基于面部识别和行为识别融合的疲劳驾驶监测方法和系统与流程
本发明涉及疲劳驾驶检测技术领域,具体地涉及一种基于面部识别和行为识别融合的疲劳驾驶监测方法和系统。
背景技术:
驾驶人疲劳状态的检测目前有较多研究的方法,按检测的类别可大致分为基于驾驶人生理信号的检测、基于驾驶人操作行为的检测、基于车辆状态信息的检测和基于驾驶人生理反应特征的检测等方法。
基于生理信号(脑电信号、心电信号等)判别疲劳驾驶的准确性较高,且对所有健康的驾驶员来说,生理信号差异性不大,具有共性,但传统的生理信号采集方式需要采用接触式测量,给驾驶人疲劳检测的实际应用带来很多不便和局限性。
驾驶人的操作行为除了与疲劳状态有关外,还受到个人习惯、行驶速度、道路环境、操作技能的影响,因此需要考虑的干扰因素较多,影响基于驾驶人操作行为(如方向盘操作等)判别疲劳驾驶的精确度。
利用车辆行驶轨迹变化和车道线偏离等车辆行驶状态信息也可推测驾驶人的疲劳状态,但是车辆的行驶状态也与车辆特性、道路等很多环境因素有关,和驾驶人的驾驶经验以及驾驶习惯相关性较大,因此基于车辆状态信息判别疲劳驾驶需要考虑的干扰因素也较多。
基于驾驶人生理反应特征的疲劳驾驶判别方法是指利用驾驶人的眼睛特性、嘴部运动特征等推断驾驶人的疲劳状态,这些信息被认为是反映疲劳的重要特征,眨眼幅度、眨眼频率、平均闭合时间和打哈欠的动作等都可直接用于检测疲劳,但由于不同的驾驶员的习惯和特征存在一定的差异,使通过单个面部表情特征来判断驾驶员状态的鲁棒性不够高。
但是,由于驾驶员的个体差异,单一检测指标的检测手段存在局限性,主要表现为准确性较低、容易出现偏差,等等。
因此,如何将多传感器信息融合技术引入到驾驶疲劳检测技术中来,以提高驾驶员疲劳检测的准确性和实时性,成为亟待解决的问题。
技术实现要素:
为了解决上述技术问题,本发明提出了一种基于面部识别和行为识别融合的疲劳驾驶监测系统和方法,将面部识别结果和行为识别结果进行动态融合,可以准确判定疲劳驾驶状态,精度更高。
本发明所采用的技术方案是:
一种基于面部识别和行为识别融合的疲劳驾驶监测方法,包括以下步骤:
s01:采用第一深度卷积神经网络对采集的行为图像检测人体位置;
s02:采用第二深度卷积神经网络对检测到的人体位置进行骨架检测,得到人体各部位在图像中所处的位置及对应的置信度,并且同时预测各部位间的关联向量场,通过关联向量场表示各部位间的连接关系,根据得到的各部位的位置和部位间的关联向量场得到人体骨架模型;
s03:将预定义疲劳驾驶状态的骨架模型与获得的骨架模型进行比对,得到行为状态识别结果p1(x);
s04:对采集的驾驶员面部图像进行处理,得到驾驶员的面部表情状态特征,根据面部表情状态特征判断是否疲劳驾驶,得到面部状态识别结果p2(x);
s05:将面部状态识别结果p2(x)以及行为状态识别结果p1(x)进行融合得到最终检测结果p(x),即:p(x)=w1·p1(x)+w2·p2(x);
其中,w1,w2为特征融合的权重。
优选的技术方案中,所述步骤s05还包括,划分疲劳等级,所述疲劳等级包括i阶段,轻度疲劳;ii阶段,中度疲劳;iii阶段,重度疲劳;当判定为疲劳驾驶后,对不同等级的疲劳采用不同报警模式进行报警。
优选的技术方案中,在识别过程中,w1,w2根据p1及p2的值进行动态调整,对应关系公式为:w1=p1*p1,w2=p2*p2。
优选的技术方案中,所述步骤s01中人体位置检测步骤包括:
1)在图像中确定多个候选框;
2)根据第一深度卷积神经网络得到多维特征向量图;
3)对图像的每一个位置得到多个可能的候选框;
4)对候选框中提取的多维特征,使用分类器判别是否属于一个特定类;
5)对于属于某一类的候选框,用回归器调整其位置,得到损失函数最小的目标位置,即为目标框rect(x,y,width,height),其中,x,y为中心点坐标,width为宽度,height为高度。
优选的技术方案中,所述步骤s04具体的步骤包括:
s41:采用渐进式校准网络对采集的驾驶员面部图像进行处理,校准人脸,所述渐进式校准网络包括三层网络,第1层网络用于计算人脸偏转角,校准人脸;第2层网络用于进一步计算人脸偏转角,进一步校准人脸;第3层网络用于计算人脸偏转角,校准人脸,并输出人脸分类、偏转角度、边界回归;
s42:定位面部特征,所述面部特征包括嘴部、眼部、头部,将眼部图像分离出来,输入到第三深度卷积神经网络中,分类得到眼部的状态,判断是否为闭眼状态;对嘴部区域图像分离出来,输入到第四深度网络中,分类得到嘴部的状态,判断是否为打哈欠等状态;通过统计头部区域轨迹,分析得到头部运动状态,判断头部是否处于相对静止状态;
s43:在一段时间内对嘴部、眼部、头部状态特征进行统计,判断眼部是否产生闭眼状态,嘴部是否出现打哈欠状态以及头部是否为相对静止状态进行累计判断,得到面部状态识别结果p2(x)。
本发明还公开了一种基于面部识别和行为识别融合的疲劳驾驶监测系统,包括:
人体位置检测模块,采用第一深度卷积神经网络对采集的行为图像检测人体位置;
人体骨架检测模块,采用第二深度卷积神经网络对检测到的人体位置进行骨架检测,得到人体各部位在图像中所处的位置及对应的置信度,并且同时预测各部位间的关联向量场,通过关联向量场表示各部位间的连接关系,根据得到的各部位的位置和部位间的关联向量场得到人体骨架模型;
行为状态识别模块,将预定义疲劳驾驶状态的骨架模型与获得的骨架模型进行比对,得到行为状态识别结果p1(x);
面部图像处理和识别模块:对采集的驾驶员面部图像进行处理,得到驾驶员的面部表情状态特征,根据面部表情状态特征判断是否疲劳驾驶,得到面部状态识别结果p2(x);
融合模块:将面部状态识别结果p2(x)以及行为状态识别结果p1(x)进行融合得到最终检测结果p(x),即:p(x)=w1·p1(x)+w2·p2(x);
其中,w1,w2为特征融合的权重。
优选的技术方案中,还包括判断报警模块,用于划分疲劳等级,所述疲劳等级包括i阶段,轻度疲劳;ii阶段,中度疲劳;iii阶段,重度疲劳;当判定为疲劳驾驶后,对不同等级的疲劳采用不同报警模式进行报警。
优选的技术方案中,所述融合模块,在识别过程中,w1,w2根据p1及p2的值进行动态调整,对应关系公式为:w1=p1*p1,w2=p2*p2。
优选的技术方案中,所述人体位置检测模块中人体位置检测步骤包括:
1)在图像中确定多个候选框;
2)根据第一深度卷积神经网络得到多维特征向量图;
3)对图像的每一个位置得到多个可能的候选框;
4)对候选框中提取的多维特征,使用分类器判别是否属于一个特定类;
5)对于属于某一类的候选框,用回归器调整其位置,得到损失函数最小的目标位置,即为目标框rect(x,y,width,height),其中,x,y为中心点坐标,width为宽度,height为高度。
优选的技术方案中,所述面部图像处理和识别模块具体处理步骤包括:
s41:采用渐进式校准网络对采集的驾驶员面部图像进行处理,校准人脸,所述渐进式校准网络包括三层网络,第1层网络用于计算人脸偏转角,校准人脸;第2层网络用于进一步计算人脸偏转角,进一步校准人脸;第3层网络用于计算人脸偏转角,校准人脸,并输出人脸分类、偏转角度、边界回归;
s42:定位面部特征,所述面部特征包括嘴部、眼部、头部,将眼部图像分离出来,输入到第三深度卷积神经网络中,分类得到眼部的状态,判断是否为闭眼状态;对嘴部区域图像分离出来,输入到第四深度网络中,分类得到嘴部的状态,判断是否为打哈欠等状态;通过统计头部区域轨迹,分析得到头部运动状态,判断头部是否处于相对静止状态;
s43:在一段时间内对嘴部、眼部、头部状态特征进行统计,判断眼部是否产生闭眼状态,嘴部是否出现打哈欠状态以及头部是否为相对静止状态进行累计判断,得到面部状态识别结果p2(x)。
与现有技术相比,本发明的有益效果是:
1、本发明将面部识别结果和行为识别结果进行动态融合,可以准确判定疲劳驾驶状态,并实时进行分级预警提醒,精度更高。
2、本发明使用人体骨架模型状态表征人体所处的姿态,可以更加准确地分析预测驾驶员行为状态,对驾驶员的行为进行监控。
附图说明
下面结合附图及实施例对本发明作进一步描述:
图1为基于面部识别和行为识别融合的疲劳驾驶监测方法的流程图;
图2为本发明人体目标检测效果示意图;
图3为本发明人体骨架模型检测效果示意图;
图4为本发明旋转人脸检测示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
实施例
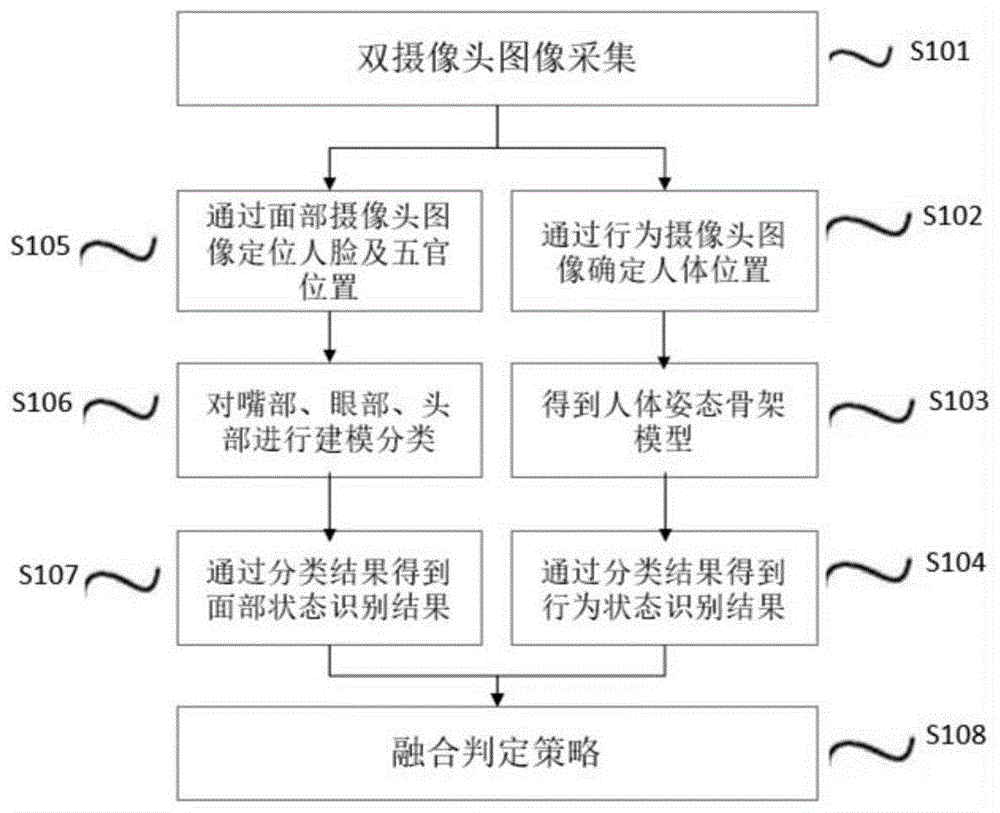
如图1所示,本发明的基于面部识别和行为识别融合的疲劳驾驶监测方法,包括如下步骤:
本发明采用双摄像头采集装置采集图像s101,主要包括面部摄像头1,对准驾驶员面部进行图像采集,输入到面部分析模块。通过摄像头抓取人脸,输入到算法模块进行识别和处理。摄像头1采用mipi数字摄像头,图像分辨率为1920*1080。支持自动曝光,自动对焦和自动白平衡。图像每秒输出不低于30帧。
行为摄像头2,从驾驶员前方45°左右向下,对准驾驶员的身体部分,采集驾驶员的行为图像,输入到行为分析模块。摄像头2采用ahd模拟摄像头,图像分辨率为1280*720。支持自动曝光,自动对焦和自动白平衡。图像每秒输出不低于30帧。
人体定位检测模块,通过行为摄像头采集的行为图像确定人体位置s102。基于深度学习技术,设计一种轻量级的卷积神经网络,使用端对端的单阶段训练方法。通过将不同卷积层的特征图分别进行检测,最后使用非极大值抑制方法将结果综合起来检测人体,相比传统算法使用图像金字塔检测的方法,大大提高了算法的实时性。如图2所示,定位到人体,返回目标位置rect(x,y,width,height)。基于深度学习的端到端的人体检测方法:
1)在图像中确定约1000-2000个候选框(使用选择性搜索)。
2)对整张图片输进卷积神经网络,得到人体梯度、边缘等相关的128维特征向量图。
3)在尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口。
4)对候选框中提取出的128维特征,使用分类器判别是否属于一个特定类。
5)对于属于某一特征候选框,用回归器调整其位置,得到损失函数最小的目标位置rect(x,y,width,height),x,y,中心点x,y坐标,width对象高度,height对象宽度。
获取人体骨架s103。通过对人体框进行骨架检测,得到人体骨架状态,表征人体当前进行的动作和行为,因此只要能够检测出人体骨架的状态就能够推理出人体当前的行为动作,通过人体骨架检测模型也可以对司机的驾驶行为进行监控。
人体骨架模型利用深度卷积神经网络对输入图像进行处理,输出人体各部位在图片中所处的位置及对应的置信度,并且同时预测各部位间的关联向量场来表示各部位间的连接关系,最终利用贪心算法对输出的位置和部位间的关联向量场进行推理得到人体骨架模型。
通过分类结果得到行为状态识别结果s104,如图3所示,通过提前训练定义驾驶员疲劳状态时的骨架模型,与获取得到的骨架模型进行比对,通过支持向量机算法计算向量之间的距离,得出相似度。即为行为识别状态结果p1。
通过面部摄像头采集的图像定位人脸及五官位置s105,通过采集的面部图像定位人脸及五官位置可以采用申请为201310731567.1的专利文献中记载的方法处理得到表情特征判断疲劳驾驶。但是本申请提出了一种新的方案。
本方案提出渐进式校准网络检测器。给定图像,根据滑动窗口和图像金字塔原理获得所有候选面,并且每个候选窗口逐步通过检测器。在渐进式校准网络的每个阶段中,检测器同时拒绝具有脸部置信度低的大多数候选者,对剩余脸部候选者的进行边界回归,并校准脸部候选者的平面旋转方向。在每个阶段之后,非最大抑制(nms)用于合并那些高度重叠的候选者。
第1层网络:先初略判断一个偏转角,校准人脸,减少人脸偏转角度范围。
第2层网络:同样操作,进一步校准,以减少人脸偏转角度范围。
第3层网络:精准计算偏转角度,基于前两步骤校准后,再使用第三层网络直接输出人脸分类、偏转角度、边界回归。渐进式地校准人脸角度,逐步降低人脸的偏转角度,本方法可以处理任意角度旋转的人脸,结果如图4。
对嘴部、眼部、头部进行建模分类s106,定位到嘴部、眼部、头部等部位之后,将眼部图像分离出来,输入到cnn网络中,分类得到眼部的状态,是否为闭眼状态。对嘴部区域图像分离出来,输入到cnn网络中,分类得到嘴部的状态,是否为打哈欠等状态。通过统计头部区域轨迹,分析得到头部运动状态,驾驶员头部是否处于相对静止状态。
通过分类结果得到面部状态识别结果s107,通过一段时间内对嘴部、眼部状态特征进行统计,即通过眼部是否产生闭眼状态、嘴部是否出现打哈欠状态以及头部是否为相对静止状态进行累计判断,得到面部状态识别结果p2。
融合判定策略s108,对面部识别状态以及行为识别状态进行融合得到最终检测结果,即:
p(x)=w1·p1(x)+w2·p2(x)
其中,w1,w2为特征融合的权重;初始权重w1=0.5,w2=0.5,在识别过程中,w1,w2根据p1及p2的值动态调整,对应关系公式为:w1=p1*p1,w2=p2*p2。
当判定为疲劳驾驶后,划分疲劳等级,对不同等级的疲劳采用不同形式的报警模式。疲劳等级分为i阶段,轻度疲劳;ii阶段,中度疲劳;iii阶段,重度疲劳。表现行为如下表所示。i阶段报警提示音比较平缓,ii阶段为较急促且音量较大,iii阶段为非常急促且音量大的提示音,并伴随可以增加振动座椅等。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!