一种面向GPU高效绘制的帧缓冲区存储编码方法与流程
本发明涉及计算机硬件技术领域,尤其涉及GPU的帧缓冲区存储编码方法。
背景技术:
3D图形绘制时GPU需要极大的存储带宽,主要是由于纹理数据、颜色数据及深度数据的访问,设计中往往采用纹理Cache、颜色Cache和深度Cache及对应的压缩算法来缓解DDR存储带宽压力。Cache的访问是按Block存取的,同时压缩算法是按Tile进行压缩和解压缩的,DDR中不同的帧缓冲区存储编码方式会极大地影响压缩算法的效率及Cache的命中率和Cache更新效率。
技术实现要素:
本发明的目的是:
本发明描述了一种面向GPU高效绘制的帧缓冲区存储编码方法,能够最大程度的利用图形绘制时帧缓冲区的空间局部性,降低颜色、深度及纹理Cache的缺失率,加快GPU的绘制,并减少DDR的带宽需求。
本发明的技术方案是:
一种面向GPU高效绘制的帧缓冲区存储编码方法,包括:
将编码存储对象按网格划分成若干个等大的Block单元,每个Block单元内按网格划分成若干个等大的Tile单元或者SuperTile单元;每个Tile单元或者SuperTile单元内包含相同数量的图像数据;
编码时,在每个Tile单元或者SuperTile单元内图像数据按照正常的编码顺序进行编码;
每个Block单元内的Tile单元或者SuperTile单元的编码顺序与光栅化方向一致,按照“之”字形编码,每个Block单元内从左下角第一个Tile单元或者SuperTile单元开始,按照从左到右,然后从下到上的顺序编码;
在每个编码存储对象中Block单元的编码顺序与光栅化方向一致,按照“之”字形编码,每个编码存储对象内从左下角第一个Block单元开始,按照从左到右,然后从下到上的顺序编码。
所述编码存储对象为纹理数据或者颜色数据或者深度数据。
所述图像数据为4行4列共16个纹素,或者4行16列共64个像素,或者8行8列共64个深度数据。
本发明的优点是:
所述纹理数据的编码存储方式可以保证纹理Cache每次访问的一个Block数据的空间局部性最优;所述颜色数据的编码存储方式可以颜色Cache保证每次访问的一个Block数据的空间局部性、数据压缩方式和像素缓冲区显示时的带宽和缓冲的最佳平衡;所述深度数据的编码存储方式可以保证深度Cache每次访问的一个Block数据的空间局部性、数据压缩方式的最佳平衡。
附图说明
图1是本发明中一种面向GPU高效绘制的纹理缓冲区存储编码方式示意图;
图2是本发明中一种面向GPU高效绘制的颜色缓冲区存储编码方式示意图;
图3是本发明中一种面向GPU高效绘制的深度缓冲区存储编码方式示意图。
具体实施方式
下面结合附图和具体实施例,对本发明的技术方案进行清楚、完整地表述。显然,所表述的实施例仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提所获得的所有其他实施例,都属于本发明的保护范围。
一种面向GPU高效绘制的帧缓冲区存储编码方法,包括:
将编码存储对象按网格划分成若干个等大的Block单元,每个Block单元内按网格划分成若干个等大的Tile单元或者SuperTile单元;每个Tile单元或者SuperTile单元内包含相同数量的图像数据;
编码时,在每个Tile单元或者SuperTile单元内图像数据按照正常的编码顺序进行编码;
每个Block单元内的Tile单元或者SuperTile单元的编码顺序与光栅化方向一致,按照“之”字形编码,每个Block单元内从左下角第一个Tile单元或者SuperTile单元开始,按照从左到右,然后从下到上的顺序编码;
在每个编码存储对象中Block单元的编码顺序与光栅化方向一致,按照“之”字形编码,每个编码存储对象内从左下角第一个Block单元开始,按照从左到右,然后从下到上的顺序编码。
所述编码存储对象为纹理数据或者颜色数据或者深度数据。
所述图像数据为4行4列共16个纹素,或者4行16列共64个像素,或者8行8列共64个深度数据。
实施例
如图1所示,一种面向GPU高效绘制的纹理缓冲区存储编码方式,纹理缓冲区的纹理贴图访问时根据贴图模式的不同,一个像素点可能需要空间上相邻的2个、4个、8个甚至更多的纹素点进行拟合,所以为纹理贴图提供纹素数据的纹理Cache的空间局部性就特别重要。设计上采用基于Tile的“之”字形编码存储方式,一个Cache的Block数据在二维空间上包含了16个Tile,16行16列共256个纹素数据,其空间局部性能够达到最优。
纹理Cache为只读Cache,当纹理贴图时从Cache中按照二维空间相邻的方式读取多个纹素数据,如果纹理Cache发生了缺失,则需要从DDR中一次获取一个Block的数据。采用基于Tile的“之”字形编码存储方式,一个二维空间相邻的Block数据在DDR中是连续存储的,可以通过一次突发传输完成DDR数据的获取,能够在保证纹素空间局部性最优的基础上降低DDR的访问带宽需求。
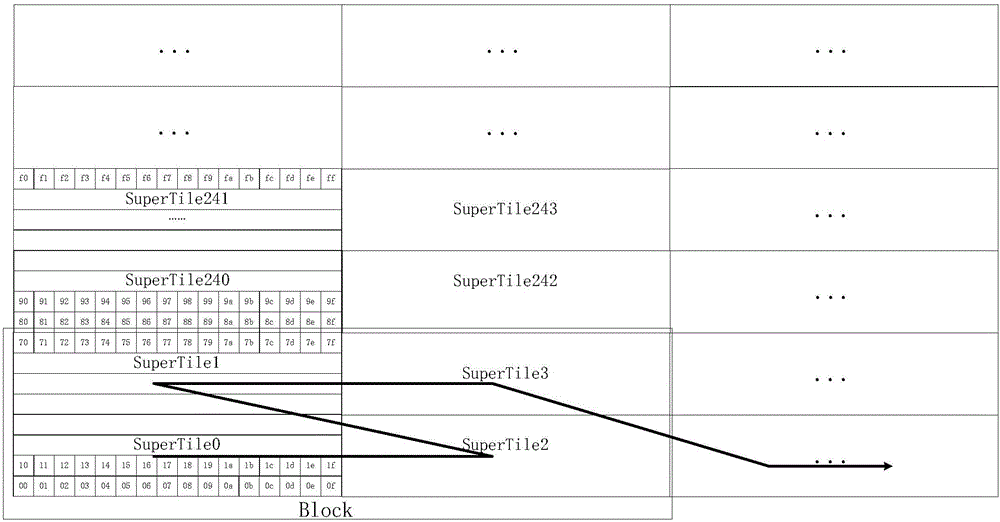
如图2所示,一种面向GPU高效绘制的颜色缓冲区存储编码方式,颜色缓冲区在GPU进行图形绘制时存储所绘制片段的最终结果,通过显示模块读取并显示到屏幕上。所以颜色缓冲区的编码格式不仅要考虑图形绘制时颜色Cache的访问特性,还要考虑显示模块读取时的显示特性,同时为了减少DDR的带宽需求,颜色缓冲区一般需要采用基于Tile或SuperTile的无损压缩算法。设计上采用基于SuperTile的“之”字形编码存储方式,一个SuperTile为一个压缩块,采用无损压缩算法进行压缩。为提高可压缩率,SuperTile的大小设定为4行16列的像素组成。由于最终颜色缓冲区的显示需要逐行进行显示,如果仍然采用二维空间局部性最优的编码方式则显示模块读取颜色缓冲区时就需要缓存至少16行数据,而实际上显示的逐行读取特性是不需要这么大容量的缓存的,为了在颜色Cache访问的二维空间局部性最优和显示读取缓冲容量两者之间取得最好的平衡,设计一个Cache的Block数据在二维空间上包含了4个SuperTile,共256个像素数据。
当颜色Cache进行缓冲区读写时,如果颜色Cache发生了缺失,则需要从DDR中一次获取一个Block的数据。采用基于Tile的“之”字形编码存储方式,一个二维空间相邻的Block数据在DDR中是连续存储,可以通过一次突发传输完成DDR数据的获取,能够在保证像素空间局部性最优的基础上降低DDR的访问带宽需求。而显示模块读取时不需要按Block读取,一次只需要读取一个4行16列的SuperTile的数据,节约了内部实现的缓存空间,数据的空间局部性、数据压缩方式和像素缓冲区显示时的带宽和缓冲的最佳平衡。
如图3所示,一种面向GPU高效绘制的深度缓冲区存储编码方式,深度缓冲区在GPU进行图形绘制时存储所绘制片段的深度值,并通过片断操作对后续片断的深度进行测试,以确定那些片断可以显示到屏幕上。为了减少DDR的带宽需求,深度缓冲区一般需要采用基于Tile或SuperTile的无损压缩算法。设计上采用基于SuperTile的“之”字形编码存储方式,一个SuperTile为一个压缩块,采用无损压缩算法进行压缩。为提高可压缩率,SuperTile的大小设定为8行8列的片断深度值组成,设计一个Cache的Block数据在二维空间上包含了4个SuperTile,共256个片断深度数据。
当深度Cache进行缓冲区读写时,如果深度Cache发生了缺失,则需要从DDR中一次获取一个Block的数据。采用基于Tile的“之”字形编码存储方式,一个二维空间相邻的Block数据在DDR中是连续存储,可以通过一次突发传输完成DDR数据的获取,能够在保证像素空间局部性最优的基础上降低DDR的访问带宽需求。
最后应说明的是,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述各实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!