基于交错增强注意力网络的人体行为识别方法与流程
[0001]
本发明属于视频处理技术领域,更进一步涉及计算机视觉技术领域中的一种基于交错增强注意力网络的人体行为识别方法。本发明可用于从视频中识别出人体的行为类别。
背景技术:
[0002]
近年来,随着人工智能和计算机视觉的发展,基于视频的人体行为识别已被广泛应用于智能视频监控、人机交互、无人驾驶等技术领域。人体行为识别主要目标是判断一个视频中人体行为的类别。所以人体行为识别也可以看作是输入为视频,输出为行为类别的分类问题。目前,卷积神经网络由于其强大的图像表征能力,成为了人体行为识别中的主流方法。
[0003]
西安交通大学在其申请的专利文献“基于时空注意力的人体行为识别方法”(专利申请号2019102507757,申请公开号cn110059587a)中公开了一种人体行为识别方法。该方法的具体步骤为:1.将输入的视频拆分成图像帧;2.均匀抽取一定数量的图片,并使用卷积神经网络对每帧图片进行特征提取,将网络的高层特征作为每帧图片对应的特征向量;3.使用前向感知机计算每帧图片对应的空间注意力权重,并使用这些权重对每帧图片的特征向量进行加权;4.将加权特征向量输入到长短期记忆网络中,输出类别概率向量;5.使用特征向量和长短期记忆网络隐藏层的输出计算相应的时间注意力权重,并对类别概率向量加权求和,得到新的类别概率向量;6.对模型进行训练,取类别概率向量中的最大值对应的类别作为最终的类别并输出,作为模型参数;7.将保存的模型和参数相结合,得到人体行为识别模型。该方法存在的不足之处是,仅使用卷积神经网络的高层特征获取注意力以及进行识别,而网络的低层特征包含了视频帧中的局部细节信息,这些信息的忽略会导致行为识别的失败。
[0004]
天津大学在其申请的专利文献“一种基于注意力机制的视频行为识别方法”(专利申请号2019105583023,申请公开号cn110287879 a)中公开了一种视频行为识别方法。该方法的具体步骤为:1.采样视频帧,将每一帧图像输入卷积神经网络,将网络的高层输出作为每一个视频帧的帧级特征;2.对帧级特征进行空域全局平均处理,融合特征中的空域信息,获取不同帧的通道级特征表达,并计算通道级时域注意力得分;3.将所获得的注意力得分作为权重系数,使用加权求和,将帧级特征表达融合为视频级特征表达。该方法存在的不足之处是,由于该方法是同等地看待视频帧中的各个空间位置,然而视频中的每个帧的不同空间位置对行为识别通常有不同程度的重要性,这使得该方法容易被视频中存在的大量冗余的背景信息和与行为无关的信息干扰,从而导致行为识别的结果产生错误。
技术实现要素:
[0005]
本发明的目的在于针对上述现有技术存在的不足,提出了一种基于交错增强注意力网络的人体行为识别方法,用于解决由于现有技术忽略视频帧中的局部细节信息,容易
被视频中存在的大量冗余的背景信息和与行为无关的信息干扰,导致的对行为的识别能力不足的问题。
[0006]
为实现上述目的,本发明的思路是,先构建局部增强注意力模块和层次互补注意力模块,并基于此构建交错增强注意力网络,交错增强注意力网络的输入为从inception-v3中获得的视频帧的低层特征图和高层特征图,使得本网络能够充分利用视频帧中的局部细节信息;利用构建的新的损失函数训练交错增强注意力网络,使得网络能够聚焦于视频帧中具有鉴别性的信息。
[0007]
为实现上述目的,本发明的实现的具体步骤如下:
[0008]
(1)生成训练集:
[0009]
(1a)选取视频数据集中包含n个行为类别的rgb视频,其中n>50,每个类别包含至少100个视频,每个视频均有一个确定的行为类别;
[0010]
(1b)将每个视频分成3个等长片段,在每个片段中随机选择1帧rgb图像,将rgb图像尺寸固定为256
×
340个像素后依次通过角点裁剪、随机水平翻转、尺度抖动进行预处理,得到10帧尺寸为224
×
224个像素的rgb图像;
[0011]
(1c)将预处理后的rgb图像组成训练集;
[0012]
(2)获得低层特征图和高层特征图:
[0013]
将训练集中的每帧rgb图像依次输入到inception-v3中,inception-v3中的第一个inception-a模块和第二个inception-c模块分别输出该帧rgb图像的低层特征图和高层特征图其中,表示第t帧rgb图像的低层特征图,其尺寸为26
×
26
×
288;表示第t帧rgb图像的高层特征图,其尺寸为6
×6×
288;
[0014]
(3)构建层次互补注意力模块:
[0015]
(3a)搭建层次互补注意力模块的第一个子模块,其结构依次为:第一卷积层,第一池化层,第二卷积层,第二池化层,通道平均池化层,第三卷积层,softmax激活层,加权层;
[0016]
各层参数设置如下:第一至第三卷积层的卷积核个数依次为768,1280和1,卷积核大小分别设置为5
×
5,3
×
3和3
×
3,第一和第二池化层均采用最大池化方式,池化核大小均设置为2
×
2,池化步长均设置为2,加权层使用softmax激活层的输出对第一卷积层的输出进行加权;
[0017]
(3b)搭建层次互补注意力模块的第二个子模块,其结构依次为:通道平均池化层,卷积层,softmax激活层,加权层;
[0018]
各层参数设置如下:卷积层的卷积核的个数为1,卷积核大小为3
×
3,加权层使用softmax激活层的输出对通道平均池化层的输出进行加权;
[0019]
(3c)搭建层次互补注意力模块的第三个子模块,第三个子模块将第一个子模块和第二个子模块的输出作为输入,其结构依次为:concat层,第一卷积层,第二卷积层;
[0020]
各层参数设置如下:concat层的拼接维度设置为1280,两个卷积层的卷积核个数均为1280,卷积核大小分别设置为1
×
1和6
×
6;
[0021]
(3d)将层次互补注意力模块的第一个和第二个子模块并联后再与第三个子模块串联,组成层次互补注意力模块;
[0022]
(4)构建局部增强注意力模块:
[0023]
(4a)搭建局部增强注意力模块的第一个子模块,其结构依次为:第一卷积层,第一池化层,第二卷积层,第二池化层,全局平均池化层,第三卷积层,relu激活层,第四卷积层,softmax激活层;
[0024]
各层参数设置如下:第一至第四个卷积层的卷积核个数依次为768,1280,1280,1280,卷积核大小依次设置为5
×
5,3
×
3,1
×
1和1
×
1,第一和第二池化层均采用最大池化方式,池化核大小均设置为2
×
2,池化步长均设置为2;
[0025]
(4b)搭建局部增强注意力模块的第二个子模块,其结构依次为:全局平均池化层,第一卷积层,relu激活层,第二卷积层,softmax激活层;
[0026]
各层参数设置如下:第一和第二卷积层的卷积核个数均为1280,卷积核大小均设置为1
×
1;
[0027]
(4c)搭建局部增强注意力模块的第三个子模块,其结构依次为:第一add层,卷积层,softmax激活层,加权层,第二add层,全局平均池化层;
[0028]
各层参数设置如下:第一add层的输出维数为1280,卷积层的个数为1280,卷积核大小设置为1
×
1,加权层使用softmax激活层的输出对第一个子模块的第二个池化层的输出加权,第二add层的输入为加权层的输出和第二个子模块的全局平均池化层的输入,输出维数为1280;
[0029]
(4d)将局部增强注意力模块的第一个和第二个子模块并联后再与第三个子模块串联,组成局部增强注意力模块;
[0030]
(5)搭建分类网络:
[0031]
搭建一个五层的分类网络,其结构依次为:concat层,卷积层,第一全连接层,第二全连接层,softmax激活层;
[0032]
网络的每层参数如下:concat层的拼接维度设置为1280,卷积层的卷积核个数为1000,卷积核大小设置为1
×
1,两个全连接层的输出神经元个数分别为1000和n;
[0033]
(6)搭建交错增强注意力网络:
[0034]
将层次互补注意力模块和局部增强注意力模块并联后再与分类网络串联,组成交错增强注意力网络;
[0035]
(7)构建交错增强注意力网络的损失函数:
[0036]
(7a)构建相似性度量函数如下:
[0037][0038]
其中,和分别表示训练集中第t帧rgb图像输入后层次互补注意力模块的第一个子模块和第二个子模块的softmax激活层输出的注意力矩阵,其维度均为6
×
6,∑表示求和操作,n表示应用第一预设规则将和分别依次排列成向量后,该向量中元素的序号,表示应用所述第一预设规则将依次排列成向量后,该向量中的第n个元素,表示应用所述第一预设规则将依次排列成向量后,该向量中的第n个元素,其中,所述第一预设规则为以行的顺序为最高优先级,以列的顺序为次一级优先级将矩阵依次排列成向量;
[0039]
(7b)构建交错增强注意力网络的损失函数loss如下:
[0040][0041]
其中,l
c
表示基本交叉熵函数,ξ1和ξ2表示正则化参数,e表示以自然常数为底的指数操作,a
t
表示训练集中第t帧rgb图像输入后局部增强注意力模块的第三个子模块的softmax激活层输出的通道注意力向量,其维数为1280,m表示a
t
中的元素的序号,a
m
表示a
t
中的第m个元素,max{
·
}表示取最大值操作,||
·
||2表示二范数操作,γ表示调节因子;
[0042]
(8)训练交错增强注意力网络:
[0043]
将训练集中的所有图像对应的低层特征图和高层特征图输入到所述交错增强注意力网络中,利用反向传播梯度下降法更新所述交错增强注意力网络的各层参数,直到交错增强注意力网络的损失值接近于0.25时,得到训练好的交错增强注意力网络;
[0044]
(9)识别视频图像中的行为:
[0045]
对每个待识别的行为视频均匀采样25帧rgb图像,得到待识别图像,将所述待识别图像的尺寸固定为224
×
224个像素后,输入到inception-v3中提取低层特征图和高层特征图,再将低层特征图和高层特征图输入到所述交错增强注意力网络中,得到所述待识别图像的分类概率,将所述待识别图像的分类概率取平均值,得到行为视频的识别结果。
[0046]
本发明与现有技术相比较,具有以下优点:
[0047]
第一,由于本发明构建了层次互补注意力模块和局部增强注意力模块,其输入为inception-v3提取的低层特征图和高层特征图,克服了现有技术仅使用卷积神经网络的高层特征图获取注意力以及进行识别,而网络的低层特征包含了人体的局部细节信息,这些信息的忽略会导致行为识别的失败的问题,使得本发明提出的技术能够充分利用视频帧中的细节信息,提高了行为识别的准确率。
[0048]
第二,由于本发明构建了一个新的损失函数,使得交错增强注意力网络能够自动聚焦于视频帧中的重要区域,同时抑制噪声,克服了现有技术同等地看待视频帧中的各个空间位置,然而视频中的每个帧的不同空间位置对行为识别通常有不同程度的重要性,这使得现有技术容易被视频中存在的大量冗余的背景信息和与行为无关的信息干扰,从而导致行为识别的结果产生错误的问题,使得本发明提出的技术能够关注到视频帧中具有鉴别性的信息,获取更具有表达能力的特征。
附图说明
[0049]
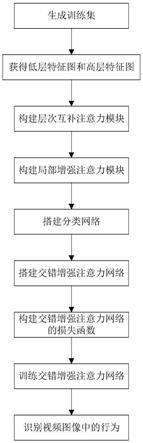
图1为本发明的流程图;
[0050]
图2为本发明层次互补注意力模块的结构示意图;
[0051]
图3为本发明局部增强注意力模块的结构示意图。
具体实施方式
[0052]
下面结合附图对本发明做进一步的描述。
[0053]
参照图1,对本发明的具体步骤做进一步的描述。
[0054]
步骤1.生成训练集。
[0055]
选取视频数据集中包含n个行为类别的rgb视频,其中n>50,每个类别包含至少100个视频,每个视频均有一个确定的行为类别。
[0056]
将每个视频分成3个等长片段,在每个片段中随机选择1帧rgb图像,将rgb图像尺寸固定为256
×
340个像素后依次通过角点裁剪、随机水平翻转、尺度抖动进行预处理,得到10帧尺寸为224
×
224个像素的rgb图像。角点裁剪是指在图像的中心和四角选取一定大小的区域进行裁剪,随机水平翻转是指对图片的水平方向进行随机翻转,尺度抖动是指按一定抖动比例决定裁剪区域的大小。以公开的ucf101数据集为例,固定从视频中提取的rgb图像的尺寸为256
×
340,在图像的四个角和中心裁剪,裁剪区域的宽和高从{256,224,192,168}中随机选取,然后将裁剪后的区域调整为224
×
224,并进行随机水平翻转。
[0057]
将预处理后的所有rgb图像组成训练集。
[0058]
步骤2.获得低层特征图和高层特征图。
[0059]
使用inception-v3作为提取特征的卷积神经网络,将训练集中的每帧rgb图像依次输入到inception-v3中,inception-v3中的第一个inception-a模块和第二个inception-c模块分别输出该帧rgb图像的低层特征图和高层特征图其中,表示第t帧rgb图像的低层特征图,其尺寸为26
×
26
×
288;表示第t帧rgb图像的高层特征图,其尺寸为6
×6×
288;
[0060]
步骤3.构建层次互补注意力模块。
[0061]
参照附图2,对本发明构建的层次互补注意力模块的结构做进一步的描述。
[0062]
搭建层次互补注意力模块的第一个子模块,其结构依次为:第一卷积层,第一池化层,第二卷积层,第二池化层,通道平均池化层,第三卷积层,softmax激活层,加权层,第一个子模块的输入为
[0063]
各层参数设置如下:第一至第三卷积层的卷积核个数依次为768,1280和1,卷积核大小分别设置为5
×
5,3
×
3和3
×
3,第一和第二池化层均采用最大池化方式,池化核大小均设置为2
×
2,池化步长均设置为2,加权层使用softmax激活层的输出对第一卷积层的输出进行加权。
[0064]
搭建层次互补注意力模块的第二个子模块,其结构依次为:通道平均池化层,卷积层,softmax激活层,加权层,第二个子模块的输入为
[0065]
各层参数设置如下:卷积层的卷积核的个数为1,卷积核大小为3
×
3,加权层使用softmax激活层的输出对通道平均池化层的输出进行加权。
[0066]
搭建层次互补注意力模块的第三个子模块,第三个子模块将第一个子模块和第二个子模块的输出作为输入,其结构依次为:concat层,第一卷积层,第二卷积层。
[0067]
各层参数设置如下:concat层的拼接维度设置为1280,两个卷积层的卷积核个数均为1280,卷积核大小分别设置为1
×
1和6
×
6。
[0068]
将层次互补注意力模块的第一个和第二个子模块并联后再与第三个子模块串联,组成层次互补注意力模块,层次互补注意力模块的输出为层次互补特征。
[0069]
步骤4.构建局部增强注意力模块
[0070]
参照附图3,对本发明构建的局部增强注意力模块的结构做进一步的描述。
[0071]
搭建局部增强注意力模块的第一个子模块,其结构依次为:第一卷积层,第一池化层,第二卷积层,第二池化层,全局平均池化层,第三卷积层,relu激活层,第四卷积层,softmax激活层,第一个子模块的输入为
[0072]
各层参数设置如下:第一至第四个卷积层的卷积核个数依次为768,1280,1280,1280,卷积核大小依次设置为5
×
5,3
×
3,1
×
1和1
×
1,第一和第二池化层均采用最大池化方式,池化核大小均设置为2
×
2,池化步长均设置为2。
[0073]
搭建局部增强注意力模块的第二个子模块,其结构依次为:全局平均池化层,第一卷积层,relu激活层,第二卷积层,softmax激活层,第二个子模块的输入为
[0074]
各层参数设置如下:第一和第二卷积层的卷积核个数均为1280,卷积核大小均设置为1
×
1。
[0075]
搭建局部增强注意力模块的第三个子模块,其结构依次为:第一add层,卷积层,softmax激活层,加权层,第二add层,全局平均池化层。
[0076]
各层参数设置如下:第一add层的输出维数为1280,卷积层的个数为1280,卷积核大小设置为1
×
1,加权层使用softmax激活层的输出对第一个子模块的第二个池化层的输出加权,第二add层的输入为加权层的输出和第二个子模块的全局平均池化层的输入,输出维数为1280。
[0077]
将局部增强注意力模块的第一个和第二个子模块并联后再与第三个子模块串联,组成局部增强注意力模块,局部增强注意力模块的输出为局部增强特征。
[0078]
步骤5.搭建分类网络。
[0079]
搭建一个五层的分类网络,其结构依次为:concat层,卷积层,第一全连接层,第二全连接层,softmax激活层。
[0080]
网络的每层参数如下:concat层的拼接维度设置为1280,卷积层的卷积核个数为1000,卷积核大小设置为1
×
1,两个全连接层的输出神经元个数分别为1000和n。
[0081]
步骤6.搭建交错增强注意力网络。
[0082]
将层次互补注意力模块和局部增强注意力模块并联后再与分类网络串联,组成交错增强注意力网络。
[0083]
步骤7.构建交错增强注意力网络的损失函数。
[0084]
构建相似性度量函数如下:
[0085][0086]
其中,和分别表示训练集中第t帧rgb图像输入后层次互补注意力模块的第一个子模块和第二个子模块的softmax激活层输出的注意力矩阵,其维度均为6
×
6,∑表示求和操作,n表示应用第一预设规则将和分别依次排列成向量后,该向量中元素的序号,表示应用所述第一预设规则将依次排列成向量后,该向量中的第n个元素,表示应用所述第一预设规则将依次排列成向量后,该向量中的第n个元素,其中,所述第一
预设规则为以行的顺序为最高优先级,以列的顺序为次一级优先级将矩阵依次排列成向量。具体地,在第一预设规则中,行的顺序的优先级高于列的顺序的优先级,排列规则可以先将矩阵中每一行元素按照列的顺序展开成列向量,再将得到的列向量按照排列之前行的顺序的前后进行首尾拼接。
[0087]
构建交错增强注意力网络的损失函数loss如下:
[0088][0089]
其中,l
c
表示基本交叉熵函数,ξ1和ξ2表示正则化参数,e表示以自然常数为底的指数操作,a
t
表示训练集中第t帧rgb图像输入后局部增强注意力模块的第三个子模块的softmax激活层输出的通道注意力向量,其维数为1280,m表示a
t
中的元素的序号,a
m
表示a
t
中的第m个元素,max{
·
}表示取最大值操作,||
·
||2表示二范数操作,γ表示调节因子。
[0090]
损失函数loss中的第二项能够鼓励层次互补注意力模块中的第一个子模块和第二个子模块聚焦于给定图像的不同区域,loss中的第三项能够增强与特定任务有关的局部增强注意力模块得到的通道注意力的权重,因而loss能够强调出鉴别性的语义特征,更加精确地聚焦于细粒度信息而不受前景和背景比例的影响。
[0091]
步骤8.训练交错增强注意力网络。
[0092]
将训练集中的所有图像对应的低层特征图和高层特征图输入到所述交错增强注意力网络中,利用反向传播梯度下降法更新所述交错增强注意力网络的各层参数,直到交错增强注意力网络的损失值接近于0.25时,得到训练好的交错增强注意力网络。
[0093]
步骤9.识别视频图像中的行为。
[0094]
对每个待识别的行为视频均匀采样25帧rgb图像,得到待识别图像,将所述待识别图像的尺寸固定为224
×
224个像素后,输入到inception-v3中提取低层特征图和高层特征图,再将低层特征图和高层特征图输入到所述交错增强注意力网络中,得到所述待识别图像的分类概率,将所述待识别图像的分类概率取平均值,得到行为视频的识别结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1