一种协同制导律模型的预训练方法、训练方法和系统
本技术涉及控制的,尤其是涉及一种协同制导律模型的预训练方法、训练方法和系统。
背景技术:
1、无人机在对抗的过程中,需要根据敌机的位置、状态和策略,不断调整自己的行动策略,使能按一定的路径或轨迹准确打击到敌方。当多个无人机对抗或发射多个导弹时,需要共同合作完成对目标的追踪和打击。可以通过多弹时间协同制导律,即以主弹引导,从弹跟踪的方式,引入剩余时间协同补偿指令,实现所有从弹跟随主动对目标的时间协同攻击。
2、相关技术中,直接利用经验池中的样本进行神经网络训练,但是训练过程需要大量的数据,在线的模型训练耗时较长。
技术实现思路
1、本技术目的是提供一种协同制导律模型的预训练方法、训练方法和系统,能够提高训练效率。
2、本技术的上述申请目的一是通过以下技术方案得以实现的:
3、第一方面,提供了一种协同制导律模型的预训练方法,包括:
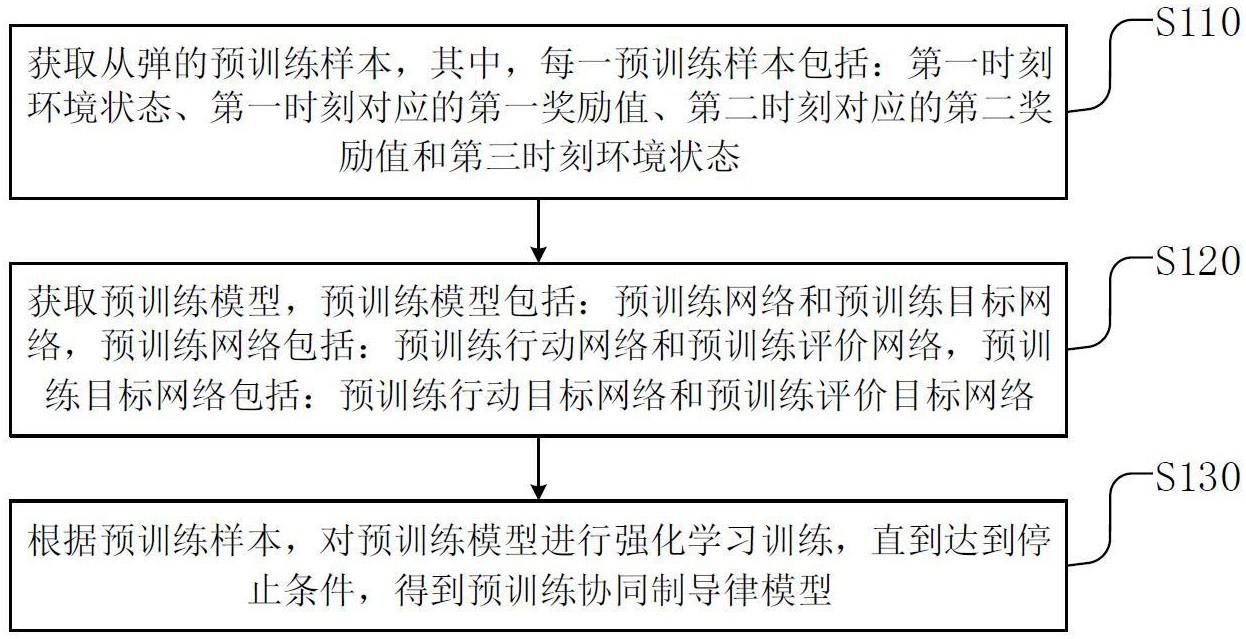
4、获取从弹的预训练样本,其中,每一预训练样本包括:第一时刻环境状态、第一时刻对应的第一奖励值、第二时刻对应的第二奖励值和第三时刻环境状态;
5、获取预训练模型,所述预训练模型包括:所述预训练网络和预训练目标网络,所述预训练网络包括:预训练行动网络和预训练评价网络,所述预训练目标网络包括:预训练行动目标网络和预训练评价目标网络;
6、根据所述预训练样本,对所述预训练模型进行强化学习训练,直到达到停止条件,得到预训练协同制导律模型,
7、所述预训练协同制导律模型中的预训练评价网络的网络参数和预训练评价目标网络的网络参数作为协同制导律模型训练过程中的待训练评价网络的初始网络参数和待训练评价目标的初始网络参数。
8、在一种可能的实现方式中,所述获取从弹的预训练样本,包括:
9、获取第一时刻环境状态,根据所述第一时刻环境状态利用协同制导律得到第一时刻对应的动作值;
10、根据所述第一时刻对应的动作值,通过训练环境进行仿真,得到第二时刻环境状态和第一时刻对应的奖励值;
11、根据所述第二时刻环境状态和协同制导律,得到第二时刻对应的第二动作值;根据所述第二时刻对应的动作值通过训练环境进行仿真,得到第三时刻环境状态和第二时刻对应的第二奖励值。
12、在一种可能的实现方式中,所述根据所述第一时刻对应的动作值,通过训练环境进行仿真,得到第二时刻环境状态和第一时刻对应的奖励值,包括:
13、根据所述第一时刻对应的动作值通过训练环境进行仿真,得到第二时刻环境状态;
14、根据所述第二时刻环境状态确定第二时刻下导弹对应的前置角、导弹与目标的相对距离和导弹和目标的相对速度,导弹包括主弹和从弹;
15、当导弹命中时,根据主弹命中时刻和从弹命中时刻确定所述第一时刻对应的第一奖励值;
16、当导弹未命中时,根据导弹对应的前置角、导弹与目标的相对距离和导弹和目标的相对速度,确定主弹对应的预测命中时刻和从弹对应的预测命中时刻;并根据主弹对应的预测命中时刻和从弹对应的预测命中时刻,确定所述第一时刻对应的第一奖励值。
17、在一种可能的实现方式中,所述根据所述预训练样本,对所述预训练模型进行强化学习训练,直到达到停止条件,得到预训练协同制导律模型,包括:
18、根据所述第一时刻环境状态和预训练网络,得到评价值;
19、根据所述第三时刻环境状态利用预训练目标网络,得到初始评价目标值;
20、根据所述初始评价目标值、所述第一奖励值和所述第二奖励值,确定评价目标值;
21、根据所述评价目标值、所述评价值和预训练样本对预训练模型进行迭代训练,直至达到停止条件得到预训练协同制导律模型。
22、在一种可能的实现方式中,所述根据所述初始评价目标值、所述第一奖励值和所述第二奖励值,确定评价目标值,包括:
23、根据所述初始评价目标值、衰减折扣系数和所述第二奖励值,确定中间评价目标值;
24、根据所述中间评价目标值、所述衰减折扣系数和所述第一奖励值,确定所述评价目标值。
25、在一种可能的实现方式中,所述根据所述评价目标值、所述评价值和预训练样本对预训练模型进行迭代训练,直至达到停止条件得到预训练协同制导律模型,包括:
26、在完成预设数量的样本的预训练模型的计算后,根据预设数量的样本对应的所述评价目标值、所述评价值,确定评价网络参数,并根据所述评价网络参数更新预训练评价网络;
27、当预训练评价网络更新第一预设周期后,根据第一预设周期后确定的评价网络参数更新预训练评价目标网络;
28、根据更新后的预训练评价网络对预训练行动网络进行策略梯度计算,得到动作损失值,并根据所述动作损失值更新预训练行动网络的网络参数;
29、当预训练行动网络更新第二预设周期后,根据第二预设周期后确定的动作损失值更新预训练行动目标网络的网络参数;
30、进行迭代训练,直至达到停止条件得到预训练协同制导律模型。
31、在一种可能的实现方式中,所述预训练样本还包括:第一时刻对应的动作值,
32、所述根据更新后的预训练评价网络对预训练行动网络进行策略梯度计算,得到动作损失值,包括:
33、对第一时刻对应的动作值进行评价得到第一时刻对应的离线专家评价值;
34、根据所述离线专家评价值和第一时刻对应的评价值,确定修正值;
35、其中,当第一时刻对应的离线专家评价值大于第一时刻对应的评价值时,所述修正值为第一时刻对应的动作值和第一时刻对应的预测动作值的二范数,否则,所述修正值为0;所述第一时刻对应的预测动作值是根据所述第一时刻环境状态和预训练行动网络得到的,
36、根据所述修正值、更新后的预训练评价网络对预训练行动网络进行策略梯度计算,得到动作损失值。
37、第二方面,本技术提供一种协同制导律模型的训练方法,包括:
38、获取多个训练样本,其中,每一训练样本包括:第一时刻环境状态、第一时刻对应的第一奖励值、第二时刻对应的第二奖励值第三时刻环境状态;
39、根据所述多个训练样本,对待训练模型进行迭代强化学习训练,得到协同制导律模型;
40、其中,所述待训练模型包括待训练网络和待训练目标网络,所述待训练网络中的待训练评价网络和所述待训练目标网络的待训练目标评价网络的初始参数均为预训练协同制导律模型中的对应参数,所述预训练协同制导律模型是根据多个预训练样本进行强化学习训练得到的。
41、第三方面,提供了一种协同制导律模型的预训练系统,包括:
42、第一获取模块,用于获取从弹的预训练样本,其中,每一预训练样本包括:第一时刻环境状态、第一时刻对应的第一奖励值、第二时刻对应的第二奖励值和第三时刻环境状态;
43、第二获取模块,用于获取预训练模型,所述预训练模型包括:所述预训练网络和预训练目标网络,所述预训练网络包括:预训练行动网络和预训练评价网络,所述预训练目标网络包括:预训练行动目标网络和预训练评价目标网络;
44、第一训练模块,用于根据所述预训练样本,对所述预训练模型进行强化学习训练,直到达到停止条件,得到预训练协同制导律模型,
45、所述预训练协同制导律模型中的预训练评价网络的网络参数和预训练评价目标网络的网络参数作为协同制导律模型训练过程中的待训练评价网络的初始网络参数和待训练评价目标的初始网络参数。
46、第四方面,提供了一种协同制导律模型的训练系统,包括:
47、第三获取模块,用于获取多个训练样本,其中,每一训练样本包括:第一时刻环境状态、第一时刻对应的第一奖励值、第二时刻对应的第二奖励值第三时刻环境状态;
48、第二训练模块,用于根据所述多个训练样本,对待训练模型进行迭代强化学习训练,得到协同制导律模型;
49、其中,所述待训练模型包括待训练网络和待训练目标网络,所述待训练网络中的待训练评价网络和所述待训练目标网络的待训练目标评价网络的初始参数均为预训练协同制导律模型中的对应参数,所述预训练协同制导律模型是根据多个预训练样本进行强化学习训练得到的。
50、第五方面,提供了一种电子设备,包括:
51、一个或多个处理器;
52、存储器;
53、一个或多个应用程序,其中一个或多个应用程序被存储在存储器中并被配置为由一个或多个处理器执行,一个或多个程序配置用于:执行根据第一方面任一可能的实现方式所示的方法对应的操作。
54、第六方面,提供了另一种电子设备,包括:
55、一个或多个处理器;
56、存储器;
57、一个或多个应用程序,其中一个或多个应用程序被存储在存储器中并被配置为由一个或多个处理器执行,一个或多个程序配置用于:执行根据第二方面所示的方法对应的操作。
58、第七方面,提供了一种计算机可读存储介质,存储介质存储有至少一条指令、至少一段程序、代码集或指令集,至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行以实现如第一方面中任一可能的实现方式所示的方法。
59、第八方面,提供了一种计算机可读存储介质,存储介质存储有至少一条指令、至少一段程序、代码集或指令集,至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行以实现如第二方面所示的方法。
60、综上所述,本技术包括以下至少一种有益技术效果:
61、本方案获取从弹的预训练样本和预训练模型,进而基于预训练样本对预训练模型进行离线的强化学习训练以得到预训练协同制导律模型,并将该预训练协同制导律模型中的预训练评价网络的网络参数和预训练评价目标网络的网络参数作为协同制导律模型训练过程中的待训练评价网络的初始网络参数和待训练评价目标的初始网络参数,能够简化实际训练的过程,提高训练效率,快速高效的得到协同制导律模型。
- 还没有人留言评论。精彩留言会获得点赞!