山黧豆及家桑这3种植物获得的p2cr的酶反应产物均为l-哌可酸。
[0266]
(3)酶催化活性的解析
[0267]
以与实施例2(1)相同的组成制作了pipc2酶反应溶液。*nadph以在加入酶溶液后的总体积1ml中终浓度为500μm、300μm、150μm、80μm、40μm、20μm及10μm的方式分别加入到pipc2酶反应溶液中,最后将50mm tris-hcl(ph7.2)加入到各酶反应溶液中,使得总体积达到900μl。将其作为反应溶液。
[0268]
向这些反应溶液中分别加入实施例1中得到的atp2cr的纯化重组酶液100μl而开始反应。从反应开始时刻起测定340nm的吸光度,进行10分钟的测定。将同一实验实施3次,计算平均值。
[0269]
由得到的测定值计算反应速率。使用计算出的反应速率由哈尼斯-伍尔夫图(hanes cs.,(1932),vol.26,5,1406,biochemical journal)计算各动力学参数(米氏常数km及最大反应速率vmax)。
[0270]
对于ljp2cr,也与atp2cr同样地进行反应、测定及计算。
[0271]
对于map2cr,在上述*nadph浓度为80μm、40μm、20μm、10μm、2μm、1μμ及0.5μm的条件下进行反应,除此以外与atp2cr同样地进行测定及计算。
[0272]
使用*nadph的摩尔吸光系数6.3
×
10(1/mmol ·
cm)将测定出的吸光度变化转换为*nadph的浓度变化。由该值计算*nadph的减少中的反应速率(μm/s)。需要说明的是,使用的吸光度的减少值使用了从测定开始起呈线性减少的期间的值。
[0273]
通过在各*nadph浓度下对底物浓度/反应速率的值作图,从而求出哈尼斯-伍尔夫图的线性近似线。将结果示于图2。图2中,(1)为atp2cr、(2)为map2cr、(3)为ljp2cr。3个p2cr的结果中,r2均为0.99,因此认为得到了可靠性高的结果。哈尼斯-伍尔夫图中,斜率为1/vmax,与x轴的交点为km。然后由哈尼斯-伍尔夫公式计算最大反应速率vmax及km。atp2cr的vmax为208.73nmol/分钟/mg、km为33.42μm,map2cr的vmax为24.00nmol/分钟/mg、km为6.16μm,ljp2cr的vmax为199.55nmol/分钟/mg、km为170.24μm。
[0274]
另外,利用anemona(hernandez and ruiz,(1998)14,2,227,bioinformatics)进行非线性回归分析,同样地计算vmax及km。将利用anemona的米海利斯-曼恬模型示于图3。图3中,(1)为atp2cr、(2)为map2cr、(3)为ljp2cr。atp2cr的vmax为215.5nmol/分钟/mg、km为34.29μm,map2cr的vmax为21.2nmol/分钟/mg、km为3.57μm,ljp2cr的vmax为187.3nmol/分钟/mg、km为155.03μm。
[0275]
通过哈尼斯-伍尔夫图和anemona这两种方法求出的vmax及km的值取得了类似的值,因此认为通过非线性回归求出的值为接近真正的vmax及km的值,采用通过anemona求出的vmax及km。
[0276]
[表5]
[0277]
表5
[0278][0279]
(km:mm)
[0280]
*atp2cr,map2cr,lip2cr均为gst融合型蛋白
[0281]
文献(muramatsu等,(2005),vol.280,7,5329the journal of biological chemistry)中记载了,被用作pipa生产的产业用酶催化剂的来自微生物恶臭假单胞菌(pseudomonas putida)的pipc2还原酶dpka的vmax为220nmol/分钟/mg、km为140μm。
[0282]
如表5所示,由该文献计算出的催化活性的指标kcat/km值为56,但本发明的酶的kcat/km值均为超过该值的值。因此可知,atp2cr、map2cr及ljp2cr均具有将pipc2还原而转换为pipa的优良的能力,另外在酶学上稳定,为优良的酶催化剂。
[0283]
<参考例1>(来自植物的赖氨酸氨基转移酶maald1的制备)
[0284]
(a)来自植物的赖氨酸氨基转移酶基因maald1的克隆
[0285]
使用rneasy植物小量试剂盒(qiagen公司制),从自发芽起生长了约1个月的家桑的叶中进行rna提取。从得到的总rna中,使用revertra ace(注册商标)含gdna去除剂的qpcr rt反应混合物(toyobo公司制)合成cdna。
[0286]
以得到的cdna为模板进行pcr反应。关于引物,使用maald1-fw(ggatccatgacgcataattattctcag)(序列号20)和maald1-rv(gtcgactcatttgtaaagagattttagtc)(序列号21)来进行。反应基于takara ex taq(注册商标)热启动版本(takara公司制)的规程来进行。
[0287]
将经纯化的dna克隆到t-vector pmd19(takara bio公司制)中。序列分析的结果是,确认其为编码氨基转移酶maald1(序列号19)的基因。将亚克隆到pmd19中的maald1的基因区域用限制酶bamhi和sali进行处理,从多克隆位点切断。利用电泳进行消化确认后,切出作为目标的dna片段,将经纯化的dna片段连接到纯化后同样地进行了限制酶处理的大肠杆菌表达用载体pcold pros2载体(takara bio公司制)中。使用该溶液转化大肠杆菌dh5α,由此构建目标质粒。将得到的质粒命名为pcold-maald1。
[0288]
(b)重组酶的表达
[0289]
使用上述(a)中制作的表达载体pcold-maald1转化大肠杆菌(bl21株)。约18小时后,将形成的菌落用牙签挑起,放入到lb液体培养基(100μl/ml氨苄青霉素)2ml中,培养一晚,作为预培养液。将预培养液500μl加入到lb液体培养基(100μg/ml氨苄青霉素)50ml中,
在培养温度37℃、225rpm下培养至浊度(od600)达到0.5左右。接着,将pcold-maald1转化体在冰上静置30分钟,以使终浓度为0.1mm的方式加入iptg。将其在培养温度15℃、150rpm下培养约18小时。
[0290]
(c)重组酶的纯化
[0291]
将上述(b)中得到的培养液转移到50ml容量的falcon(注册商标)管中,在2330
×
g、4℃下进行10分钟的离心分离。
[0292]
弃掉上清,向菌体中加入1
×
pbs(磷酸盐缓冲液)5ml,用涡旋混合器进行再悬浮,接着在与此前的离心分离相同的条件下进行离心分离,由此洗涤菌体。将该操作重复2次。
[0293]
向回收的菌体中加入超声处理缓冲液(sonication buffer){50mm tris-hcl(ph 7.5)、150mm nacl、10%(v/v)甘油、5mm二硫苏糖醇(dtt)}4ml,利用超声波破碎(50%duty、output 2、30秒
×
2次)破碎菌体。在15000rpm、4℃下离心分离10分钟,作为可溶性蛋白质级分得到上清、作为不溶性蛋白质级分得到沉淀。
[0294]
将得到的可溶性蛋白质级分使用his-tagged纯化小量制备试剂盒(purification miniprep kit)(clontech laboratories公司制)进行纯化,由此得到maald1。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1