一种自动产生时间序列上的交易策略的方法与流程
本发明涉及一种自动产生时间序列上的交易策略的方法,属于金融科技领域。
背景技术:
量化投资是指通过数量化方式及计算机程序化发出买卖指令,以获取稳定收益为目的的交易方式。量化投资从广义上来说,可以分为相对价值交易和在时间序列上的方向交易。传统上按照方法区分,时间序列上的方向交易又可以分为基于机器学习的交易策略和基于规则的交易策略。
在基于机器学习方法中,研究人员首先要确定因子组(机器学习领域称之为特征)及其对应的因子参数、一个预测目标因子(例如下一小时或下一天的价格变化或者夏普比率)及其对应的预测目标因子参数、一个机器学习模型及其对应的超参数。然后在因子组和预测目标因子之间建立机器学习模型。在建立模型之后,研究人员需要根据模型产生测试集上的预测值,并根据预测值产生交易信号,进而产生回测结果。如果回测目标达到预期,则该基于机器学习的交易策略确定,如果回测目标未达到预期,再修改因子组或其对应的因子参数、预测目标因子或其对应的预测目标参数、机器学习模型或其对应的机器学习模型超参数。
在基于规则的交易策略中,研究人员首先要确定因子组,但无需确定预测目标因子。随后研究人员会根据因子产生规则组,并根据规则组产生交易信号,进而产生回测结果。如果回测目标达到预期,则该基于规则的交易策略确定,如果回测目标未达到预期,再修改因子组或其对应的因子参数、规则组或其对应的规则参数。
若是研究基于规则的交易策略,研究人员需要大量尝试不同因子组及其对应的因子参数和规则组或其对应的规则参数的排列组合,若是研究基于机器学习的交易策略,研究人员需要大量尝试不同因子组或其对应的因子参数、预测目标因子或其对应的预测目标参数、机器学习模型或其对应的机器学习模型超参数的排列组合。并且在理论上,这样的排列组合有无穷多,回测目标达到预期的排列组合相对数量少。因此,研究基于机器学习的交易策略和基于规则的交易策略都需要大量的人力成本。
技术实现要素:
本发明针对现有技术存在的不足,提供一种能满足用户预期收益风险需求的、高效的自动产生时间序列上基于机器学习或基于规则的交易策略的方法。
为达到上述目的,本发明采用的技术方案提供一种自动产生时间序列上的交易策略的方法,该方法产生基于机器学习或基于规则的交易策略,包括以下步骤:
第一步:建立因子库;其中的每个因子为一个函数,各函数的自变量为给定或未给定,自变量为标量或向量,但至少应有一个向量,函数的输出值为向量且长度与自变量中的向量相同;若为算法相同而自变量的给定标量或向量不同的若干个函数,则合并成为一个函数;若为基于机器学习的交易策略,选定机器学习模型;
第二步:从因子库中随机抽取m个因子,依据给定的交易标的实例化因子;若为基于机器学习的交易策略,随机抽取1个预测目标因子,依据给定的交易标的实例化预测目标因子;
第三步:随机产生从m个实例化后的因子到交易信号的基于机器学习或基于规则的映射;若为基于机器学习的交易策略,通过固定起点的推进分析的预测值产生交易信号;若为基于规则的交易策略,通过规则组产生交易信号;
第四步:根据交易信号产生回测,得到一个交易策略;
第五步:重复第二步至第四步k次,将得到的k个交易策略作为候选种群;
第六步:设定若干回测目标,根据回测目标对种群进行迭代演化;
若为基于机器学习的交易策略,根据回测目标对种群进行迭代演化的方法为:
(1)依据选定的机器学习模型,对候选种群中每个交易策略的实例化后的预测目标因子和因子进行交叉、变异,创建一部分的下一代交易策略新种群;
(2)重复第二步至第四步,新建另一部分下一代交易策略新种群;
(3)对(1)和(2)产生的下一代交易策略新种群的总和进行回测,选取回测目标接近预期的交易策略个体组成下一候选种群;
(4)将(1)~(3)迭代r次结束;
若为基于规则的交易策略,根据回测目标对种群进行迭代演化的方法为:
(1)对候选种群中的每个交易策略的规则进行交叉、变异,创建一部分的下一代交易策略新种群;
(2)重复第二步至第四步,新建另一部分下一代交易策略新种群;
(3)对(1)和(2)产生的下一代交易策略新种群的总和进行回测,选取回测目标接近预期的交易策略个体组成下一候选种群;
(4)将(1)~(3)迭代r次结束;
第七步:判断第r次迭代的最优交易策略个体的回测目标是否达到预期;若达到预期,则为达到回测目标的时间序列上的交易策略,否则重复第二步到第六步。
本技术方案第二步所述的实例化因子的方法包括:
若函数的自变量为未给定的标量,则标量值根据标量的数据类型随机确定;
若函数的自变量为未给定的向量,则随机抽取一个时间序列作为该向量的值。
本技术方案第三步所述的随机产生基于机器学习的映射方法为:通过固定起点的推进分析的预测值产生交易信号;所述的固定起点的推进分析的方法为:
以t=0,1,2,3,4...t-1,t为时间序列,n为最小训练样本数;
在时刻a,a>=n:用t=0,1,2,...,a的样本作为训练集,建立在m个实例化后的因子和1个实例化后的预测目标因子之间建立机器学习模型,,产生t=a+1时刻的预测值;
遍历所有可能的a,收集t=n+1,n+2...t时刻的预测值。
本技术方案第三步所述的随机产生基于规则的映射方法为:用m个实例化后的因子随机建立多个规则,构成规则组;再按规则组产生交易信号。
由于上述技术方案运用,本发明与现有技术相比具有以下有益效果:
(1)能产生符合用户预期收益风险需求的交易策略。
(2)提高研究效率,减轻交易策略研发人员的工作负担。
(3)通过挖掘出因子组合的局部最优解,供研究人员借鉴。
(4)通过批量大规模产生交易策略,弥补单一交易策略的资金容量不足的问题。
(5)通过产生与原有交易策略相关性较低的交易策略,增加资金收益的稳定性。
附图说明
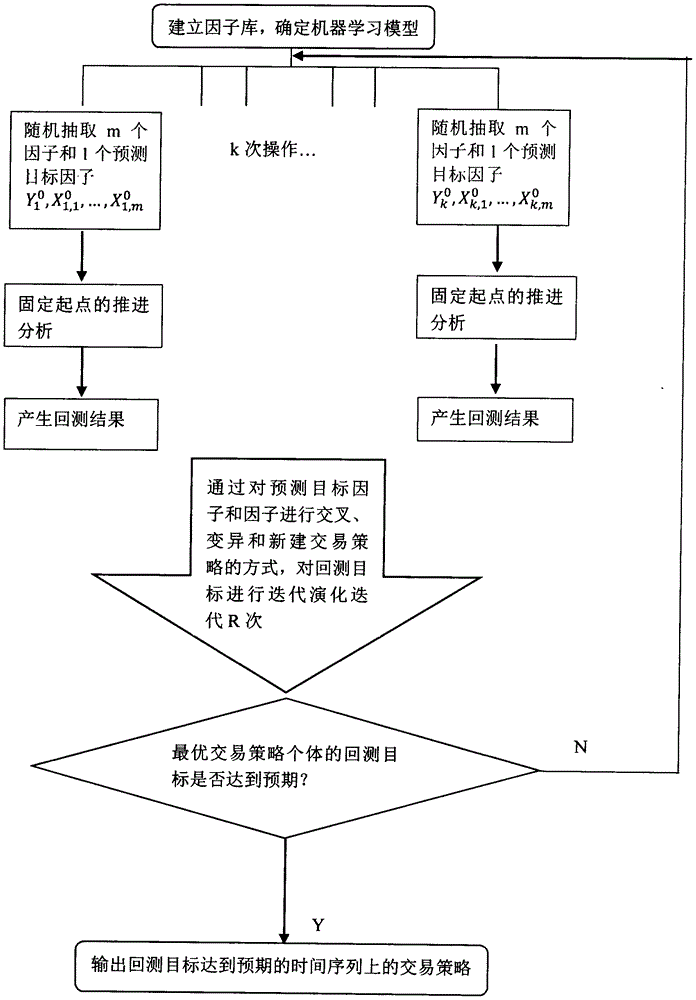
图1是本发明实施例提供的自动产生时间序列上基于机器学习的交易策略机制总示例流程。
图2是本发明实施例对预先设定的回测目标(年化收益、收益回撤比、夏普比率等)进行基于机器学习的交易策略演化迭代的示意图。其中,a图是对交易策略的实例化后的预测目标因子和因子进行交叉的示意图,b图是对交易策略的实例化后的预测目标因子和因子进行变异的示意图,c图是新建基于机器学习的交易策略的示意图,d图是对预先设定的回测目标(年化收益、收益回撤比、夏普比率等)进行基于机器学习的交易策略演化迭代的示意图。
图3是本发明实施例提供的自动产生时间序列上基于规则的交易策略机制总示例流程。
图4是本发明实施例对预先设定的回测目标(年化收益、收益回撤比、夏普比率等)进行基于规则的演化迭代的示意图。其中,a图是对交易策略的规则进行交叉的示意图,b图是对交易策略的规则进行变异的示意图,c图是新建基于规则的交易策略的示意图,d图是对预先设定的回测目标(年化收益、收益回撤比、夏普比率等)进行基于规则的演化迭代的示意图。
具体实施方式
下面结合实施例和附图对本发明技术方案作进一步阐述。
实施例1
如图1,本实施例提供一种自动产生时间序列上基于机器学习的交易策略机制:
(1)建立因子库,确定使用神经网络模型。
(2)给定标的为上证综指一小时线,首先从因子库随机抽取5个因子x1,1,,x1,2,x1,3,x1,4,x1,5,分别是ma(real,timeperiod)、头肩底形态(open,high,low,close)、ma(real,timeperiod)、价格变化率(close)、atr(high,low,close,timeperiod)。因子实例化后为ma(close,timeperiod=5)、头肩底形态(open,high,low,close),ma(open,timeperiod=10)、价格变化率(close)、atr(high,low,close,timeperiod=8);随机抽取1个预测目标因子y1为sharperatio(close,timeperiod)。实例化后为sharperatio(close,timeperiod=4)。
ma因子:real是未给定的向量,可以随机取值open、high、low、close、volume、amount等。timeperiod是int类型未给定的标量,因此随机取一个int值。ma因子的输出值是向量且和real长度相同。
头肩底形态因子:open、high、low、close是给定的向量且长度相同,头肩底形态因子的输出值是向量且和open、high、low、close长度相同。
价格变化率因子:close是给定的向量。价格变化率因子的输出值是向量且和close长度相同。
atr因子:high、low、close是给定的向量且长度相同,timeperiod是int类型未给定的标量,因此随机取一个int值。atr因子的输出值是向量且和high、low、close长度相同。
sharperatio因子:close是给定的向量,timeperiod是int类型未给定的标量,因此随机取一个int值。sharperatio因子的输出值是向量且和close长度相同。
另外,如果有两个函数ma(close,timeperiod=5)和ma(open,timeperiod=10)同在因子库中,它们算法相同,自变量有不同的给定标量或向量的取值,则合并成为一个函数ma(real,timeperiod)。
(3)在预测目标因子sharperatio(close,timeperiod=4)和因子ma(close,timeperiod=5)、头肩底形态(open,high,low,close)、ma(open,timeperiod=10)、价格变化率(close)、atr(high,low,close,timeperiod=8)之间建立神经网络模型。神经网络模型的超参数是随机确定的。依照固定起点的推进分析的方式,取得t=2010-01-049:30:00到2018-01-0415:00:00的预测值。
固定起点的推进分析方法如下:
在时刻2010-01-049:30:00:用t=2007-01-049:30:00,2007-01-0410:30:00...2010-01-049:30:00的样本作为训练集建立神经网络模型,产生t=2010-01-0410:30:00时刻的预测值。
在时刻2010-01-0410:30:00:用t=2007-01-049:30:00,2007-01-0410:30:00...2010-01-0410:30:00的样本作为训练集建立神经网络模型,产生t=2010-01-0411:30:00时刻的预测值。
以此类推。
在时刻2018-01-0414:00:00:用t=2007-01-049:30:00,2007-01-0410:30:00...2018-01-0414:00:00的样本作为训练集建立神经网络模型,产生t=2018-01-0415:00:00时刻的预测值。
收集t=2010-01-0410:30:00,2010-01-0411:30:00...2018-01-0415:00:00时刻的预测值。
(4)若预测值大于0.3%,则发出买入信号,若预测值小于-0.3%,则发出卖出信号,否则没有交易信号,并产生回测结果。
(5)将步骤(2)~(4)重复50遍,获得50个神经网络回归的交易策略,
(6)设定若干回测目标,如图2中d图所示,根据回测目标对种群进行迭代演化;
(6.1)如图2中a图、b图所示,基于神经网络模型,对候选种群中的每个交易策略实例化后的预测目标因子和因子进行交叉、变异,创建100个的下一代交易策略。
如图2中a图所示,交叉是指把某两个交易策略实例化后的因子组中的一个或者多个因子互相交换位置的过程。如用
如图2中b图所示,变异是指改变某交易策略实例化后的因子组中的一个或者多个因子的过程。如用
(6.2)如图2中c图所示,使用(2)~(4)的新建交易策略的方式,新建50个下一代交易策略。
(6.1)(6.2)产生的下一代交易策略的总和即为下一代共150个交易策略的种群。
注意
(6.3)对(6.1)(6.2)产生的150个下一代交易策略种群进行回测,选取回测目标靠近预期的50个交易策略个体组成下一候选种群。
(6.4)将(6.1)~(6.3)迭代5次结束。
(7)如果基于机器学习的冠军交易策略回测目标的sharperatio大于2,则为最后接受的基于机器学习的自动产生的交易策略。否则重新开始步骤(2)~(6)。
实施例2
如图3,本实施例提供一种自动产生时间序列上基于规则的交易策略机制:
(1)建立因子库。
(2)给定标的上证综指一小时线,首先从因子库随机抽取5个因子x1,1,,x1,2,x1,3,x1,4,x1,5,分别是ma(real,timeperiod)、头肩底形态(open,high,low,close)、ma(real,timeperiod)、价格变化率(close)、atr(high,low,close,timeperiod)。因子实例化后为ma(close,timeperiod=5)、头肩底形态(open,high,low,close)、ma(open,timeperiod=10)、价格变化率(close)、atr(high,low,close,timeperiod=8)。
ma因子:real是未给定的向量,可以随机取值open、high、low、close、volume、amount等。timeperiod是int类型未给定的标量,因此随机取一个int值。ma因子的输出值是向量且和real长度相同。
头肩底形态因子:open、high、low、close是给定的向量且长度相同,头肩底形态因子的输出值是向量且和open、high、low、close长度相同。
价格变化率因子:close是给定的向量。价格变化率因子的输出值是向量且和close长度相同。
atr因子:high、low、close是给定的向量且长度相同,timeperiod是int类型未给定的标量,因此随机取一个int值。atr因子的输出值是向量且和high、low、close长度相同。
另外,如果有两个函数ma(close,timeperiod=5)和ma(open,timeperiod=10)同在因子库中,它们算法相同,自变量有不同的给定标量或向量的取值,则合并成为一个函数ma(real,timeperiod)。
(3)用上述5个实例化后的因子随机建立多个规则,一个随机产生的实例化的规则组可以是:
(4)根据(3)的规则产生多空交易信号,并产生回测结果。
(5)将(2)~(4)重复50遍,获得50个基于规则的交易策略,
(6)设定若干回测目标,如图4中d图所示,根据回测目标对种群进行迭代演化;
(6.1)参照图4中的a图、b图,对候选种群中的每个交易策略的规则组进行交叉、变异,创建100个的下一代交易策略。
如图4中a图所示,交叉是指把某两个交易策略规则组中的一个或者多个规则互相交换位置的过程。如用
如图4中b图所示,变异是指改变某交易策略规则组中的一个或者多个规则的过程。如用
(6.2)如图4中c图所示,使用(2)~(4)新建交易策略的方式,新建50个下一代交易策略。
(6.1)(6.2)产生的下一代交易策略的总和即为下一代共150个交易策略的种群。
注意
(6.3)对(6.1)(6.2)产生的150个下一代交易策略种群进行回测,选取回测目标靠近预期的50个交易策略个体组成下一候选种群。
(6.4)将(6.1)~(6.3)迭代5次结束。
(7)如果基于规则的冠军交易策略回测中的sharperatio大于2,则为最后接受的基于规则的自动产生的交易策略。否则重新开始步骤(2)~(6)。
- 还没有人留言评论。精彩留言会获得点赞!