一种基于大语言模型的微调方法、系统、设备及介质与流程
本发明涉及工业自动化,具体地说,涉及一种基于大语言模型的微调方法、系统、设备及介质。
背景技术:
1、自然语言处理(nlp)任务在transformer模型出现后迎来飞速发展,2022年11月openai推出的chatgpt在短短三个月时间内实现月活跃用户超过1亿,成为历史上用户数量增长最快的消费者应用,也让大语言模型(large language model,llm)走入大众视野。大语言模型超大规模的参数(例如1750亿参数的gpt-3和5400亿参数的palm)使得模型出现了以前参数量较小的预训练语言模型(pre-training language model,plm)所不具备的涌现能力,在对话、检索、问答、推理等一系列复杂任务上表现出惊人的能力。
2、大语言模型具备的通用语言能力已经相当惊艳,但如何将llm的能力专业化于特定任务,在垂直业务和专业领域的专业化能力仍然不足,没有经过微调训练的大语言模型在边界条件模糊、专业知识要求精确的细分领域存在严重的事实性错误,大语言模型生成的信息与现有来源相互冲突,或无法通过现有知识溯源验证(幻觉),严重制约了大语言模型在工业领域的应用。
3、为将大语言模型的通用能力适配到具体的应用领域,通常需要在预训练的基础上结合专业领域的知识进行适配微调。现有的适配预训练后llm的方法包括:指令微调(instruction tuning)、对齐微调(alignment tuning)两种微调方法,由于llm本身参数量巨大、预训练数据集不开源、专业领域数据相对较少、模型存在灾难性遗忘等问题,这两种全量参数微调在实际应用和训练的过程中代价巨大。
4、为解决llm全参数微调开销大的问题,同时尽可能保留llm的良好性能,现在提出大语言模型的高效微调方法,包括适配器微调(adapter tuning)、前缀微调(prefixtuning)、提示微调(prompt tuning)和低秩微调(lora)四种方法。
5、现有llm极度依赖prompt提示词,对prompt提示词变化比较敏感,需要人工精心设计prompt提示词才能取得预想中的较好结果;
6、现有微调方法没有包含类似知识图谱形式的图结构数据,无法高效使用工业界已经存在的丰富、可靠、可信的知识图谱数据;
7、现有微调方法无法解决本地数据规模较小和专业知识较少导致的训练数据分布不均的问题,微调效果无法保证;
8、现有微调方法使用本地已有数据进行更新,对更新的领域知识需要再次训练,否则在知识边界或垂直领域仍会存在幻觉现象;
9、现有微调训练方法在融合新知识后,通常会产生一定程度的模型原本知识的遗忘,导致llm通用能力的损失;
10、现有微调方法将新增知识输入llm进行微调,推理过程存在不确定性,无法准确溯源,无法满足工业领域对结果的可靠性要求。
技术实现思路
1、本发明针对现有的微调方法可靠性和确定性不足的问题,提出一种基于大语言模型的微调方法、系统、设备及介质;通过将知识图谱作为控制模态进行微调,并基于逻辑链分解的知识图谱三元组训练数据,生成高质量的llm微调数据集,能够充分利用知识图谱的内容和关系,缓解微调数据分布不均衡的问题,实现了基于知识图谱的上下文学习,将多种工业知识图谱作为大语言模型的输入,增强了大语言模型输出的可靠性和确定性。
2、本发明具体实现内容如下:
3、一种基于大语言模型的微调方法,首先从智能中台获取工业知识图谱,根据待输入的查询问题和所述工业知识图谱生成知识图谱三元组训练数据,然后根据llm大语言模型构建微调模型,最后将所述三元组训练数据输入至所述微调模型中,得到知识图谱逻辑链溯源回答。
4、为了更好地实现本发明,进一步地,所述基于大语言模型的微调方法具体包括以下步骤:
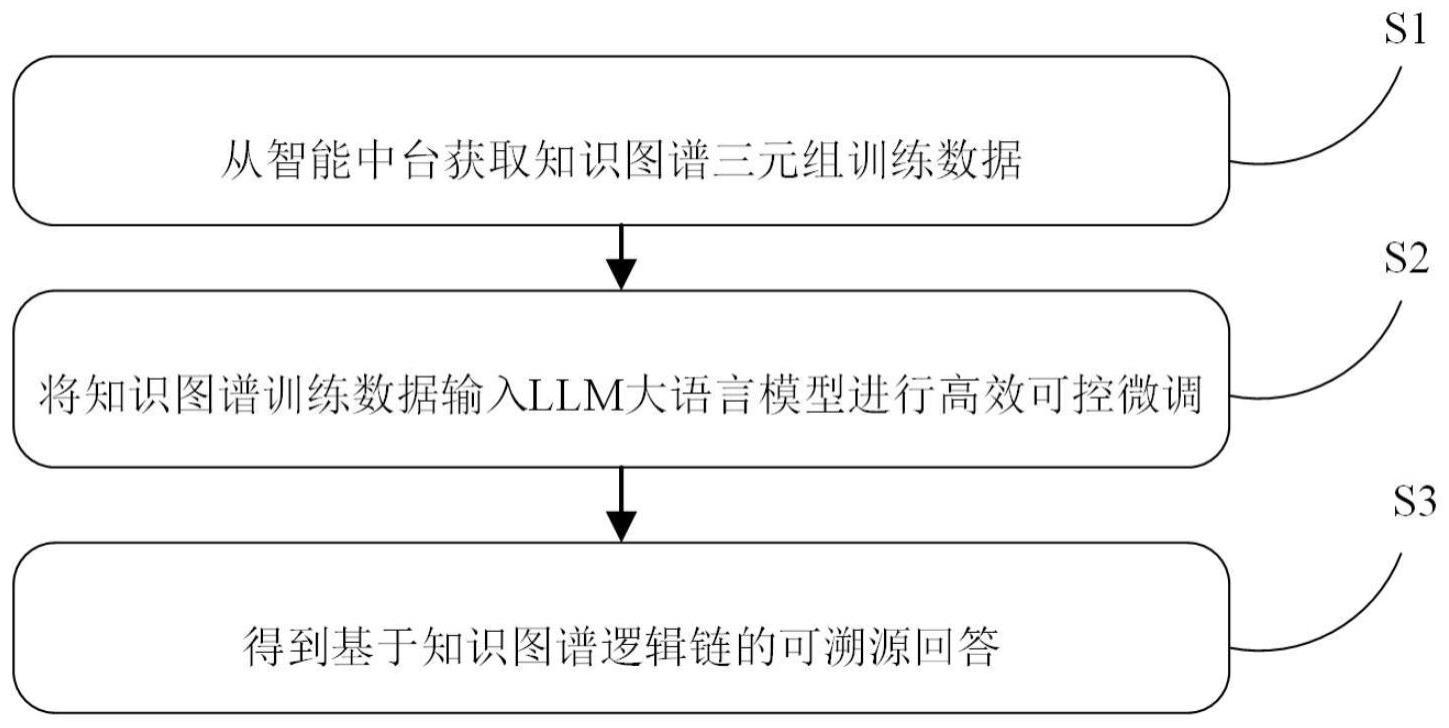
5、步骤s1:从智能中台获取工业知识图谱,根据待输入的查询问题和所述工业知识图谱生成知识图谱三元组训练数据;
6、步骤s2:根据llm大语言模型构建微调训练模型,并调用注意力可控微调网络训练所述微调训练模型;
7、步骤s3:将所述知识图谱三元组训练数据输入至所述微调训练模型中,得到知识图谱逻辑链溯源回答。
8、为了更好地实现本发明,进一步地,所述步骤s1具体包括以下步骤:
9、步骤s11:调用逻辑链分解方法分解查询问题,得到查询子问题;
10、步骤s12:从智能中台获取工业知识图谱,根据所述查询子问题和所述工业知识图谱生成知识图谱三元组训练数据;
11、步骤s13:将所述知识图谱三元组训练数据作为控制模态,根据所述知识图谱三元组数据对应的查询问题生成查询数据。
12、为了更好地实现本发明,进一步地,所述步骤s12具体包括以下步骤:
13、步骤s121:关联搜索所述查询子问题,根据所述知识图谱检索与所述查询问题相关的实体和关系;
14、步骤s122:根据所述实体和关系,得到与所述查询问题相关的知识图谱子图;
15、步骤s123:将所述知识图谱子图分解为原子级单条逻辑,将所述原子级单条逻辑与所述查询问题根据设定的格式构建知识图谱三元组训练数据。
16、为了更好地实现本发明,进一步地,所述步骤s2具体包括以下步骤:
17、步骤s21:根据llm大语言模型,推理所述查询问题,预测推理结果;
18、步骤s22:调用图神经网络提取所述知识图谱三元组训练数据的特征;
19、步骤s23:添加初始化为0的卷积层与所述llm大语言模型的冻结参数残差连接,将所述推理结果与所述知识图谱三元组训练数据的特征拼接得到混合特征;
20、步骤s24:根据所述混合特征构建微调训练模型,调用低秩分解矩阵结合通道和空间注意力机制训练所述微调训练模型。
21、为了更好地实现本发明,进一步地,所述步骤s3具体包括以下步骤:
22、步骤s31:将所述三元组训练数据中的查询问题转换为词特征向量;
23、步骤s32:将所述词特征向量与获取的位置信息融合,得到包含所述位置信息的词特征向量;
24、步骤s33:推理所述包含所述位置信息的词特征向量,得到推理特征向量;
25、步骤s34:将所述推理特征向量与所述工业知识图谱融合,得到融合知识图谱信息的特征向量;
26、步骤s35:将所述融合知识图谱信息的特征向量还原为自然语言,得到知识图谱逻辑链溯源回答。
27、基于上述提出的基于大语言模型的微调方法,为了更好地实现本发明,进一步地,提出一种基于大语言模型的微调系统,包括预处理单元、构建单元、预测单元;
28、所述预处理单元,用于从智能中台获取工业知识图谱,根据待输入的查询问题和所述工业知识图谱生成知识图谱三元组训练数据;
29、所述构建单元,用于根据llm大语言模型构建微调模型;
30、所述预测单元,用于将所述三元组训练数据输入至所述微调模型中,得到知识图谱逻辑链溯源回答。
31、基于上述提出的基于大语言模型的微调方法,为了更好地实现本发明,进一步地,提出一种电子设备,包括存储器和处理器;所述存储器上存储有计算机程序;当所述计算机程序在所述处理器上执行时,实现上述的基于大语言模型的微调方法。
32、基于上述提出的基于大语言模型的微调方法,为了更好地实现本发明,进一步地,提出一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机指令;当所述计算机指令在上述的电子设备上执行时,实现上述的基于大语言模型的微调方法。
33、本发明具有以下有益效果:
34、(1)本发明将知识图谱作为控制模态进行微调,并基于逻辑链分解的知识图谱三元组训练数据,生成高质量的llm微调数据集,能够充分利用知识图谱的内容和关系,缓解微调数据分布不均衡的问题,实现了基于知识图谱的上下文学习,将多种工业知识图谱作为大语言模型的输入,增强了大语言模型输出的可靠性和确定性。
35、(2)本发明基于知识图谱逻辑链分解的知识图谱三元组训练数据,有效地提升了大语言模型对知识图谱实体间逻辑关系的理解和推理能力,增强了大语言模型的零样本推理能力,提升了大语言模型对知识图谱的通用推理能力。
36、(3)本发明使用将注意力可控微调模块acnet和低秩注意力分解微调模块lra与大语言模型冻结参数残差连接,在增强大语言模型对知识图谱的理解和推理能力的同时,最大限度保留了大语言模型原本的通用推理能力。
- 还没有人留言评论。精彩留言会获得点赞!