基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法与流程
本发明涉及高炉冶炼自动化控制技术领域,尤其涉及一种基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法。
背景技术
高炉炼铁作为最重要的炼铁方式,正在向大规模、高效益、低能耗、自动化的方向发展,其中高炉炼铁闭环自动控制一直是冶金工程和自动化领域的难题。由于高炉炼铁系统是一个物理化学反应复杂、多相、多场耦合的非线性、大滞后、动态时变系统,因此很难为其建立精确的数学模型,从而很难实现稳定控制。目前,被广泛用来间接反映高炉内部状态的指标为铁水质量参数,其中铁水si含量和铁水温度是衡量高炉内热状态和稳定顺行的主要参数。采用铁水质量参数作为高炉内部状态的评判指标,可以较全面地了解高炉内部的运行状态,为高炉的控制运行提供指导。因此,要实现高炉炼铁过程的稳定顺行,并且生产出质量合格的铁水,为后续的转炉炼钢提供优质的原材料,有必要对铁水质量参数加以有效的监测和控制。
预测控制被广泛应用于高炉炼铁过程,由于高炉炼铁过程是一个非线性过程,因此传统基于线性模型预测控制方法无法实现有效控制。已有研究将支持向量回归和双线性子空间辨识等非线性建模方法与模型预测控制相结合,从而实现非线性高炉炼铁过程铁水质量的优化控制。
公开号为cn107390524a的专利“一种基于双线性子空间辨识的优化控制方法”,该专利基于双线性子空间辨识技术与模型预测控制,提出一种高炉铁水质量指标优化控制方法,利用双线性子空间辨识方法构造一个结构简单的高炉铁水质量指标预测模型,实现同时对综合性的铁水质量指标,即铁水si含量和铁水温度进行预测,然后进一步将此模型作为预测模型应用于模型预测控制中,实现了高炉铁水质量对设定期望值的快速跟踪。但是高炉炼铁系统具有复杂的非线性,双线性子空间模型对复杂非线性系统的逼近能力不强,因此利用双线性子空间辨识方法获得的预测模型,不能充分地表达非线性系统的动态特性。
公开号为cn106249724a的专利“一种高炉多元铁水质量预测控制方法及系统”,该专利依据高炉冶铁过程生产线上传感器测量的高炉多元铁水相关数据,结合多输出最小二乘支持向量回归理论,建立了高炉多元铁水质量与控制量之间的m-ls-svr预测模型,然后用非线性预测控制理论设计了非线性预测控制器,实现对多元铁水质量的有效控制。但该专利中的非线性建模方法基于离线全局建模,缺乏在线参数调整机制,当预测模型不匹配或者设定工作范围改变时,全局模型很难在线更新,从而导致控制系统不稳定。
此外,在实际高炉炼铁生产过程中,会产生大量离线和在线测量数据,如何充分利用这些数据信息对控制器参数进行实时调整,也是高炉炼铁自动控制过程中的关键问题。而且受检测仪表和变送器等装置的故障以及其他异常干扰对测量数据的影响,采集数据经常出现数据异常情况,如:数据值大于实际情况或者出现数据缺失现象。在上述专利提供的方法以及其他相关文献相关类似方法,均没有对此类异常数据干扰情况设计合理的鲁棒机制。
技术实现要素:
本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法,有效解决了非线性预测控制中预测模型的在线更新问题,并且该方法可以重复利用有用数据样本,大大提高了离线和在线输入输出测量数据的利用率,能有效抑制异常数据对控制器的影响,增强控制器的鲁棒性能,从而提高高炉炼铁系统的稳定性。
为解决上述技术问题,本发明所采取的技术方案是:
一种基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法,包括以下步骤:
步骤1、选取铁水si含量和铁水温度作为被控量,选取高炉本体参数中与被控量相关性最强且可操作的变量作为控制量,控制量包括冷风流量、热风温度、富氧流量、喷煤量,根据选择的控制量和被控量采集高炉生产历史输入输出数据,对数据进行预处理,并构造初始数据库,初始化相关参数;
步骤2、构造当前工作时刻的查询回归向量,通过懒惰学习方法从数据库中查询相似数据样本组成学习子集,采用留一法交叉验证选出最优相似学习子集,根据最优相似学习子集中的数据样本信息处理异常数据,并采用多输出最小二乘支持向量回归建模方法建立局部预测模型;
步骤3、计算多步输出预测值进行并对预测值进行在线校正,根据未来输出期望值与校正后预测值构造控制性能指标,利用序贯二次规划算法计算得到最优控制向量,即当前时刻的最优输入——冷风流量、热风温度、富氧流量、喷煤量;
步骤4、将最优控制向量即最优的冷风流量、热风温度、富氧流量和喷煤量发给底层plc系统并调节执行机构,采集新一组高炉测量数据,数据预处理并更新数据库。
所述步骤1中,数据预处理包括滤波处理和归一化处理;滤波处理,采用噪声尖峰滤波算法剔除高炉生产过程中的噪声尖峰跳变数据;归一化处理,对滤波后的高炉生产历史数据,包括控制量和被控量,进行归一化处理;
所述步骤1中,构造初始数据库,初始化相关参数包括:确定局部预测模型结构为y(t)=f(x(t)),f(·)为非线性映射,将上一时刻控制向量、当前时刻控制向量、上一时刻被控向量作为局部预测模型输入,即x(t)=[yt(t-1),ut(t),ut(t-1)]t为局部预测模型输入,当前时刻被控向量y(t)作为局部预测模型输出;根据映射对{x(t),y(t)}的形式,利用历史输入输出数据构造初始数据库
所述步骤2的具体方法包括:
步骤2.1、根据当前工作时刻t,采集上一时刻的控制向量u(t-1)、上一时刻的被控向量y(t-1),构造查询回归向量xt=[yt(t-1),ut(t),ut(t-1)]t;由于u(t)是需要求解的当前时刻控制向量,所以在计算xt与数据库中xi间的相似度时不考虑该项,同时也不考虑xt中的异常数据项,将高于历史采集数据中最大值的2倍以上或者出现数据缺失的新采集数据视为异常数据;
步骤2.2、为了计算查询回归向量xt与数据库中数据向量xi的相似度大小,综合考虑xt与xi间的角度和距离,定义相似度如下:
s(xi,xt)=σ·exp(-dti)+(1-σ)·cos(αti),cos(αti)≥0
其中,s(xi,xt)∈[01],若s(xi,xt)越接近1表示xi与xt越相似,0≤σ≤1是权重参数,用于调节距离相似性dti和角度相似性cos(αti)所占比重的大小;
根据上述定义的相似度,查询数据库中与xt最相似的k个xi,并组成相似学习子集{xi,yi},i=1,2,…,k,由于k∈[kminkmax],所以有(kmax-kmin+1)个相似学习子集;
步骤2.3、为了选出最优相似学习子集,采用留一法交叉验证方法,分别计算(kmax-kmin+1)个相似学习子集对应的留一法交叉验证均方误差,选择对应均方误差最小的相似学习子集,作为最优相似学习子集;
m输入n输出最小二乘支持向量回归预测模型如下:
其中,
如下计算每个学习子集对应的留一法交叉验证均方误差:
其中,mseloo(k)为对应近邻数为k的留一法交叉验证均方误差;
步骤2.4、鲁棒机制:为保证控制系统稳定工作,需要及时处理xt中的异常数据,根据最优相似学习子集中的数据向量xi,i=1,2,…,kbest,如下计算平均数据向量
将xt的异常数据项用
步骤2.5、将最优相似学习子集作为训练集,采用多输出最小二乘支持向量回归建模方法建立局部预测模型。
所述步骤3的具体方法包括:
步骤3.1、根据局部预测模型计算提前多步的预测输出;
局部预测模型的np步预测输出分别为:
其中,
步骤3.2、根据被控向量设定期望值建立参考轨迹方程,使铁水质量指标能够平滑过渡到设定期望值;
步骤3.3、为了防止模型失配或环境干扰对控制器的影响,反馈校正采用对未来的误差做出预测并加以补偿;
步骤3.4、预测控制性能指标为高炉铁水质量指标参考轨迹和高炉铁水质量指标预测值的误差平方和并对其进行加权,同时在指标中加入对控制向量增量的惩罚项;采用序贯二次规划算法对高炉铁水质量指标预测控制中的优化问题进行优化求解,得到使性能指标函数值最小的控制向量增量,进而得到最优控制向量。
采用上述技术方案所产生的有益效果在于:本发明提供的基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法,将懒惰学习与非线性支持向量回归预测控制相结合,该方法通过实时查询数据库中的相似数据样本,为系统建立当前工作点的局部预测模型,有效解决了非线性预测控制中预测模型的在线更新问题。并且该方法可以重复利用有用数据样本,大大提高了离线和在线输入输出测量数据的利用率。由于懒惰学习在每一个控制时刻建立新的局部预测模型,不保留旧模型参数,因此过去时刻出现的干扰不会影响当前时刻局部预测模型的预测准确性,有利于控制器对输入和输出干扰的抑制。此外,本发明考虑到在实际炼铁生产过程中,受检测仪表和变送器等装置的故障以及其他异常干扰对测量数据的影响,针对高炉炼铁过程中出现的数据异常情况,利用从数据库中查询的相似数据样本信息来处理异常数据,有效抑制了异常数据对控制器的影响,增强了控制器的鲁棒性能,从而提高了高炉炼铁系统的稳定性。
本发明提供的方法能够自适应高炉炼铁过程时变的工况,避免了离线全局建模方法的局限性,更加贴合实际工业过程,实用价值很高。同时,本发明也为如何合理利用高炉炼铁过程中产生的大量离线历史数据问题,提供了一种新的思路,解决了离线测量数据利用率不足的问题。此外,本发明所提供的方法能够有效查询高炉炼铁产生的大量数据信息,不断根据最新的高炉炼铁工况数据更新预测模型参数,有效抑制了数据异常对控制器的不良干扰,提高了控制器的鲁棒性、自适应能力和稳定性。本发明给高炉现场操作人员提供了良好的控制参考依据,更有利于实现高炉炼铁过程的稳定顺行和优质高产。
附图说明
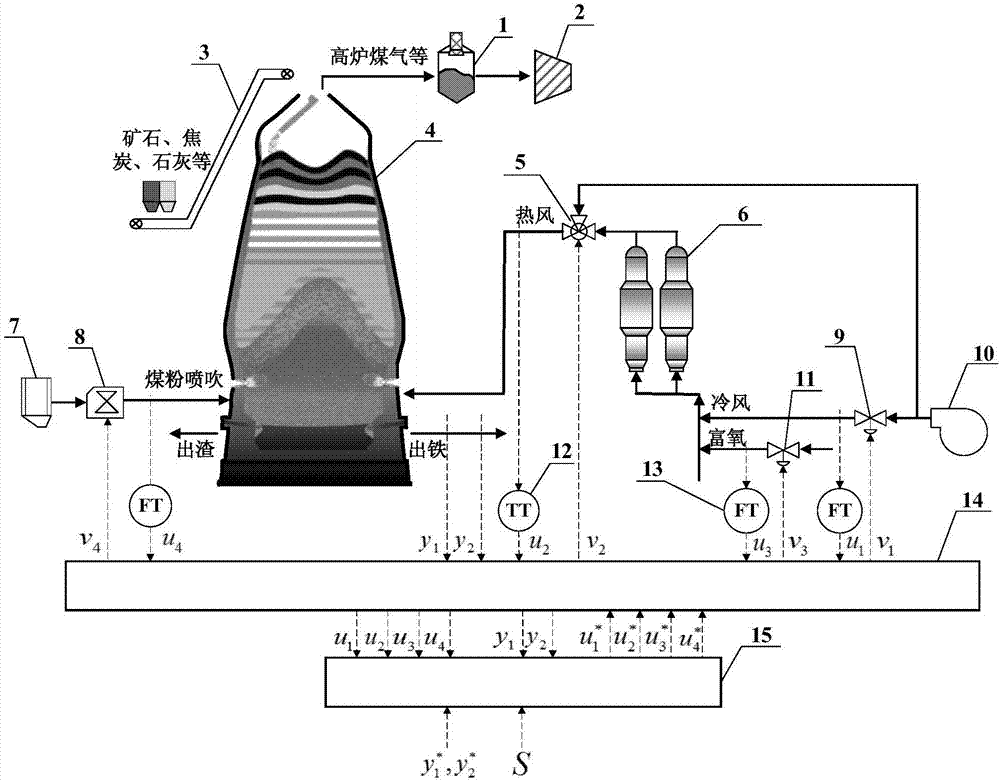
图1为本发明具体实施方式中高炉炼铁过程铁水质量控制系统结构图;
图2是本发明具体实施方式中基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法流程图;
图3是本发明具体实施方式中不同时刻下更改不同设定值的预测控制效果图,其中,(a)是铁水si含量和铁水温度的控制效果图,(b)是冷风流量、热风温度、富氧流量、喷煤量的变化曲线;
图4是本发明具体实施方式中不同时刻对不同输入加入干扰时的预测控制效果图,其中,(a)是铁水si含量和铁水温度的控制效果图,(b)是冷风流量、热风温度、富氧流量、喷煤量的变化曲线;
图5是本发明具体实施方式中不同时刻对不同输出加入干扰时的预测控制效果图,其中,(a)是铁水si含量和铁水温度的控制效果图,(b)是冷风流量、热风温度、富氧流量、喷煤量的变化曲线;
图6是本发明具体实施方式中不同时刻对不同输出加入异常数据时的预测控制效果图,其中,(a)是未采用鲁棒机制时铁水si含量和铁水温度的控制效果图,(b)是未采用鲁棒机制时冷风流量、热风温度、富氧流量、喷煤量的变化曲线,(c)是采用鲁棒机制时铁水si含量和铁水温度的控制效果图,(d)是采用鲁棒机制时冷风流量、热风温度、富氧流量、喷煤量的变化曲线。
图中:1-重力除尘装置,2-trt,3-物料传送带,4-高炉本体,5-热风混合电动阀,6-热风炉,7-煤粉仓,8-喷煤量调节阀,9-冷风流量阀,10-送风机,11-富氧流量阀,12-温度计,13-流量计,14-plc系统,15-上位机。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
以柳钢的一个容积为2600m3的炼铁高炉对象为例,应用本发明提供的一种基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法。现在的炼铁高炉对象安装了如下的常规测量系统,包括:用于测量冷风流量的差压流量计、用于测量富氧流量的平衡流量计、用于测量热风温度的红外温度计、用于测量煤粉喷吹量的煤粉流量计;以及如下执行机构:用于调节冷风流量和富氧流量的流量调节阀、用于调节热风温度的混合电动调节阀、用于调节喷煤量的调节阀:如图1所示,1-重力除尘装置,2-trt,3-物料传送带,4-高炉本体,5-热风混合电动阀,6-热风炉,7-煤粉仓,8-喷煤量调节阀,9-冷风流量阀,10-送风机,11-富氧流量阀,12-温度计,13-流量计,14-plc系统,15-上位机;流量计、温度计等常规测量仪表和执行机构安装于高炉的各个位置,底层plc系统连接常规测量仪表和执行机构,并通过通讯总线连接上位机系统。图1的符号含义如下:
本发明方法可以采用c#高级语言实现软件系统的编写。该软件系统可实现数据显示、软测量结果显示以及设定被控量期望输出值等功能,可以方便地让操作人员对高炉炼铁系统进行实时优化控制。另外,计算机系统上装有opc通讯软件负责与下位机以及数据采集装置进行数据双向通讯。
本发明利用实际的柳钢2号高炉,现有常规测量设备采集的高炉炼铁过程数据作为优化控制需要的数据,将采集后的数据经过预处理之后,利用本发明所提供的方法对铁水质量进行优化控制,为高炉生产过程的优化操作和稳定顺行运行提供参考,使炼铁厂获得最大的效益。
本实施例中基于懒惰学习的高炉铁水质量自适应鲁棒预测控制方法,如图2所示,包括:确定铁水si含量和铁水温度为被控量;选取冷风流量、热风温度、富氧流量和喷煤量为控制量;采集高炉生产历史输入输出测量数据构造初始数据库,并且在线实时更新数据库;根据当前工作时刻,采集上一时刻的控制向量和上一时刻的被控向量构造查询回归向量,确定异常数据;通过懒惰学习方法从数据库中查询相似学习子集,采用留一法交叉验证选出最优相似学习子集,根据最优相似学习子集中的样本数据信息对异常数据进行处理,并将最优相似学习子集作为训练集采用多输出最小二乘支持向量回归建模方法,建立局部预测模型;由铁水质量指标期望值计算铁水质量指标参考轨迹,并基于铁水质量指标参考轨迹和其校正后的输出预测值构造预测控制性能指标,利用序贯二次规划优化算法计算得到最优控制向量;将最优控制向量即最优的冷风流量、热风温度、富氧流量和喷煤量发给底层plc系统并调节执行机构。具体方法如下所述。
步骤1、选取铁水si含量和铁水温度作为被控量,选取高炉本体参数中与被控量相关性最强且可操作的变量作为控制量,控制量包括冷风流量、热风温度、富氧流量、喷煤量,根据选择的控制量和被控量采集高炉生产历史输入输出数据,对数据进行预处理,并构造初始数据库,初始化相关参数;
步骤1.1、选取高炉众多本体参数中,与被控量铁水si含量和铁水温度相关性最强且可操作的变量作为控制量:冷风流量u1(单位是m3/min)、热风温度u2(单位是℃)、富氧流量u3(单位是m3/min)和喷煤量u4(单位是t/h);被控量为:铁水si含量y1(单位是%)和y2铁水温度(单位是℃);
采集高炉生产历史输入输出测量数据,包括控制量和被控量,共600组,{(u(t),y(t))|u(t)∈rm,y(t)∈rn,t=1,2,…,n},t表示采样时刻,n=600,为采样时刻总数;u(t)=[u1(t),u2(t),u3(t),u4(t)]t为采样时刻t时的控制向量,y(t)=[y1(t),y2(t)]t为采样时刻t时的被控向量,m=4为控制向量的维数,n=2为被控向量的维数;
步骤1.2、对控制量和被变量进行滤波及归一化处理;
滤波处理:采用噪声尖峰滤波算法剔除高炉生产过程中的噪声尖峰跳变数据;
归一化处理:对滤波后的高炉生产历史数据,包括控制量和被控量,进行归一化处理;
步骤1.3、构造初始数据库,确定局部预测模型结构为y(t)=f(x(t)),f(·)为非线性映射,将上一时刻控制向量u(t-1)、当前时刻控制向量u(t)、上一时刻被控向量y(t-1)作为局部预测模型输入,即x(t)=[yt(t-1),ut(t),ut(t-1)]t为局部预测模型输入,当前时刻被控向量y(t)作为局部预测模型输出;根据映射对{x(t),y(t)}的形式构造初始数据库
步骤1.4:初始化相关参数包括:相似度比重因子σ;近邻数范围k∈[kminkmax],kmin为最小邻数,kmax为最大邻数;核半径δ;惩罚系数λ,c;预测步长np;控制步长nc;加权系数ry,ru;
在本实施例中,取kmin=3,kmax=20,δ=0.9,λ=0.2,c=0.5,np=6,nc=3,ry=1,ru=0.5。
步骤2、构造当前工作时刻的查询回归向量,通过懒惰学习方法从数据库中查询相似数据样本组成学习子集,采用留一法交叉验证选出最优相似学习子集,根据最优相似学习子集中的数据样本信息处理异常数据,并采用多输出最小二乘支持向量回归建模方法建立局部预测模型;
步骤2.1、根据当前工作时刻t,采集上一时刻的控制向量u(t-1)、上一时刻的被控向量y(t-1),构造查询回归向量xt=[yt(t-1),ut(t),ut(t-1)]t;由于u(t)是需要求解的当前时刻控制向量,所以在计算xt与数据库中xi间的相似度时不考虑该项,同时也不考虑xt中的异常数据项,将高于历史采集数据中最大值的2倍以上或者出现数据缺失的新采集数据视为异常数据;
步骤2.2、为了计算查询回归向量xt与数据库中数据向量xi的相似度大小,综合考虑xt与xi间的角度和距离,定义相似度如下:
s(xi,xt)=σ·exp(-dti)+(1-σ)·cos(αti),cos(αti)≥0(1)
其中,s(xi,xt)∈[01],若s(xi,xt)越接近1表示xi与xt越相似,0≤σ≤1是权重参数,用于调节距离相似性dti和角度相似性cos(αti)所占比重的大小,dti和cos(αti)分别定义如下:
dti=||xi-xt||2
其中,<xi,xt>为xi与xt间的内积运算,||·||2为向量2范数;
根据公式(1)定义的相似度,查询数据库中与xt最相似的k个xi,并组成相似学习子集{xi,yi},i=1,2,…,k,由于k∈[kminkmax],所以有(kmax-kmin+1)个相似学习子集;
步骤2.3、为了选出最优相似学习子集,采用留一法交叉验证方法,分别计算(kmax-kmin+1)个相似学习子集对应的留一法交叉验证均方误差,选择对应均方误差最小的相似学习子集,作为最优相似学习子集;
多输出最小二乘支持向量回归建模:
其中,kl×l为训练样本核矩阵,l为训练样本数量,n为输出维数,0n×n为n×n维全0矩阵,ones(n)为n×n维全1矩阵,in×n为n×n维单位矩阵,1l×1=[1,1,…,1]t∈rl为全1向量,α=[α1;…;αl]∈rnl和bn×1∈rn为支持向量回归模型参数,ynl×1=[y1;…;yl]∈rnl为模型输出向量;
通过求解式(2)获取最优参数矩阵α和参数向量b,m输入n输出最小二乘支持向量回归预测模型如下:
其中,
k(x,xi)=exp(-||x-xi||2/2δ2)(4)
其中,δ为核半径;
如下计算每个学习子集对应的留一法交叉验证均方误差:
其中,mseloo(k)为对应近邻数为k的留一法交叉验证均方误差;
步骤2.4、鲁棒机制:为保证控制系统稳定工作,需要及时处理xt中的异常数据,根据最优相似学习子集中的数据向量xi,i=1,2,…,kbest,如下计算平均数据向量
将xi的异常数据项用
步骤2.5、将最优相似学习子集作为训练集,结合式(2)、(3)和(4)采用多输出最小二乘支持向量回归建模方法建立局部预测模型。
步骤3、计算多步输出预测值进行并对预测值进行在线校正,根据未来输出期望值与校正后预测值构造控制性能指标,利用序贯二次规划算法计算得到最优控制向量,即当前时刻的最优输入——冷风流量、热风温度、富氧流量、喷煤量;
步骤3.1、根据局部预测模型计算提前多步的预测输出;
在每个当前采样时刻t,m-ls-svr局部预测模型所建立的映射关系为:
yi=f(xi)(7)
通过求解式(2)可知,局部预测模型的np步预测输出分别为:
其中,
步骤3.2、根据被控向量设定值期望ysp建立参考轨迹方程,为了把当前的输出y(t)平滑的引导到设定值期望ysp,将参考轨迹方程采用如下所示的一阶平滑模型:
其中,η为柔化系数,0<η<1;
这样可以使yr(t)平滑过渡到ysp,若η较小,则系统跟随性好,快速性好,鲁棒性变差;η较大,则系统过渡过程平缓,鲁棒性好;
步骤3.3、为了防止模型失配或环境干扰对控制器的影响,反馈校正采用对未来的误差做出预测并加以补偿,即:
其中,y(t)为t时刻被控向量实际值,
步骤3.4、预测控制性能指标为高炉铁水质量指标参考轨迹和高炉铁水质量指标预测值的误差平方和并对其进行加权,同时在指标中加入对控制向量增量的惩罚项;采用序贯二次规划算法对高炉铁水质量指标预测控制中的优化问题进行优化求解,得到使性能指标函数值最小的控制向量增量,进而得到最优控制向量;
预测控制优化问题如下:
s.t.umin≤u(t+j-1)+δu(t+j)≤umax
其中,j为优化性能指标,np为预测步长,研为控制步长,yr(t+j)为t+j时刻被控向量参考值,
在具体实施中,此优化问题可以通过调用matlab工具箱中的fmincon()函数来求解,调用格式为:
[x,f]=fmincon(h,f,a,b,aeq,beq,lb,ub)
相应项的具体定义参见matlab中fmincon的参考页,通过调用上述fmincon()函数,可求得t时刻的最优控制向量增量δut,则t时刻的最优控制向量可计算为u(t)=u(t-1)+δu(t)。
步骤4、将最优控制向量即最优冷风流量
为了验证本实施例中高炉铁水质量优化控制方法的性能,分别进行了设定值跟踪实验、输入脉冲干扰抑制实验、输出脉冲干扰抑制实验和数据异常鲁棒性能测试实验。铁水质量指标的控制效果及控制量曲线如图3(a)~(b)、图4(a)~(b)、图5(a)~(b)和图6(a)~(d)所示,其中,图3(a)~(b)为设定值跟踪实验,铁水si含量的设定值分别在150时刻、300时刻由0.45更改为0.5、0.5更改为0.45,铁水温度的设定值分别在200时刻、350时刻由1500更改为1510、1510更改为1500;图4(a)~(b)为输入脉冲干扰抑制实验,分别在100、150、200和250时刻在控制量中加入脉冲干扰;图5(a)~(b)为输出脉冲干扰抑制实验,分别在100和150时刻在被控量中加输出脉冲干扰;图6(a)~(d)为数据异常鲁棒性能检测实验,分别在100、150、200和250时刻对被控量加入异常数据,数据异常指新采集数据高于历史采集数据样本中最大值的2倍以上或者出现数据缺失情况;其中图6(a)~(b)未采用鲁棒机制,图6(c)~(d)采用了鲁棒机制;由图可以看出本实施例中的高炉铁水质量指标优化控制方法具有良好的设定值跟踪性能、良好的输入输出干扰抑制能力以及针对数据异常情况具有良好的鲁棒控制性能。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!