一种不同品牌等级的同种茶叶香气区分检测方法与流程
本发明涉及数据分析
技术领域:
,尤其涉及一种不同品牌等级的同种茶叶香气数据分类方法。
背景技术:
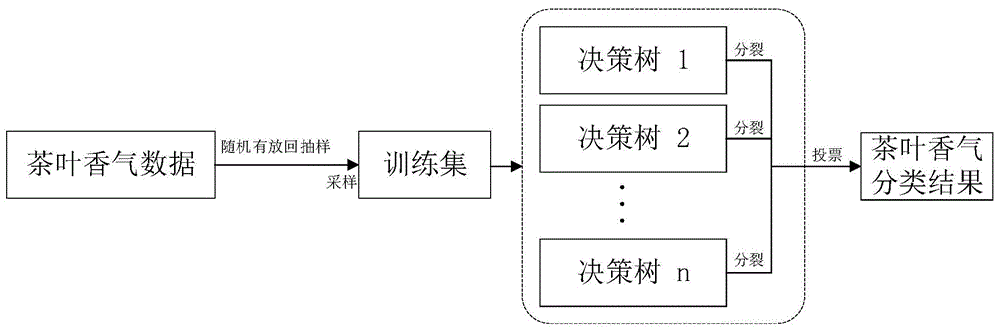
:中国属于茶叶大国,茶叶的种类和等级成千上万,各个地区也有不同品牌的名茶和特色茶。但是随着市场需求的逐渐扩大,市面上销售的茶叶质量参差不齐。茶叶的加工方法主要有两种,手工加工和机器加工。一般的大型自动化茶厂,原料采摘和加工过程都有明确的标准。但是手工炒制的茶叶,根据不同的炒制师傅,加工工艺或多或少会有不同。消费者在购买茶叶的过程中,由于缺乏茶叶的相关专业知识,面对纷繁复杂的茶叶品牌和等级分类,消费者很难挑选合适的茶叶。针对这个需求,目前主要有以下几种解决方法:第一种,聘请茶叶专家人工区分,通过茶的色泽、香气、滋味以及多年的经验来评判;第二种,结合香气传感器构成的电子鼻系统和味觉传感器构成电子舌系统,对香气和滋味数据进行结合分析,得出茶叶分类结果。但是这类方法消耗的成本较高;第三种,利用香气传感器构建电子鼻系统检测茶叶香气数据,对香气数据进行分类处理。技术实现要素:本发明的目的在于针对消费者对市面上的茶叶等级种类分类较为困难的问题,提供一种不同品牌等级的同种茶叶香气数据分类方法。本发明的目的是通过以下技术方案来实现的:一种不同品牌等级的同种茶叶香气区分检测方法,该方法包括以下步骤:(1)利用传感器性能的相关性计算和传感器针对茶叶香气成分的敏感程度筛选出8个传感器,构建电子鼻系统用于香气检测;(2)采集不同品牌及不同等级的龙井茶样本,用步骤(1)的电子鼻系统对样本的茶叶香气进行检测,获取样本的香气数据,将香气数据作为原始数据进行统计,得到香气数据库;(3)使用原始数据构建决策树模型cart,使用gini系数来分裂属性其中d为香气数据库,c是样本类型数量,pi是每种样本类型的可能性;若cart将样本类型a视为可分裂节点,则对应的子节点为dl和dr;则分裂后的gini系数为通过分裂后的gini系数获得分裂属性的最优解,对香气数据库进行数据分类,得到不同品牌等级的同种茶叶香气分类结果。进一步地,所述步骤(1)中,筛选的8个传感器型号为tgs813,tgs822,tgs2602,tgs2620,tgs2600,mq-138,mq-135,mq-6。进一步地,所述步骤(2)具体为:(2.1)采用7种不同品牌及不同等级的龙井茶样本,每种样本随机选取25g作为待测样本;(2.2)将步骤(2.1)中的样本分为5g/杯,并用250ml沸水冲泡;(2.3)密封浸泡5分钟后,倒掉茶汤,滤出茶叶;(2.4)将步骤(2.3)中滤出的茶叶密封于杯中,静置45分钟放凉,保证室温在25±1℃,且室内相对湿度在80±2%;(2.5)将步骤(2.4)中杯内的茶叶香气抽取到电子鼻系统中;(2.6)统计8个传感器80秒的数据,则每一杯有640个数据,总共22400个数据构成香气数据库。进一步地,所述步骤(3)具体为:(3.1)将总共22400个原始数据作为香气数据库d;(3.2)从d中随机有放回抽样n个样本,并做k次随机采样,得到k个训练集;(3.3)使用k个训练集构建k个分类决策树模型cart;(3.4)针对每个cart,使用gini系数来分裂属性,得到分裂后的gini系数;(3.5)gini系数越大代表着样本的不确定性也越大,因此最小的gini系数是分裂属性的最优解;(3.6)按照上述步骤继续分裂属性直到样本都被分为同一类别为止;(3.7)所有的cart模型构成一个随机森林,茶叶香气样本的最终分类结果就是所有cart决策树的投票结果。进一步地,得到香气数据库后,可采用固定片段参数t进行片段分割,通过基于时域片段的茶叶香气数据,对不同品牌等级的同种茶叶香气进行分类,具体步骤如下:a.采集传感器80s的香气数据样本用于计算;b.采用固定片段参数t进行片段分割,分别将80s的香气数据分割为t=10s一段或是t=20s一段;c.将步骤b中的数据片段利用步骤(3)的方法重新进行分类检测,并随机提取3个时域片段的分类结果;d.分类结果平均值即为茶叶香气样本的分类结果。本发明的有益效果是:本发明以龙井茶为例,对7种不同品牌不同等级的茶叶香气数据做分类处理,实验结果证明分类成功率高于95%。说明基于电子鼻系统的茶叶香气数据,可以对茶叶进行较为准确的区分,对于消费者选取茶叶有较高的参考价值。附图说明图1本发明不同品牌等级的同种茶叶香气数据分类方法的流程图;图2本发明基于时域片段的茶香数据分割方法。具体实施方式下面结合附图和具体实施例对本发明作进一步详细说明。一种不同品牌和不同等级的同种茶叶香气区分检测方法,包括以下步骤:(1)利用相关性计算和传感器敏感程度筛选出8个传感器,构建电子鼻系统用于香气检测,筛选出的8个传感器型号以及敏感物质如表1所示;表1传感器型号以及敏感物质表(2)用步骤1的电子鼻系统对茶叶香气进行检测,以不同品牌不同等级的龙井茶为例,将香气数据进行统计得到香气数据库;(2.1)采购7种不同品牌及不同等级的龙井茶样本,如表2所示,每种样本随机选取25g待测样本;表2龙井茶实验样本数据来源表品牌等级价格(¥/500g)品牌西湖龙井-特级500杭州本土茶农处购买西湖龙井-一级260杭州本土茶农处购买西湖龙井-二级100杭州本土茶农处购买聚呈龙井-一级850聚呈西湖龙井聚呈龙井-二级336聚呈西湖龙井佩云龙井-一级690佩云西湖龙井佩云龙井-二级345佩云西湖龙井(2.2)将步骤2.1中的样本分为5g/杯,并用250ml沸水冲泡;(2.3)密封浸泡5分钟后,倒掉茶汤,滤出茶叶;(2.4)将步骤2.3中滤出的茶叶密封于杯中,静置45分钟放凉(保证室温在25±1℃,且室内湿度在80±2%左右);(2.5)将步骤2.4中杯内的茶香气抽取到电子鼻系统中;(2.6)统计8个传感器80秒的数据,则每一杯有640个数据(80*8);(3)利用机器学习方法对香气数据库进行数据分类,目的在于区分不同品牌不同等级的龙井茶香,具体方法流程如图1所示。(3.1)将22400(7种*8个传感器*80秒*5杯)个原始数据视为茶香数据集d;(3.2)从d中随机有放回抽样n个样本,并做k次随机采样,得到k个训练集;(3.3)使用k个训练集构建k个分类决策树模型(cart);(3.4)针对每个cart,使用gini系数来分裂属性其中c是样本类型数量,pi是每种样本类型的可能性;(3.5)若cart将样本类型a视为可分裂节点,则对应的子节点为dl和dr。则分裂后的gini系数为(3.6)gini系数越大代表着样本的不确定性也越大,因此最小的gini系数是分裂属性的最优解;(3.7)按照上述步骤继续分裂属性直到样本都被分为同一类别为止;(3.8)所有的cart模型构成一个随机森林,茶叶香气样本的最终分类结果就是所有cart决策树的投票结果。提出了一种基于时域片段的茶香数据分类简化计算方法,具体步骤如下:a.通常,茶叶香气需要采集60s以上的数据才能进行精确分类,本方法采集了80s的香气数据样本用于计算;b.基于时域片段的茶香数据分类简化计算方法需提供固定片段参数t用于片段分割;c.本发明验证了t=10,20两种参数,分别将80s的香气数据分割为10s一段或是20s一段,具体分割方法如图2所示;d.将步骤c中的数据片段利用步骤(3)的方法重新进行分类检测;e.结果证明每个片段的结果与步骤(3)中整体数据分类的结果近似;f.为了减少分类方法的计算量,并最大程度确保分类精确性,本发明随机提取3个时域片段的分类结果;g.步骤f中的分类结果平均值即为茶叶香气样本的分类结果。利用本发明方法对7种不同品牌不同等级的龙井茶香气做分类,其中分类效果如表3所示。对比了3种其它机器学习方法的分类效果:线性判别分类(lda)、多层感知器分类(mlp)、支持向量机分类(svm)。可以发现,本发明方法准确率都在95%以上,分类效果较好。表3本发明方法与其他算法分类效果准确率比较表rfldamlpsvm西湖龙井-特级1.00000.93750.76630.9725西湖龙井-一级0.99750.99250.87130.9925西湖龙井-二级1.00001.00001.00001.0000聚呈龙井-二级1.00000.83880.82130.7550聚呈龙井-一级0.99370.65880.45000.3438佩云龙井-二级0.99370.65130.46130.4700佩云龙井-一级0.99620.54130.35630.7575平均值0.99730.80290.67520.7559当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1