一种基于Void-Kalman滤波器的主动声音模拟装置的制作方法
本发明属于电动车及混合动力汽车主动发声技术领域,具体的说是涉及一种基于void-kalman滤波器的主动声音模拟装置。
背景技术
近几年,随着国家对节能减排、绿色环保的重视,新能源车辆迅猛发展,销量持续增长,有些国家甚至出台了燃油车的禁令时间表,这使电动化、智能化成为汽车发展的必然趋势,电动汽车已被纳入许多国家的发展战略中。
目前,许多国家出台了相关的技术指标,法规对汽车的噪声的上限值进行了限制;然而,随着新能源汽车的发展,汽车nvh又出现了新的问题。声音用来传播信息,是重要的传播媒介之一,汽车噪声除了可以提示行人外,还可以为驾驶员提供车辆状态信息和驾驶体验感,有些赛车和跑车甚至会对发动机和排气管进行合理的结构设计,以产生澎湃的发动机轰鸣声,来增添驾驶乐趣。但由于电动车在低速时非常安静,电驱动系统几乎不发出任何噪声,普通行人很容易忽略汽车的存在,对于视力障碍者,更是很难感受到汽车的存在感,造成安全隐患;此外,由于电动车噪声太低,车内驾驶员缺少通过声音来判断车辆运动状态的必要信息,不仅增加了安全隐患,也使得那些追求发动机轰鸣声的驾驶员感到电动车失去了驾驶乐趣。
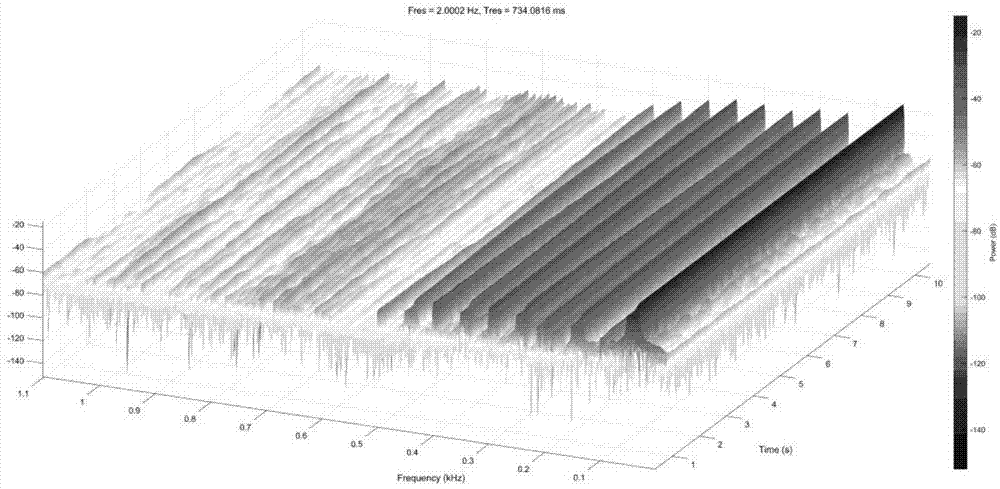
由于电动车在低速时噪声过低而造成的安全隐患也日益突出,特别是有些盲人和视力障碍对此更加敏感;为了解决电动汽车噪声过低而造成的行人安全问题,行人警示音系统应运而生,前几年行人警示音系统在国外主流主机厂还仅作为储备技术,未有实现产业化,在国内市场更属空白。但随着国内整车企业力挺和各国政府相继出台安装声音警示系统的法规标准,行人警示音系统越来越受到重视,市场空间广阔,尽管现在相应的系统已经将要实现产业化,但是如何设计得到一套符合自身品牌形象的声音依然是一个具有挑战性的问题。而且现有相应的系统无法实现在线调整模拟发动机声音的各个阶次信号的成分大小,声音频率成分无法随着车辆工况而变化,会使得声音显得过分单调枯燥,图1展示的是发动机平稳工况下的声音频谱图,图中凸峰代表阶次信号,由于是发动机稳态下的声音,可以看出凸峰对应的频率和峰值随时间是没有变化的,即无法通过对平稳声音的设计得到阶次分量随时间或者转速变化的声音。
技术实现要素:
本发明的目的在于提供一种基于void-kalman滤波器的主动声音模拟装置,以解决现有现有行人警示音系统或车内主动发声系统无法实现在线调整模拟发动机声音的各个阶次信号的成分大小,声音频率成分无法随着车辆工况而变化的技术问题。该主动声音模拟装置可以为电动车行人警示音系统或车内主动发声系统提供一个符合品牌形象的汽车声音,实现模拟发动机声音阶次能量的在线变化与控制,使得声音更加符合审美需求。
为实现上述目的,本发明是采用如下技术方案实现的:
一种基于void-kalman滤波器的主动声音模拟装置,包括:fpga主动声音设计模块、mcu控制发声模块、pc上位机;所述fpga主动声音设计模块,用于完成设计过程中的计算密集型任务,主要是使用void-kalman滤波器进行发动机声源的阶次信号提取,提取出的阶次信号通过spi接口实时下载到mcu控制发声模块中;同时,fpga主动声音设计模块通过spi接口接收mcu控制发声模块的参数信号;所述mcu控制发声模块,用于根据fpga主动声音设计模块提取的阶次信号完成并控制模拟发动机声音实时生成;所述pc上位机,作为人机交互接口,向fpga主动声音设计模块下载控制数据,请求和接收fpga主动声音设计模块发送的数据;
其中,所述mcu控制发声模块包括:mcu主控模块、电源模块、保护电路、can总线模块、fpga与mcu通信模块、dac模块、音频放大器、喇叭;
所述mcu主控模块,一端通过spi总线与fpga主动声音设计模块连接,另一端通过can总线与can总线模块连接,用于获取fpga主动声音设计模块计算提取的发动机声音阶次信号,同时从can总线模块获取车速、加速度和加速踏板开度信号,根据获取的信号来实时控制声音的生成,计算得到的结果通过spi接口发送给dac模块,所述dac模块将数字信号转化为模拟信号,得到的模拟信号经过音频放大器放大,输出给喇叭,产生声音;
所述电源模块与保护电路连接,用于给mcu主控模块及其他外部设备提供可靠的供电;
所述can总线模块,用于从整车can总线上获取车速、加速度和加速踏板开度信息,并将信息发送给mcu主控模块;
所述fpga与mcu通信模块,用于mcu主控模块从fpga主动声音设计模块上读取相应的发动机及发动机阶次音频文件。
作为本发明的优选,所述fpga主动声音设计模块中void-kalman滤波器对发动机声源的阶次信号提取过程如下文所述。为使本申请中各步骤更清楚的表述,下文使用相关数学表达式进行表述,但并非代表本申请中出现的数学表达式或者模型的表达式为本申请技术方案的唯一表现形式,仅作为一种可行且优选的实施方式。
步骤s1、构建kalman滤波器,kalman状态方程和测量方程如下:
x(n)=fnx(n-1)+bnu(n)+ω(n)(1)
y(n)=hnx(n)+v(n)(2)
公式(1)为状态方程,其中,x(n)为状态量,u(n)为输入,ω(n)为系统噪声,fn、bn为矩阵;公式(2)为测量方程,其中,y(n)为测量结果,v(n)为测量噪声,hn为矩阵,系统噪声和测量噪声都被假定为白噪声,ω(n)是系统噪声,其均值为零,且其协方差矩阵为符合多元正态分布的qn;v(n)是测量噪声,其均值为零,且其协方差矩阵为符合多元正态分布的rn,在得到了测量输出y(n)的情况下,运用kalman滤波器得到状态x的最佳估计;滤波过程包含两步:kalman滤波器的预测和更新;
预测:
x(n|n-1)=fnx(n-1|n-1)+bnu(n)(3)
公式(3)为状态预测方程,其中,x(n|n-1)为在已知n-1步的状态下对n步状态的预测,x(n-1|n-1)为第n-1步状态的估计值;公式(4)为协方差矩阵预测方程,p(n|n-1)为第n-1步对第n步的状态协方差预测,p(n-1|n-1)为第n-1步的状态协方差估计;
更新:
其中,
p(n|n)=(i-knhn)p(n|n-1)(9)
其中x(n|n)为当前时刻对状态x的估计,p(n|n)为当前时刻对状态的协方差矩阵的估计;
步骤s2、构建void-kalman滤波器的“状态方程”和“测量方程”;
振动信号的第k阶分量表达为如下的形式:
yk(n)=xk(n)exp(jθk(n))(10)
其中,exp(jθk(n)为复指数正旋信号;xk(n)为复指数信号,是exp(jθk(n))复指数正旋信号的幅值和相位调制信号;
y(n)=∑xk(n)exp(jθk(n))+η(n)(11)
其中,η(n)代表噪声;
对于调制信号xk(t),使用低阶的多项式来表达,其满足
假定s=3,则上述表达式离散化后可以表示为:
xk(n+1)-3xk(n)+3xk(n-1)-xk(n-2)=ak(n)(13)
上式经过变换可以得到
令
xk(n+1)=mxk(n)+ak(n)(15)
将上述公式推广到多个阶次,如下述公式所示:
令
x(n+1)=fx(n)+ω(k)(17)
公式(17)便是对应于void-kalman滤波器的“状态方程”,在这里被称为结构方程;
步骤s3、获取void-kalman滤波器的增广数据方程;
对公式(11)进行变换,得到公式(18)数据方程增广形式
y(n)=h(n)x(n)+η(n)(18)
其中,h(n)=[h1(n),h2(n),h3(n)...hk(n)],hk(n)=[00θk];
步骤s4、使用滤波器进行滤波,得到各个阶次的时域信号;
将上述结构方程和增广数据方程运用kalman滤波框架,得到各个待跟踪阶次的状态估计xk(n),具体做法是令公式(1)中的fn=f,bn=0,u(n)=0,公式(2)中的hn=h(n),将公式(17)和公式(18)带入公式(1)-(9),其它公式符号同公式(1)和(2),得到状态x的估计,最终得到各个阶次的时域信号,通过spi通信接口将得到的各个阶次的时域信号及时下载到mcu控制发声模块中,保证系统的实时性。
作为本发明的优选,所述mcu主控模块实时控制声音生成的过程为:mcu主控模块根据从can总线模块获得的速度、加速度、加速踏板开度信号来控制各个阶次信号和源声音样本输出,控制各个阶次通道的声音增益和音调,最后经过整体音量控制、渐入/渐出控制、滤波模块、dac模块和音频放大器,将信号输出给喇叭;所述的各个阶次信号是由void-kalman滤波器计算得到;通道声音增益是在原阶次信号上乘以一个系数,这个系数即为增益;音调控制是通过线性重采样算法来实现;
将相应阶次信号通道的声音增益设为-1时,其相位与声源中的对应阶次成分的相位恰好相反,理论上该阶次被衰减为零;当相应阶次通道的增益大于零的时候,该阶次成分增多;当阶次通道的增益介于-1到0时,该阶次被衰减,通过控制各个阶次通道的增益来实现各个阶次成分的控制,增益是随速度变化的函数,将相应地阶次通道增益随速度、加速度和加速度变化的函数制成查找表,即实时实现各个阶次成分随速度增强或者衰减,最后得到富有变化的声音。
作为本发明的进一步优选,增益随速度、加速度和加速踏板开度的变化用如下的关系来表达:
ch_1_volume=f_voice_1(s)+k1’×pa_1(a)+k2’×pp_1(p)
ch_2_volume=f_voice_2(s)+k3’×pa_2(a)+k4’×pp_2(p)
ch_3_volume=f_voice_3(s)+k5’×pa_3(a)+k6’×pp_3(p)
……
ch_i_volume=f_voice_i(s)+k(2i-1)’×pa_i(a)+k(2i)’×pp_i(p)
……
ch_n_volume=f_voice_n(s)+k(2n-1)’×pa_n(a)+k(2n)’×pp_n(p)
其中,ch_i_volume代表第i个通道(或者说阶次)的增益,s为速度,a为加速度,p为加速踏板开度;函数f_voice_i(s)、pa_i(a)、pp_i(p)刻画了第i个通道增益和速度、加速度与踏板开度之间的关系;k(2i-1)’为加速度权重的开关量,当其为1时,表示第i个通道的增益是随加速度变化的;为0时,表示该通道增益不随加速度变化;k(2i)’为第i个通道的加速踏板开度权重,当其为1时,表示第i个通道的增益是随加速踏板变化的,为0时,表示该通道增益不随加速踏板变化。
作为本发明的更进一步优选,音调控制主要是实现模拟发动机声音音调随速度、加速度和踏板开度的变化,音调的控制是通过对源声音进行重采样,再以相同的播放速率播放出来实现的,提高采样率,声音音调就会降低,降低采样率,声音音调就会身升高,与通道的音量控制相同,用如下来描述其与速度的关系:
ch_1_pitch=f_voice_1(s)+k1×pa(a)+k2×pp(p)
ch_2_pitch=f_voice_2(s)+k3×pa(a)+k4×pp(p)
ch_3_pitch=f_voice_3(s)+k5×pa(a)+k6×pp(p)
……
ch_i_pitch=f_voice_i(s)+k(2i-1)×pa(a)+k(2i)×pp(p)
……
ch_n_pitch=f_voice_n(s)+k(2n-1)×pa(a)+k(2n)×pp(p)
其中,ch_i_pitch代表第i个通道(或者说阶次)的音调,s为速度,a为加速度,p为加速踏板开度,函数f_voice_i(s)、pa_i(a)、pp_i(p)刻画了第i个通道音调和速度、加速度与踏板开度之间的关系;k(2i-1)’为加速度权重的开关量,当其为1时,表示第i个通道的音调是随加速度变化的;为0时,表示该通道音调不随加速度变化;k(2i)’为第i个通道的加速踏板开度权重,当其为1时,表示第i个通道的音调是随加速踏板变化的,为0时,表示该通道音调不随加速踏板变化。
作为本发明的更进一步优选,所述整体音量控制是用于实现对最后输出声音声压级大小的控制;所述滤波模块采用低通滤波器,滤掉高频噪声;所述dac模块采用16位dac模块;所述渐入/渐出控制过程是:在系统开始工作时,系统音量会逐渐增大,避免过分突兀,惊吓到行人;当系统退出工作时,音量会逐渐减小,而不是突然减小,以避免吓到行人。
作为本发明的更进一步优选,所述mcu控制发声模块还包括led指示灯,led指示灯通过led驱动器与mcu主控模块连接,当mcu主控模块出现故障时,led指示灯闪亮或熄灭,提醒出现故障。
作为本发明的更进一步优选,所述pc上位机主要是实现对系统参数的设置,主要包括声音加载菜单、void-kalman滤波器参数菜单、阶次增益vs车速菜单以及其它参数菜单;其中,所述声音加载菜单,主要实现录制得到的发动机声音的加载;所述void-kalman滤波器参数菜单,主要实现void-kalman滤波器参数的设定,便于提取得到各个所需阶次的时间域信号;所述阶次增益vs车速表菜单,主要是为了设计各个阶次信号随时间变化的曲线图;所述其它参数菜单,主要控制系统的其它参数,如整体音量控制等。
本发明的优点和积极效果:本发明提供的主动声音模拟装置利用void-kalman滤波器实现对发动机声音阶次信号的提取,然后通过mcu主控模块来实时控制声音的生成,从而得到富有变化的发动机声音,该声音不仅可以提醒行人,降低安全隐患,还可以让驾驶者感受到开车的乐趣;此外,通过该声音驾驶者还可以及时了解车辆工况情况,例如车速、加速度等信息,进一步降低安全隐患;该模拟装置可以为电动车行人警示音系统或车内主动发声系统提供一个符合品牌形象的汽车声音,实现模拟发动机声音阶次能量的在线变化与控制,使得声音更加符合审美需求;由于该模拟装置结构简单,安装自由灵活,整车厂可根据自身品牌的特点自由配置和设计符合自身的模拟发动机声音。
附图说明
图1为发动机平稳工况下的声音频谱图。
图2是本发明模拟装置的结构示意图。
图3是void-kalman滤波器提取发动机声源的阶次信号流程图。
图4是mcu主控模块控制原理图。
图5pc上位机人机交互界面图。
图6为本发明获得的富有变化的发动机声音频谱图。
具体实施方式
为使本领域技术人员更加清楚本发明的技术方案和优点,下面将结合附图对本发明的技术方案进行清楚、完整地描述。
参阅图2,本发明提供的一种基于void-kalman滤波器的主动声音模拟装置,包括:fpga主动声音设计模块1、mcu控制发声模块2、pc上位机3;所述fpga主动声音设计模块1,用于完成设计过程中的计算密集型任务,主要是使用void-kalman滤波器进行发动机声源的阶次信号提取,提取出的阶次信号通过spi接口实时下载到mcu控制发声模块中;同时,fpga主动声音设计模块1通过spi接口接收mcu控制发声模块2的参数信号;所述mcu控制发声模块2,用于根据fpga主动声音设计模块提取的阶次信号完成并控制模拟发动机声音实时生成;所述pc上位机3,作为人机交互接口,向fpga主动声音设计模块下载控制数据,请求和接收fpga主动声音设计模块发送的数据;
其中,所述mcu控制发声模块2包括:mcu主控模块21、电源模块22、保护电路23、can总线模块24、fpga与mcu通信模块25、dac模块26、音频放大器27、喇叭28、led指示灯29;
所述mcu主控模块21,一端通过spi总线与fpga主动声音设计模块1连接,另一端通过can总线与can总线模块24连接,用于获取fpga主动声音设计模块计算提取的发动机声音阶次信号,同时从can总线模块24获取车速、加速度和加速踏板开度信号,根据获取的信号来实时控制声音的生成,计算得到的结果通过spi接口发送给dac模块26,所述dac模块26将数字信号转化为模拟信号,得到的模拟信号经过音频放大器27放大,输出给喇叭28,产生声音;
所述电源模块22与保护电路23连接,用于给mcu主控模块21及其他外部设备提供可靠的供电;
所述can总线模块24,用于从整车can总线上获取车速、加速度和加速踏板开度信息,并将信息发送给mcu主控模块21;
所述fpga与mcu通信模块25,用于mcu主控模块从fpga主动声音设计模块上读取相应的发动机及发动机阶次音频文件;
所述led指示灯29通过led驱动器与mcu主控模块21连接,当mcu主控模块21出现故障时,led指示灯闪亮或熄灭,提醒出现故障;当led指示灯出现故障时,led驱动器将故障信号传输给mcu主控模块21。
由于声音设计相关的数值信号处理是非常消耗计算资源的,mcu主控模块21无法独立完成工作,为了满足实时性要求,需要基于fpga主动声音设计模块1,fpga主动声音设计模块1完成的主要计算工作是void-kalman滤波器,使用该技术的主要原因是,现有系统无法通过对平稳声音的设计得到阶次分量随时间或者转速变化的声音,富有变化(阶次成分变化)的声音往往让人感觉更加有趣,相反则让人感觉枯燥。
参阅图3,本发明为得到富有变化的发动机声音,所述fpga主动声音设计模块中void-kalman滤波器对发动机声源的阶次信号提取过程如下:
步骤s1、构建kalman滤波器,kalman状态方程和测量方程如下:
x(n)=fnx(n-1)+bnu(n)+ω(n)(1)
y(n)=hnx(n)+v(n)(2)
公式(1)为状态方程,其中,x(n)为状态量,u(n)为输入,ω(n)为系统噪声,fn、bn为矩阵;公式(2)为测量方程,其中,y(n)为测量结果,v(n)为测量噪声,hn为矩阵,系统噪声和测量噪声都被假定为白噪声,ω(n)是系统噪声,其均值为零,且其协方差矩阵为符合多元正态分布的qn;v(n)是测量噪声,其均值为零,且其协方差矩阵为符合多元正态分布的rn,在得到了测量输出y(n)的情况下,运用kalman滤波器得到状态x的最佳估计;滤波过程包含两步:kalman滤波器的预测和更新;
预测:
x(n|n-1)=fnx(n-1|n-1)+bnu(n)(3)
公式(3)为状态预测方程,其中,x(n|n-1)为在已知n-1步的状态下对n步状态的预测,x(n-1|n-1)为第n-1步状态的估计值;公式(4)为协方差矩阵预测方程,p(n|n-1)为第n-1步对第n步的状态协方差预测,p(n-1|n-1)为第n-1步的状态协方差估计;
更新:
其中,
p(n|n)=(i-knhn)p(n|n-1)(9)
其中x(n|n)为当前时刻对状态x的估计,p(n|n)为当前时刻对状态的协方差矩阵的估计;
步骤s2、构建void-kalman滤波器的“状态方程”和“测量方程”;
振动信号的第k阶分量表达为如下的形式:
yk(n)=xk(n)exp(jθk(n))(10)
其中,exp(jθk(n)为复指数正旋信号;xk(n)为复指数信号,是exp(jθk(n))复指数正旋信号的幅值和相位调制信号;
y(n)=∑xk(n)exp(jθk(n))+η(n)(11)
其中,η(n)代表噪声;
对于调制信号xk(t),使用低阶的多项式来表达,其满足
假定s=3,则上述表达式离散化后可以表示为:
xk(n+1)-3xk(n)+3xk(n-1)-xk(n-2)=ak(n)(13)
上式经过变换可以得到
令
xk(n+1)=mxk(n)+ak(n)(15)
将上述公式推广到多个阶次,如下述公式所示:
令
x(n+1)=fx(n)+ω(k)(17)
公式(17)便是对应于void-kalman滤波器的“状态方程”,在这里被称为结构方程;
步骤s3、获取void-kalman滤波器的增广数据方程;
对公式(11)进行变换,得到公式(18)数据方程增广形式
y(n)=h(n)x(n)+η(n)(18)
其中,h(n)=[h1(n),h2(n),h3(n)...hk(n)],hk(n)=[00θk];
步骤s4、使用滤波器进行滤波,得到各个阶次的时域信号;
将上述结构方程和增广数据方程运用kalman滤波框架,得到各个待跟踪阶次的状态估计xk(n),具体做法是令公式(1)中的fn=f,bn=0,u(n)=0,公式(2)中的hn=h(n),将公式(17)和公式(18)带入公式(1)-(9),其它公式符号同公式(1)和(2),得到状态x的估计,最终得到各个阶次的时域信号,通过spi通信接口将得到的各个阶次的时域信号及时下载到mcu控制发声模块中,保证系统的实时性,通过mcu主控模块21实时控制声音生成。
参阅图4,所述mcu主控模块21实时控制声音生成的过程为:mcu主控模块21根据从can总线模块24获得的速度、加速度、加速踏板开度信号来控制各个阶次信号和源声音样本输出,控制各个阶次通道的声音增益和音调,最后经过整体音量控制、渐入/渐出控制、滤波模块、dac模块26和音频放大器27,将信号输出给喇叭28;所述的各个阶次信号是由void-kalman滤波器计算得到;通道声音增益是在原阶次信号上乘以一个系数,这个系数即为增益;音调控制是通过线性重采样算法来实现;
将相应阶次信号通道的声音增益设为-1时,其相位与声源中的对应阶次成分的相位恰好相反,理论上该阶次被衰减为零;当相应阶次通道的增益大于零的时候,该阶次成分增多;当阶次通道的增益介于-1到0时,该阶次被衰减,通过控制各个阶次通道的增益来实现各个阶次成分的控制,增益是随速度变化的函数,将相应地阶次通道增益随速度、加速度和加速度变化的函数制成查找表,即实时实现各个阶次成分随速度增强或者衰减,最后得到富有变化的声音,富有变化的发动机声音频谱图见图6。
本发明增益随速度、加速度和加速踏板开度的变化可以用如下的关系来表达:
ch_1_volume=f_voice_1(s)+k1’×pa_1(a)+k2’×pp_1(p)
ch_2_volume=f_voice_2(s)+k3’×pa_2(a)+k4’×pp_2(p)
ch_3_volume=f_voice_3(s)+k5’×pa_3(a)+k6’×pp_3(p)
……
ch_i_volume=f_voice_i(s)+k(2i-1)’×pa_i(a)+k(2i)’×pp_i(p)
……
ch_n_volume=f_voice_n(s)+k(2n-1)’×pa_n(a)+k(2n)’×pp_n(p)
其中,ch_i_volume代表第i个通道(或者说阶次)的增益,s为速度,a为加速度,p为加速踏板开度;函数f_voice_i(s)、pa_i(a)、pp_i(p)刻画了第i个通道增益和速度、加速度与踏板开度之间的关系;k(2i-1)’为加速度权重的开关量,当其为1时,表示第i个通道的增益是随加速度变化的;为0时,表示该通道增益不随加速度变化;k(2i)’为第i个通道的加速踏板开度权重,当其为1时,表示第i个通道的增益是随加速踏板变化的,为0时,表示该通道增益不随加速踏板变化。
本发明音调控制主要是实现模拟发动机声音音调随速度、加速度和踏板开度的变化,音调的控制是通过对源声音进行重采样,再以相同的播放速率播放出来实现的,提高采样率,声音音调就会降低,降低采样率,声音音调就会身升高,与通道的音量控制相同,可以用如下来描述其与速度的关系:
ch_1_pitch=f_voice_1(s)+k1×pa(a)+k2×pp(p)
ch_2_pitch=f_voice_2(s)+k3×pa(a)+k4×pp(p)
ch_3_pitch=f_voice_3(s)+k5×pa(a)+k6×pp(p)
……
ch_i_pitch=f_voice_i(s)+k(2i-1)×pa(a)+k(2i)×pp(p)
……
ch_n_pitch=f_voice_n(s)+k(2n-1)×pa(a)+k(2n)×pp(p)
其中,ch_i_pitch代表第i个通道(或者说阶次)的音调,s为速度,a为加速度,p为加速踏板开度,函数f_voice_i(s)、pa_i(a)、pp_i(p)刻画了第i个通道音调和速度、加速度与踏板开度之间的关系;k(2i-1)’为加速度权重的开关量,当其为1时,表示第i个通道的音调是随加速度变化的;为0时,表示该通道音调不随加速度变化;k(2i)’为第i个通道的加速踏板开度权重,当其为1时,表示第i个通道的音调是随加速踏板变化的,为0时,表示该通道音调不随加速踏板变化。
所述整体音量控制是用于实现对最后输出声音声压级大小的控制;所述滤波模块采用低通滤波器,滤掉高频噪声;所述dac模块26采用16位dac模块;所述渐入/渐出控制过程是:在系统开始工作时,系统音量会逐渐增大,避免过分突兀,惊吓到行人;当系统退出工作时,音量会逐渐减小,而不是突然减小,以避免吓到行人。
参阅图5,本发明所述的pc上位机3主要是实现对系统参数的设置,主要包括声音加载31菜单、void-kalman滤波器参数32菜单、阶次增益vs车速33菜单以及其它参数34菜单;其中,所述声音加载31菜单,主要实现录制得到的发动机声音的加载;所述void-kalman滤波器参数32菜单,主要实现void-kalman滤波器参数的设定,便于提取得到各个所需阶次的时间域信号;所述阶次增益vs车速表33菜单,主要是为了设计各个阶次信号随时间变化的曲线图;所述其它参数34菜单,主要控制系统的其它参数,如整体音量控制等。此外,还可以在pc上位机人界交互界面设置void-kalman滤波器的阶次,可以指定要提取的发动机声音的阶次,坐标中显示的是各个阶次信号的时域图。
- 还没有人留言评论。精彩留言会获得点赞!