基于主动领域适应学习的地质建模方法、系统及介质
本发明涉及地质信息解释,具体涉及一种基于主动领域适应学习的地质建模方法、系统及介质。
背景技术:
1、地质建模是一门综合学科,涉及地质学、数据分析、信息分析和计算科学,它基于对地质、测井、地球物理资料以及各种解释结果或概念模型的综合分析,利用计算机图形技术生成三维定量模型。以测井解释为例,在地质建模中,钻孔几乎是直接探索地下表面的唯一方法,因为我们可以观察到钻孔岩屑和岩芯。未损坏的岩心为地层的形成提供了丰富的信息,但由于取心成本高昂且耗时,无法获得完整连续的岩心序列。与岩心直接观测井眼地质相比,测井可以连续、高分辨率地记录井眼物探参数(如声波、电阻率等),间接反映地层性质。因此,将稀缺但直接的岩心数据与间接但连续的地球物理测井数据相结合,建立完整而精细的井眼地质模型成为地质工作者的重要任务。
2、在地质建模中,基于机器学习的测井解释已经广泛研究。然而,大多数研究都基于独立同分布(iid)的假设,即训练数据集和测试数据集之间的概率分布不存在差异。一般情况下,训练数据集可以由单口井组成,也可以将多口井的数据合并而成。因此,我们通常可以假设获得一个具有丰富甚至完整标签的训练数据集。然而,不同井的钻井条件、测井设备等存在差异,导致有标记的训练数据集与少标记(或几乎没有标记)的测试数据集之间存在不可忽略的概率分布差异。因此,在实践中,基于机器学习的建模应该研究非iid问题。
3、为了解决这个问题,主动领域适应方法可以被引入。主动领域适应学习通过结合主动学习和领域适应技术,旨在充分利用源域(训练数据)的模型参数,以提高在目标域(测试数据)上的学习性能。在地质建模中,这意味着通过主动学习方法选择有意义的训练地质样本,同时采用领域适应技术来调整模型以适应目标域的特点。通过主动领域适应方法,可以更好地解决地质建模中源域与目标域数据分布不一致的问题,提高模型的泛化能力和适应性。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于主动领域适应学习的地质建模方法、系统及介质。
2、为解决上述技术问题,本发明采用如下技术方案:
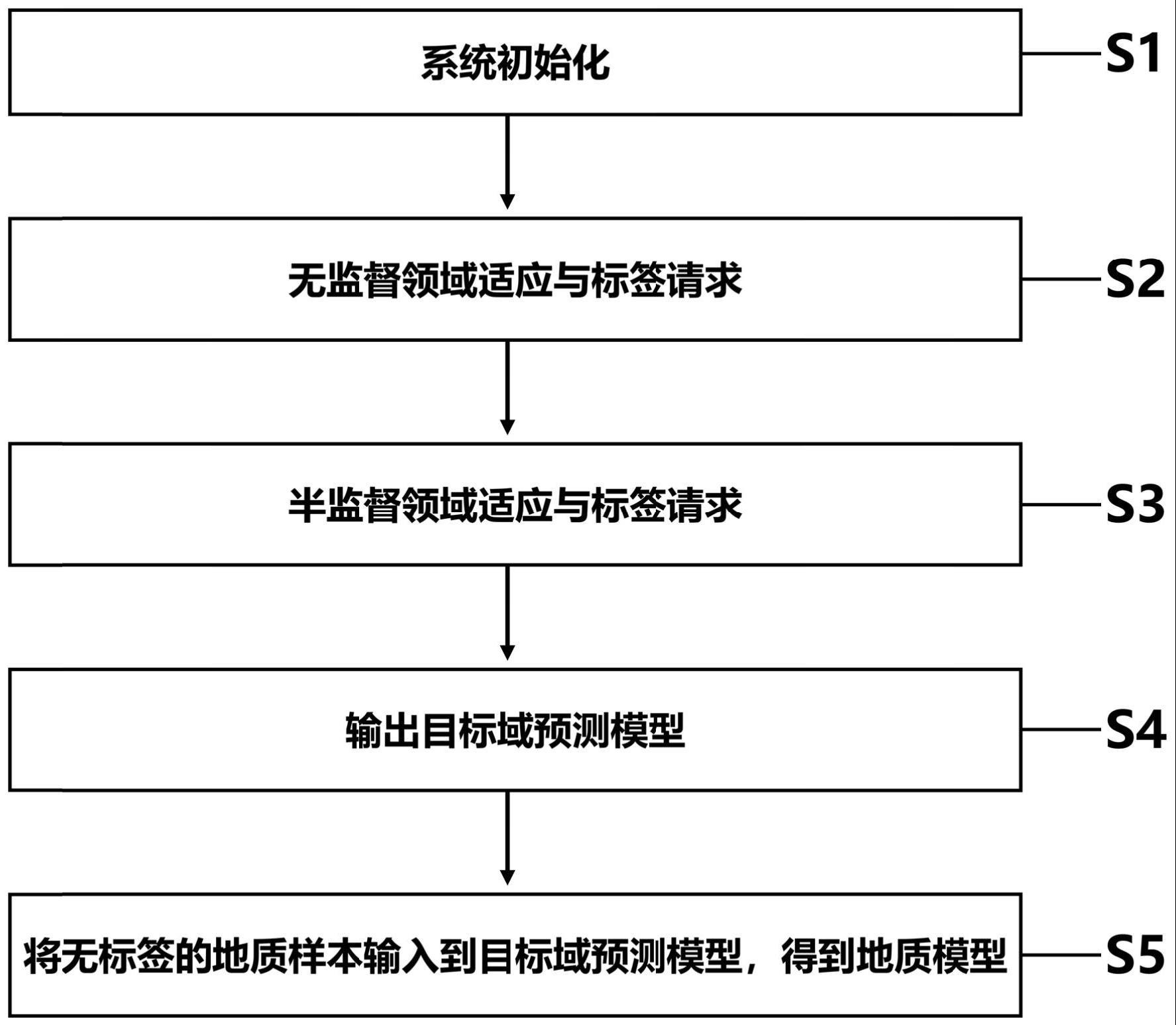
3、一种基于主动领域适应学习的地质建模方法,根据目标域无标签的地质样本对源域预测模型进行调整,得到目标域预测模型,并通过目标域预测模型得到地质模型;其特征在于,包括以下步骤:
4、步骤一、系统初始化:预测模型为f(x)=φ(x)ω,源域预测模型为f0(x)=φ(x)ω0,表示地质样本,表示实数域,d为地质样本的原始维度,地质样本x的标签记为为输出权重矩阵,ω0为源域的输出权重矩阵;为高维映射函数,将地质样本映射到高维特征空间;τ为映射后地质样本的维度,c为地质信息的类别数量;目标域地质样本集为n为中地质样本的数量,xi表示中第i个地质样本;通过目标域的地质样本求解图拉普拉斯矩阵候选集合为目标域的第i个图拉普拉斯矩阵,m为图拉普拉斯矩阵候选集合中的元素数量;
5、步骤二、无监督领域适应:通过图拉普拉斯矩阵对无标签的目标域地质样本进行一次无监督领域适应,求解优化问题,得到调整后的输出权重矩阵ω*;
6、步骤三、标签请求:根据所述输出权重矩阵ω*计算目标域地质样本的伪标签在目标域地质样本集选取a个地质样本的请求标签,更新标签矩阵y;
7、步骤四、半监督领域适应:令输出权重矩阵为最新得到的ω*,使用标签矩阵y对进行更新,求解优化问题,得到调整后的输出权重矩阵集合为输出权重矩阵集合中的第i个调整后的输出权重矩阵,r为输出权重矩阵集合中的元素数量;
8、步骤五、二次标签请求:根据所述权重矩阵集合从除步骤三选取过的地质样本外的目标域地质样本集中选取不确定性最高的a个地质样本请求标签,更新标签矩阵
9、步骤六、如果没达到标签请求最大数量,则将值赋予ω*,并跳至步骤四;如果达到标签请求最大数量,则将值赋予跳至步骤七;
10、步骤七、输出目标域预测模型:输出目标域预测模型模型调整完毕;
11、步骤八、将无标签的地质样本x*输入到目标域预测模型,得到无标签地质样本的预测结果,即得到地质模型。
12、进一步地,步骤一中求解图拉普拉斯矩阵候选集合时,具体包括:
13、图拉普拉斯矩阵li由相似矩阵计算得到,相似矩阵a的第i行第j列元素ai,j为:
14、
15、其中,表示xj的κ个最近邻的集合,通过人工设置不同κ值,得到m个不同的图拉普拉斯矩阵,组成图拉普拉斯矩阵候选集合
16、进一步地,步骤一中,所述优化问题如下:
17、
18、
19、其中,γ1,γ2,γ3分别为人工设定的用以平衡先验分布约束项、特征空间平滑约束项、模型调整约束项的平衡系数,高维映射函数集合为用以计算协方差矩阵的中心矩阵,为全1向量,为人工设定目标域先验分布的均值,为协方差,f表示f范数,上标t表示转置,tr(·)用于度量不确定性;
20、所述优化问题的求解步骤包括:
21、令集合固定μ,求解并令等于0,求得ω的解析解;
22、固定ω,采用序列最小优化算法求解μ;
23、多次迭代得到最优的输出权重矩阵ω*。
24、进一步地,步骤三具体包括:
25、根据所述输出权重矩阵ω*计算目标域地质样本的伪标签φ为高维映射函数;
26、从每类中分别选取预测概率最低的a个地质样本请求标签,得到标签矩阵y对应到φ,y的行对应φ相应行的标签,φ的行向量表示某个映射后地质样本,如果映射后地质样本没有标签,则y对应行向量置零。
27、进一步地,所述优化问题如下:
28、
29、
30、其中,λ1,λ2,λ3分别为用以平衡模型调整约束项,子模型差异度量项,特征空间、深度域平滑约束项的平衡系数,r为子模型数量;为地质样本加权对角阵;ωi表示第i个输出权重矩阵;f表示f范数;tr(·)用于度量不确定性;
31、所述优化问题求解步骤包括:
32、令集合固定μ,求解并令等于0,求得ω1的解析解;
33、固定ω1并采用smo算法求解μ;
34、固定ω1和μ,采用交叉优化算法,在固定中除ω1以外的输出权重矩阵的同时,分别求解并令等于0,依次求得的解析解;
35、多次迭代上述ω1到μ再到的求解过程,得到调整后的输出权重矩阵集合
36、进一步地,所述二次标签请求包括:
37、将输出权重矩阵集合中作为目标域的输出权重矩阵,并将的值赋予计算得到目标域由第2至r子模型输出的预测矩阵;表示第i个子模型预测结果;
38、将的所有第j行向量取出来,合并得到目标域的第j个地质样本的子模型预测结果矩阵fj的方差矩阵为采用tr(ξj)度量第j个地质样本的不确定性;
39、从除步骤三选取过的地质样本外的目标域地质样本集中选取不确定性最高的a个地质样本请求标签,更新标签矩阵
40、进一步地,如果地质样本为测井数据样本,则测井数据样本x为由同一深度上的测井值sp、gr、ac、r25、cond组成的向量,d为测井总数;测井数据样本的标签为需要解释的地质信息,如果需要解释岩性,则c为岩性总数,y为独热编码,如果需要解释物性,则
41、进一步地,如果地质样本为地震属性数据样本,则地震属性数据样本x为由同一方位上的地震属性值组成的向量,d为地震属性总数,地震属性数据样的标签为需要解释的地质信息,如果需要解释岩性,则c为岩性总数,y为独热编码,如果需要解释物性,则
42、一种基于主动领域适应学习的地质建模系统,根据目标域无标签的地质样本对源域预测模型进行调整,得到目标域预测模型,并通过目标域预测模型得到地质模型;包括:
43、系统初始化模块:预测模型为f(x)=φ(x)ω,源域预测模型为f0(x)=φ(x)ω0,表示地质样本,表示实数域,d为地质样本的原始维度,表示地质样本x的标签,为输出权重矩阵,ω0为源域的输出权重矩阵;为高维映射函数,将地质样本映射到高维特征空间;τ为映射后地质样本的维度,c为地质信息的类别数量;目标域地质样本集为n为中地质样本的数量,xi表示中第i个地质样本;通过目标域的地质样本求解图拉普拉斯矩阵候选集合为目标域的第i个图拉普拉斯矩阵,m为图拉普拉斯矩阵候选集合中的元素数量;
44、无监督领域适应模块:通过图拉普拉斯矩阵对无标签的目标域地质样本进行一次无监督领域适应,求解优化问题,得到调整后的输出权重矩阵ω*;
45、标签请求模块:根据所述输出权重矩阵ω*计算目标域地质样本的伪标签在目标域地质样本集选取a个地质样本的请求标签,更新标签矩阵y;
46、半监督领域适应模块:令输出权重矩阵为最新得到的ω*,使用标签矩阵y对进行更新,求解优化问题,得到调整后的输出权重矩阵集合为输出权重矩阵集合中的第i个调整后的输出权重矩阵,r为输出权重矩阵集合中的元素数量;
47、二次标签请求模块:根据所述权重矩阵集合从除步骤三选取过的地质样本外的目标域地质样本集中选取不确定性最高的a个地质样本请求标签,更新标签矩阵
48、判断模块:如果没达到标签请求最大数量,则将值赋予ω*,并跳至半监督领域适应模块;如果达到标签请求最大数量,则将值赋予跳至输出目标域预测模型模块;
49、输出目标域预测模型模块:输出目标域预测模型模型调整完毕;
50、预测模块:将无标签的地质样本x*输入到目标域预测模型,得到无标签地质样本的预测结果,即得到地质模型。
51、一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行所述方法的步骤。
52、本发明的系统与方法相对应,方法的细化方案、优化方案同样适用于系统。
53、与现有技术相比,本发明的有益技术效果是:
54、本发明无需源域的数据,只需要提供源域模型;采用了先验分布对齐,能够快速缩小源域和目标域的分布差异;采用了集成流形正则化,能够保证分类结果的平滑性,增加了半监督的安全性,并进一步加快了模型的调整速率;利用模型差异度量,训练得到了多个子模型,进而利用其预测结果的方差描述了地质样本的关键性,最终实现地质样本的主动选取;能够同时解决分类和回归问题。
- 还没有人留言评论。精彩留言会获得点赞!