多语言词权重分析模型的训练方法、装置、设备及介质与流程
本技术涉及nlp(natural language processing,自然语言处理)领域,特别涉及一种多语言词权重分析模型的训练方法、装置、设备及介质。
背景技术:
1、基于用户请求为用户提供服务时,需要重点关注用户请求中的核心词,减少对非核心词的过召回。词权重分析技术是计算各个词或词组的重要性的常见方法,可以帮助召回与核心词更相关的内容。
2、相关技术中的词权重分析,通常采用tf-idf方法,也即通过计算目标词在目标文档中出现的频率和目标词在所有统计文档中出现的频率,来获取目标词的重要性。这种方法得到的词权重分析结果是静态的,但实际上同一个词的重要性是随着语境、语言的不同而变化的,因此这样静态的词权重分析结果的准确度,在实际运用中存在问题。
技术实现思路
1、本技术实施例提供了一种多语言词权重分析模型的训练方法、装置、设备及介质。所述技术方案如下:
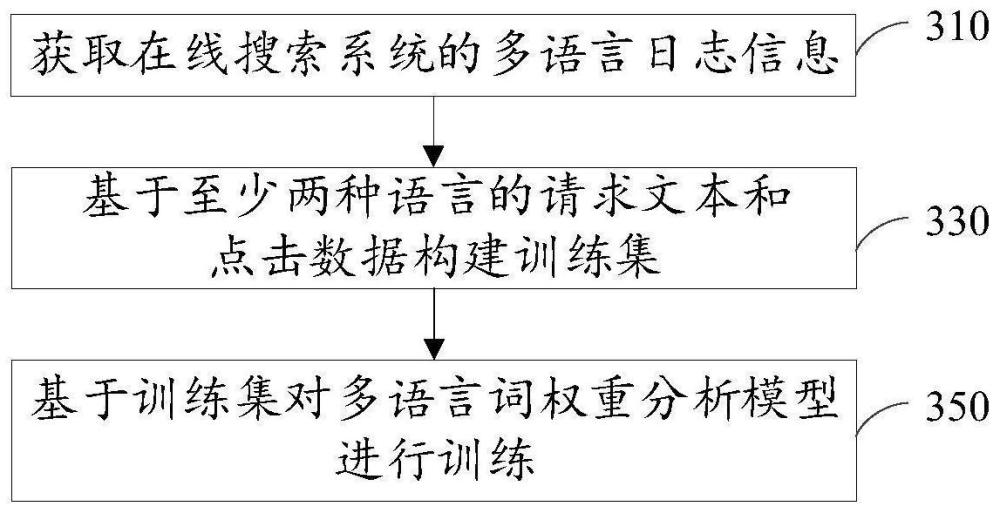
2、根据本技术的一个方面,提供了一种多语言词权重分析模型的训练方法,所述方法包括:
3、获取在线搜索系统的多语言日志信息,所述多语言日志信息包括至少两种语言的请求文本和点击数据;
4、基于所述至少两种语言的请求文本和所述点击数据构建训练集,所述训练集包括多个训练样本和所述多个训练样本对应的样本标签,所述多个训练样本对应至少两种语言;
5、基于所述训练集对所述多语言词权重分析模型进行训练。
6、一些实施例中,所述点击数据包括响应信息的被点击次数,所述响应信息与所述请求文本关联;
7、所述基于所述至少两种语言的请求文本和所述点击数据构建训练集,包括:
8、当所述响应信息的被点击次数达到阈值,构建所述至少两种语言的请求文本与所述响应信息的分类标签之间的映射关系;
9、基于所述映射关系构建所述训练集,所述多个训练样本包括所述至少两种语言的请求文本,所述样本标签包括所述响应信息的分类标签。
10、一些实施例中,所述多语言词权重分析模型包括编码层和分类层;
11、所述基于所述训练集对所述多语言词权重分析模型进行训练,包括:
12、通过所述编码层对所述训练样本进行编码,获取所述训练样本的词权重向量;
13、通过所述分类层对所述词权重向量进行分类,获取所述训练样本的预测标签,所述预测标签指所述训练样本对应的预测分类标签;
14、通过所述预测标签与所述样本标签构建的误差函数,更新所述多语言词权重分析模型的参数。
15、一些实施例中,所述通过所述编码层对所述训练样本进行编码,获取所述训练样本的词权重向量,包括:
16、通过第一编码层对所述训练样本进行编码,获取所述训练样本的相似语义向量;
17、通过第二编码层对所述相似语义向量进行编码,获取所述训练样本的位置语义向量;
18、通过第三编码层对所述位置语义向量进行编码,获取所述训练样本的词权重向量。
19、一些实施例中,所述通过第一编码层对所述训练样本进行编码,获取所述训练样本的相似语义向量,包括:
20、通过通用句子编码层对所述训练样本进行编码,获取所述训练样本的相似语义向量;
21、所述通过第二编码层对所述相似语义向量进行编码,获取所述训练样本的位置语义向量,包括:
22、通过位置编码层对所述相似语义向量进行编码,获取所述训练样本的位置语义向量;
23、所述通过第三编码层对所述位置语义向量进行编码,获取所述训练样本的词权重向量,包括:
24、通过至少两个自注意力层对所述位置语义向量进行编码,获取所述训练样本的词权重向量。
25、根据本技术的一个方面,提供了一种多语言词权重分析方法,所述方法包括:
26、获取请求文本;
27、通过如上所述的多语言词权重分析模型的训练方法,所训练得到的多语言词权重分析模型,对所述请求文本进行分析,得到所述请求文本对应的词权重分析结果。
28、根据本技术的一个方面,提供了一种多语言词权重分析模型的训练装置,所述装置包括:
29、获取模块,用于获取在线搜索系统的多语言日志信息,所述多语言日志信息包括至少两种语言的请求文本和点击数据;
30、构建模块,用于基于所述至少两种语言的请求文本和所述点击数据构建训练集,所述训练集包括多个训练样本和所述多个训练样本对应的样本标签,所述多个训练样本对应至少两种语言;
31、训练模块,用于基于所述训练集对所述多语言词权重分析模型进行训练。
32、一些实施例中,所述点击数据包括响应信息的被点击次数,所述响应信息与所述请求文本关联;
33、所述构建模块,用于当所述响应信息的被点击次数达到阈值,构建所述至少两种语言的请求文本与所述响应信息的分类标签之间的映射关系;
34、基于所述映射关系构建所述训练集,所述多个训练样本包括所述至少两种语言的请求文本,所述样本标签包括所述响应信息的分类标签。
35、一些实施例中,所述训练模块包括编码模块、分类模块和更新模块;
36、所述编码模块,用于对所述训练样本进行编码,获取所述训练样本的词权重向量;
37、所述分类模块,用于对所述词权重向量进行分类,获取所述训练样本的预测标签,所述预测标签指所述训练样本对应的预测分类标签;
38、所述更新模块,用于通过所述预测标签与所述样本标签构建的误差函数,更新所述多语言词权重分析模型的参数。
39、一些实施例中,所述编码模块包括第一编码模块、第二编码模块和第三编码模块;
40、所述第一编码模块,用于对所述训练样本进行编码,获取所述训练样本的相似语义向量;
41、所述第二编码模块,用于对所述相似语义向量进行编码,获取所述训练样本的位置语义向量;
42、所述第三编码模块,用于对所述位置语义向量进行编码,获取所述训练样本的词权重向量。
43、一些实施例中,所述第一编码模块包括通用句子编码模块,所述第二编码模块包括位置编码模块,所述第三编码模块包括至少两个自注意力模块。
44、根据本技术的一个方面,提供了一种多语言词权重分析装置,所述装置包括:
45、请求获取模块,用于获取请求文本;
46、分类模块,用于通过如上所述的多语言词权重分析模型的训练方法,所训练得到的多语言词权重分析模型,对所述请求文本进行分析,得到所述请求文本对应的词权重分析结果。
47、根据本技术的一个方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器存储有计算机程序,所述计算机程序由所述处理器加载并执行,以使得所述计算机设备实现如上所述的多语言词权重分析模型的训练方法,或如上所述的多语言词权重分析方法。
48、根据本技术的一个方面,提供了一种计算机程序产品,所述计算机可读存储介质存储有计算机程序,所述计算机程序由处理器加载并执行以实现如上所述的多语言词权重分析模型的训练方法,或如上所述的多语言词权重分析方法。
49、根据本技术的一个方面,提供了一种芯片,所述芯片包括可编程逻辑电路或程序,所述芯片用于实现如上所述的多语言词权重分析模型的训练方法,或如上所述的多语言词权重分析方法。
50、根据本技术的一个方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序由处理器加载并执行以实现如上所述的多语言词权重分析模型的训练方法,或如上所述的多语言词权重分析方法。
51、本技术实施例提供的技术方案至少包括如下有益效果:
52、通过对应至少两种语言的训练样本和样本标签,对多语言词权重分析模型进行训练,使得该模型具备了至少两种语言的词权重分析能力,有效提升了多语言环境下词权重分析结果的准确度。并且,由于利用了至少两种语言下的请求文本和点击数据,使得该模型实现了不同语言之间的数据互补,比如在分析a语言中的词权重时,可以利用b语言中的词权重分析结果对a语言的词权重分析过程提供补充、增强和帮助,进一步提升了词权重分析结果的准确度。另外,由于训练集的构建是基于在线搜索系统的日志信息构建的,还避免了人工标注所导致的资源浪费和标注错误的问题。
- 还没有人留言评论。精彩留言会获得点赞!