一种基于视觉Transformer的多细粒度遮挡行人重识别方法
本发明属于行人重识别领域,更为具体地讲,是一种基于视觉transformer的多细粒度遮挡行人重识别方法。
背景技术:
1、近年来,随着万物互联的发展,身份识别技术迎来蓬勃发展。除了熟知的用于访问控制、手机解锁等应用的人脸识别场景,在很多大场景下诸如大型超市,大型娱乐场所,大型交通等,现有的摄像设备难以捕捉到清晰的人脸的图像,因此基于行人图像的行人重识别技术(reid)广泛应用于大型视野场景。目前现有的大多数行人重识别技术都基于单个完整的行人图像(图1(a)所示),但是在实际应用场景中,多数行人存在不同程度的遮挡(图1(b)所示),基于完整的单个行人图像的方法则会因为图像特征的缺失而失效。
2、为解决上述问题,本发明提出一种基于视觉transformer的多细粒度遮挡行人重识别方法。这是一个包含视觉transformer为骨干网络的多分支网络结构,包含一个全局分支和三个局部分支。在多分支架构的设计中,我们在通道注意力和空间注意力的基础上,通过联合交互不同细粒度分支的特征信息,设计了跨分支注意力模块,以此来强化各个分支之间的相互关系,调和在不同遮挡程度上,全局分支和局部分支的重要关系。在骨干网络视觉transformer的设计中,提出特征增强模块,其不仅能够获取到transformer的全局感知信息,也能综合卷积操作的局部感受野,实现对图像全局特征和局部特征的把控,弥补图像中行人被不同程度遮挡带来的特征缺失问题。通过特征增强模块和跨分支注意力模块,我们的模型能够更好的适应遮挡行人重识别场景。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于视觉transformer的多细粒度遮挡行人重识别方法,利用单帧图像中行人的全局特征和局部特征信息相结合,弥补行人遮挡状态下的特征缺失导致的难以识别的问题,提升深度学习模型在遮挡行人重识别场景下的精度。
2、为实现上述发明目的,本文发明一种基于视觉transformer的多细粒度遮挡行人重识别方法,包括以下步骤:
3、步骤1:获取用于骨干网络预训练的imagenet数据集,以及用于行人重识别的market-1501、msmt17和用于遮挡行人重识别的occluded-dukemtmc数据集。
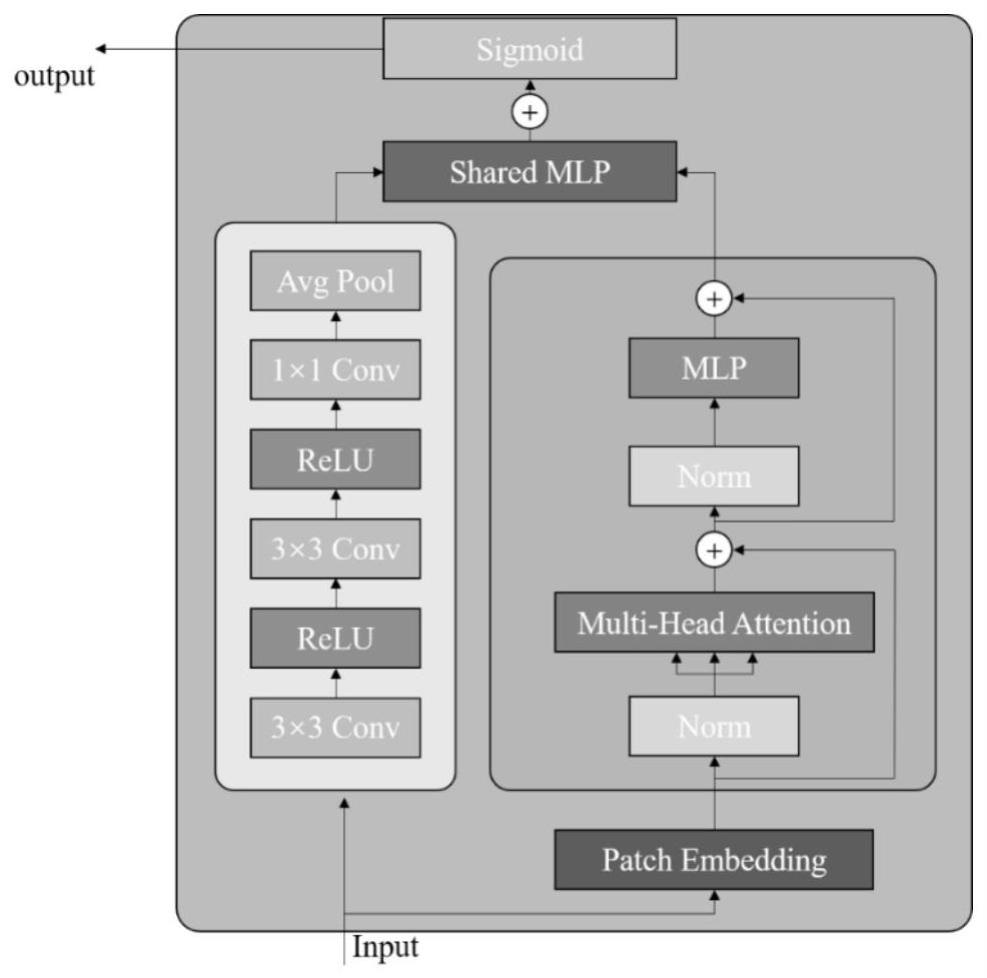
4、步骤2:构建提取特征的视觉transformer骨干网络,其包含设计的特征增强模块,在一个特征增强模块中包含卷积操作和激活函数堆叠的卷积层以及由多头自注意力机制和前馈神经网络组成的former层,其具体步骤如下:
5、步骤2-1:将输入的数据过两个分支网络,其中一个分支为卷积层,另一个分支为多头自注意力机制和前馈神经网络组成的former层;
6、步骤2-2:对于经过former层的数据,首先通过patchembedding操作将输入的行人数据进行分块,考虑到分块尺寸和行人图像的特征,我们将图像缩放为256×128大小,按照最大10%的重叠操作并设置图像的patch尺寸为16×16,如图2所示,然后将每个patch展平后按照batch方向合并,将图像实现向量化。此时通道维度会变成原先的6倍(因为h,w各缩小2,3倍),此时再通过一个全连接层再调整通道维度为原来的两倍。;
7、步骤2-3:将patchembedding的输出经过layernorm层实现层归一化;
8、步骤2-4:构建q、k、v三个线性层,将layernorm的输出进行多头自注意力机制计算,将计算的结果过dropout层输出。将输出的结果与layernorm的输出相加得到多头自注意力计算后的特征;
9、步骤2-5:将多头自注意力计算后的特征依次通过layernorm层,mlp层。mlp是一个级联的二层线性层,通过投影的方式将输入维度扩增为原来的四倍再缩放回去,最后将mlp的输出和layernorm的输入相加得到former层的输出特征;
10、步骤2-6:对于经过卷积层的数据,首先通过连续的两个3×3卷积和relu激活函数对输入图像进行特征提取;
11、步骤2-7:将提取的特征过1×1卷积,调整输出特征的通道数,使其保持与former层的输出通道相同;
12、步骤2-8:通过均值池化操作调整输出特征的宽高,使其与former层输出尺寸相同;
13、步骤2-9:将former层的输出和卷积层的输出过shared mlp层,shared mlp层由2层级联的3×3卷积和一个relu激活函数组成,其目的是通过计算通道注意力融合former层和卷积层的输出特征;
14、步骤2-10:将shared mlp层输出的两个特征进行elementwise add后通过sigmoid激活函数得到最终的输出;
15、步骤3:骨干网络构建,将本发明提出的特征增强模块作为基础的transformerencoder块,通过添加class token和位置编码构建完成的骨干网络,其具体步骤如下:
16、步骤3-1:通过patchembedding将图像划分成均匀大小的patch,然后通过一个线性层将patch投射成向量;
17、步骤3-2:构建class token可训练参数,采用kaimingnormal的方式进行初始化,其维度与patchembedding输出向量维度一致;
18、步骤3-3:构建位置编码参数,采用kaimingnormal的方式进行初始化,主要用于计算各个patch之间的相互关系;
19、步骤3-4:构建transformerencoder模块,它由多个特征增强模块堆叠而成;
20、步骤3-5:构建具有1000个类别的分类头以及用于分类的损失函数softmax,完成整个用于提取特征的骨干网络构建;
21、步骤4:对于imagenet中所有的训练样本集,统一进行随机翻转,随机亮度增强,随机通道交换数据增强,设置迭代次数为300,batch-size为256,warm-up学习率为0.001,初始学习率为0.0001,经过300次迭代训练,损失值与精度趋于稳定,保存此时的最佳参数模型,作为身份重识别任务的预训练模型。
22、步骤5:在骨干网络下游任务构建细粒度分支和跨分支注意力模块,其含一个全局分支和三个局部分支,跨分支注意力模块能够强化各个分支之间的相互关系,调和在不同遮挡程度上,全局分支和局部分支的重要关系。其具体步骤如下:
23、步骤5-1:通过骨干网络,我们得到四个输出特征分支,其包含三个局部分支,分别是局部上游分支、局部中游分支以及局部下游分支,三个局部分支分别对应着patchembedding层对输入图像从上而下的分块。此外,输出一个全局分支,用于提取图像全局特征;
24、步骤5-2:跨分支注意力模块包含两个设计的注意力计算模块,每个模块由两个线性层,一个1x1卷积层调控输出通道数和一个layernorm层;
25、步骤5-3:不同的遮挡程度会导致不同局部分支提取到不同重要程度的特征信息,为了弥补遮挡条件下的特征信息损失,需要强化未遮挡部分的特征信息,因此我们通过计算不同局部分支的注意力来分配不同局部分支的特征信息重要程度;
26、步骤5-4:计算全局分支和不同局部分支的注意力,调和不同分支特征信息的重要程度,将最终结果作为多分支结构输出;
27、步骤6:构建身份重识别模型训练损失函数,其包含用于分类的损失函数和用于计算特征距离的损失函数,具体步骤如下:
28、步骤6-1:将四路输出特征接全局最大池化和1×1卷积,将最终特征输入进分类学习和度量学习;
29、步骤6-2:构建softmax损失函数作为分类部分损失函数,将三个局部分支的输出结果拼接后馈入分类部分;
30、步骤6-3:构建triplet损失函数作为度量学习部分损失函数,将全局分支的输出结果拼接后馈入分类部分;
31、步骤6-4:加载由imagenet训练的预训练权重,利用market-1501,msmt17数据集进行行人重识别预训练,其目的是让多分支模型结构适应身份重识别任务,并使用遮挡行人数据集occluded-duke作为微调,增强模型在遮挡行人上的识别效果;
32、步骤7:对于occluded-dukemtmc中所有的训练样本集,统一进行随机翻转,并将尺寸统一缩放到128×256,设置迭代次数为160,batch-size为64,warm-up学习率为0.001,初始学习率为0.0001,经过300次迭代训练,损失值与精度趋于稳定,保存此时的最佳参数模型。
33、步骤8:对于occluded-dukemtmc所有的测试样本集,进行批量测试,输入图片分辨率大小为128×256,计算其平均精度map以及rank1进行评估。
34、本文发明一种基于视觉transformer的多细粒度遮挡行人重识别方法。通过构建跨分支注意力模块,来强化各个分支之间的相互关系,调和在不同遮挡程度上,全局分支和局部分支的重要关系。通过提出特征增强模块,综合transformer的全局感知信息以及卷积操作的局部感受野,实现对图像全局特征和局部特征的把控,弥补图像中行人被不同程度遮挡带来的特征缺失问题。
- 还没有人留言评论。精彩留言会获得点赞!