机器阅读理解方法及其装置、电子设备及存储介质与流程
本发明涉及人工智能领域,具体而言,涉及一种机器阅读理解方法及其装置、电子设备及存储介质。
背景技术:
1、机器阅读理解是自然语言处理(nlp)中一项具有挑战性的任务,在智能问答、信息检索等领域有很好的应用前景。机器阅读理解旨在让机器学会根据相关文本内容自动回答相关问题,是自然语言理解(nlu)和强人工智能的重要基础。当前,根据答案的类型,可以将机器阅读理解任务分成完形填空、多项选择、区间提取和自由回答四种类型。由于存在比完形填空和多项选择模式更加贴合现实应用场景、比自由回答类型更容易评价的特性,区间提取式(span extraction)机器阅读理解已经成为最受欢迎的选择。给定段落和相关问题,机器需要提取段落中一段连续的文本区间作为答案。不局限于单词或实体,根据特定情况,答案可以是一个很长的句子。
2、预训练语言模型,如bert等,可以有效利用非标注数据进行模型训练,从而学习丰富的词向量表示。对于下游任务而言,不再需要从零开始训练一个模型,从大规模语料中得到的预训练模型在新的数据集上经过简单的“微调”就可以取得非常好的效果。预训练方法经过不断发展,出现了众多优秀模型,已经在机器阅读理解领域取得了成功。
3、相关技术中,基于预训练方法来完成机器阅读理解任务,其网络结构一般是预训练模型输出词向量表示后拼接全连接层,经过softmax(归一化指数函数)输出各个token(即字符)分别作为答案起止位置的概率分布。
4、图1是根据相关技术的一种可选的基于bert的区间式机器阅读理解方法的示意图,如图1所示,将question(问题)和paragraph(段落)输入至bert模型中,question在输入bert模型前可以处理为tok1…tokn,paragraph在输入bert模型前可以处理为tok1…tokm,并且在tok1…tokn前加上[cls]符号,在tok1…tokn和tok1…tokm之间加入[sep]符号,将[cls]tok1…tokn[sep]tok1…tokm的表征ecls e1…en esep e1‘…em′输入至bert模型中,输出c t1…tn tsep t1‘…tm′,然后通过softmax输出各个token分别作为答案起止位置的概率分布,例如,t1‘的作为s(起始位置)的概率为pstart1,作为e(终止位置)的概率为pend1;tm‘的作为s(起始位置)的概率为pstartm,作为e(终止位置)的概率为pendm。
5、然而,基于bert等预训练模型的机器阅读理解存在如下缺点:
6、(1)中英文预训练模型训练方式的差异。当前,中文预训练模型都是基于“字”训练得到,其输出的向量表示准确来说是字向量,而英文预训练模型都是基于词的,这对于答案区间获取有很大影响。例如:
7、the/capital/city/of/china/is/beijing;
8、中/国/的/首/都/是/北/京;
9、(2)忽略了临近词语之间的语义相关性,这对于机器阅读理解的答案区间定位至关重要。一个token是否属于答案起始词或结束词的范畴在一定程度上取决于它近邻词的语义,但相关技术中的预训练词向量表示直接经过全连接层输出起止位置概率的模式缺乏对近邻上下文的显式建模过程。例如,如果某一个token之后紧邻的位置是一个标点符号,那么该token作为答案起始位置的概率就会相对较低;如果某个单词在“坐落于”之后,那么它作为某“地点”类问题答案的起始位置概率就会相对较高。
10、如:
11、the palace museum is located atbeijing,which is completed in 1420;
12、故宫坐落于北京,在1420年建成;
13、(3)进一步提升预训练模型机器阅读理解下游任务效果困难。由于预训练模型本身强大的特征建模能力及巨大参数量,单独地在预训练模型之后继续叠加各种注意力网络层并不能显著提升实际效果。当前的提升方式主要来自于更大规模的预训练模型或外部数据知识的引入,实施起来耗时较长且难度较高。
14、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种机器阅读理解方法及其装置、电子设备及存储介质,以至少解决相关技术中无法整合相邻字符之间的语义相关性,导致机器阅读理解准确性较低的技术问题。
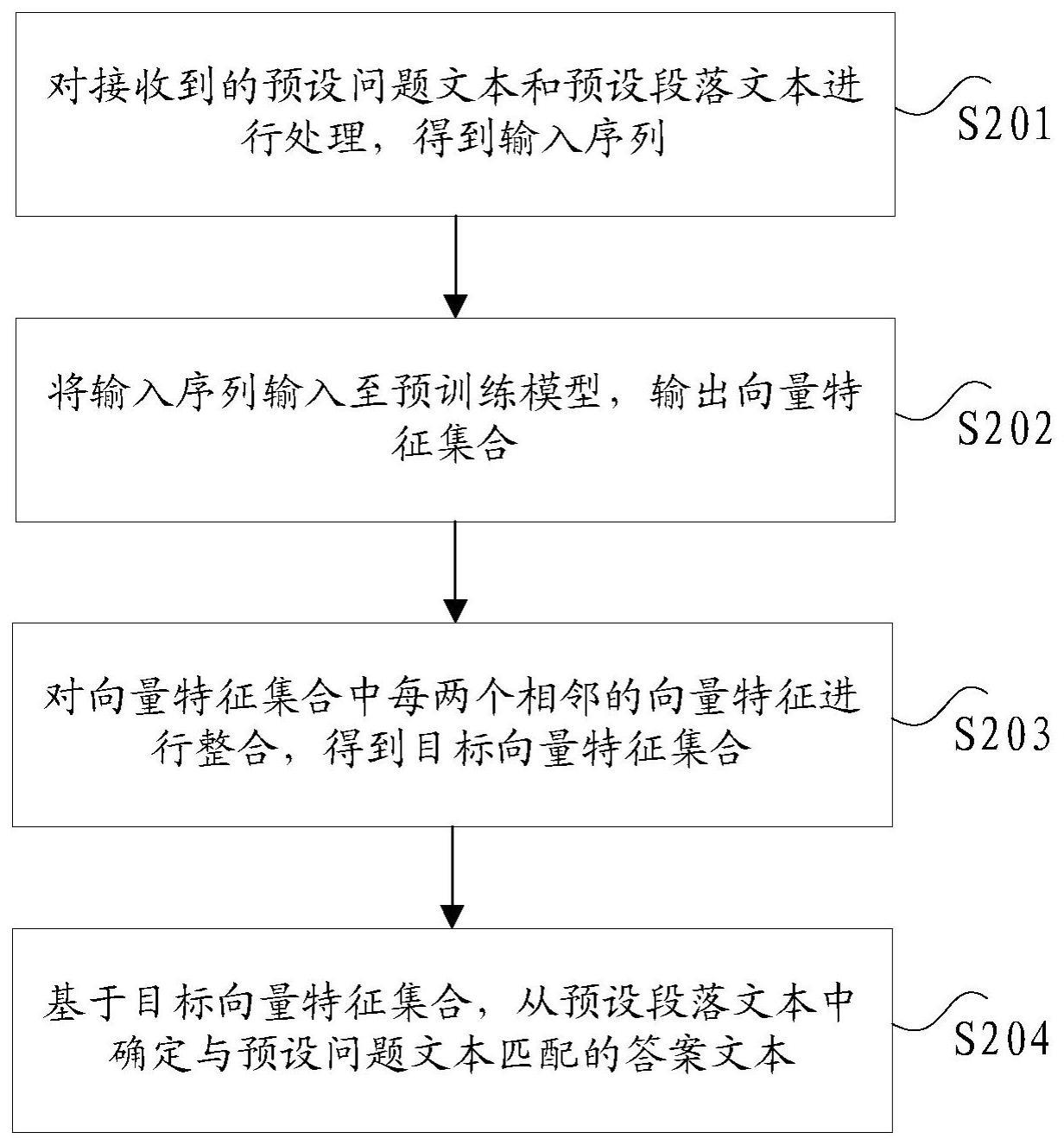
2、根据本发明实施例的一个方面,提供了一种机器阅读理解方法,包括:对接收到的预设问题文本和预设段落文本进行处理,得到输入序列,其中,所述输入序列包括:多个字符;将所述输入序列输入至预训练模型,输出向量特征集合,其中,所述向量特征集合包括多个向量特征,每个所述向量特征对应一个所述字符;对所述向量特征集合中每两个相邻的所述向量特征进行整合,得到目标向量特征集合;基于所述目标向量特征集合,从所述预设段落文本中确定与所述预设问题文本匹配的答案文本,其中,所述答案文本是所述预设段落文本中一段连续的文本。
3、可选地,对接收到的预设问题文本和预设段落文本进行处理,得到输入序列的步骤,包括:确定第一符号、第二符号以及第三符号,其中,所述第一符号是所述输入序列的开始符号,所述第二符号用于区分所述预设问题文本以及所述预设段落文本,所述第三符号用于区分所述预设段落文本以及预设补充文本,所述预设补充文本是增加的空白文本;将所述预设问题文本划分为多个问题字符,并将所述预设段落文本划分为多个段落字符;基于所述第一符号、所述第二符号、所述第三符号、所述问题字符以及所述段落字符,构建所述输入序列。
4、可选地,在得到输入序列之后,还包括:确定所述输入序列中每个所述字符的输入结构,其中,所述输入结构包括:字符语义编码、字符类型编码、位置编码;确定预设特征提取器的编码层数以及所述向量特征的向量长度。
5、可选地,将所述输入序列输入至预训练模型,输出向量特征集合的步骤,包括:将所述输入序列中每个所述字符的结构转换为所述输入结构;将转换后的所述输入序列输入至所述预训练模型;基于所述预训练模型,采用所述预设特征提取器对所述输入序列进行连续所述编码层数的编码,得到所述向量特征集合,其中,所述向量特征集合中每个所述向量特征的长度为所述向量长度。
6、可选地,对所述向量特征集合中每两个相邻的所述向量特征进行整合,得到目标向量特征集合的步骤,包括:对所述向量特征进行升维操作,得到升维向量特征;基于第一预设卷积核、第一预设步长以及第一预设补充类型,对每两个相邻的所述升维向量特征进行卷积,得到新增向量特征;基于第二预设卷积核、第二预设步长以及第二预设补充类型,确定所述新增向量特征的向量权重;基于所述升维向量特征、所述向量权重与所述新增向量特征之积,确定目标向量特征;基于所有所述目标向量特征,得到所述目标向量特征集合。
7、可选地,基于所述目标向量特征集合,从所述预设段落文本中确定与所述预设问题文本匹配的答案文本的步骤,包括:对所述目标向量特征集合中的每个所述目标向量特征进行降维操作,并将降维后的所述目标向量特征输入至预设输出层;采用所述预设输出层,计算所述目标向量特征的起始位置值和终止位置值;对所有所述起始位置值以及所有所述止位置值进行排序,得到排序结果;基于所述排序结果,确定满足预设位置条件的最大起始位置值以及最大终止位置值,其中,所述预设位置条件是起始位置位于终止位置之前的条件;基于所述最大起始位置值指示的目标起始位置以及所述最大终止位置值指示的目标终止位置,确定所述答案文本。
8、可选地,在将降维后的所述目标向量特征输入至预设输出层之前,还包括:基于第一损失参数以及真实起始位置对应的字符输出概率值,确定起始交叉熵损失;基于第二损失参数以及真实终止位置对应的字符输出概率值,确定终止交叉熵损失;基于所述起始交叉熵损失以及所述终止交叉熵损失,构建损失函数;基于所述损失函数,训练所述预设输出层。
9、根据本发明实施例的另一方面,还提供了一种机器阅读理解装置,包括:处理单元,用于对接收到的预设问题文本和预设段落文本进行处理,得到输入序列,其中,所述输入序列包括:多个字符;输出单元,用于将所述输入序列输入至预训练模型,输出向量特征集合,其中,所述向量特征集合包括多个向量特征,每个所述向量特征对应一个所述字符;整合单元,用于对所述向量特征集合中每两个相邻的所述向量特征进行整合,得到目标向量特征集合;确定单元,用于基于所述目标向量特征集合,从所述预设段落文本中确定与所述预设问题文本匹配的答案文本,其中,所述答案文本是所述预设段落文本中一段连续的文本。
10、可选地,所述处理单元包括:第一确定模块,用于确定第一符号、第二符号以及第三符号,其中,所述第一符号是所述输入序列的开始符号,所述第二符号用于区分所述预设问题文本以及所述预设段落文本,所述第三符号用于区分所述预设段落文本以及预设补充文本,所述预设补充文本是增加的空白文本;第一划分模块,用于将所述预设问题文本划分为多个问题字符,并将所述预设段落文本划分为多个段落字符;第一构建模块,用于基于所述第一符号、所述第二符号、所述第三符号、所述问题字符以及所述段落字符,构建所述输入序列。
11、可选地,所述机器阅读理解装置还包括:第二确定模块,用于在得到输入序列之后,确定所述输入序列中每个所述字符的输入结构,其中,所述输入结构包括:字符语义编码、字符类型编码、位置编码;第三确定模块,用于确定预设特征提取器的编码层数以及所述向量特征的向量长度。
12、可选地,所述输出单元包括:第一转换模块,用于将所述输入序列中每个所述字符的结构转换为所述输入结构;第一输入模块,用于将转换后的所述输入序列输入至所述预训练模型;第一编码模块,用于基于所述预训练模型,采用所述预设特征提取器对所述输入序列进行连续所述编码层数的编码,得到所述向量特征集合,其中,所述向量特征集合中每个所述向量特征的长度为所述向量长度。
13、可选地,所述整合单元包括:第一升维模块,用于对所述向量特征进行升维操作,得到升维向量特征;第一卷积模块,用于基于第一预设卷积核、第一预设步长以及第一预设补充类型,对每两个相邻的所述升维向量特征进行卷积,得到新增向量特征;第四确定模块,用于基于第二预设卷积核、第二预设步长以及第二预设补充类型,确定所述新增向量特征的向量权重;第五确定模块,用于基于所述升维向量特征、所述向量权重与所述新增向量特征之积,确定目标向量特征;第一输出模块,用于基于所有所述目标向量特征,得到所述目标向量特征集合。
14、可选地,所述确定单元包括:第一降维模块,用于对所述目标向量特征集合中的每个所述目标向量特征进行降维操作,并将降维后的所述目标向量特征输入至预设输出层;第一计算模块,用于采用所述预设输出层,计算所述目标向量特征的起始位置值和终止位置值;第一排序模块,用于对所有所述起始位置值以及所有所述止位置值进行排序,得到排序结果;第六确定模块,用于基于所述排序结果,确定满足预设位置条件的最大起始位置值以及最大终止位置值,其中,所述预设位置条件是起始位置位于终止位置之前的条件;第七确定模块,用于基于所述最大起始位置值指示的目标起始位置以及所述最大终止位置值指示的目标终止位置,确定所述答案文本。
15、可选地,所述机器阅读理解装置还包括:第八确定模块,用于在将降维后的所述目标向量特征输入至预设输出层之前,基于第一损失参数以及真实起始位置对应的字符输出概率值,确定起始交叉熵损失;第九确定模块,用于基于第二损失参数以及真实终止位置对应的字符输出概率值,确定终止交叉熵损失;第二构建模块,用于基于所述起始交叉熵损失以及所述终止交叉熵损失,构建损失函数;第一训练模块,用于基于所述损失函数,训练所述预设输出层。
16、根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述机器阅读理解方法。
17、根据本发明实施例的另一方面,还提供了一种电子设备,包括一个或多个处理器和存储器,所述存储器用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述机器阅读理解方法。
18、在本公开中,对接收到的预设问题文本和预设段落文本进行处理,得到输入序列,将输入序列输入至预训练模型,输出向量特征集合,对向量特征集合中每两个相邻的向量特征进行整合,得到目标向量特征集合,基于目标向量特征集合,从预设段落文本中确定与预设问题文本匹配的答案文本。在本公开中,可以先对预设问题文本和预设段落文本进行处理,然后将得到的输入序列输入至预训练模型中,之后对输出的向量特征集合中每两个相邻的向量特征进行整合,以得到目标向量特征集合,再根据目标向量特征集合从预设段落文本中确定与预设问题文本匹配的答案文本,通过整合相邻字符之间的相关信息,能够提升机器阅读理解水平,得到更加准确的答案,进而解决了相关技术中无法整合相邻字符之间的语义相关性,导致机器阅读理解准确性较低的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!