基于成果转换标准的整合制定方法及系统与流程
本发明涉及深度学习应用、分布式大数据,具体涉及一种基于成果转换标准的整合制定方法及系统。
背景技术:
1、成果转换标准的整合制定,是指通过网络爬虫等数据收集手段采集记录各种信息成果的公开的文本数据,再通过人工智能技术进行文本分析及文本生成,从而得到标准文本的结构化数据的一种大数据工业应用。标准文本是在全国范围内统一的技术要求,是定制其他标准的一个基石。通过办理标准文本,能够让参与企业拥有规则的话语权,引导同行业的发展方向,甚至引起行业的重新定位;同时能够帮助企业抢占市场先机,促进企业的发展。根据标准文本撰写的严格要求,标准文本最好能先形成初步的草稿。但是,不可避免的,草稿形成过程中需要进行大量的调研材料,大量的市场调查,以及大量的行业经验。更重要的是,标准文本需要严谨的章节组织结构,章节彼此间需要清晰的逻辑关系。这些使得标准文本草稿的形成具有很高的难度。因此,我们希望能够通过引入关键词以及相关文档生成方法,辅助生成标准文本草稿。
2、人工智能与各行业的结合是实现智能化方向发展的必然趋势,对推动行业朝智能化方面发展具有重要意义。人工智能领域中最主要的是针对不同的行业任务,设计相应的深度学习网络模型。随着计算机算力的提高,网络训练的难度大大减低,网络预测精度也在不断提高。深度学习网络的基本特点是模型拟合能力强、信息量大和精度高,能够满足不同行业中不同需求。
3、对于标准文本草稿的形成,其关键的问题是如何对浩瀚如烟的资料进行筛查获得摘要式文本,这将需要关键词的引导。另一方面,在获得相关摘要式文本后,还需要对不同摘要式文本之间的逻辑关系进行梳理,构建出合乎情理的标准文本章节结构,因此,需要设计相应的网络,保证不同摘要式文本的顺序。目前亟待针对这两个问题,设计相应合理的深度学习网络框架,利用计算机处理能力对网络进行训练,可以获得标准文本章节结构生成模型,进而可以通过相应的网络从复杂的文本中,获得具有清晰逻辑的标准文本章节结构。
技术实现思路
1、为了解决上述现有技术的不足,本发明提供一种基于成果转换标准的整合制定方法,用深度学习网络框架设计相关模型,进而可以获得标准文本章节结构生成模型,生成具有清晰逻辑的标准文本章节结构,为后续的标准文本撰写打下务实的基础。
2、本发明的第一个目的在于提供一种基于成果转换标准的整合制定方法。
3、本发明的第二个目的在于提供一种基于成果转换标准的整合制定系统。
4、本发明的第三个目的在于提供一种计算机设备。
5、本发明的第四个目的在于提供一种存储介质。
6、本发明的第一个目的可以通过采取如下技术方案达到:
7、一种基于成果转换标准的整合制定方法,所述方法包括如下步骤:
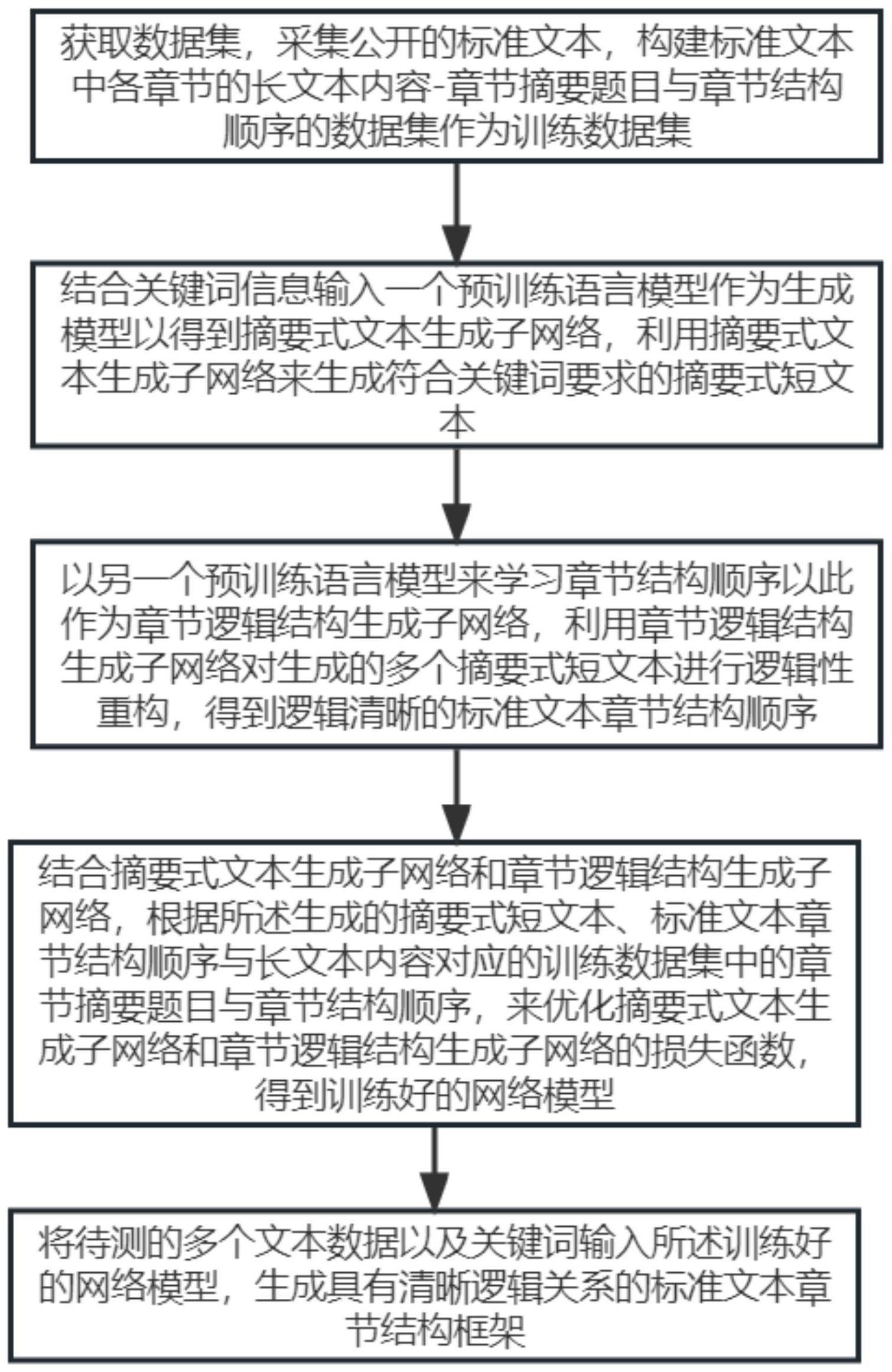
8、获取数据集,采集公开的标准文本,构建标准文本中各章节的长文本内容-章节摘要题目与章节结构顺序的数据集作为训练数据集;
9、结合关键词信息输入一个预训练语言模型作为生成模型以得到摘要式文本生成子网络,利用摘要式文本生成子网络来生成符合关键词要求的摘要式短文本;
10、以另一个预训练语言模型来学习章节结构顺序以此作为章节逻辑结构生成子网络,利用章节逻辑结构生成子网络对生成的多个摘要式短文本进行逻辑性重构,得到逻辑清晰的标准文本章节结构顺序;
11、结合摘要式文本生成子网络和章节逻辑结构生成子网络,根据所述生成的摘要式短文本、标准文本章节结构顺序与长文本内容对应的训练数据集中的章节摘要题目与章节结构顺序,来优化摘要式文本生成子网络和章节逻辑结构生成子网络的损失函数,得到训练好的网络模型;
12、将待测的多个文本数据以及关键词输入所述训练好的网络模型,生成具有清晰逻辑关系的标准文本章节结构框架。
13、进一步地,所述训练好的网络模型由摘要式文本生成子网络和章节逻辑结构生成子网络构成;摘要式文本生成子网络输出所述生成的多个摘要式短文本,其中,所述生成的多个摘要式短文本以多个预测词语的形式被序列化地输出,一个预测词语为一个字符串,摘要式文本生成子网络对各预测词语分别输出每个预测词语在生成过程中的预测的概率作为词语预测概率、以及统计该预测词语在训练数据集真实出现的概率作为词语真实概率;章节逻辑结构生成子网络将所述多个预测词语进行逻辑性重构,进行逻辑性重构即是章节逻辑结构生成子网络预测出所述多个预测词语对应需要的章节的数量,以一个章节在各个章节中的顺序按顺序作为一个节点,预测各个预测词语对应出现在各个节点中的概率作为章节预测概率、以及统计该预测词语在训练数据集真实出现在各节点对用顺序的概率作为章节真实概率;由此,所述训练好的网络模型输出所述多个预测词语。
14、进一步地,在得到所述训练好的网络模型后,当有不属于训练数据集的新的数据加入时,可以使用所述新的数据对所述训练好的网络模型进行微调,具体为:
15、根据加入的新的数据,所述训练好的网络模型再次进行优化,令训练好的网络模型输出多个预测词语,获取预测词语的词语预测概率记为pshort、词语真实概率记为pgtshort、章节预测概率记为prelate以及章节真实概率记为pgtrelate,设置损失函数为:
16、
17、其中,上标的ji和li表示进行遍历的序号:j表示预测词语的数量,其中的序号为ji;li表示章节的数量,其中的序号为li;由此遍历加入的新的数据中各预测词语对应各章节的词语预测概率、词语真实概率、章节预测概率以及章节真实概率;
18、通过优化所述损失函数,以基于梯度下降的优化算法进行微调,从而实现网络模型的收敛。
19、进一步地,可优选地,在得到所述训练好的网络模型后,当有不属于训练数据集的新的数据加入时,不使用上述进行微调的方法,还可以根据预测词语的词语预测概率、词语真实概率、章节预测概率以及章节真实概率,构建预测搜索平面,再在预测搜索平面上进行预测搜索,然后输出各预测词语,传输至客户端或保存至数据库,具体为:
20、根据加入的新的数据,所述训练好的网络模型再次进行优化,令训练好的网络模型输出多个预测词语,获取预测词语的词语预测概率、词语真实概率、章节预测概率以及章节真实概率,
21、预测词语向量对应的词语预测概率章节预测概率章节真实概率设所述训练好的网络模型输出j个预测词语且每个预测词语分别对应l个节点而有了l个章节预测概率和章节真实概率,把一个预测词语分别对应l个节点的l个章节预测概率和章节真实概率作为一个概率对照数组,一个概率对照数组中含有l个元素而每个元素为一个二元数组,每个二元数组为该概率对照数组对应的预测词语对应l个节点中的一个节点的章节预测概率和章节真实概率,将j个预测词语对应的概率对照数组分别作为j行,每行里面都有l个所述二元数组,其中,每行与其对应的预测词语保持对应关系,每行与其对应的预测词语的预测词语对应的词语预测概率、词语真实概率保留对应关系,把j个预测词语对应的概率对照数组组成一个j行l列的矩阵称为基础概率词平面记作bis,其中,行的序号为ji,有ji∈[1,j],列的序号为li,有li∈[1,l],第ji行对应的预测词语的对应的词语预测概率记为p(ji)s、词语真实概率记为p(ji)gts,第ji行第li列的二元数组中的章节预测概率记为p(ji,li)rel和章节真实概率p(ji,li)gtrel,由此,构建预测搜索平面:所述预测搜索平面同样为j行l列的矩阵,行的序号保持一致同样使用ji,列的序号保持一致同样使用li,记所述预测搜索词平面为vis,所述预测搜索词平面中第ji行第li列的元素的值记为vis(ji,li),计算vis(ji,li)需要先找到所述基础概率词平面中第ji行第li列的元素记作bis(ji,li),再获取所述bis(ji,li)在所述基础概率词平面中相邻的各元素,以所述相邻的各元素的预测词语向量对应的词语预测概率的算术平均值作为预测概率平均值p(ji)savg、并以其词语真实概率的算术平均值作为真实概率平均值p(ji)gtsavg,以所述相邻的各元素的章节预测概率的算术平均值作为p(ji,li)relavg,以所述相邻的各元素的章节真实概率的算术平均值作为p(ji,li)gtrelavg,则有vis(ji,li)的计算公式为:
22、vis(ji,li)=sqrt[|sin(π*p(ji)savg)*cos(π*p(ji)gtsavg)|*|sin(π*p(ji,li)relavg)*cos(π*p(ji,li)gtrelavg)|],
23、由此,称vis(ji,li)为所述预测搜索词平面中第ji行第li列的元素的预测搜索值;然后,在预测搜索平面vis上进行预测搜索;将输出的集合vset中的各预测词语作为网络模型的输出,传输至客户端或保存至数据库。
24、其中,还可以包括,将待测的多个长文本以及关键词输入所述训练好的网络模型,生成具有清晰逻辑关系的标准文本章节结构框架的方法,具体可包括:
25、使用人工交互的方法,获取需要处理的多个长文本以及关键词;
26、将所述多个长文本以及关键词输入所述训练好的网络模型,生成具有清晰逻辑关系的标准文本章节结构框架。
27、其中,还可以包括,获取训练数据集的方法,具体可包括:
28、获取当前的标准文本文档,按关键词、标准文本章节摘要题目、标准文本章节内容(长文本)进行分类;
29、将所述标准文本文档数据库中的标准文本章节提纲输入到现有的关系解析工具,得到标准文本章节顺序表示;
30、将所述标准文本章节内容(长文本)、关键词与所述标准文本章节顺序表示作为训练数据集的图像对,用于模型训练。
31、本发明的第二个目的可以通过采取如下技术方案达到:
32、一种基于成果转换标准的整合制定系统,所述一种基于成果转换标准的整合制定系统实现所述一种基于成果转换标准的整合制定方法中的各步骤,所述一种基于成果转换标准的整合制定系统可包括:
33、获取模块,用于获取数据集,采集公开的标准文本,构建标准文本中各章节的长文本内容-章节摘要题目与章节结构顺序的数据集作为训练数据集;
34、摘要式文本生成模块,用于结合关键词信息输入一个预训练语言模型作为生成模型以得到摘要式文本生成子网络,利用摘要式文本生成子网络来生成符合关键词要求的摘要式短文本;
35、章节逻辑结构生成模块,用于以另一个预训练语言模型来学习章节结构顺序以此作为章节逻辑结构生成子网络,利用章节逻辑结构生成子网络对生成的多个摘要式短文本进行逻辑性重构,得到逻辑清晰的标准文本章节结构顺序;
36、优化模块,用于结合摘要式文本生成子网络和章节逻辑结构生成子网络,根据所述生成的摘要式短文本、标准文本章节结构顺序与长文本内容对应的训练数据集中的章节摘要题目与章节结构顺序,来优化摘要式文本生成子网络和章节逻辑结构生成子网络的损失函数,得到训练好的网络模型;
37、生成模块,用于将待测的多个文本数据以及关键词输入所述训练好的网络模型,生成具有清晰逻辑关系的标准文本章节结构框架。
38、本发明的第三个目的可以通过采取如下技术方案达到:
39、一种计算机设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,可以实现上述的所述一种基于成果转换标准的整合制定系统中的生成模块中的具体方法。
40、本发明的第四个目的可以通过采取如下技术方案达到:
41、一种存储介质,存储有程序,所述程序被处理器执行时,可以实现上述的所述一种基于成果转换标准的整合制定系统中的生成模块中的具体方法。
42、其中,本发明中涉及到的未定义的变量,可优选地,在实施过程中皆可输入为人工定义或预先设置的阈值或具体数值。
43、本发明相对于现有技术具有如下的有益效果:
44、1、本发明将深度学习技术与注意力机制应用到网络模型的构建,用来生成具有清晰逻辑关系的标准文本章节结构框架。
45、2、本发明通过利用人工智能对网络模型中各个节点的信息表征进行特征处理,使到生成的摘要文本以及章节结构顺序更加贴合主题,并减少了数据的冗余。
46、3、本发明利用构建的网络模型,能够获得具有清晰逻辑关系的标准文本章节结构框架,为后续标准文本的撰写应用打下坚实基础。
- 还没有人留言评论。精彩留言会获得点赞!