一种UI图像自动标注方法及装置与流程
一种ui图像自动标注方法及装置
技术领域
[0001]
本发明涉及图像标注领域,更具体的说是涉及一种ui图像自动标注方法及装置。
背景技术:
[0002]
优秀的设计能够有效地传达产品价值,但也离不开技术的落地支持。随着市场环境变化与行业水平的提升,越来越多设计师开始意识到:ui设计稿还原的重要性。但是在配合过程中,设计与研发思维的偏差也逐渐体现:“这个需求做不了,那个间距调不好
”……
设计稿落地后,往往要经过多轮测试和“小板凳”对接,才能达到预期效果。可以说,在每一位ui设计师的成长过程中,设计稿还原,是一个必定经历且难以解决的问题。传统ui设计师交付设计稿存在两个缺陷。
[0003]
(1).给设计图做切图标注都是纯手动切图标注操作,经常会出现漏标、错标的情况。
[0004]
(2).手动切图标注过程中漏标、错标的地方,工程师在开发过程中发现后又找设计师沟通进行反复的确认,十分耗费心神,效率极低,不能有效的提升工作效率。
技术实现要素:
[0005]
本发明的目的在于提供一种ui图像自动标注方法及装置,以期解决背景技术中的问题。通过建立低层特征和高层语义标签之间的联系,得到待标注图像各标签的概率并灵活预测需标注的标签个数,并由此完成图像的自动标注,从而提升图像标注的准确度。
[0006]
为了实现上述目的,本发明采用以下技术方案:
[0007]
一种ui图像自动标注方法,包括以下步骤:
[0008]
s100:利用深度学习技术提取待标注图像的视觉特征;
[0009]
s200:利用图像库构建待标注图像的候选标签集;
[0010]
s300:融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;
[0011]
s400:根据待标注图像的高层特征,利用图像库中各标签计算在标注待标注图像时的概率;
[0012]
s500:根据待标注图像的高层特征,预测待标注图像所需的标签个数;
[0013]
s600:根据所计算的标签概率和所预测的标签个数,利用概率最高的前n个标签对待标注图像进行标注;其中,n为预测的标签个数。
[0014]
进一步的,所述s100利用深度学习技术提取待标注图像的视觉特征,包括:利用基于卷积神经网络的视觉特征提取模型提取待标注图像的视觉特征;视觉特征提取模型的训练方法包括:构建基于卷积神经网络的第一神经网络模型,用于提取图像的视觉特征,存放在图像库中,并利用图像库中提取的图像的视觉特征训练第一神经网络模型,从而得到视觉特征提取模型。
[0015]
进一步的,所述s200:利用图像库构建待标注图像的候选标签集,包括:获得图像库中每个标签出现的次数;对于待标注图像,根据图像距离计算待标注图像与图像库中其
余图像的相似性,从而得到与待标注图像相似性最高的m幅图像;其中,用于计算图像相似性的图像距离为街区距离、欧式距离、无穷范数、直方图相交、二次式距离、马氏距离、emd距离;
[0016]
从m幅图像中获得与待标注图像相似性最高的n幅图像,并获得在这n幅图像中出现的p1个标签;若p1≥k,则根据图像库中每个标签出现的次数从p1个标签中获得出现次数最高的k个标签,作为k个候选标签,从而构建待标注图像的候选标签集;否则,获得在m幅图像中出现的p2个标签,并根据图像库中每个标签出现的次数从p2个标签中获得出现次数最高的k个标签,作为k个候选标签,从而得到该图像的候选标签集;其中,k为预设的候选标签集大小,且m、n及k满足:k≤m,n≤m。
[0017]
进一步的,所述s300:融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征,包括:利用一个全连接层融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;具体包括:
[0018]
s301:对于图像库中的图像i,利用视觉特征提取模型提取其视觉特征;
[0019]
s302:构建图像i的候选标签集l,并利用候选标签集l和语义特征提取模型提取图像i的语义特征;
[0020]
s303:融合图像i的视觉特征和语义特征以得到图像i的高层特征;对于图像库中的每一幅图像,执行步骤s301:~s303,从而提取图像库中每一幅图像的高层特征。
[0021]
进一步的,所述s400:根据待标注图像的高层特征,利用图像库中各标签计算在标注待标注图像时的概率,包括:构建基于多层感知机的第三神经网络模型,用于根据图像的高层特征计算图像库中各标签在标注图像时的概率。
[0022]
进一步的,所述s500:根据待标注图像的高层特征,预测待标注图像所需的标签个数,包括:构建基于多层感知机的第四神经网络模型,用于根据图像的高层特征预测图像所需的标签个数;第四神经网络模型包括两个隐藏层,分别有512和256个神经元,在隐藏层中对所有神经元进行dropout,且概率设置为0.5;利用已提取图像高层特征的图像库训练第四神经网络模型,从而得到标签个数预测模型。
[0023]
本发明还提供了一种ui图像自动标注装置,应用于权1-权6中任一所述的标注方法,包括:
[0024]
视觉特征提取模块,用于提取待标注图像的视觉特征;
[0025]
候选标签集构建模块,用于利用图像库构建待标注图像的候选标签集;
[0026]
语义特征提取模块,用于利用深度学习技术提从待标注图像的候选标签集中取待标注图像的语义特征;
[0027]
特征融合模块,用于融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;
[0028]
多目标分类模块,用于根据待标注图像的高层特征,利用深度学习技术计算图像库中各标签在标注待标注图像时的概率;
[0029]
标签个数预测模块,用于根据待标注图像的高层特征,利用深度学习技术预测待标注图像所需的标签个数;
[0030]
标注模块,用于根据多目标分类模块所计算的标签概率和标签个数预测模块所预测的标签个数,利用概率最高的前n个标签对待标注图像进行标注。
[0031]
进一步的,所述图像库中的图像为已标注标签的图像,候选标签集包括图像库中的多个标签,n为标签个数预测模块所预测的标签个数。
[0032]
本发明与现有技术相比具有的有益效果是:
[0033]
本发明根据ui设计师的图像智能切图标注,无需手动切图标注,本发明在不影响ui设计师的设计,就可以完整而清晰地的将ps设计图中的每个元素的尺寸、位置、颜色、间距、字号等样式信息自动同步到系统平台,工程师可随时查看,还支持百分比标注;可单选图层,可连续选多个图层,并智能标注需要的度量。工程师需要什么信息自己就能查看。减少ui设计机械重复的标注工作,减少漏标、错标与工程师反复沟通确认的时间成本,提高了工作效率。
附图说明
[0034]
图1为本发明的一种ui图像自动标注方法的流程图;
具体实施方式
[0035]
下面结合实施例对本发明作进一步的描述,所描述的实施例仅仅是本发明一部分实施例,并不是全部的实施例。基于本发明中的实施例,本领域的普通技术人员在没有做出创造性劳动前提下所获得的其他所用实施例,都属于本发明的保护范围。
[0036]
实施例1:
[0037]
本发明提供了一种ui图像自动标注方法,其整体思路在于:分别提取图像的视觉特征和语义特征,并通过融合图像的视觉特征和语义特征得到图像的高层特征;根据图像的高层特征计算图像库中各标签在标注待标注图像时的概率并预测待标注图像的标签个数,然后结合所计算的标签的概率和所预测的标签个数,完成对图像的自动标注。
[0038]
本发明所提供一种ui图像自动标注装置,用于完成对待标注图像的自动标注,为了让协作设计更加高效,灵活地适应不同规模和类型的产品团队,“柔性工作流”,通过“一条主线多个节点”的工作流解决协作难的问题。标注是设计和开发之间交付协作的重要载体,「自动+手动」标注就是在柔性工作流的设计主线下进行的。普通工作流往往是将很多东西混杂在一起,并施以一种固定的线程去实现某种业务目标。特点是注重体系规范,业务按照固定模式流转。
[0039]
而柔性工作流,最通俗易懂的说法——是基于固定流程(规则性)与自由流程(灵活性)之间的一种流程。也就是说,主线是固定的,流程有一个固定的步骤,但主线中的某一个或多个节点使用自由流程方式转交,且互不干扰。相较普通工作流,柔性工作流在其基础上实现了随需而动、业务复用,改善业务流程,提升团队效率。
[0040]
如图1所示,包括如下步骤:
[0041]
s100:利用深度学习技术提取待标注图像的视觉特征;具体包括:利用基于卷积神经网络(convolutional neural network,cnn)的视觉特征提取模型提取待标注图像的视觉特征;视觉特征提取模型的训练方法包括:构建基于卷积神经网络的第一神经网络模型,用于提取图像的视觉特征;其中,卷神经网络可为alexnet网络、lenet网络、googlenet网络、vgg网络、inception网络、resnet网络、inception-resnet-v2网络或其他卷积神经网络;在本实施例中,卷积神经网络为inception-resnet-v2网络,使用inception-resnet-v2
网络提取图像的视觉特征,一方面能够在极大的提高训练速度的同时大幅度的提高分类准确率,另一方面能够增加网络的非线性;利用mmrf图像库训练第一神经网络,从而得到视觉特征提取模型;利用mmrf图像库构建待标注图像的候选标签集,并利用待标注图像的候选标签集中提取待标注图像的语义特征;
[0042]
s200:利用图像库构建待标注图像的候选标签集;包括:获得图像库中每个标签出现的次数;对于待标注图像,根据图像距离计算待标注图像与图像库中其余图像的相似性,从而得到与待标注图像相似性最高的m幅图像;其中,用于计算图像相似性的图像距离可以为街区距离、欧式距离、无穷范数、直方图相交、二次式距离、马氏距离、emd距离或其他图像距离。
[0043]
从m幅图像中获得与待标注图像相似性最高的n幅图像,并获得在这n幅图像中出现的p1个标签;若p1≥k,则根据图像库中每个标签出现的次数从p1个标签中获得出现次数最高的k个标签,作为k个候选标签,从而构建待标注图像的候选标签集;否则,获得在m幅图像中出现的p2个标签,并根据图像库中每个标签出现的次数从p2个标签中获得出现次数最高的k个标签,作为k个候选标签,从而得到该图像的候选标签集;其中,k为预设的候选标签集大小,且m、n及k满足:k≤m,n≤m;
[0044]
基于上述构建候选标签集的方法,具体还包括:利用图像库构建待标注图像的候选标签集,并利用基于多层感知机(multi-layerperceptron,mlp)的语义特征提取模型从待标注图像的候选标签集中提取待标注图像的语义特征;
[0045]
语义特征提取模型的训练方法包括如下步骤:构建图像库中每一幅图像的候选标签集;构建基于多层感知机的第二神经网络模型,用于从图像的候选标签集中提取图像的语义特征;其中,第二神经网络模型包含两个隐藏层,且激活函数采用relu函数;利用已构建候选标签集的图像库训练第二神经网络模型,从而得到语义特征提取模型;
[0046]
s300:融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;在一个可选的实施方式中,步骤s300:具体包括:s301:利用一个全连接层(fc)融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;具体包括:
[0047]
s301:对于图像库中的图像i,利用视觉特征提取模型提取其视觉特征;
[0048]
s302:构建图像i的候选标签集l,并利用候选标签集l和语义特征提取模型提取图像i的语义特征;
[0049]
s303:融合图像i的视觉特征和语义特征以得到图像i的高层特征;对于图像库中的每一幅图像,执行步骤s301:~s303,从而提取图像库中每一幅图像的高层特征。应当理解的是,除了全连接层外,其他用于实现特征融合的方式也可用于融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征。
[0050]
s400:根据待标注图像的高层特征,利用图像库中各标签计算在标注待标注图像时的概率;在一个可选的实施方式中,具体包括:根据待标注图像的高层特征,利用基于多层感知机的多目标分类模型计算图像库中各标签在标注待标注图像时的概率;多目标分类模型的训练方法包括:对于图像库中的图像i,利用视觉特征提取模型提取其视觉特征;基于生成模型的图像标注算法得到第i个标签在第k幅图像中出现或者不出现,训练集总共包含k幅图像和观察图像的特征d共同出现的联合概率p(d,w),若2个标签共同出现于同一幅图像,则认为这2个标签相关,如此可以构建一个基于点s={1,2,
…
,m}的关系图ζ=(s,ε),
其中ε代表关系图的边集,再代入mmrf中的模型参数θ。
[0051]
输入:待标注图像i,词表s,训练图像集x;
[0052]
输出:mmrf模型参数θ。
[0053]
①
for每一个词i∈s do
[0054]
②
构建语义概念关系图;
[0055]
③
构建相应的训练图像集;
[0056]
④
求解mmrf模型参数θ;
[0057]
⑤
end for。
[0058]
图像的特征提取是系统使用了gist和颜色直方图(其优点在于:它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。)2种全局图像特征,颜色直方图分别在rgb,lab,hsv三个颜色空间上计算3种颜色直方图。
[0059]
局部特征上使用了sift和强化色调(dense hue)特征,2种特征都分别在密集多尺度网格(dense multi-scale grid)和由harris laplacian检测器(detector)检测到图像区域上计算得到。为了引入图像内容布局信息,还将图像从水平方向分成3个区域,对这些区域根据gist以外的方法进行特征提取,再将得到的3种特征综合成为一个完整的全局特征描述。我们用到的特征总共15种,不同特征对于图像标注的作用不同,在计算2幅图像的距离时需要综合考虑所有特征。具体举例,设2幅图像在第i种特征上的欧氏距离为d
i
,则2幅图像在15种特征上的距离为:
[0060][0061]
其中w
i
是第i种特征上的欧氏距离的权重系数。权重向量w=(w1,w2,
…
,w
15
);构建基于多层感知机的第三神经网络模型,用于根据图像的高层特征计算图像库中各标签在标注图像时的概率;利用已提取图像高层特征的图像库训练第三神经网络模型,从而得到多目标分类模型;训练过程中,采用交叉作为损失函数。
[0062]
s500:根据待标注图像的高层特征,预测待标注图像所需的标签个数;在一个可选的实施方式中,具体包括:根据待标注图像的高层特征,利用基于多层感知机的标签个数预测模型预测待标注图像所需的标签个数;标签个数预测模型的训练方法包括:提取图像库中每一幅图像的高层特征,构建基于多层感知机的第四神经网络模型,用于根据图像的高层特征预测图像所需的标签个数;第四神经网络模型包括两个隐藏层,分别有512和256个神经元,并且为了避免出现过拟合的情况,在隐藏层中对所有神经元进行dropout,且概率设置为0.5;利用已提取图像高层特征的图像库训练第四神经网络模型,从而得到标签个数预测模型。
[0063]
s600:根据所计算的标签概率和所预测的标签个数,利用概率最高的前n个标签对待标注图像进行标注;其中,图像库中的图像为已标注标签的图像,候选标签集包括图像库中的多个标签,n为利用深度学习技术预测的标签个数。
[0064]
利用深度学习技术预测待标注图像所需的标签个数;重点在用tinyml算法在用户计算机上或云上进行训练,后期的tinmml这个训练才是标签标注过程工作真正开始的地
方,过程通常被称为深度压缩。利用概率最高的前n个标签对待标注图像进行标注;其中,图像库中的图像为已标注标签的图像,候选标签集包括图像库中的多个标签,n为利用深度学习技术预测的标签个数。
[0065]
tinyml算法的工作方式与传统机器学习模型基本相同。通常,这些模型是在用户的计算机上或云上进行训练的。后期训练是tinyml的工作真正开始的地方,这个过程通常被称为深度压缩。
[0066]
本发明还提供了一种图像自动标注装置,用于完成对待标注图像的自动标注,包括:视觉特征提取模块,用于提取待标注图像的视觉特征;候选标签集构建模块,用于利用图像库构建待标注图像的候选标签集;
[0067]
语义特征提取模块,用于利用深度学习技术提从待标注图像的候选标签集中取待标注图像的语义特征;
[0068]
特征融合模块,用于融合待标注图像的视觉特征和语义特征以得到待标注图像的高层特征;
[0069]
多目标分类模块,用于根据待标注图像的高层特征,利用深度学习技术计算图像库中各标签在标注待标注图像时的概率;
[0070]
标签个数预测模块,用于根据待标注图像的高层特征,利用深度学习技术预测待标注图像所需的标签个数;
[0071]
标注模块,用于根据多目标分类模块所计算的标签概率和标签个数预测模块所预测的标签个数,利用概率最高的前n个标签对待标注图像进行标注;
[0072]
其中,图像库中的图像为已标注标签的图像,候选标签集包括图像库中的多个标签,n为标签个数预测模块所预测的标签个数;
[0073]
具体来讲,就定位到设计主线下的定稿和开发这两个节点。定稿和开发两个模式的场景划分,最大程度地保障了设计师和开发工程师可以高效协作,同时又互不打扰,两个模式也可以自由切换,随需选择,相辅相成。也就是说区域、文字、坐标、尺寸、颜色。其中,文字标注工具可以能够很高效地解决自动标注不能表达的部分,比如自适应方案描述。此外,定稿模式还可查看图钉以及改变图钉工具的状态,并可以一键标记所有图钉状态为已解决,与评论模式相对接。
[0074]
在本实施例中,各模块的具体实施方式可参考以上方法实施例中的相关解释,在此不再复述。
[0075]
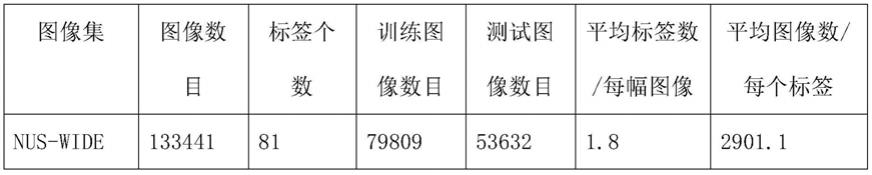
利用带有81个主题标签nus-wide图像库进行标注性能测试,nus-wide图像库的各项参数如表1所示:
[0076]
表1nus-wide图像库的各项参数
[0077][0078]
现有的比较经典的基于深度网络的图像自动标注模型包括:(1)cnn模型,即仅利用卷积神经网络提取的图像视觉特征进行图像标注的模型;(2)cnn+softmax模型,其主要
思想即利用cnn特征通过softmax函数进行多目标分类从而进行标注。
[0079]
利用nus-wide图像库,将本发明所提供的图像自动标注方法与利用上述两种图像自动标注模型进行图像标注的方法进行对比分析,评价指标包括:每个标签的查全率(c_r)和查准率(c_p),每幅图像的查全率(i_r)和查准率(i_p),每个标签的f1-score(c_f1)以及每幅图像的f1-score(i_f1);对比分析的结果如表2所示:
[0080]
表2对比分析结果
[0081][0082]
表2所示的结果显示,本发明所提供的基于一种ui图像自动标注切图方法及其系统与流程的方法,其各项评价指标均优于其余两种现有的模型;由此可知,本发明所提供的图像自动标注方法通过
[0083]
融合图像的视觉特征和语义特征得到图像的高层特征;根据图像的高层特征计算图像库中各标签在标注待标注图像时的概率并预测待标注图像的标签个数,然后结合所计算的标签的概率和所预测的标签个数,完成对图像的自动标注,能够有效提升图像标注的准确度和标注性能。
[0084]
以上所述仅为本发明较佳实例而已,本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1