一种基于跨模态特征融合的图像识别方法及系统与流程
本发明涉及图像处理,特别涉及一种基于跨模态特征融合的图像识别方法及系统。
背景技术:
1、配电柜是电力系统中至关重要的设备,承担着电能分配、控制和保护的功能,确保电力系统的安全运行,提供稳定可靠的电力供应,并保护电路和设备免受电力故障的影响。机器人技术在配电柜的运维和操作中发挥着重要的角色,通过精确的运动和控制,被用于实现故障检测、元器件操作等任务,大大提高了工作的效率和安全性。计算机视觉技术为机器人在配电柜操作中提供了强化的感知和识别能力,通过使用计算机视觉技术,机器人可以准确地识别配电柜中的设备、连接器等,并获取相关的数据和图像信息,为机器人操作提供了重要的指导和支持。然而,配电柜的工作环境通常是封闭和动态的,靠机器人去代替工作人员进行日常操作,就需要模型去应对动态环境下带来的挑战,比如阴影遮挡,光线不足,低分辨率等。在这些条件下,对于只用可见光这一种算法很难达到高精度,因此采用深度相机来提供可见光图像和深度图像,通过融合不同模态的互补性,可以提高目标定位和分割算法的可感知性、可靠性和鲁棒性。
2、随着卷积神经网络的发展,出现了基于cnn(卷积神经网络)的双流网络用于目标检测及分割。在以往的工作中无论如何设计模态融合机制,都是在卷积神经网络上进行的,例如基于跨模态学习与领域自适应rgbd图像语义分割方法(cn 114419323 a),cnn在单模态内推理中具有很强表征和学习能力,能够通过卷积操作能够有效地捕捉输入数据中的局部特征,对图像等具有空间结构的数据具有较好的处理能力,具有局部感知性和多层次的特征表示的优点。与cnn相比,transformer模型是建立在全局关注的基础上的,具有键-查询间的相关性,能够建模长程依赖关系并捕捉全局信息,将卷积神经网络和transformer结合起来,可以同时考虑局部和全局信息,提取强大的特征表示,并解决长程依赖性问题,例如一种腹部ct图像多器官分割方法、装置及终端设备(cn 116030259 a),这篇专利将cnn与transformer结合起来并运用在了目标检测领域。
3、但是,上述解决方式中,基于跨模态学习与领域自适应rgbd图像语义分割方法(cn114419323 a)是使用卷积神经网络的模型并有着良好的分割性能,但卷积运算的局部性限制了模型很难学到感受野以外图像中长距离依赖关系,使基于卷积神经网络的模型处理图像中的纹理、形状和尺寸变化等细节的能力受到一定的限制;因此,在处理具有长距离依赖关系的图像任务时,卷积神经网络可能会面临挑战,并可能无法捕捉到图像全局的特征和上下文信息。
4、而一种腹部ct图像多器官分割方法、装置及终端设备(cn 116030259 a),则是基于视觉transformer的模型采用自注意力机制能够对图像全局信息进行建模,并且整个模型通过多尺度的全局语义特征提取能力来提高目标的分割精度。但是这种单模态的transformer模型应用的场景是非常的单一固定的,用在实际场景中进行目标分割会非常具有局限性,在真实世界中的环境通常是开放的、动态的,比如阴影遮挡、光线曝光及不足、低分辨率的情况等等,在这种条件下,单一模态的分割算法是很难达到较高的分割精度。
5、为了满足动态环境下对配电柜元器件进行目标的分割,通过引入深度相机拍摄的深度图像作为另一个模态,并基于cnn提取各个模态在不同尺度下的特征,然后通过transformer模块来进行不同模态间的互补性融合,来提高目标定位和分割算法的可感知性、可靠性和鲁棒性,且上述模型具有结构体积小、资源消耗低等特点,易于部署到边缘设备上。
技术实现思路
1、本发明实施例的目的是提供一种基于跨模态特征融合的图像识别方法及系统,为了满足动态环境下对配电柜元器件进行目标的分割,通过引入深度相机拍摄的深度图像作为另一个模态,并基于cnn提取各个模态在不同尺度下的特征,然后通过transformer模块来进行不同模态间的互补性融合,来提高目标定位和分割算法的可感知性、可靠性和鲁棒性,且上述模型具有结构体积小、资源消耗低等特点,易于部署到边缘设备上。
2、为解决上述技术问题,本发明实施例的第一方面提供了一种基于跨模态特征融合的图像识别方法,包括如下步骤:
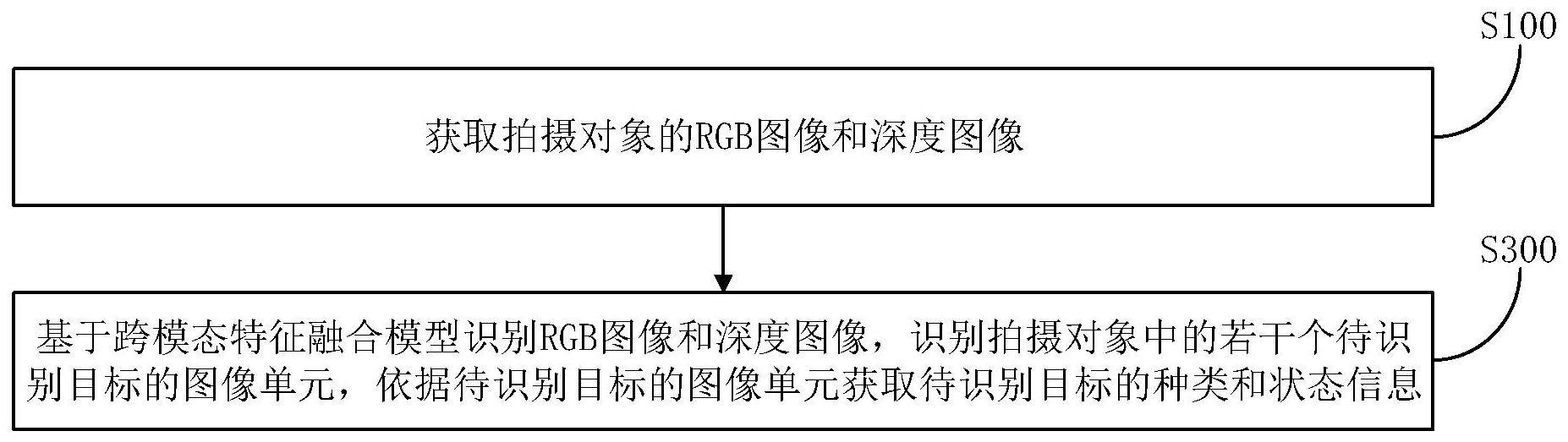
3、获取拍摄对象的rgb图像和深度图像;
4、基于所述跨模态特征融合模型识别所述rgb图像和所述深度图像,识别所述拍摄对象中的若干个待识别目标的图像单元,依据所述待识别目标的图像单元获取所述待识别目标的种类和状态信息;
5、其中,所述跨模态特征融合模型对所述rgb图像和所述深度图像进行特征提取,获取所述rgb图像和所述深度图像多个层级的特征,利用自注意力机制、交错注意力机制和多头注意力机制融合所述rgb图像和所述深度图像特征之间的互补语义信息,逐级对多个尺度的特征进行融合。
6、进一步地,所述基于所述跨模态特征融合模型识别所述rgb图像和所述深度图像之前,还包括:
7、获取所述拍摄对象在各种拍摄条件下的历史图像数据,所述历史图像数据包括:所述拍摄对象的若干个历史rgb图像及对应的历史深度图像;
8、基于预设比例的所述历史图像数据,对所述跨模态特征融合模型进行所述待识别目标的识别训练。
9、进一步地,所述跨模态特征融合模型包括:backbone部分、neck部分和head部分;
10、所述backbone部分分别接收所述rgb图像和所述深度图像,通过卷积模块提取所述rgb图像和所述深度图像的多个尺度的特征,再通过若干个相应的特征融合模块进行特征融合后得到多个尺度的特征图,分别经通道注意力模块发送至所述neck部分;
11、所述neck部分对所述通道注意力模块输出的特征进行提取及并进行尺度上的融合处理,将融合处理后的所述特征发送至所述head部分;
12、所述head部分根据特征确定所述待识别目标的分割区域。
13、进一步地,所述backbone部分包括接收所述rgb图像的第一支路和接收所述深度图像的第二支路;
14、所述第一支路和所述第二支路上分别设有相应的多个图片特征提取单元,所述图片特征提取单元包括:conv模块、c3模块和/或sppf模块;
15、所述第一支路和所述第二支路设有与所述图片特征提取单元相应的transsaca模块,所述transsaca模块分别接收所述第一支路和所述第二支路中相应的所述图片特征提取单元中提取的所述特征,进行特征融合后,再分别发送至相应支路中。
16、进一步地,所述transsaca模块采用多模态特征融合机制,第一输入端为rgb图像卷积特征图,第二输入端为d图像卷积特征图,分别将所述rgb图像卷积特征图和所述d图像卷积特征图展平并重新培训矩阵序列,添加位置嵌入后得到所述transformer模块的输入序列;
17、基于所述transformer模块的输入序列,通过自注意力机制使用qrgb和krgb的点积来计算注意力权重,然后乘上vrgb去得到输出zsargb和zsad,在通过交叉注意力机制使用qd和krgb的点积来计算注意力权重然后乘上vrgb去得到输出zcargb和zcad;
18、基于多层感知器模型进行处理,包括两层全连接前馈网络,中间用一个gelu激活函数去计算输出xoutrgb与xoutd,xoutrgb与xoutd输出维度与输入序列相同,将输出重塑为c×h×w的特征映射foutrgb和foutd,并使用与现有特征映射的元素求和反馈到每个单独的模态分支中。
19、进一步地,所述head部分的损失函数为边界框回归损失函数;
20、其中,所述边界框回归损失函数包括:有界盒回归损失、置信度损失、分类损失及掩码回归损失的和。
21、进一步地,所述识别所述拍摄对象中的若干个待识别目标的图像单元之后,还包括:
22、依据识别结果对所述图像单元进行分割,得到若干个所述待识别目标的图像数据;
23、将若干个所述待识别目标的图像数据的尺寸调整为预设尺寸;
24、基于预设尺寸的所述待识别目标的图像数据获取所述待识别目标的种类和状态信息。
25、相应地,本发明实施例的第二方面提供了一种基于跨模态特征融合的图像识别系统,包括:
26、图像获取模块,其用于获取拍摄对象的rgb图像和深度图像;
27、图像识别模块,其用于基于所述跨模态特征融合模型识别所述rgb图像和所述深度图像,识别所述拍摄对象中的若干个待识别目标的图像单元,依据所述待识别目标的图像单元获取所述待识别目标的种类和状态信息;
28、其中,所述跨模态特征融合模型对所述rgb图像和所述深度图像进行特征提取,获取所述rgb图像和所述深度图像多个层级的特征,利用自注意力机制、交错注意力机制和多头注意力机制融合所述rgb图像和所述深度图像特征之间的互补语义信息,逐级对多个尺度的特征进行融合。
29、进一步地,所述基于跨模态特征融合的图像识别系统还包括:模型训练模块,所述模型训练模块包括:
30、历史数据获取单元,其用于获取所述拍摄对象在各种拍摄条件下的历史图像数据,所述历史图像数据包括:所述拍摄对象的若干个历史rgb图像及对应的历史深度图像;
31、模型识别训练单元,其用于基于预设比例的所述历史图像数据,对所述跨模态特征融合模型进行所述待识别目标的识别训练。
32、进一步地,所述跨模态特征融合模型包括:backbone部分、neck部分和head部分;
33、所述backbone部分分别接收所述rgb图像和所述深度图像,通过卷积模块提取所述rgb图像和所述深度图像的多个尺度的特征,再通过若干个相应的特征融合模块进行特征融合后得到多个尺度的特征图,分别经通道注意力模块发送至所述neck部分;
34、所述neck部分对所述通道注意力模块输出的特征进行提取及并进行尺度上的融合处理,将融合处理后的所述特征发送至所述head部分;
35、所述head部分根据特征确定所述待识别目标的分割区域。
36、进一步地,所述backbone部分包括接收所述rgb图像的第一支路和接收所述深度图像的第二支路;
37、所述第一支路和所述第二支路上分别设有相应的多个图片特征提取单元,所述图片特征提取单元包括:conv模块、c3模块和/或sppf模块;
38、所述第一支路和所述第二支路设有与所述图片特征提取单元相应的transsaca模块,所述transsaca模块分别接收所述第一支路和所述第二支路中相应的所述图片特征提取单元中提取的所述特征,进行特征融合后,再分别发送至相应支路中。
39、进一步地,所述transsaca模块采用多模态特征融合机制,第一输入端为rgb图像卷积特征图,第二输入端为d图像卷积特征图,分别将所述rgb图像卷积特征图和所述d图像卷积特征图展平并重新培训矩阵序列,添加位置嵌入后得到所述transformer模块的输入序列;
40、基于所述transformer模块的输入序列,通过自注意力机制使用qrgb和krgb的点积来计算注意力权重,然后乘上vrgb去得到输出zsargb和zsad,在通过交叉注意力机制使用qd和krgb的点积来计算注意力权重然后乘上vrgb去得到输出zcargb和zcad;
41、基于多层感知器模型进行处理,包括两层全连接前馈网络,中间用一个gelu激活函数去计算输出xoutrgb与xoutd,xoutrgb与xoutd输出维度与输入序列相同,将输出重塑为c×h×w的特征映射foutrgb和foutd,并使用与现有特征映射的元素求和反馈到每个单独的模态分支中。
42、进一步地,所述head部分的损失函数为边界框回归损失函数;
43、其中,所述边界框回归损失函数包括:有界盒回归损失、置信度损失、分类损失及掩码回归损失的和。
44、进一步地,所述图像识别模块包括:
45、图像分割单元,其用于依据识别结果对所述图像单元进行分割,得到若干个所述待识别目标的图像数据;
46、图像调整单元,其用于将若干个所述待识别目标的图像数据的尺寸调整为预设尺寸;
47、信息获取单元,其用于基于预设尺寸的所述待识别目标的图像数据获取所述待识别目标的种类和状态信息。
48、相应地,本发明实施例的第三方面提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器连接的存储器;其中,所述存储器存储有可被所述一个处理器执行的指令,所述指令被所述一个处理器执行,以使所述至少一个处理器执行上述基于跨模态特征融合的图像识别方法。
49、相应地,本发明实施例的第四方面提供了一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现上述基于跨模态特征融合的图像识别方法。
50、本发明实施例的上述技术方案具有如下有益的技术效果:
51、为了满足动态环境下对配电柜元器件进行目标的分割,通过引入深度相机拍摄的深度图像作为另一个模态,并基于cnn提取各个模态在不同尺度下的特征,然后通过transformer模块来进行不同模态间的互补性融合,来提高目标定位和分割算法的可感知性、可靠性和鲁棒性,且上述模型具有结构体积小、资源消耗低等特点,易于部署到边缘设备上。
- 还没有人留言评论。精彩留言会获得点赞!