一种基于机器学习的污水处理的水质预测方法及系统与流程
本发明涉及机器学习领域,特别涉及一种基于机器学习的污水处理的水质预测方法及系统。
背景技术:
水环境治理一直是民生关心的一大问题,其中污水处理更是第一要务。现阶段,随着我国社会水平逐步提高、工业化发展程度的加深,社会用水需求量大,工业污水排放量增加,使我国水资源环境遭到一定程度的破坏,水资源短缺、水生态损害、水环境污染等问题越来越突出,水安全保障面临严峻的挑战。在政府水务治理规划中,黑臭水体整治更是目前城镇水务工作的重中之重。因此,为了促进我国生态文明的建设,减少水资源浪费,需要做好污水处理工作,加强水资源的循环应用,达到我国可持续发展的规划。
近年来,随着水务治理工作的推进,污水处理的情况得到较大改善。但污水处理过程是一个变量繁多、具有时滞特点的动态非线性反应过程。如果我们能从以往的污水水质数检测标准数据预测出以后实时阶段的水质数据,对即将突发的水质问题进行预警、及时处理。对于水务工厂的长期安稳运行具有重要的意义
在现有的污水处理领域中,针对于污水厂水质预测现阶段大部分是人工的方式去设计或提取水质数据的特征来实现数据的处理,这种方法的缺点在于需要耗费大量的劳动力且得出的特征往往局限于特定的任务,并且最主要的问题在于由于污水水质是实时变化的当污水水质出现问题后不能保证实时的解决。因此现有技术往往直接采用传统的信息检索中的一些方法来提取水质数据中的特征而这些传统方法并不能很好捕捉到我们所需要的信息,并且不能及时的对出现的问题进行补救。
技术实现要素:
为了更加有效地对污水处理进行预测,本发明提出一种基于机器学习的污水处理的水质预测方法及系统,所述方法具体包括以下步骤:
s1、确定污水的测量参数和污水处理的行业标准,并初始化污水的测量参数,并将测量参数的特征权重向量初始化为1为v0(i)=1;
s2、通过线性支持向量机获取污水测量参数的适应度,将适应度最大的个体作为最优的个体,令i=1;
s3、在第i次迭代中,将最优的个体复制n-1个,并在每个复制的个体上的特征权重上随机加上一个[0,max_variation]的值;
s4、通过线性支持向量机获取当前个体的适应度,选择适应度最大的个体作为最优的个体;
s5、判断是否达到最大迭代次数,若没达到则令i=i+1,返回步骤s3;否则输出最优的特征权重向量;
s6、将得到最优特征向量输入线性支持向量机,完成训练;将实时污水测量参数输入完成训练的线性支持向量机即可得到预测结果;
其中,n为预定的种群数量;max_variation为预设的单代最大变异度;vj(i)为第j个污水的测量参数的特征向量,1≤i≤m,m为该测量参数的特征向量的维数。
进一步的,所述适应度为个体的f1分数,f1分数为支持向量机在验证集上的性能参数。
所述污水的测量参数至少包括codcr出水、ph值、溶解氧do、氨氮nh3-n。
本发明还提出一种基于机器学习的污水处理的水质预测系统,包括数据输入模块、基于线性支持向量机的预测模块和水务平台污水检测子系统;所述数据输入模块包括历史数据存储器、实时数据缓存器以及期望数据存储器;其中:
历史数据存储器用于存储污水处理厂最近几天实时检测到的水务数据;
期望数据存储器用于存储污水处理的行业标准的数据;
实时数据缓存器用于缓存实时监测到的水务数据;
基于线性支持向量机的预测模块用于根据历史数据存储器和期望数据存储器的数据对实时数据缓存器中的数据进行预测;
水务平台污水检测子系统用于获取水务信息。
进一步的,所述水务平台污水监测子系统包括数据采集单元和数据存储打印单元,所述数据采集单元包括codcr出水检测装置、ph值检测装置、溶解氧do检测装置、氨氮nh3-n检测装置;数据采集单元将各个检测装置检测的污水的测量参数通过数据存储打印单元存储打印。
进一步的,污水处理厂的每种污水处理设备的出水口至少设置有一个数据采集单元。
进一步的,基于线性支持向量机的预测模块包括线性支持向量机,将历史数据存储器中的数据和期望数据存储器的数据输入线性支持向量机进行训练获得特征权值,线性支持向量机训练获得最优特征权值的过程中,调用线性支持向量机在验证集上的性能f1分数作为筛选特征权值的指标;将实时数据缓存器中的数据作为线性支持向量机的输入,线性支持向量机输出对污水处理的预测结果。
本发明提出的一种基于机器学习的污水处理水质预测方法是基于遗传算法与支持向量机的水质做出预测模型对于整个原始数据进行初始化,利用遗传算法筛选出最佳特征权重来对原始数据进行加权放缩,训练模型对污水处理水质完成预测;对于整个原始数据(原始数据参数)进行初始化,并将其权重都设置相同进行标准化;其次利用遗传算法筛选出最佳特征权重vk来对原始数据进行加权放缩;最后利用加权后的数据对支持向量机模型进行训练得到最终的污水水质预测模型,达到实时预测污水质量,人为进行辅助调控的目的。
附图说明
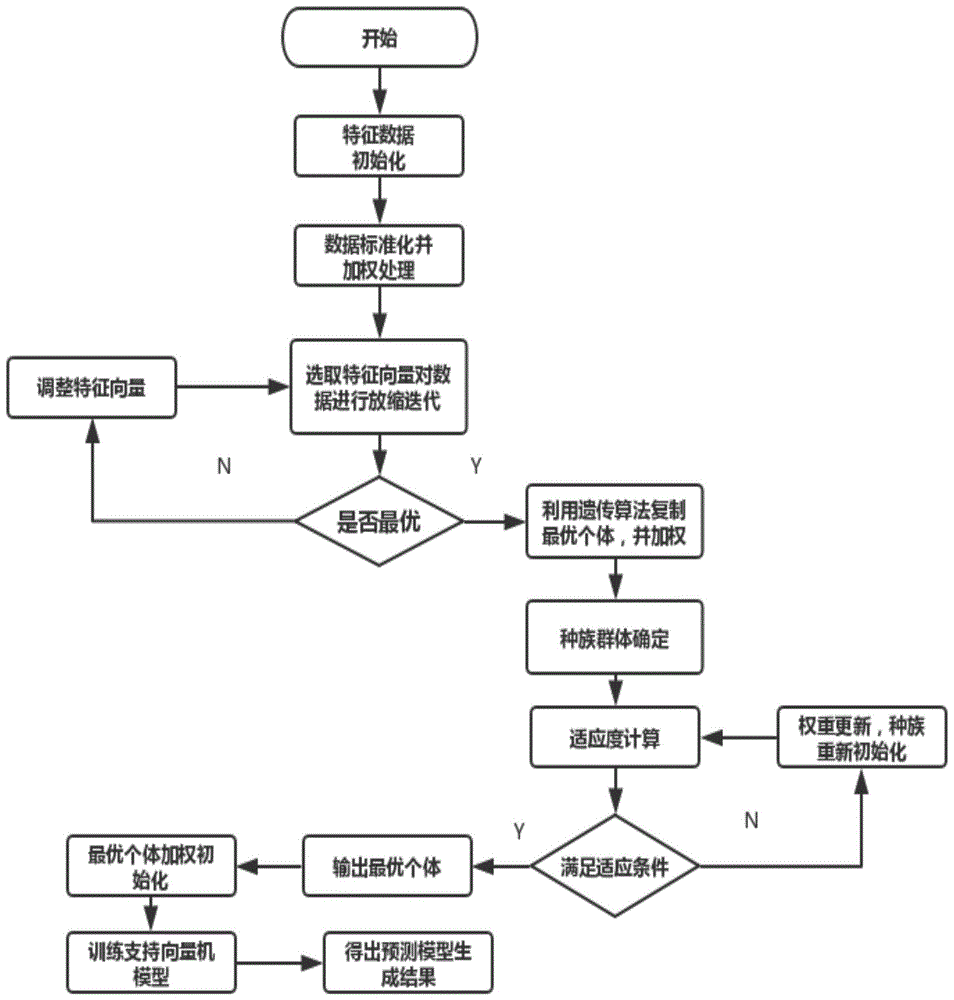
图1是本发明一种基于机器学习的污水处理水质预测方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种基于机器学习的污水处理水质预测方法,如图1,具体包括以下步骤:
s1、确定污水的测量参数和污水处理的行业标准,并初始化污水的测量参数,并将测量参数的特征权重向量初始化为1为v0(i)=1;
s2、通过线性支持向量机获取污水测量参数的适应度,将适应度最大的个体作为最优的个体,令i=1;
s3、在第i次迭代中,将最优的个体复制n-1个,并在每个复制的个体上的特征权重上随机加上一个[0,max_variation]的值;
s4、通过线性支持向量机获取当前个体的适应度,选择适应度最大的个体作为最优的个体;
s5、判断是否达到最大迭代次数,若没达到则令i=i+1,返回步骤s3;否则输出最优的特征权重向量;
s6、将得到最优特征向量输入线性支持向量机,完成训练;将实时污水测量参数输入完成训练的线性支持向量机即可得到预测结果;
其中,n为预定的种群数量;max_variation为预设的单代最大变异度;vj(i)为第j个污水的测量参数的特征向量,1≤i≤m,m为该测量参数的特征向量的维数。
在对线性支持向量机进行训练的过程中,线性支持向量机使数据集中的每一个错误样本点(xi,yi)都引入一个松弛变量ξi≥0,使函数间间隔加上松弛变量大于等1,如下公式所示:
yi(ω·xi+b)≥1-ξi;
同时,对每一个松弛变量ξi,都支付相应代价,则目标函数为:
其中,c>0为惩罚参数,通过交叉验证法确定c的值,c值最大时,对误分类项的惩罚增大,c值小时,对误分类的惩罚减小;ω、b是线性支持向量机的两个超参数;此时最小化目标函数使得几何间隔尽量大,而同时保持松弛变量的和尽量小,c是调和二者的系数;最终输出分离出两个线性支持向量机的最优的超参数ω*、b*以及决策分析函数,完成训练。
进一步的,所述适应度为个体的f1分数,f1分数为支持向量机在验证集上的性能参数。
进一步的,污水的测量参数至少包括codcr出水、ph值、溶解氧do、氨氮nh3-n。
本发明还提出一种基于机器学习的污水处理的水质预测系统,包括数据输入模块、基于线性支持向量机的预测模块和水务平台污水检测子系统;所述数据输入模块包括历史数据存储器、实时数据缓存器以及期望数据存储器;其中:
历史数据存储器用于存储污水处理厂最近几天实时检测到的水务数据;
期望数据存储器用于存储污水处理的行业标准的数据;
实时数据缓存器用于缓存实时监测到的水务数据;
基于线性支持向量机的预测模块用于根据历史数据存储器和期望数据存储器的数据对实时数据缓存器中的数据进行预测;
水务平台污水检测子系统用于获取水务信息。
进一步的,所述水务平台污水监测子系统包括数据采集单元和数据存储打印单元,所述数据采集单元包括codcr出水检测装置、ph值检测装置、溶解氧do检测装置、氨氮nh3-n检测装置;数据采集单元将各个检测装置检测的污水的测量参数通过数据存储打印单元存储打印。
进一步的,污水处理厂的每种污水处理设备的出水口至少设置有一个数据采集装置。
进一步的,基于线性支持向量机的预测模块包括线性支持向量机,将历史数据存储器中的数据和期望数据存储器的数据输入线性支持向量机进行训练获得特征权值,线性支持向量机训练获得最优特征权值的过程中,调用线性支持向量机在验证集上的性能f1分数作为筛选特征权值的指标;将实时数据缓存器中的数据作为线性支持向量机的输入,线性支持向量机输出对污水处理的预测结果。
本发明是通过对以往污水水质的数据集进行数据的处理训练的结果,来实时预测未来的污水水质的情况。有助于提前预测污水可能出现的问题,让污水处理与解决更加的便捷,达到一致实时监管、实时调控的作用,提前预防。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!